Referenz zu Protokollmetriken
Dieses Handbuch enthält Definitionen für alle integrierten Metrikdiagramme im ExtraHop-System. Diagramme sind nach Protokoll, Asset und in System-Dashboards verfügbar.
Metriken sind Echtzeitmessungen Ihres Netzwerkverhaltens, die das ExtraHop-System anhand von Kabel- oder Durchflussdaten berechnet. Das ExtraHop-System kann über 5.000 Metriken aus dem Netzwerkverkehr analysieren und klassifizieren und die Metriken dann einer Quelle zuordnen — den Ressourcen in Ihrem Netzwerk, wie Anwendungen, Geräten, Aktivitätsgruppen oder Netzwerken.
Mit Metriken arbeiten
Hier sind einige Möglichkeiten, wie Sie mit Metriken arbeiten können:
- Wählen Sie ein Asset als Metrik Quelle im gesamten ExtraHop-System, wenn Dashboard-Diagramme erstellen, Warnmeldungen konfigurieren, oder Trigger bauen.
- Metriken anzeigen und auf Protokollseiten zugreifen von einem Seite „ Geräteübersicht".
- Metriken im System anzeigen Sicherheit, Netzwerk, und Aktivität Dashboards.
- Gehen Sie anhand von Kennzahlen auf oberster Ebene genauer vor um detaillierte Metrikseiten anzuzeigen, die eine Liste von Metrikwerten für einen bestimmten Schlüssel (z. B. eine Client- oder Server-IP-Adresse) enthalten. Wenn Sie sich beispielsweise die Gesamtzahl der Fehler ansehen, klicken Sie auf die Zahl und wählen Sie Server um zu sehen, welche Server die Fehler zurückgegeben haben.
- Zusätzliche Quellen oder Metriken hinzufügen zu einem Diagramm.
- Sehen Sie sich alle integrierten und benutzerdefinierten Messwerte an, die in der Metrischer Katalog.
- Erstelle eine benutzerdefinierte Metrik um Daten zu sammeln, die nicht in einer integrierten Metrik enthalten sind.
- Diagrammdaten exportieren zu Excel oder CSV.
- Erstellen Sie ein PDF eines Dashboard oder Diagramms.
- Erstellen Sie ein Diagramm
- Erstellen Sie eine Aktivitätsdiagramm.
- Suche nach Geräten nach Protokollaktivität.
- Finden Sie Erkennungen.
Arten von Metriken
Jede Metrik im ExtraHop-System ist in einen Metrik Typ eingeteilt. Wenn Sie die Unterschiede zwischen den Metriktypen verstehen, können Sie Diagramme konfigurieren oder Trigger schreiben, um benutzerdefinierte Metriken zu erfassen. Ein Heatmap-Diagramm kann beispielsweise nur Datensatzmetriken anzeigen.
- Zählen
- Die Anzahl der Ereignisse, die in einem bestimmten Zeitraum aufgetreten sind. Sie können die Zählmetriken als Rate oder als Gesamtzahl anzeigen. Ein Byte wird beispielsweise als Zählung aufgezeichnet und kann entweder eine Durchsatzrate (wie in einem Zeitreihendiagramm dargestellt) oder das gesamte Verkehrsvolumen (wie in einer Tabelle dargestellt) darstellen. Tarife sind hilfreich, um Zählungen über verschiedene Zeiträume hinweg zu vergleichen. Eine Zählmetrik kann als Durchschnittswert pro Sekunde im Zeitverlauf berechnet werden. Bei der Anzeige hochgenauer Byte- und Paketmetriken (1 Sekunde) können Sie auch eine maximale Rate und eine minimale Rate anzeigen. Zu den Zählmetriken gehören Fehler, Pakete und Antworten.
- Zählrate
-
Die Anzahl der Ereignisse, die in einem bestimmten Zeitraum aufgetreten sind. Zählratenmetriken und Zählmetriken werden auf die gleiche Weise berechnet. Zählraten-Metriken erfassen jedoch zusätzliche Details, anhand derer Sie die Höchst- und Mindestrate für ein Intervall anzeigen können. Zu den Messwerten für die Zählrate gehören Byte und Pakete.
- Eindeutige Anzahl
-
Die Anzahl der eindeutigen Ereignisse, die während eines ausgewählten Zeitintervalls aufgetreten sind. Die Kennzahl für die eindeutige Anzahl bietet eine Schätzung der Anzahl der eindeutigen Elemente, die während des ausgewählten Zeitintervalls in einem Satz platziert wurden. Schätzungen werden mit dem HyperLogLog-Algorithmus berechnet.
- Datensatz
- Eine Verteilung von Daten, die in Perzentilwerte berechnet werden kann. Zu den Datensatzmetriken gehören die Verarbeitungszeit und die Roundtrip-Zeit.
- Maximal
- Ein einzelner Datenpunkt, der den Maximalwert aus einem bestimmten Zeitraum darstellt.
- Probenset
- Eine Zusammenfassung der Daten über ein Detail-Metrik. Wenn Sie eine Stichprobenmetrik in einem Diagramm auswählen, können Sie einen Mittelwert (Durchschnitt) und eine Standardabweichung über einen bestimmten Zeitraum anzeigen.
- Schnappschuss
- Ein Datenpunkt, der einen einzelnen Zeitpunkt darstellt.
Metriken nach Protokoll
Jede Protokollseite enthält integrierte Diagramme mit wichtigen Kennzahlen zu Ihren Ressourcen. Diese Metrikdiagramme können in Ihre Dashboards kopiert werden.
AAA
Das ExtraHop-System sammelt Metriken zu Authentifizierung, Autorisierung und Abrechnung (AAA) Protokollaktivität. AAA ist ein Sicherheitsframework, das Netzwerkzugriffsprotokolle auf Anwendungsebene wie RADIUS, Diameter, TACACS und TACACS+ umfasst.
AAA-Anwendungsseite
Auf dieser Seite werden Metrikdiagramme von angezeigt AAA Verkehr, der mit einem Anwendungscontainer in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
AAA Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann AAA-Fehler und -Antworten mit der
Anwendung verknüpft waren. Anhand dieser Informationen können Sie feststellen, wie aktiv die Anwendung zum
Zeitpunkt des Auftretens der Fehler war.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der AAA-Antworten. Fehler Die Anzahl der AAA-Antworten Fehler. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der AAA-Antworten, die mit der
Anwendung verknüpft waren, und wie viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der AAA-Antworten. Fehler Die Anzahl der AAA-Antworten Fehler. - Leistung (95. Perzentil)
-
Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken.
Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer vollständigen
Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange Clients gebraucht haben, um Anfragen an
das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange die Server für die Bearbeitung von Anfragen gebraucht haben;
und die Antwortübertragungszeit zeigt, wie lange die Server gebraucht haben, um Antworten an
das Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
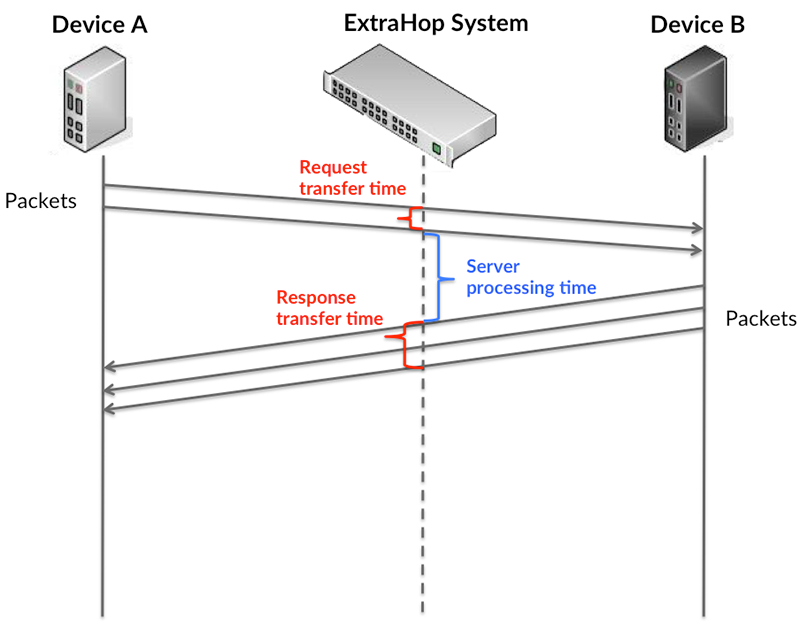
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
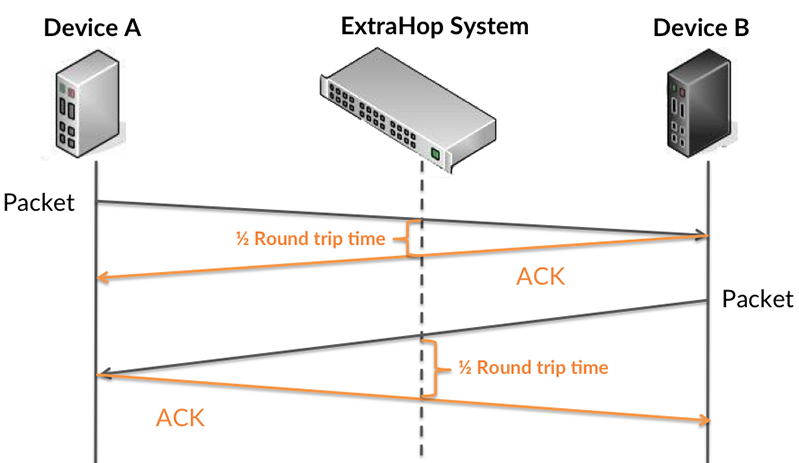
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Transferzeit anfragen Die Zeit zwischen der Erkennung durch das ExtraHop-System das erste Paket und das letzte Paket einer AAA-Anfrage. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit des Servers Die Zeit zwischen der Erkennung durch das ExtraHop-System das letzte Paket einer AAA-Anfrage und das erste Paket der entsprechenden Antwort. Übertragungszeit der Antwort Die Zeit zwischen der Erkennung durch das ExtraHop-System das erste Paket und das letzte Paket einer AAA-Antwort. Ein hoher Wert könnte darauf hinweisen eine große Antwort oder Netzwerkverzögerung. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines AAA-Clients oder Server Paket, für das eine sofortige Bestätigung erforderlich war und wann die Bestätigung erfolgte erhalten. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
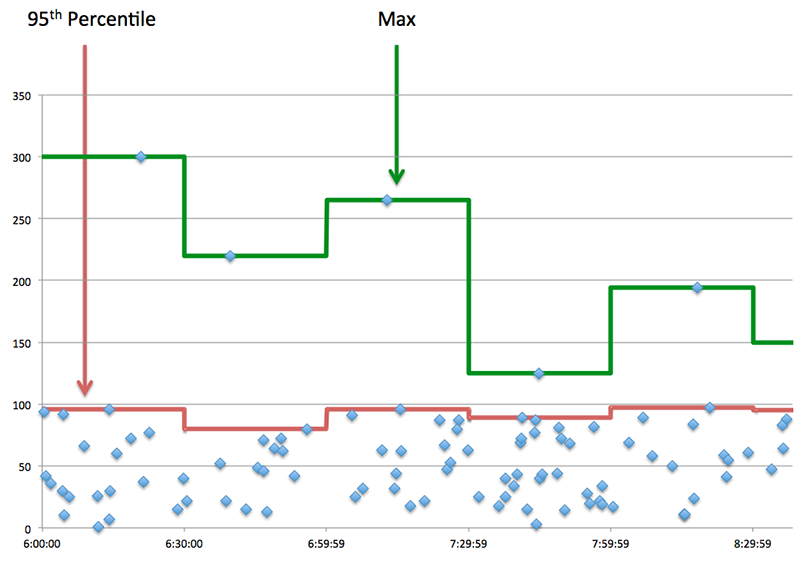
- Aufführung (95.)
-
Wenn eine Anwendung langsam reagiert, können Sie anhand
von Leistungsübersichtsmetriken herausfinden, ob das Netzwerk oder die Server das
Problem verursachen. Diese Metriken zeigen das 95. Perzentil der Zeit, die Server für die Bearbeitung von
Anfragen von Clients benötigten, im Vergleich zum 95. Perzentil der Zeit, die Pakete aus diesen Anfragen
(und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten. Hohe
Serververarbeitungszeiten deuten darauf hin, dass Clients langsame Server kontaktieren. Hohe
TCP-Roundtrip-Zeiten deuten darauf hin, dass Clients über langsame Netzwerke kommunizieren.
Metrisch Beschreibung Verarbeitungszeit des Servers Die Zeit zwischen der Erkennung durch das ExtraHop-System das letzte Paket einer AAA-Anfrage und das erste Paket der entsprechenden Antwort. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines AAA-Clients oder Server Paket, für das eine sofortige Bestätigung erforderlich war und wann die Bestätigung erfolgte erhalten.
AAA-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche AAA-Methoden mit der Anwendung verknüpft waren, indem die Gesamtzahl der AAA-Anfragen nach Methoden aufgeschlüsselt wird.
- Die häufigsten Fehlertypen
- Dieses Diagramm zeigt, welche AAA-Fehlertypen am häufigsten mit der Anwendung in Verbindung gebracht wurden, indem die Anzahl der Antworten nach Fehlertyp aufgeschlüsselt wird.
AAA-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des AAA-Servers Die Zeit zwischen der Erkennung durch das ExtraHop-System das letzte Paket einer AAA-Anfrage und das erste Paket der entsprechenden Antwort. - Verarbeitungszeit des Servers
-
Diese Tabelle zeigt die durchschnittliche Bearbeitungszeit für den Anwendung.
Metrisch Beschreibung Verarbeitungszeit des AAA-Servers Die Zeit zwischen der Erkennung durch das ExtraHop-System das letzte Paket einer AAA-Anfrage und das erste Paket der entsprechenden Antwort. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines AAA-Clients oder Server Paket, für das eine sofortige Bestätigung erforderlich war und wann die Bestätigung erfolgte erhalten. - Zeit für Hin- und Rückfahrt
-
Diese Tabelle zeigt
die durchschnittliche Hin- und Rückflugzeit für die Anwendung.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines AAA-Clients oder Server Paket, für das eine sofortige Bestätigung erforderlich war und wann die Bestätigung erfolgte erhalten.
AAA Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass ein Problem mit einem Server oder einem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
-
Dieses Diagramm zeigt die Anzahl der Nullfenster, die einer Anwendung
zugeordnet waren. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der Pakete
angeben, die über einen bestimmten Zeitraum an sie gesendet werden können.
Wenn an ein Gerät mehr Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein
Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig einzustellen, bis das Gerät den Vorgang
aufholt. Wenn Sie eine große Anzahl von Nullfenstern sehen, ist ein Server oder Client möglicherweise
nicht schnell genug, um die empfangene Datenmenge zu unterstützen.
Metrisch Definition Zero Windows anfordern Die Anzahl der Null-Window-Werbungen, die wurden von AAA-Kunden gesendet. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl eingehender Zero-Windows weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Antwort Null Windows Die Anzahl der gesendeten Null-Window-Anzeigen von Servern beim Empfang von AAA-Anfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von ausgehenden Zero-Windows weist darauf hin, dass ein Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Gesamtzahl der Host-Stände
- Dieses Diagramm zeigt die durchschnittliche Anzahl von Zero-Window-Werbeanzeigen, die von Geräten gesendet wurden.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen
Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu
viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät
eine Anfrage oder Antwort sendet und innerhalb einer bestimmten
Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen
nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise
zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, als Clients AAA-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server AAA-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
- Gesamtzahl der Netzwerkausfälle
-
Dieses Diagramm zeigt die durchschnittliche Anzahl von Timeouts bei der
erneuten Übertragung, die durch Überlastung beim Senden von Anfragen durch Clients und Server verursacht wurden.
Metrisch Definition RTOs Ein Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, als Clients AAA-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server AAA-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Metrische AAA-Gesamtwerte
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr Anfragen, als Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um herauszufinden, ob das Problem mit dem Netzwerk oder einem Server zusammenhängt, überprüfen Sie RTOs und Zero Windows in der Netzwerk-Daten Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der AAA-Anfragen und -Antworten exakt gleich sein wird, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der AAA-Anfragen, die waren gesendet. Antworten Die Anzahl der AAA-Antworten. Fehler Die Anzahl der AAA-Antworten Fehler. Durchmesser-Anfrage Die Anzahl der Diameter-Anfragen, die waren gesendet. Diameter ist eine aktualisierte Version des RADIUS AAA-Protokolls. RADIUS-Anfrage Die Anzahl der RADIUS (Remote Authentication) Dial-In User Service) -Anfragen, die gesendet wurden Aborte Die Anzahl der AAA-Protokollsitzungen, die abgebrochen. - AAA-Netzwerkmetriken
-
Metrisch Beschreibung Zero Windows anfordern Die Anzahl der Null-Window-Werbungen, die wurden von AAA-Kunden gesendet. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Antwort Null Windows Die Anzahl der gesendeten Null-Window-Anzeigen von Servern beim Empfang von AAA-Anfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. RTOs anfragen Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, als Clients AAA-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Antwort-RTOs Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server AAA-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. L2-Byte anfordern Die Anzahl der gesendeten L2-Bytes, die verbunden mit AAA-Anfragen. Antwort L2 Byte Die Anzahl der gesendeten L2-Bytes, die verbunden mit AAA-Antworten. Goodput Bytes anfordern Die Anzahl der Goodput-Bytes, die mit verknüpft sind AAA-Anfragen. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Antwort Goodput Bytes Die Anzahl der Goodput-Bytes, die mit verknüpft sind AAA-Antworten. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Pakete anfordern Die Anzahl der versendeten Pakete, die zugeordnet wurden mit AAA-Anfragen. Antwortpakete Die Anzahl der versendeten Pakete, die zugeordnet wurden mit AAA-Antworten.
AAA-Kundenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt AAA Client-Verkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
AAA Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann AAA-Fehler aufgetreten sind und wie viele Antworten der AAA-Client
erhalten hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Client zu dem Zeitpunkt war, als er die Fehler
empfing.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der AAA-Antworten, die eingegangen sind als das Gerät als AAA-Client fungierte. Fehler Die Anzahl der AAA-Antwortfehler, die waren empfangen, als das Gerät als AAA-Client fungierte. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der AAA-Antworten, die der Client erhalten hat, und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der AAA-Antworten, die eingegangen sind als das Gerät als AAA-Client fungierte. Fehler Die Anzahl der AAA-Antwortfehler, die waren empfangen, als das Gerät als AAA-Client fungierte. - Leistung (95. Perzentil)
- Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken. Die Serververarbeitungszeit
gibt an, wie lange Server gebraucht haben, um Anfragen von Clients zu verarbeiten. Die Verarbeitungszeiten werden
berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und
Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, allein anhand der Verarbeitungszeit zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Metrik allein ein unvollständiges Bild liefert. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Verarbeitungszeiten sehen, aber die RTT niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn jedoch sowohl die RTT- als auch die Verarbeitungszeiten hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
RTT misst nur, wie lange es dauert, bis eine sofortige Bestätigung gesendet wird; es wartet nicht, bis alle Pakete zugestellt sind. Daher ist RTT ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Verarbeitungszeiten feststellen, die TCP-RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Überprüfen Sie das Netzwerk auf Latenzprobleme, wenn sowohl TCP-RTT als auch Verarbeitungszeiten übereinstimmen.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Die Verarbeitungszeit kann hoch sein, weil der Server lange gebraucht hat, um die Antwort zu übertragen (möglicherweise, weil die Antwort sehr umfangreich war). Die Verarbeitungszeit kann jedoch auch hoch sein, weil die Antwort lange Zeit benötigt hat, bis die Antwort im Netzwerk übertragen wurde (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Verarbeitungszeit des Servers Die Zeit zwischen dem ExtraHop-System Erkennen des letzten Paket einer gesendeten AAA-Anfrage und des ersten Paket der entsprechende Antwort, wenn das Gerät als AAA-Client fungierte. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen AAA-Client das erforderte eine sofortige Bestätigung und wann die Bestätigung eingegangen war. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Leistungsübersicht (95. Perzentil)
-
Wenn ein Client langsam reagiert, können Sie
anhand von Leistungsübersichtsmetriken herausfinden, ob das Netzwerk oder die Server das Problem verursachen.
Diese Metriken zeigen das 95. Perzentil der Zeit, die Server für die Bearbeitung von
Anfragen vom Client benötigten, im Vergleich zur 95. Perzentilzeit, die Pakete aus diesen
Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten.
Hohe Serververarbeitungszeiten deuten darauf hin, dass der Client langsame Server kontaktiert. Hohe
TCP-Roundtrip-Zeiten deuten darauf hin, dass der Client über langsame
Netzwerke kommuniziert.
Metrisch Beschreibung Verarbeitungszeit des Servers Die Zeit zwischen dem ExtraHop-System Erkennen des letzten Paket einer gesendeten AAA-Anfrage und des ersten Paket der entsprechende Antwort, wenn das Gerät als AAA-Client fungierte. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen AAA-Client das erforderte eine sofortige Bestätigung und wann die Bestätigung eingegangen war. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz
AAA-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche AAA-Methoden der Client am häufigsten aufgerufen hat, indem die Gesamtzahl der Anfragen, die der Client nach Methode gesendet hat, aufgeschlüsselt wird.
- Die häufigsten Fehlertypen
- Dieses Diagramm zeigt, welche AAA-Fehlertypen der Client am häufigsten erhalten hat, indem die Anzahl der an den Client zurückgegebenen Antworten nach Fehlertyp aufgeschlüsselt wird.
AAA-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung AAA-Client-Server-Verarbeitungszeit Die Zeit zwischen dem ExtraHop-System Erkennen des letzten Paket einer gesendeten AAA-Anfrage und des ersten Paket der entsprechende Antwort, wenn das Gerät als AAA-Client fungierte. - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Bearbeitungszeit für den Client.
Metrisch Beschreibung AAA-Client-Server-Verarbeitungszeit Die Zeit zwischen dem ExtraHop-System Erkennen des letzten Paket einer gesendeten AAA-Anfrage und des ersten Paket der entsprechende Antwort, wenn das Gerät als AAA-Client fungierte. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen AAA-Client das erforderte eine sofortige Bestätigung und wann die Bestätigung eingegangen war. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Hin- und Rückflugzeit für den Client.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen AAA-Client das erforderte eine sofortige Bestätigung und wann die Bestätigung eingegangen war. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Metrische AAA-Gesamtwerte
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten
-
Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, sendet der Client möglicherweise mehr Anfragen, als die Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen , ob das Problem beim Netzwerk oder beim Server liegt, überprüfen Sie RTOs und Zero Windows in der Netzwerk-Daten Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der AAA-Anfragen und -Antworten exakt gleich sein wird, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der AAA-Anfragen, die gesendet wurden, als Gerät fungierte als AAA-Client. Antworten Die Anzahl der AAA-Antworten, die eingegangen sind als das Gerät als AAA-Client fungierte. Fehler Die Anzahl der AAA-Antwortfehler, die waren empfangen, als das Gerät als AAA-Client fungierte. Durchmesser-Anfrage Die Anzahl der Diameter-Anfragen, die waren gesendet, als das Gerät als AAA-Client fungierte. Diameter ist eine aktualisierte Version von das RADIUS-AAA-Protokoll. RADIUS-Anfrage Die Anzahl der RADIUS (Remote Authentication) Dial-In (User Service) -Anfragen, die gesendet wurden, als das Gerät als AAA fungierte Client. Aborte Die Anzahl der aufgetretenen abgebrochenen Sitzungen als das Gerät als AAA-Client fungierte.
AAA-Serverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt AAA Serververkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
AAA Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann AAA-Fehler aufgetreten sind und wie viele AAA-Antworten der Server
gesendet hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Server zu dem Zeitpunkt war, als er die Fehler
zurückgab.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der AAA-Antworten, die gesendet wurden, als das Gerät fungierte als AAA-Server. Fehler Die Anzahl der AAA-Antwortfehler, die gesendet, als das Gerät als AAA-Server fungierte. - Transaktionen insgesamt
-
Dieses Diagramm zeigt die Gesamtzahl der AAA-Antworten, die der Server gesendet hat, und wie viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der AAA-Antworten, die gesendet wurden, als das Gerät fungierte als AAA-Server. Fehler Die Anzahl der AAA-Antwortfehler, die gesendet, als das Gerät als AAA-Server fungierte. - Leistung (95. Perzentil)
- Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken. Die Serververarbeitungszeit
gibt an, wie lange Server gebraucht haben, um Anfragen von Clients zu verarbeiten. Die Verarbeitungszeiten werden
berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und
Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, allein anhand der Verarbeitungszeit zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Metrik allein ein unvollständiges Bild liefert. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Verarbeitungszeiten sehen, aber die RTT niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn jedoch sowohl die RTT- als auch die Verarbeitungszeiten hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
RTT misst nur, wie lange es dauert, bis eine sofortige Bestätigung gesendet wird; es wartet nicht, bis alle Pakete zugestellt sind. Daher ist RTT ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Verarbeitungszeiten sehen, aber die TCP-RTT niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Überprüfen Sie das Netzwerk auf Latenzprobleme, wenn sowohl TCP-RTT als auch Verarbeitungszeiten übereinstimmen.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Die Verarbeitungszeit kann hoch sein, weil der Server lange gebraucht hat, um die Antwort zu übertragen (möglicherweise, weil die Antwort sehr umfangreich war). Die Verarbeitungszeit kann jedoch auch hoch sein, weil die Antwort lange Zeit benötigt hat, bis die Antwort im Netzwerk übertragen wurde (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Verarbeitungszeit des AAA-Servers Die Zeit zwischen dem ExtraHop-System Erfassen des letzten Paket einer empfangenen AAA-Anfrage und des ersten Paket der entsprechende Antwort, wenn das Gerät als AAA-Server fungierte. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen AAA-Server das erforderte eine sofortige Bestätigung und wann die Bestätigung eingegangen war. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Leistungsübersicht (95. Perzentil)
-
Wenn ein Server langsam reagiert, können Sie
anhand von Leistungsübersichtsmetriken herausfinden, ob das
Problem vom Netzwerk oder vom Server verursacht wird. Die Leistungsübersichtsmetriken zeigen das 95. Perzentil der Zeit, die der
Server für die Verarbeitung von Anfragen von Clients benötigte, im Vergleich zur 95. Perzentilzeit, die
Pakete aus diesen Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten.
Hohe Serververarbeitungszeiten deuten darauf hin, dass der Server langsam ist.
Hohe RTTs weisen darauf hin, dass der Server über langsame Netzwerke kommuniziert.
Metrisch Beschreibung AAA-Client-Server-Verarbeitungszeit Die Zeit zwischen dem ExtraHop-System Erfassen des letzten Paket einer empfangenen AAA-Anfrage und des ersten Paket der entsprechende Antwort, wenn das Gerät als AAA-Server fungierte. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen AAA-Server das erforderte eine sofortige Bestätigung und wann die Bestätigung eingegangen war. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz
AAA-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche AAA-Methoden auf dem Server am häufigsten aufgerufen wurden, indem die Gesamtzahl der Anfragen, die der Server erhalten hat, nach Methode aufgeteilt wird.
- Die häufigsten Fehlertypen
- Dieses Diagramm zeigt, welche AAA-Fehlertypen der Server am häufigsten zurückgegeben hat, indem die Gesamtzahl der vom Server gesendeten Antworten nach Fehlertyp aufgeschlüsselt wird.
AAA-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des AAA-Servers Die Zeit zwischen dem ExtraHop-System Erfassen des letzten Paket einer empfangenen AAA-Anfrage und des ersten Paket der entsprechende Antwort, wenn das Gerät als AAA-Server fungierte. - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Verarbeitungszeit für den Server.
Metrisch Beschreibung Verarbeitungszeit des AAA-Servers Die Zeit zwischen dem ExtraHop-System Erfassen des letzten Paket einer empfangenen AAA-Anfrage und des ersten Paket der entsprechende Antwort, wenn das Gerät als AAA-Server fungierte. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen AAA-Server das erforderte eine sofortige Bestätigung und wann die Bestätigung eingegangen war. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Roundtrip-Zeit für den Server.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen AAA-Server das erforderte eine sofortige Bestätigung und wann die Bestätigung eingegangen war. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Metrische AAA-Gesamtwerte
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten
-
Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr Anfragen, als der Server verarbeiten kann, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen , ob das Problem am Netzwerk oder am Server liegt, überprüfen Sie RTOs und Zero Windows in der Netzwerk-Daten Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der AAA-Anfragen und -Antworten exakt gleich sein wird, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der AAA-Anfragen, die eingegangen sind, als das Gerät fungierte als AAA-Server. Antworten Die Anzahl der AAA-Antworten, die gesendet wurden, als das Gerät fungierte als AAA-Server. Fehler Die Anzahl der AAA-Antwortfehler, die gesendet, als das Gerät als AAA-Server fungierte. Durchmesser-Anfrage Die Anzahl der Diameter-Anfragen, die waren empfangen, als das Gerät als AAA-Server fungierte. Diameter ist eine aktualisierte Version des RADIUS-AAA-Protokolls. RADIUS-Anfrage Die Anzahl der RADIUS-Anfragen, die der Gerät, das empfangen wurde, wenn es als AAA-Server fungiert. Aborte Die Anzahl der aufgetretenen abgebrochenen Sitzungen als das Gerät als AAA-Server fungierte.
AAA-Kundengruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt AAA Client-Verkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
AAA-Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann AAA-Fehler aufgetreten sind und wie viele Antworten die AAA-Clients
erhalten haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Kunden zu dem Zeitpunkt waren, als sie die Fehler
erhielten.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie weiter unten im Abschnitt Metriken für Gruppen.
Metrisch Beschreibung Antworten Die Anzahl der AAA-Antworten, die eingegangen sind als das Gerät als AAA-Client fungierte. Fehler Die Anzahl der AAA-Antwortfehler, die waren empfangen, als das Gerät als AAA-Client fungierte. - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele AAA-Antworten die Kunden erhalten haben und wie viele dieser
Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der AAA-Antworten, die eingegangen sind als das Gerät als AAA-Client fungierte. Fehler Die Anzahl der AAA-Antwortfehler, die waren empfangen, als das Gerät als AAA-Client fungierte.
AAA-Details für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (AAA-Kunden)
- Dieses Diagramm zeigt, welche AAA-Clients in der Gruppe am aktivsten waren, indem es die Gesamtzahl der AAA-Anfragen aufschlüsselt, die die Gruppe vom Client gesendet hat.
- Die besten Methoden
- Dieses Diagramm zeigt, welche AAA-Methoden die Gruppe am häufigsten aufgerufen hat, indem die Gesamtzahl der von der Gruppe gesendeten Anfragen nach Methode aufgeschlüsselt wird.
- Die häufigsten Fehlertypen
- Dieses Diagramm zeigt, welche AAA-Fehlertypen die Gruppe am häufigsten erhalten hat, indem die Anzahl der an die Gruppe zurückgegebenen Antworten nach Fehlertyp aufgeschlüsselt wird.
AAA-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden die Clients möglicherweise mehr Anfragen, als Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Anfragen Die Anzahl der AAA-Anfragen, die gesendet wurden, als Gerät fungierte als AAA-Client. Antworten Die Anzahl der AAA-Antworten, die eingegangen sind als das Gerät als AAA-Client fungierte. Fehler Die Anzahl der AAA-Antwortfehler, die waren empfangen, als das Gerät als AAA-Client fungierte. Durchmesser-Anfrage Die Anzahl der Diameter-Anfragen, die waren gesendet, als das Gerät als AAA-Client fungierte. Diameter ist eine aktualisierte Version von das RADIUS-AAA-Protokoll. RADIUS-Anfrage Die Anzahl der RADIUS (Remote Authentication) Dial-In (User Service) -Anfragen, die gesendet wurden, als das Gerät als AAA fungierte Client. Aborte Die Anzahl der aufgetretenen abgebrochenen Sitzungen als das Gerät als AAA-Client fungierte. - Verarbeitungszeit des Servers
-
Wenn sich eine Client-Gruppe langsam verhält, können Sie anhand der Serververarbeitungszeit herausfinden,
ob das Problem bei den Servern liegt. Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche
Zeit, die Server für die Bearbeitung von Anfragen von den Clients benötigten. Hohe
Serververarbeitungszeiten deuten darauf hin, dass die Clients langsame Server kontaktieren.
Metrisch Beschreibung Verarbeitungszeit des Servers Die Zeit zwischen dem ExtraHop-System Erkennen des letzten Paket einer gesendeten AAA-Anfrage und des ersten Paket der entsprechende Antwort, wenn das Gerät als AAA-Client fungierte.
AAA-Servergruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt AAA Serververkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
AAA Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann AAA-Fehler aufgetreten sind und wie viele AAA-Antworten die Server
gesendet haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Server zu dem Zeitpunkt waren, als sie
die Fehler gemeldet haben.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie weiter unten im Abschnitt Metriken für Gruppen.
Metrisch Beschreibung Antworten Die Anzahl der AAA-Antworten, die gesendet wurden, als das Gerät fungierte als AAA-Server. Fehler Die Anzahl der AAA-Antwortfehler, die gesendet, als das Gerät als AAA-Server fungierte. - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele AAA-Antwortserver in der Gruppe gesendet haben und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der AAA-Antworten, die gesendet wurden, als das Gerät fungierte als AAA-Server. Fehler Die Anzahl der AAA-Antwortfehler, die gesendet, als das Gerät als AAA-Server fungierte.
AAA-Details für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (AAA-Server)
- Dieses Diagramm zeigt, welche AAA-Server in der Gruppe am aktivsten waren, indem die Gesamtzahl der AAA-Antworten, die die Gruppe vom Server gesendet hat, aufgeschlüsselt wird.
- Die besten Methoden
- Dieses Diagramm zeigt, welche AAA-Methoden auf Servern in der Gruppe am häufigsten aufgerufen wurden, indem die Gesamtzahl der Anfragen, die die Gruppe erhalten hat, nach Methode aufgeschlüsselt wird.
- Die häufigsten Fehlertypen
- Dieses Diagramm zeigt, welche AAA-Fehlertypen die Gruppen am häufigsten zurückgegeben haben, indem die Gesamtzahl der von der Gruppe gesendeten Antworten nach Fehlertyp aufgeschlüsselt wird.
AAA-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Anfragen und Antworten
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden Clients möglicherweise mehr Anfragen, als die Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der AAA-Anfragen, die eingegangen sind, als das Gerät fungierte als AAA-Server. Antworten Die Anzahl der AAA-Antworten, die gesendet wurden, als das Gerät fungierte als AAA-Server. Fehler Die Anzahl der AAA-Antwortfehler, die gesendet, als das Gerät als AAA-Server fungierte. Durchmesser-Anfrage Die Anzahl der Diameter-Anfragen, die waren empfangen, als das Gerät als AAA-Server fungierte. Diameter ist eine aktualisierte Version des RADIUS-AAA-Protokolls. RADIUS-Anfrage Die Anzahl der RADIUS-Anfragen, die der Gerät, das empfangen wurde, wenn es als AAA-Server fungiert. Aborte Die Anzahl der aufgetretenen abgebrochenen Sitzungen als das Gerät als AAA-Server fungierte. - Verarbeitungszeit des Servers
-
Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche Zeit, die die Server für die
Bearbeitung von Anfragen von Clients benötigten. Hohe Serververarbeitungszeiten deuten darauf hin, dass die Server in einer
Gruppe langsam sind.
Metrisch Beschreibung AAA-Client-Server-Verarbeitungszeit Die Zeit zwischen dem ExtraHop-System Erfassen des letzten Paket einer empfangenen AAA-Anfrage und des ersten Paket der entsprechende Antwort, wenn das Gerät als AAA-Server fungierte.
AJP
Das ExtraHop-System sammelt Metriken über das AJP (AJP) Aktivität. AJP ist ein Binärformat für die Kommunikation zwischen einem Apache-Webserver und einem Anwendungsserver.
| Hinweis: | Das ExtraHop-System enthält keine integrierten Metrikseiten für AJP. Sie können AJP-Metriken jedoch anzeigen, indem Sie sie zu einer benutzerdefinierten Seite hinzufügen oder Dashboard. |
AMF
Das ExtraHop-System sammelt Metriken zum Action Message Format (AMF) Protokollaktivität. AMF ist ein Format zur Verschlüsselung von Daten, die zwischen Adobe Flash-Clients und -Servern über HTTP-Anfragen und -Antworten übertragen werden.
AMF-Clientseite
Auf dieser Seite werden Metrikdiagramme von angezeigt AMF Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
AMF Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann AMF-Fehler aufgetreten sind und wie viele Antworten der AMF-Client
erhalten hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Client zu dem Zeitpunkt war, als er die Fehler
empfing.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als HTTP-AMF-Client agieren Fehler Die Anzahl der Antwortfehler, die der Gerät, das empfangen wurde, wenn es als HTTP-AMF-Client fungiert - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der AMF-Antworten, die der Client erhalten hat, und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als HTTP-AMF-Client agieren Fehler Die Anzahl der Antwortfehler, die der Gerät, das empfangen wurde, wenn es als HTTP-AMF-Client fungiert - Leistung (95. Perzentil)
-
Dieses Diagramm zeigt das
95. Perzentil der Timing-Metriken. Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer
vollständigen Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange der Client gebraucht hat, um
Anfragen an das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange Server gebraucht haben, um
die Anfragen zu verarbeiten; und die Antwortübertragungszeit zeigt, wie lange Server gebraucht haben, um
Antworten an das Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Übertragungszeit für AMF-Client-Anfragen Wenn das Gerät als HTTP-AMF fungiert client, die Zeit zwischen der Entdeckung des ersten und des letzten Paket durch das ExtraHop-System Paket gesendeter Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit AMF AMF-Client-Servers Wenn das Gerät als HTTP-AMF fungiert client, die Zeit zwischen der Entdeckung des letzten Pakets des gesendeten Pakets durch das ExtraHop-System Anfrage und das erste Paket der empfangenen Antwort. Übertragungszeit AMF AMF-Client-Antwort Wenn das Gerät als HTTP-AMF fungiert client, die Zeit zwischen der Entdeckung des ersten und des letzten Paket durch das ExtraHop-System Paket der empfangenen Antworten. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen AMF-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn ein Client langsam reagiert, können Sie
anhand von Leistungsübersichtsmetriken herausfinden, ob das Netzwerk oder die Server das Problem verursachen.
Diese Metriken zeigen das 95. Perzentil der Zeit, die Server für die Bearbeitung von
Anfragen vom Client benötigten, im Vergleich zur 95. Perzentilzeit, die Pakete aus diesen
Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten.
Hohe Serververarbeitungszeiten deuten darauf hin, dass der Client langsame Server kontaktiert. Hohe
TCP-Roundtrip-Zeiten deuten darauf hin, dass der Client über langsame
Netzwerke kommuniziert.
Verarbeitungszeit AMF AMF-Client-Servers Wenn das Gerät als HTTP-AMF fungiert client, die Zeit zwischen der Entdeckung des letzten Pakets des gesendeten Pakets durch das ExtraHop-System Anfrage und das erste Paket der empfangenen Antwort. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen AMF-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
AMF-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit AMF AMF-Client-Servers Wenn das Gerät als HTTP-AMF fungiert client, die Zeit zwischen der Entdeckung des letzten Pakets des gesendeten Pakets durch das ExtraHop-System Anfrage und das erste Paket der empfangenen Antwort. - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Bearbeitungszeit für den Client.
Metrisch Beschreibung Verarbeitungszeit AMF AMF-Client-Servers Wenn das Gerät als HTTP-AMF fungiert client, die Zeit zwischen der Entdeckung des letzten Pakets des gesendeten Pakets durch das ExtraHop-System Anfrage und das erste Paket der empfangenen Antwort. - Verteilung von Hin- und Rückflügen
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen AMF-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Hin- und Rückflugzeit für den Client.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen AMF-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Metrische AMF-Gesamtwerte
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, sendet der Client möglicherweise mehr
Anfragen, als die Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen
, ob das Problem am Netzwerk oder am Server liegt, überprüfen Sie RTOs und Zero Windows in der
Netzwerk-Daten
Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der AMF-Anfragen und -Antworten exakt gleich sein wird, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät gesendet hat, als fungiert als HTTP-AMF-Client Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als HTTP-AMF-Client agieren Antworten ohne Länge Die Anzahl der Antworten, die keine Länge hatten, die das Gerät empfangen hat, als es als HTTP-AMF-Client fungierte Fehler Die Anzahl der Antwortfehler, die der Gerät, das empfangen wurde, wenn es als HTTP-AMF-Client fungiert Anfragen ohne Länge Die Anzahl der Anfragen, die keine Länge hatten, die das Gerät gesendet hat, als es als HTTP-AMF-Client agiert - Größe der Anfrage und Antwort
- Dieses Diagramm zeigt die durchschnittliche Größe der Anfragen und Antworten.
Metrisch Beschreibung Größe der Anfrage Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät gesendet hat, als es als HTTP-AMF-Client agiert Größe der Antwort Die Verteilung der Größen (in Byte) von Antworten, die das Gerät erhalten hat, als es als HTTP-AMF-Client agiert
AMF-Serverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt AMF Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
AMF Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann AMF-Fehler aufgetreten sind und wie viele AMF-Antworten der Server
gesendet hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Server zu dem Zeitpunkt war, als er die Fehler
zurückgab.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als HTTP-AMF-Client agieren Fehler Die Anzahl der Antwortfehler, die der Gerät, das empfangen wurde, wenn es als HTTP-AMF-Client fungiert - Transaktionen insgesamt
-
Dieses Diagramm zeigt die Gesamtzahl der AMF-Antworten, die der Server gesendet hat, und wie viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als HTTP-AMF-Server Fehler Die Anzahl der Antwortfehler, die Gerät, das gesendet wird, wenn es als HTTP-AMF-Server fungiert - Leistungsübersicht (95. Perzentil)
-
Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken
. Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer vollständigen
Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange Clients gebraucht haben, um Anfragen an
das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange der Server gebraucht hat, um Anfragen zu verarbeiten;
und die Antwortübertragungszeit zeigt, wie lange der Server gebraucht hat, um Antworten an das
Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Übertragungszeit für AMF-Serveranfragen Wenn das Gerät als HTTP-AMF fungiert Server, die Zeit zwischen der Entdeckung des ersten und des letzten Paket durch das ExtraHop-System Paket eingegangener Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit AMF AMF-Servers Wenn das Gerät als HTTP-AMF fungiert Server, die Zeit zwischen der Entdeckung des letzten Paket durch das ExtraHop-System von empfangene Anfrage und erstes Paket der gesendeten Antwort. Übertragungszeit AMF AMF-Serverantwort Wenn das Gerät als HTTP-AMF fungiert Server, die Zeit zwischen der Entdeckung des ersten und des letzten Paket durch das ExtraHop-System Paket gesendeter Antworten. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen AMF-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Leistung (95. Perzentil)
-
Wenn ein Server langsam reagiert, können Sie
anhand von Leistungsübersichtsmetriken herausfinden, ob das
Problem vom Netzwerk oder vom Server verursacht wird. Die Leistungsübersichtsmetriken zeigen das 95. Perzentil der Zeit, die der
Server für die Verarbeitung von Anfragen von Clients benötigte, im Vergleich zur 95. Perzentilzeit, die
Pakete aus diesen Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten.
Hohe Serververarbeitungszeiten deuten darauf hin, dass der Server langsam ist.
Hohe RTTs weisen darauf hin, dass der Server über langsame Netzwerke kommuniziert.
Metrisch Beschreibung Verarbeitungszeit AMF AMF-Servers Wenn das Gerät als HTTP-AMF fungiert client, die Zeit zwischen der Entdeckung des letzten Pakets des gesendeten Pakets durch das ExtraHop-System Anfrage und das erste Paket der empfangenen Antwort. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen AMF-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
AMF-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit AMF AMF-Servers Wenn das Gerät als HTTP-AMF fungiert Server, die Zeit zwischen der Entdeckung des letzten Paket durch das ExtraHop-System von empfangene Anfrage und erstes Paket der gesendeten Antwort. - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Verarbeitungszeit für den Server.
Metrisch Beschreibung Verarbeitungszeit des Servers Wenn das Gerät als HTTP-AMF fungiert Server, die Zeit zwischen der Entdeckung des letzten Paket durch das ExtraHop-System von empfangene Anfrage und erstes Paket der gesendeten Antwort. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen AMF-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Roundtrip-Zeit für den Server.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen AMF-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Metrische AMF-Gesamtwerte
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr Anfragen, als der Server verarbeiten kann, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen , ob das Problem am Netzwerk oder am Server liegt, überprüfen Sie RTOs und Zero Windows in der Netzwerk-Daten Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der AMF-Anfragen und -Antworten exakt gleich sein wird, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät erhalten hat wenn er als HTTP-AMF-Server fungiert Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als HTTP-AMF-Server Antworten ohne Länge Die Anzahl der Antworten, die keine Länge hatten, die das Gerät gesendet hat, als es als HTTP-AMF-Server fungierte Fehler Die Anzahl der Antwortfehler, die Gerät, das gesendet wird, wenn es als HTTP-AMF-Server fungiert Anfragen ohne Länge Die Anzahl der Anfragen, die keine Länge hatten, die das Gerät empfangen hat, als es als HTTP-AMF-Server fungierte - Größe der Anfrage und Antwort
- Dieses Diagramm zeigt die durchschnittliche Größe der Anfragen und Antworten.
Metrisch Beschreibung Größe der Anfrage Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät empfangen hat, als es als HTTP-AMF-Server fungiert Größe der Antwort Die Verteilung der Größen (in Byte) von Antworten, die das Gerät gesendet hat, als es als HTTP-AMF-Server fungiert
AMF-Clientgruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt AMF Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
AMF Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann AMF-Fehler aufgetreten sind und wie viele Antworten die AMF-Clients
erhalten haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Kunden zu dem Zeitpunkt waren, als sie die Fehler
erhielten.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie weiter unten im Abschnitt Metriken für Gruppen.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als HTTP-AMF-Client agieren Fehler Die Anzahl der Antwortfehler, die der Gerät, das empfangen wurde, wenn es als HTTP-AMF-Client fungiert - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele AMF-Antworten die Kunden erhalten haben und wie viele dieser
Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als HTTP-AMF-Client agieren Fehler Die Anzahl der Antwortfehler, die der Gerät, das empfangen wurde, wenn es als HTTP-AMF-Client fungiert
AMF-Details für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (AMF-Kunden)
- Dieses Diagramm zeigt, welche AMF-Clients in der Gruppe am aktivsten waren, indem es die Gesamtzahl der AMF-Anfragen aufschlüsselt, die die Gruppe vom Client gesendet hat.
AMF-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Anfragen und Antworten
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden die Clients möglicherweise mehr Anfragen, als Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät gesendet hat, als fungiert als HTTP-AMF-Client Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als HTTP-AMF-Client agieren Antworten ohne Länge Die Anzahl der Antworten, die keine Länge hatten, die das Gerät empfangen hat, als es als HTTP-AMF-Client fungierte Fehler Die Anzahl der Antwortfehler, die der Gerät, das empfangen wurde, wenn es als HTTP-AMF-Client fungiert Anfragen ohne Länge Die Anzahl der Anfragen, die keine Länge hatten, die das Gerät gesendet hat, als es als HTTP-AMF-Client agiert - Verarbeitungszeit des Servers
-
Wenn sich eine Client-Gruppe langsam verhält, können Sie anhand der Serververarbeitungszeit herausfinden,
ob das Problem bei den Servern liegt. Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche
Zeit, die Server für die Bearbeitung von Anfragen von den Clients benötigten. Hohe
Serververarbeitungszeiten deuten darauf hin, dass die Clients langsame Server kontaktieren.
Verarbeitungszeit AMF AMF-Client-Servers Wenn das Gerät als HTTP-AMF fungiert client, die Zeit zwischen der Entdeckung des letzten Pakets des gesendeten Pakets durch das ExtraHop-System Anfrage und das erste Paket der empfangenen Antwort.
Seite AMF AMF-Servergruppe
Auf dieser Seite werden Metrikdiagramme von angezeigt AMF Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
AMF Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann AMF-Fehler aufgetreten sind und wie viele AMF-Antworten die Server
gesendet haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Server zu dem Zeitpunkt waren, als sie
die Fehler gemeldet haben.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie weiter unten im Abschnitt Metriken für Gruppen.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als HTTP-AMF-Client agieren Fehler Die Anzahl der Antwortfehler, die der Gerät, das empfangen wurde, wenn es als HTTP-AMF-Client fungiert - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele AMF-Antwortserver in der Gruppe gesendet haben und wie viele dieser
Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als HTTP-AMF-Client agieren Fehler Die Anzahl der Antwortfehler, die der Gerät, das empfangen wurde, wenn es als HTTP-AMF-Client fungiert
AMF-Details für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (AMF-Server)
- Dieses Diagramm zeigt, welche AMF-Server in der Gruppe am aktivsten waren, indem die Gesamtzahl der AMF-Antworten, die die Gruppe vom Server gesendet hat, aufgeschlüsselt wird.
AMF-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Anfragen und Antworten
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden Clients möglicherweise mehr Anfragen, als die Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät erhalten hat wenn er als HTTP-AMF-Server fungiert Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als HTTP-AMF-Server Antworten ohne Länge Die Anzahl der Antworten, die keine Länge hatten, die das Gerät gesendet hat, als es als HTTP-AMF-Server fungierte Fehler Die Anzahl der Antwortfehler, die Gerät, das gesendet wird, wenn es als HTTP-AMF-Server fungiert Anfragen ohne Länge Die Anzahl der Anfragen, die keine Länge hatten, die das Gerät empfangen hat, als es als HTTP-AMF-Server fungierte - Verarbeitungszeit des Servers
-
Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche Zeit, die die Server für die
Bearbeitung von Anfragen von Clients benötigten. Hohe Serververarbeitungszeiten deuten darauf hin, dass die Server in einer
Gruppe langsam sind.
Metrisch Beschreibung Verarbeitungszeit AMF AMF-Servers Wenn das Gerät als HTTP-AMF fungiert client, die Zeit zwischen der Entdeckung des letzten Pakets des gesendeten Pakets durch das ExtraHop-System Anfrage und das erste Paket der empfangenen Antwort.
CIFS
Das ExtraHop-System sammelt Messwerte über das Common Internet File System (CIFS) /SMB-Aktivität (Server Message Block). CIFS ist ein Protokoll auf Anwendungsebene, das Client-Zugriff auf Dateien in einem Netzwerk Attached Storage (NAS) -Repository ermöglicht, typischerweise in einer Windows-Umgebung. Das ExtraHop-System unterstützt SMB, SMB2 und SMB3.
| Wichtig: | Die Zugriffszeit ist die Zeit, die ein CIFS-Server benötigt, um einen angeforderten
Block zu empfangen. Es gibt keine Zugriffszeit für Operationen, die nicht auf tatsächliche Blockdaten innerhalb einer
Datei zugreifen. Die Verarbeitungszeit ist die Zeit, die ein CIFS-Server benötigt, um auf den vom Client
angeforderten Vorgang zu antworten, z. B. eine Anforderung zum Abrufen von Metadaten. Es gibt keine Zugriffszeiten für SMB2_CREATE. SMB2_CREATE erstellt eine Datei, auf die in der Antwort durch eine SMB2_FILEID verwiesen wird. Die referenzierten Dateiblöcke werden dann vom NAS-Speichergerät gelesen oder darauf geschrieben. Diese Datei-Lese- und Schreiboperationen werden als Zugriffszeiten berechnet. |
Überlegungen zur Sicherheit
- Die SMB/CIFS-Authentifizierung kann anfällig sein für Brute-Force, bei der es sich um eine Methode zum Erraten von Anmeldedaten handelt, indem zahlreiche Authentifizierungsanfragen mit unterschiedlichen Kombinationen aus Benutzername und Passwort eingereicht werden.
- Veraltete SMB-Dialekte wieSMB V1, haben bekannte Sicherheitslücken. Bekannte Ransomware-Malware wie Möchte weinen, nutzte SMBv1-Sicherheitslücken aus.
- SMB/CIFS kann anfällig sein fürRansomware Malware, die Tausende von Lese- und Schreibvorgängen über SMB/CIFS durchführt, um Dateien zu verschlüsseln, die auf Dateiservern im Netzwerk gespeichert sind.
- SMB/CIFS ist ein Fernwartung Protokoll, das ein Angreifer nutzen kann, um mit entfernten Geräten zu interagieren und sich seitlich im Netzwerk zu bewegen.
CIFS-Kundenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt CIFS Client-Verkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur CIFS-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
CIFS Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann SMB/CIFS-Fehler aufgetreten sind und wie viele Antworten der
SMB/CIFS-Client erhalten hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Client zu dem
Zeitpunkt war, als er die Fehler empfing.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie sich Details zu jedem Fehler anzeigen lassen, einschließlich des Fehlercodes. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von Anfragen zu Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Hinweis: Um eine Aufschlüsselung nach dem Fehlercode durchzuführen, klicken Sie auf Fehler und wähle Fehler aus der Speisekarte. Metrisch Beschreibung Antworten Die Anzahl der Antworten, die dieses SMB erhalten hat/ CIFS-Kunde Fehler Die Anzahl der eingegangenen Antworten SMB/CIFS-Clients, die einen anderen SMB-Statuscode als SUCCESS haben oder die einen Warnung. Eine hohe Anzahl von SMB/CIFS-Fehlern kann auf eine Beschädigung hinweisen Profil. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der SMB/CIFS-Antworten, die der Client erhalten hat, und
wie viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die dieses SMB erhalten hat/ CIFS-Kunde Fehler Die Anzahl der eingegangenen Antworten SMB/CIFS-Clients, die einen anderen SMB-Statuscode als SUCCESS haben oder die einen Warnung. Eine hohe Anzahl von SMB/CIFS-Fehlern kann auf eine Beschädigung hinweisen Profil. - Operationen
- Dieses Diagramm zeigt, wann der SMB/CIFS-Client Lese-, Schreib- und
Dateisysteminformationsanforderungsvorgänge ausgeführt hat.
Metrisch Beschreibung Liest Die Anzahl der gesendeten Lesevorgangsanfragen von diesem SMB- /CIFS-Client Schreibt Die Anzahl der gesendeten Schreiboperationsanforderungen von diesem SMB- /CIFS-Client Erzeugt Die Anzahl der Erstellungsvorgangsanfragen gesendet von diesem SMB/CIFS-Client Löscht Die Anzahl der Löschvorgangsanfragen gesendet von diesem SMB/CIFS-Client - Operationen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele Lese- und Schreibvorgänge der SMB/CIFS-Client
ausgeführt hat.
Metrisch Beschreibung Liest Die Anzahl der gesendeten Lesevorgangsanfragen von diesem SMB- /CIFS-Client Schreibt Die Anzahl der gesendeten Schreiboperationsanforderungen von diesem SMB- /CIFS-Client Erzeugt Die Anzahl der Erstellungsvorgangsanfragen gesendet von diesem SMB/CIFS-Client Löscht Die Anzahl der Löschvorgangsanfragen gesendet von diesem SMB/CIFS-Client - Leistung (95. Perzentil)
- Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken. Die Zugriffszeit gibt an, wie lange
Server gebraucht haben, um Lese- oder Schreibvorgänge zu verarbeiten, die auf Blockdaten innerhalb einer Datei zugegriffen haben.
Die Zugriffszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte
Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der
folgenden Abbildung dargestellt:
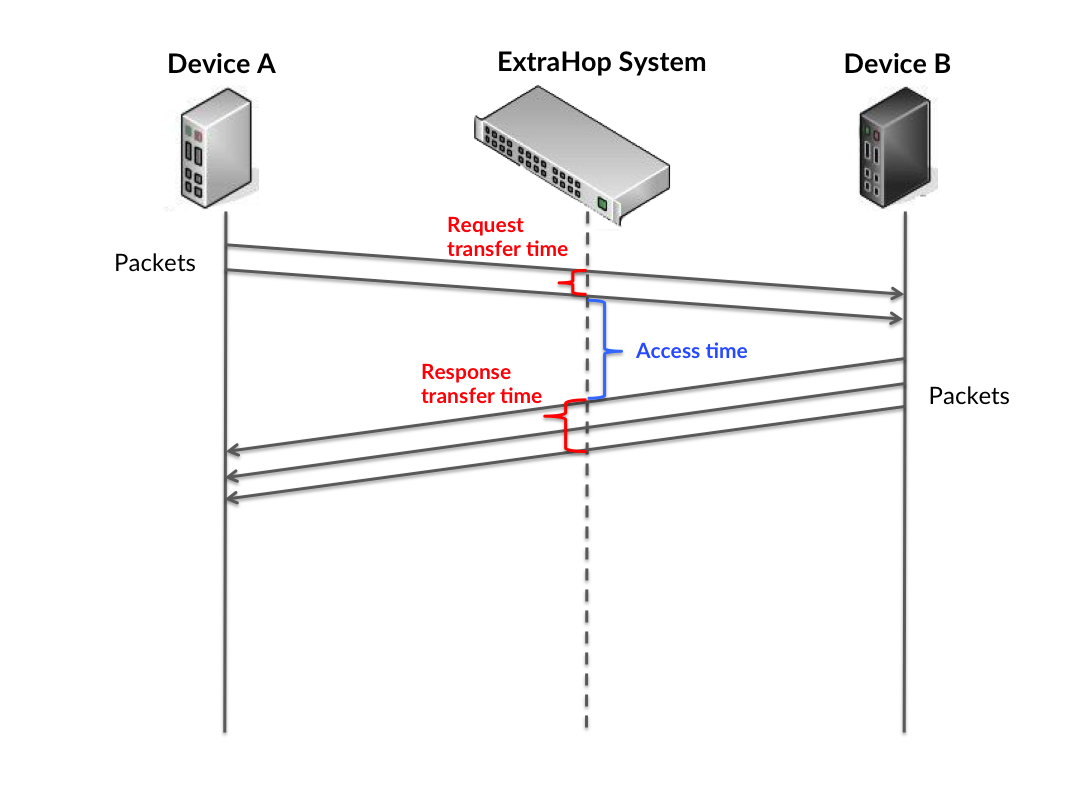
Es kann schwierig sein, allein anhand der Zugriffszeit zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Metrik allein ein unvollständiges Bild liefert. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Zugriffszeiten sehen, aber die RTT niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn jedoch sowohl die RTT- als auch die Zugriffszeiten hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Zugriffszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
RTT misst nur, wie lange es dauert, bis eine sofortige Bestätigung gesendet wird; es wartet nicht, bis alle Pakete zugestellt sind. Daher ist RTT ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Zugriffszeiten sehen, aber die TCP-RTT niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Überprüfen Sie das Netzwerk auf Latenzprobleme, wenn sowohl die TCP-RTT- als auch die Zugriffszeiten stimmen.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Die Zugriffszeit kann hoch sein, weil der Server lange gebraucht hat, um die Antwort zu übertragen (möglicherweise, weil die Antwort sehr umfangreich war). Die Zugriffszeit kann jedoch auch hoch sein, weil die Antwort lange Zeit benötigt hat, bis die Antwort im Netzwerk übertragen wurde (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung SMB-/CIFS-Client-Zugriffszeit Die Zeit zwischen dem ExtraHop-System Ermitteln des letzten Paket der von diesem SMB/CIFS-Client gesendeten Anfrage und zuerst Paket der empfangenen Antwort. Die Zugriffszeit wird nur für den ersten LESEVORGANG gemessen oder WRITE-Operation für jeden Fluss, um den Einfluss von Prefetching zu minimieren und Zwischenspeichern von Timing-Metriken Roundtrip-Zeit für SMB/CIFS-Kunden Die Zeit zwischen dem Senden eines SMB- und CIFS-Clients an Paket, das eine sofortige Bestätigung erforderte und wann der Client das erhielt Bestätigung. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Leistung (95. Perzentil)
- Wenn ein Client langsam reagiert, können Sie anhand von Leistungsübersichtsmetriken herausfinden
, ob das Netzwerk oder die Server das Problem verursachen. Die Leistungsübersichtsmetriken
zeigen die durchschnittliche Zeit, die Server für die Bearbeitung von Anfragen vom Client benötigten,
im Vergleich zur durchschnittlichen Zeit, die Pakete aus diesen Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten
. Hohe Serverzugriffszeiten deuten darauf hin, dass der Client
langsame Server kontaktiert. Hohe TCP-Roundtrip-Zeiten deuten darauf hin, dass der Client über langsame Netzwerke
kommuniziert.
Metrisch Beschreibung SMB-/CIFS-Client-Zugriffszeit Die Zeit zwischen dem ExtraHop-System Ermitteln des letzten Paket der von diesem SMB/CIFS-Client gesendeten Anfrage und zuerst Paket der empfangenen Antwort. Die Zugriffszeit wird nur für den ersten LESEVORGANG gemessen oder WRITE-Operation für jeden Fluss, um den Einfluss von Prefetching zu minimieren und Zwischenspeichern von Timing-Metriken Roundtrip-Zeit für SMB/CIFS-Kunden Die Zeit zwischen dem Senden eines SMB- und CIFS-Clients an Paket, das eine sofortige Bestätigung erforderte und wann der Client das erhielt Bestätigung. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz
CIFS-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche SMB-Methoden der Client am häufigsten aufgerufen hat, indem die Gesamtzahl der vom Client gesendeten Anfragen nach Methode aufgeschlüsselt wird.
- Versionen
- Dieses Diagramm zeigt, welche SMB/CIFS-Versionen die meisten Antworten vom Client erhalten haben, indem die Gesamtzahl der Antworten, die der Client erhalten hat, aufgeschlüsselt nach Version.
- Die besten Nutzer
- Dieses Diagramm zeigt, welche Benutzer auf dem Client am aktivsten waren, indem die Gesamtzahl der vom Client gesendeten SMB/CIFS-Anfragen nach Benutzern aufgeschlüsselt wird.
- Die häufigsten Dateien
- Dieses Diagramm zeigt, auf welche Dateien der Client am häufigsten zugegriffen hat, indem die Gesamtzahl der Antworten, die der Client erhalten hat, nach Dateipfad aufgeschlüsselt wird.
CIFS-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Zugriffszeit
- In diesem Diagramm werden die Zugriffszeiten in einem Histogramm dargestellt, um die häufigsten
Zugriffszeiten anzuzeigen.
Metrisch Beschreibung SMB-/CIFS-Client-Zugriffszeit Die Zeit zwischen dem ExtraHop-System Ermitteln des letzten Paket der von diesem SMB/CIFS-Client gesendeten Anfrage und zuerst Paket der empfangenen Antwort. Die Zugriffszeit wird nur für den ersten LESEVORGANG gemessen oder WRITE-Operation für jeden Fluss, um den Einfluss von Prefetching zu minimieren und Zwischenspeichern von Timing-Metriken - Zeit des Zugriffs
- Dieses Diagramm zeigt die durchschnittliche Zugriffszeit für den Client.
Metrisch Beschreibung SMB-/CIFS-Client-Zugriffszeit Die Zeit zwischen dem ExtraHop-System Ermitteln des letzten Paket der von diesem SMB/CIFS-Client gesendeten Anfrage und zuerst Paket der empfangenen Antwort. Die Zugriffszeit wird nur für den ersten LESEVORGANG gemessen oder WRITE-Operation für jeden Fluss, um den Einfluss von Prefetching zu minimieren und Zwischenspeichern von Timing-Metriken
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Metrische CIFS-Summen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Anfragen und Antworten
- Dieses Diagramm zeigt Ihnen, wie viele Operationen der SMB/CIFS-Client ausgeführt hat.
Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die von diesem SMB/CIFS gesendet wurden Client. Antworten Die Anzahl der Antworten, die dieses SMB erhalten hat/ CIFS-Kunde Anfragen nach Dateisysteminformationen Die Anzahl der Dateisystem-Metadatenabfragen gesendet von diesem SMB/CIFS-Client Warnungen Die Anzahl der eingegangenen Antworten SMB- /CIFS-Client mit einem SMB-Statuscode, der auf eine Warnung hinweist, z. B. STATUS_BUFFER_TOO_SMALL und STATUS_NO_MORE_FILES Erzeugt Die Anzahl der Erstellungsvorgangsanfragen gesendet von diesem SMB/CIFS-Client Fehler Die Anzahl der eingegangenen Antworten SMB/CIFS-Clients, die einen anderen SMB-Statuscode als SUCCESS haben oder die einen Warnung. Eine hohe Anzahl von SMB/CIFS-Fehlern kann auf eine Beschädigung hinweisen Profil. Liest Die Anzahl der gesendeten Lesevorgangsanfragen von diesem SMB- /CIFS-Client Schreibt Die Anzahl der gesendeten Schreiboperationsanforderungen von diesem SMB- /CIFS-Client Umbenennungen Die Anzahl der Anfragen für Umbenennungsvorgänge gesendet von diesem SMB//CIFS-Client Löscht Die Anzahl der Löschvorgangsanfragen gesendet von diesem SMB/CIFS-Client Schleusen Die Anzahl der Sperroperationsanfragen produziert von diesem SMB/CIFS-Client - Größe der Anfrage und Antwort
- Dieses Diagramm zeigt die durchschnittliche Größe der Anfragen und Antworten.
Metrisch Beschreibung Größe der CIFS-Client-Anfrage Die Verteilung der Größen (in Byte) von Anfragen, die von diesem SMB/CIFS-Client gesendet wurden Größe der CIFS-Client-Antwort Die Verteilung der Größen (in Byte) von Antworten, die empfangen werden, wenn das Gerät als SMB/CIFS-Client fungiert
CIFS-Serverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt CIFS Serververkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur CIFS-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
CIFS Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann SMB/CIFS-Fehler aufgetreten sind und wie viele SMB/CIFS-Antworten
der Server gesendet hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Server zu dem Zeitpunkt war, als
er die Fehler zurückgab.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie sich Details zu jedem Fehler anzeigen lassen, einschließlich des Fehlercodes. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von Anfragen zu Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Hinweis: Um eine Aufschlüsselung nach dem Fehlercode durchzuführen, klicken Sie auf Fehler und wähle Fehler aus der Speisekarte. Metrisch Beschreibung Antworten Die Anzahl der von diesem SMB/CIFS gesendeten Antworten Server. Fehler Die Anzahl der von diesem gesendeten Antworten SMB/CIFS-Server, die einen anderen SMB-Statuscode als SUCCESS haben oder die einen Warnung. Eine hohe Anzahl von SMB/CIFS-Fehlern kann auf eine Beschädigung hinweisen Profil. - Transaktionen insgesamt
-
Dieses Diagramm zeigt die Gesamtzahl der CIFS-Antworten, die der Server gesendet hat, und wie viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der von diesem SMB/CIFS gesendeten Antworten Server. Fehler Die Anzahl der von diesem gesendeten Antworten SMB/CIFS-Server, die einen anderen SMB-Statuscode als SUCCESS haben oder die einen Warnung. Eine hohe Anzahl von SMB/CIFS-Fehlern kann auf eine Beschädigung hinweisen Profil. - Operationen
- Dieses Diagramm zeigt, wann die Lese-, Schreib- und
Dateisysteminformationsanforderungsvorgänge auf dem Server ausgeführt wurden.
Metrisch Beschreibung Liest Die Anzahl der Anfragen für Lesevorgänge von diesem SMB/CIFS-Server empfangen Schreibt Die Anzahl der Schreiboperationsanforderungen von diesem SMB/CIFS-Server empfangen Erzeugt Die Anzahl der Erstellungsvorgangsanfragen von diesem SMB/CIFS-Server empfangen Löscht Die Anzahl der Löschvorgangsanfragen gesendet von diesem SMB/CIFS-Server - Operationen insgesamt
- Dieses Diagramm zeigt, wie viele Lese- und Schreibvorgänge auf dem
Server ausgeführt wurden.
Metrisch Beschreibung Liest Die Anzahl der Anfragen für Lesevorgänge von diesem SMB/CIFS-Server empfangen Schreibt Die Anzahl der Schreiboperationsanforderungen von diesem SMB/CIFS-Server empfangen Erzeugt Die Anzahl der Erstellungsvorgangsanfragen von diesem SMB/CIFS-Server empfangen Löscht Die Anzahl der Löschvorgangsanfragen gesendet von diesem SMB/CIFS-Server - Leistung (95. Perzentil)
- Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken. Die Zugriffszeit gibt an, wie lange
Server gebraucht haben, um Lese- oder Schreibvorgänge zu verarbeiten, die auf Blockdaten innerhalb einer Datei zugegriffen haben.
Die Zugriffszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte
Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der
folgenden Abbildung dargestellt:
Es kann schwierig sein, allein anhand der Zugriffszeit zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Metrik allein ein unvollständiges Bild liefert. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Zugriffszeiten sehen, aber die RTT niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn jedoch sowohl die RTT- als auch die Zugriffszeiten hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Zugriffszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
RTT misst nur, wie lange es dauert, bis eine sofortige Bestätigung gesendet wird; es wartet nicht, bis alle Pakete zugestellt sind. Daher ist RTT ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Zugriffszeiten sehen, aber die TCP-RTT niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Überprüfen Sie das Netzwerk auf Latenzprobleme, wenn sowohl die TCP-RTT- als auch die Zugriffszeiten stimmen.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Die Zugriffszeit kann hoch sein, weil der Server lange gebraucht hat, um die Antwort zu übertragen (möglicherweise, weil die Antwort sehr umfangreich war). Die Zugriffszeit kann jedoch auch hoch sein, weil die Antwort lange Zeit benötigt hat, bis die Antwort im Netzwerk übertragen wurde (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung SMB-/CIFS-Serverzugriffszeit Die Zeit zwischen dem ExtraHop-System Ermitteln des letzten Paket der von diesem SMB/CIFS-Server empfangenen Anfrage und erstes Paket der Antwort. Die Zugriffszeit wird nur für den ersten LESEVORGANG gemessen oder WRITE-Operation für jeden Fluss, um den Einfluss von Prefetching zu minimieren und Zwischenspeichern von Timing-Metriken Roundtrip-Zeit für SMB-/CIFS-Server Die Zeit zwischen dem Senden eines SMB- und CIFS-Servers Paket, das eine sofortige Bestätigung erforderte und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
- Wenn ein Server langsam reagiert, können Sie anhand von Leistungsübersichtsmetriken herausfinden
, ob das Problem vom Netzwerk oder vom Server verursacht wird. Die Leistungsübersichtsmetriken
zeigen die durchschnittliche Zeit, die der Server für die Bearbeitung von Anfragen von Clients benötigte,
im Vergleich zur durchschnittlichen Zeit, die Pakete aus diesen Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten
. Hohe Serverzugriffszeiten deuten darauf hin, dass der Server langsam
ist. Hohe RTTs weisen darauf hin, dass der Server über langsame Netzwerke kommuniziert.
Metrisch Beschreibung SMB-/CIFS-Serverzugriffszeit Die Zeit zwischen dem ExtraHop-System Ermitteln des letzten Paket der von diesem SMB/CIFS-Server empfangenen Anfrage und erstes Paket der Antwort. Die Zugriffszeit wird nur für den ersten LESEVORGANG gemessen oder WRITE-Operation für jeden Fluss, um den Einfluss von Prefetching zu minimieren und Zwischenspeichern von Timing-Metriken Roundtrip-Zeit für SMB-/CIFS-Server Die Zeit zwischen dem Senden eines SMB- und CIFS-Servers Paket, das eine sofortige Bestätigung erforderte und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
CIFS-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche SMB/CIFS-Methoden auf dem Server am häufigsten aufgerufen wurden, indem die Gesamtzahl der Anfragen, die der Server erhalten hat, nach Methode aufgeteilt wird.
- Versionen
- Dieses Diagramm zeigt, welche SMB/CIFS-Versionen die meisten vom Server gesendeten Antworten hatten, indem die Gesamtzahl der vom Server gesendeten Antworten, aufgelistet nach Version, aufgeschlüsselt wird.
- Die besten Nutzer
- Dieses Diagramm zeigt, welche Benutzer auf dem Server am aktivsten waren, indem es die Gesamtzahl der SMB-/CIFS-Anfragen aufschlüsselt, die vom Benutzer an den Server gesendet wurden.
- Die häufigsten Dateien
- Dieses Diagramm zeigt, auf welche Dateien auf dem Server am häufigsten zugegriffen wurde, indem die Gesamtzahl der vom Server gesendeten Antworten nach Dateipfad aufgeschlüsselt wird.
CIFS-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Zugriffszeit
- In diesem Diagramm werden die Zugriffszeiten in einem Histogramm dargestellt, um die häufigsten
Zugriffszeiten anzuzeigen.
Metrisch Beschreibung SMB-/CIFS-Serverzugriffszeit Die Zeit zwischen dem ExtraHop-System Ermitteln des letzten Paket der von diesem SMB/CIFS-Server empfangenen Anfrage und erstes Paket der Antwort. Die Zugriffszeit wird nur für den ersten LESEVORGANG gemessen oder WRITE-Operation für jeden Fluss, um den Einfluss von Prefetching zu minimieren und Zwischenspeichern von Timing-Metriken - Zeit des Zugriffs
- Dieses Diagramm zeigt die durchschnittliche Zugriffszeit für den Client.
Metrisch Beschreibung CIFS-Serverzugriffszeit Die Zeit zwischen dem ExtraHop-System Ermitteln des letzten Paket der von diesem SMB/CIFS-Server empfangenen Anfrage und erstes Paket der Antwort. Die Zugriffszeit wird nur für den ersten LESEVORGANG gemessen oder WRITE-Operation für jeden Fluss, um den Einfluss von Prefetching zu minimieren und Zwischenspeichern von Timing-Metriken
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Metrische CIFS-Summen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
- Dieses Diagramm zeigt, wie viele Operationen auf dem
SMB/CIFS-Server ausgeführt wurden.
Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die von diesem SMB eingegangen sind/ CIFS-Server Antworten Die Anzahl der von diesem SMB/CIFS gesendeten Antworten Server. Anfragen nach Dateisysteminformationen Die Anzahl der Dateisystem-Metadatenabfragen von diesem SMB/CIFS-Server empfangen Warnungen Die Anzahl der von diesem SMB gesendeten Antworten /CIFS-Server mit einem SMB-Statuscode, der eine Warnung anzeigt, wie STATUS_BUFFER_TOO_SMALL und STATUS_NO_MORE_FILES Erzeugt Die Anzahl der Erstellungsvorgangsanfragen von diesem SMB/CIFS-Server empfangen Fehler Die Anzahl der von diesem gesendeten Antworten SMB/CIFS-Server, die einen anderen SMB-Statuscode als SUCCESS haben oder die einen Warnung. Eine hohe Anzahl von SMB/CIFS-Fehlern kann auf eine Beschädigung hinweisen Profil. Liest Die Anzahl der Anfragen für Lesevorgänge von diesem SMB/CIFS-Server empfangen Schreibt Die Anzahl der Schreiboperationsanforderungen von diesem SMB/CIFS-Server empfangen Umbenennungen Die Anzahl der Anfragen für Umbenennungsvorgänge von diesem SMB/CIFS-Server empfangen Löscht Die Anzahl der Löschvorgangsanfragen gesendet von diesem SMB/CIFS-Server Schleusen Die Anzahl der Sperroperationsanfragen von diesem SMB/CIFS-Server empfangen - Größe der Anfrage und Antwort
- Dieses Diagramm zeigt die durchschnittliche Größe der Anfragen und Antworten.
Metrisch Beschreibung Größe der SMB-/CIFS-Serveranforderung Die Verteilung der Größen (in Byte) von Anfragen, die von diesem SMB/CIFS-Server Größe der SMB-/CIFS-Serverantwortlichkeit Die Verteilung der Größen (in Byte) von Antworten, die von diesem SMB/CIFS-Server gesendet wurden
CIFS-Kundengruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt CIFS Client-Verkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur CIFS-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
CIFS Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann SMB/CIFS-Fehler aufgetreten sind und wie viele Antworten die
SMB/CIFS-Clients erhalten haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Kunden zu
dem Zeitpunkt waren, als sie die Fehler erhielten.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie weiter unten im Abschnitt Metriken für Gruppen.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die dieses SMB erhalten hat/ CIFS-Kunde Fehler Die Anzahl der eingegangenen Antworten SMB/CIFS-Clients, die einen anderen SMB-Statuscode als SUCCESS haben oder die einen Warnung. Eine hohe Anzahl von SMB/CIFS-Fehlern kann auf eine Beschädigung hinweisen Profil. - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele SMB/CIFS-Antworten die Kunden erhalten haben und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die dieses SMB erhalten hat/ CIFS-Kunde Fehler Die Anzahl der eingegangenen Antworten SMB/CIFS-Clients, die einen anderen SMB-Statuscode als SUCCESS haben oder die einen Warnung. Eine hohe Anzahl von SMB/CIFS-Fehlern kann auf eine Beschädigung hinweisen Profil.
CIFS-Details für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (CIFS-Kunden)
- Dieses Diagramm zeigt, welche SMB/CIFS-Clients in der Gruppe am aktivsten waren, indem die Gesamtzahl der SMB/CIFS-Anfragen, die die Gruppe vom Client gesendet hat, aufgeschlüsselt wird.
- Die besten Methoden
- Dieses Diagramm zeigt, welche SMB/CIFS-Methoden die Gruppe am häufigsten aufgerufen hat, indem die Gesamtzahl der von der Gruppe gesendeten Anfragen nach Methode aufgeschlüsselt wird.
- Versionen
- Dieses Diagramm zeigt, welche SMB/CIFS-Versionen die meisten Antworten von Kunden in der Gruppe erhielten, indem die Gesamtzahl der Antworten, die die Gruppe erhalten hat, aufgeschlüsselt nach Version, aufgeschlüsselt wird.
- Die besten Nutzer
- Dieses Diagramm zeigt, welche SMB/CIFS-Benutzer in der Gruppe am aktivsten waren, indem die Gesamtzahl der SMB/CIFS-Antworten, die die Gruppe nach Benutzern erhalten hat, aufgeschlüsselt wird.
CIFS-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden die Clients möglicherweise mehr Anfragen, als Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die von diesem SMB/CIFS gesendet wurden Client. Antworten Die Anzahl der Antworten, die dieses SMB erhalten hat/ CIFS-Kunde Anfragen nach Dateisysteminformationen Die Anzahl der Dateisystem-Metadatenabfragen gesendet von diesem SMB/CIFS-Client Warnungen Die Anzahl der eingegangenen Antworten SMB- /CIFS-Client mit einem SMB-Statuscode, der auf eine Warnung hinweist, z. B. STATUS_BUFFER_TOO_SMALL und STATUS_NO_MORE_FILES Erzeugt Die Anzahl der Erstellungsvorgangsanfragen gesendet von diesem SMB/CIFS-Client Fehler Die Anzahl der eingegangenen Antworten SMB/CIFS-Clients, die einen anderen SMB-Statuscode als SUCCESS haben oder die einen Warnung. Eine hohe Anzahl von SMB/CIFS-Fehlern kann auf eine Beschädigung hinweisen Profil. Liest Die Anzahl der gesendeten Lesevorgangsanfragen von diesem SMB- /CIFS-Client Schreibt Die Anzahl der gesendeten Schreiboperationsanforderungen von diesem SMB- /CIFS-Client Umbenennungen Die Anzahl der Anfragen für Umbenennungsvorgänge gesendet von diesem SMB//CIFS-Client Löscht Die Anzahl der Löschvorgangsanfragen gesendet von diesem SMB/CIFS-Client Schleusen Die Anzahl der Sperroperationsanfragen produziert von diesem SMB/CIFS-Client - Zeit des Zugriffs
- Wenn sich eine Client-Gruppe langsam verhält, können Sie anhand der Zugriffszeit herausfinden, ob das
Problem bei den Servern liegt. Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche
Zeit, die Server für die Bearbeitung von Anfragen von den Clients benötigten. Hohe Zugriffszeiten deuten darauf hin, dass
die Clients langsame Server kontaktieren.
Metrisch Beschreibung SMB-/CIFS-Serverzugriffszeit Die Zeit zwischen dem ExtraHop-System Ermitteln des letzten Paket der von diesem SMB/CIFS-Client gesendeten Anfrage und zuerst Paket der empfangenen Antwort. Die Zugriffszeit wird nur für den ersten LESEVORGANG gemessen oder WRITE-Operation für jeden Fluss, um den Einfluss von Prefetching zu minimieren und Zwischenspeichern von Timing-Metriken
CIFS-Servergruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt CIFS Serververkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur CIFS-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
CIFS Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann SMB/CIFS-Fehler aufgetreten sind und wie viele SMB/CIFS-Antworten die
Server gesendet haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Server zu dem
Zeitpunkt waren, als sie die Fehler gemeldet haben.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie weiter unten im Abschnitt Metriken für Gruppen.
Metrisch Beschreibung Antworten Die Anzahl der von diesem SMB/CIFS gesendeten Antworten Server. Fehler Die Anzahl der von diesem gesendeten Antworten SMB/CIFS-Server, die einen anderen SMB-Statuscode als SUCCESS haben oder die einen Warnung. Eine hohe Anzahl von SMB/CIFS-Fehlern kann auf eine Beschädigung hinweisen Profil. - Transaktionen insgesamt
- Dieses Diagramm zeigt, wie viele CIFS-Antwortserver in der Gruppe gesendet haben und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der von diesem SMB/CIFS gesendeten Antworten Server. Fehler Die Anzahl der von diesem gesendeten Antworten SMB/CIFS-Server, die einen anderen SMB-Statuscode als SUCCESS haben oder die einen Warnung. Eine hohe Anzahl von SMB/CIFS-Fehlern kann auf eine Beschädigung hinweisen Profil.
CIFS-Details für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (CIFS-Server)
- Dieses Diagramm zeigt, welche SMB-/CIFS-Server in der Gruppe am aktivsten waren, indem die Gesamtzahl der CIFS-Antworten, die die Gruppe vom Server gesendet hat, aufgeschlüsselt wird.
- Die besten Methoden
- Dieses Diagramm zeigt, welche SMB/CIFS-Methoden auf Servern in der Gruppe am häufigsten aufgerufen wurden, indem die Gesamtzahl der Anfragen, die die Gruppe erhalten hat, nach Methode aufgeschlüsselt wird.
- Versionen
- Dieses Diagramm zeigt, bei welchen SMB/CIFS-Versionen die meisten Antworten von Servern in der Gruppe gesendet wurden, indem die Gesamtzahl der von der Gruppe gesendeten Antworten aufgeschlüsselt wird, aufgeschlüsselt nach Version.
- Die besten Nutzer
- Dieses Diagramm zeigt, welche SMB/CIFS-Benutzer in der Gruppe am aktivsten waren, indem es die Gesamtzahl der SMB/CIFS-Antworten aufschlüsselt, die die Gruppe nach Benutzern gesendet hat.
CIFS-Metriken in der Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden Clients möglicherweise mehr Anfragen, als die Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die von diesem SMB eingegangen sind/ CIFS-Server Antworten Die Anzahl der von diesem SMB/CIFS gesendeten Antworten Server. Anfragen nach Dateisysteminformationen Die Anzahl der Dateisystem-Metadatenabfragen von diesem SMB/CIFS-Server empfangen Warnungen Die Anzahl der von diesem SMB gesendeten Antworten /CIFS-Server mit einem SMB-Statuscode, der eine Warnung anzeigt, wie STATUS_BUFFER_TOO_SMALL und STATUS_NO_MORE_FILES Erzeugt Die Anzahl der Erstellungsvorgangsanfragen von diesem SMB/CIFS-Server empfangen Fehler Die Anzahl der von diesem gesendeten Antworten SMB/CIFS-Server, die einen anderen SMB-Statuscode als SUCCESS haben oder die einen Warnung. Eine hohe Anzahl von SMB/CIFS-Fehlern kann auf eine Beschädigung hinweisen Profil. Liest Die Anzahl der Anfragen für Lesevorgänge von diesem SMB/CIFS-Server empfangen Schreibt Die Anzahl der Schreiboperationsanforderungen von diesem SMB/CIFS-Server empfangen Umbenennungen Die Anzahl der Anfragen für Umbenennungsvorgänge von diesem SMB/CIFS-Server empfangen Löscht Die Anzahl der Löschvorgangsanfragen gesendet von diesem SMB/CIFS-Server Schleusen Die Anzahl der Sperroperationsanfragen von diesem SMB/CIFS-Server empfangen - Zeit des Zugriffs
- Wenn sich eine Servergruppe langsam verhält, können Sie anhand des Diagramms „Zugriffszeit" herausfinden
, ob das Problem bei den Servern liegt. Das Diagramm „Zugriffszeit" zeigt die durchschnittliche
Zeit, die die Server für die Bearbeitung von Anfragen von Clients benötigten. Hohe Serverzugriffszeiten
deuten darauf hin, dass die Server langsam sind.
Metrisch Beschreibung SMB-/CIFS-Serverzugriffszeit Die Zeit zwischen dem ExtraHop-System Ermitteln des letzten Paket der von diesem SMB/CIFS-Server empfangenen Anfrage und erstes Paket der Antwort. Die Zugriffszeit wird nur für den ersten LESEVORGANG gemessen oder WRITE-Operation für jeden Fluss, um den Einfluss von Prefetching zu minimieren und Zwischenspeichern von Timing-Metriken
Datenbank
Das ExtraHop-System sammelt Metriken über Datenbank Aktivität. Relationale Datenbanken speichern, abrufen und verwalten strukturierte Informationen über eine Datenbankmanagementsystem-Sprache (DBMS). Aktivitäten für die folgenden Datenbanksprachen werden aggregiert und unter Datenbankmetriken im ExtraHop-System angezeigt:
- IBM DB2
- IBM Informix
- Microsoft SQL Server
- MySQL
- Orakel
- PostgreSQL
- Sybase ASE
- Sybase IQ
| Hinweis: | Das ExtraHop-System überwacht auch MongoDB Datenbankaktivität, die anhand eines separaten Satzes von Metriken angezeigt wird, die spezifisch sind für MongoDB. |
Erfahren Sie mehr, indem Sie die Quick Peek zur Datenbank Ausbildung.
In den folgenden Abschnitten werden die wichtigsten Metriken beschrieben, die Sie bei Datenbankproblemen untersuchen sollten.
Fehler
Datenbankfehler treten auf, wenn eine Datenbankanforderung vom Server nicht abgeschlossen werden kann. Fehler können auf ein geringfügiges Problem hinweisen, z. B. auf einen einzelnen Anmeldefehler, oder auf ein schwerwiegenderes Problem, z. B. einen überlasteten Datenbankserver.Bei der Untersuchung von Datenbankfehlern können Sie zunächst die Gesamtzahl der Fehler in Ihrer Umgebung auf der Seite. Sie können Details zu jedem Fehler anzeigen, einschließlich der von der Datenbank gemeldeten Rohfehlermeldung, indem Sie auf das Fehlersymbol klicken.
Auf dem Auf dieser Seite können Sie die Metriken nach Datenbankserver aufteilen, indem Sie den Mauszeiger über den Wert Antwortfehler bewegen und auf Von Server IP. Sie können dann nach der Anzahl der Fehler sortieren. Wenn ein Datenbankserver eine große Anzahl von Fehlern zurückgibt, können Sie auf den Servernamen und dann auf das Fehlersymbol klicken, um die Gesamtzahl der Fehler für diesen Server anzuzeigen. Wenn jedoch kein Server eine große Anzahl von Fehlern verursacht, ist das Problem möglicherweise komplexer, und Sie sollten untersuchen, welche Methoden für jede Datenbank aufgerufen wurden.
Methoden
Sie können sehen, welche Methoden für Datenbanken in Ihrer Umgebung aufgerufen wurden. Schlecht formatierte Datenbankaufrufe können zu Leistungsproblemen führen, auch wenn keine Fehler vorliegen. Um alle Methoden zu sehen, die in Ihrer Umgebung über ein bestimmtes Zeitintervall aufgerufen wurden, gehen Sie zu Seite und Klick Methoden.Wenn eine Methode für eine Tabelle aufgerufen wird, wird der Tabellenname hinter einem @ Symbol. Zum Beispiel CREATE @ Configuration zeigt Metriken darüber an, wie oft die CREATE-Methode für eine Tabelle mit dem Namen Configuration aufgerufen wurde. Methoden können nach der Verarbeitungszeit sortiert werden. Dies ist die Zeitspanne zwischen dem Empfang einer Anfrage durch einen Server und dem Senden einer Antwort durch den Server. Lange Verarbeitungszeiten können darauf hindeuten, dass die Datenbank schlecht optimiert ist oder dass Anweisungen schlecht formatiert sind.
Benutzerdefinierte Metriken und Datensätze (erfordert einen Recordstore)
Wenn die Verarbeitungszeit für eine Datenbankmethode kontinuierlich lang ist, sollten Sie das genauer untersuchen, indem Sie die Roh-SQL-Anweisungen sammeln, die die Methode enthalten. Sie können unformatierte SQL-Anweisungen aufzeichnen und anzeigen, indem Sie eine benutzerdefinierte Metrik erstellen oder Datensätze über einen Auslöser generieren. Mit einer benutzerdefinierten Metrik können Sie eine grafische Darstellung der Informationen anzeigen. Sie können beispielsweise ein Diagramm erstellen, in dem dargestellt wird, wie viele langsame Datenbankanfragen im Laufe der Zeit aufgetreten sind, und jede Antwort nach der SQL-Anweisung aufschlüsseln. Mithilfe von Datensätzen können Sie einzelne Datensätze zu jedem Ereignis anzeigen. Sie können beispielsweise genau sehen, wie viel Zeit der Server benötigt hat, um auf jede SQL-Anweisung zu antworten.Der folgende Auslöser wird ausgeführt, wenn ein Datenbankantwortereignis eintritt. Wenn ein Datenbankserver mehr als 100 Millisekunden benötigt, um auf eine SELECT-Anfrage in der Konfigurationstabelle zu antworten, zeichnet der Auslöser die SQL-Anweisung der Anforderung in einer benutzerdefinierten Metrik auf. Der Auslöser zeichnet auch die Gesamtzahl der Datenbankanfragen auf, für deren Beantwortung der Server mehr als 100 Millisekunden gebraucht hat.
// Event: DB_RESPONSE
if (DB.processingTime > 100 && DB.method == "SELECT" && DB.table == "Configuration") {
// Record a custom metric.
Device.metricAddCount('slow_performers', 1);
Device.metricAddDetailCount('slow_performers_by_statement', DB.statement, 1);
}
Der nächste Auslöser generiert ähnliche Informationen, jedoch in Form eines Datensatz für alle Datenbankantworten. Die Datensätze enthalten die Verarbeitungszeit, die Methode, den Tabellennamen und die SQL-Anweisung für jede Antwort. Nachdem die Datensätze gesammelt wurden, können Sie die SQL-Anweisungen für alle SELECT-Anfragen in der Konfigurationstabelle anzeigen, für deren Beantwortung der Server mehr als 100 Millisekunden gebraucht hat.
// Event: DB_RESPONSE DB.commitRecord()
Nachdem Sie einen Auslöser erstellt haben, müssen Sie ihn den Geräten zuweisen, die Sie überwachen möchten. Wenn Sie eine benutzerdefinierte Metrik erstellen, müssen Sie eine erstellen Dashboard um die benutzerdefinierte Metrik anzuzeigen.
- Weitere Hinweise zu Triggern finden Sie unter Auslöser.
- Weitere Informationen zu Dashboards finden Sie unter Armaturenbretter.
- Weitere Informationen zu Datensätzen finden Sie unter Rekorde.
Überlegungen zur Sicherheit
- Die Datenbankauthentifizierung kann anfällig sein für Brute-Force, bei der es sich um eine Methode zum Erraten von Anmeldedaten handelt, indem zahlreiche Authentifizierungsanfragen mit unterschiedlichen Kombinationen aus Benutzername und Passwort eingereicht werden.
- Webanwendungen, die anfällig sind für SQL-Injektion (SQLi) kann eine Datenbank senden bösartiger SQL-Code das in ein legitimes Dateneingabefeld (z. B. ein Passwortfeld) eingefügt wird.
- Datenbankabfragen können die Aufzählung ermöglichen. Dabei handelt es sich um eine Aufklärungstechnik, die einem Angreifer hilft , Informationen zu sammeln.
- Angriffe auf Datenbankübernahmen zielen auf Datenbankmanagementsysteme (DBMS) ab, die mit Datei- und Betriebssystemen auf einem Server interagieren. Ein Angreifer sendet bösartige Befehle ( z. B. xp_cmdshell-Abfragen für Microsoft SQL Server) in Abfragen an das DBMS.
Datenbankanwendungsseite
Auf dieser Seite werden Metrikdiagramme von angezeigt Datenbank Verkehr, der mit einem Anwendungscontainer in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur Datenbanksicherheit
- Erfahre mehr über mit Metriken arbeiten.
Datenbank Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann Datenbankfehler und -antworten mit der
Anwendung verknüpft waren. Anhand dieser Informationen können Sie feststellen, wie aktiv die Anwendung zum
Zeitpunkt des Auftretens der Fehler war.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der Datenbankaufantworten, die mit dem verknüpft sind Anwendung. Fehler Die Anzahl der Datenbankanforderungsvorgänge, die ist auf allen Datenbankinstanzen fehlgeschlagen. Alle Datenbankfehler sollten sein untersucht. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der Datenbankantworten, die mit
der Anwendung verknüpft waren, und wie viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Datenbankaufantworten, die mit dem verknüpft sind Anwendung. Fehler Die Anzahl der Datenbankanforderungsvorgänge, die ist auf allen Datenbankinstanzen fehlgeschlagen. Alle Datenbankfehler sollten sein untersucht. - Leistung (95. Perzentil)
-
Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken.
Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer vollständigen
Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange Clients gebraucht haben, um Anfragen an
das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange die Server für die Bearbeitung von Anfragen gebraucht haben;
und die Antwortübertragungszeit zeigt, wie lange die Server gebraucht haben, um Antworten an
das Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Verarbeitungszeit des Servers Die Zeit, die zum Senden der Datenbankinstanz benötigt wurde das erste Antwortpaket nach dem Empfang des letzten Paket einer Datenbankanforderung Betrieb. Zeit für Hin- und Rückfahrt Die Zeit, die der Server oder Client zum Senden einer verpacken und eine Bestätigung (ACK) erhalten. Die Hin- und Rückreisezeit kann berechnet werden im Verlauf einer TCP-Verbindung. Eine lange Roundtrip-Zeit (RTT) weist auf ein Netzwerk hin Latenz. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn eine Anwendung langsam reagiert, können Sie anhand
von Leistungsübersichtsmetriken herausfinden, ob das Netzwerk oder die Server das
Problem verursachen. Diese Metriken zeigen das 95. Perzentil der Zeit, die Server für die Bearbeitung von
Anfragen von Clients benötigten, im Vergleich zum 95. Perzentil der Zeit, die Pakete aus diesen Anfragen
(und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten. Hohe
Serververarbeitungszeiten deuten darauf hin, dass Clients langsame Server kontaktieren. Hohe
TCP-Roundtrip-Zeiten deuten darauf hin, dass Clients über langsame Netzwerke kommunizieren.
Metrisch Beschreibung Verarbeitungszeit des Servers Die Zeit, die zum Senden der Datenbankinstanz benötigt wurde das erste Antwortpaket nach dem Empfang des letzten Paket einer Datenbankanforderung Betrieb. Zeit für Hin- und Rückfahrt Die Zeit, die der Server oder Client zum Senden einer verpacken und eine Bestätigung (ACK) erhalten. Die Hin- und Rückreisezeit kann berechnet werden im Verlauf einer TCP-Verbindung. Eine lange Roundtrip-Zeit (RTT) weist auf ein Netzwerk hin Latenz.
Angaben zur Datenbank
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche Datenbankmethoden mit der Anwendung verknüpft waren, indem die Gesamtzahl der Datenbankanfragen nach Methode aufgeschlüsselt wird.
- Die besten Methoden (detailliert)
- Dieses Diagramm zeigt, welche Datenbankmethoden mit der Anwendung verknüpft waren, indem die Gesamtzahl der Datenbankanfragen nach Methode aufgeschlüsselt wird.
- Die besten Nutzer
- Dieses Diagramm zeigt, welche Benutzer in der Anwendung am aktivsten waren, indem es die Gesamtzahl der von der Anwendung gesendeten Datenbankanfragen aufschlüsselt.
Datenbank-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des Datenbankservers Die Zeit, die zum Senden der Datenbankinstanz benötigt wurde das erste Antwortpaket nach dem Empfang des letzten Paket einer Datenbankanforderung Betrieb. - Verarbeitungszeit des Servers
-
Diese Tabelle zeigt die durchschnittliche Bearbeitungszeit für den Anwendung.
Metrisch Beschreibung Verarbeitungszeit des Datenbankservers Die Zeit, die zum Senden der Datenbankinstanz benötigt wurde das erste Antwortpaket nach dem Empfang des letzten Paket einer Datenbankanforderung Betrieb. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit, die der Server oder Client zum Senden einer verpacken und eine Bestätigung (ACK) erhalten. Die Hin- und Rückreisezeit kann berechnet werden im Verlauf einer TCP-Verbindung. Eine lange Roundtrip-Zeit (RTT) weist auf ein Netzwerk hin Latenz. - Zeit für Hin- und Rückfahrt
-
Diese Tabelle zeigt
die durchschnittliche Hin- und Rückflugzeit für die Anwendung.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit, die der Server oder Client zum Senden einer verpacken und eine Bestätigung (ACK) erhalten. Die Hin- und Rückreisezeit kann berechnet werden im Verlauf einer TCP-Verbindung. Eine lange Roundtrip-Zeit (RTT) weist auf ein Netzwerk hin Latenz.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass ein Problem mit einem Server oder einem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
-
Dieses Diagramm zeigt die Anzahl der Nullfenster, die einer Anwendung
zugeordnet waren. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der Pakete
angeben, die über einen bestimmten Zeitraum an sie gesendet werden können.
Wenn an ein Gerät mehr Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein
Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig einzustellen, bis das Gerät den Vorgang
aufholt. Wenn Sie eine große Anzahl von Nullfenstern sehen, ist ein Server oder Client möglicherweise
nicht schnell genug, um die empfangene Datenmenge zu unterstützen.
Metrisch Definition Zero Windows anfordern Die Anzahl der Null-Window-Anzeigen, die gesendet wurden von Datenbankclients. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl eingehender Zero-Windows weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Antwort Null Windows Die Anzahl der Null-Window-Anzeigen, die gesendet wurden von Server beim Empfangen von Datenbankanfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von ausgehenden Zero-Windows weist darauf hin, dass ein Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Gesamtzahl der Host-Stände
- Dieses Diagramm zeigt die durchschnittliche Anzahl von Zero-Window-Werbeanzeigen, die von Geräten gesendet wurden.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen
Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu
viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät
eine Anfrage oder Antwort sendet und innerhalb einer bestimmten
Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen
nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise
zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Clients Datenbankanfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, als Server Datenbankaufantworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
- Gesamtzahl der Netzwerkausfälle
- Dieses Diagramm zeigt die durchschnittliche Anzahl von Timeouts bei der erneuten Übertragung, die durch Überlastung beim Senden von Anfragen durch Clients und Server verursacht wurden.
Gesamtwerte der Datenbankmetriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr Anfragen, als Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um herauszufinden, ob das Problem mit dem Netzwerk oder einem Server zusammenhängt, überprüfen Sie RTOs und Zero Windows in der Netzwerk-Daten Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Datenbankanfragen und -antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der damit verbundenen Datenbankanfragen Anwendung. Antworten Die Anzahl der Datenbankaufantworten, die mit dem verknüpft sind Anwendung. Fehler Die Anzahl der Datenbankanforderungsvorgänge, die ist auf allen Datenbankinstanzen fehlgeschlagen. Alle Datenbankfehler sollten sein untersucht. - Datenbank-Netzwerkmetriken
-
Metrisch Beschreibung Zero Windows anfordern Die Anzahl der Null-Window-Anzeigen, die gesendet wurden von Datenbankclients. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Antwort Null Windows Die Anzahl der Null-Window-Anzeigen, die gesendet wurden von Server beim Empfangen von Datenbankanfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. RTOs anfragen Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Clients Datenbankanfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Antwort-RTOs Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, als Server Datenbankaufantworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. L2-Byte anfordern Die Anzahl der L2-Bytes, die mit verknüpft sind Datenbankanfragen. Antwort L2 Byte Die Anzahl der L2-Bytes, die mit verknüpft sind Antworten der Datenbank. Goodput Bytes anfordern Die Anzahl der Goodput-Bytes, die mit verknüpft sind Datenbankanfragen. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Antwort Goodput Bytes Die Anzahl der Goodput-Bytes, die mit verknüpft sind Antworten der Datenbank. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Pakete anfordern Die Anzahl der Pakete, die der Datenbank zugeordnet sind Anfragen. Antwortpakete Die Anzahl der Pakete, die der Datenbank zugeordnet sind Antworten.
Datenbank-Client-Seite
Auf dieser Seite werden Metrikdiagramme von angezeigt Datenbank Client-Verkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur Datenbanksicherheit
- Erfahre mehr über mit Metriken arbeiten.
Datenbank Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann Datenbankfehler aufgetreten sind und wie viele Antworten der
Datenbankclient erhalten hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Client zum Zeitpunkt des
Eingangs der Fehler war.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie Details zu jedem Fehler anzeigen, einschließlich der von der Datenbank gemeldeten Rohfehlermeldung. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von Anfragen zu Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Hinweis: Um weitere Informationen zu Fehlern zu erhalten, klicken Sie auf Fehler Link oben auf der Seite. Metrisch Beschreibung Antworten Die Anzahl der Antworten, die von dieser Datenbank empfangen wurden Client. Die Antworten variieren je nach angefordertem Vorgang. Fehler Die Anzahl der Fehlermeldungen, die waren von Datenbankclients empfangen. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der Datenbankantworten, die der Client erhalten hat, und wie
viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die von dieser Datenbank empfangen wurden Client. Die Antworten variieren je nach angefordertem Vorgang. Fehler Die Anzahl der Fehlermeldungen, die waren von Datenbankclients empfangen. - Leistung (95. Perzentil)
-
Dieses Diagramm zeigt das
95. Perzentil der Timing-Metriken. Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer
vollständigen Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange der Client gebraucht hat, um
Anfragen an das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange Server gebraucht haben, um
die Anfragen zu verarbeiten; und die Antwortübertragungszeit zeigt, wie lange Server gebraucht haben, um
Antworten an das Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Übertragungszeit der Datenbank-Client-Anfrage Wenn das Gerät als Datenbank fungiert client, die Zeit zwischen der Entdeckung des ersten und des letzten Paket durch das ExtraHop-System Paket gesendeter Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit des Datenbank-Client-Servers Die Zeit, die dieser Datenbankclient Client hat Empfangen Sie das erste Paket einer Antwort nach dem Senden des letzten Paket der abfragen. Übertragungszeit der Datenbank-Client-Antwort Wenn das Gerät als Datenbank fungiert client, die Zeit zwischen der Entdeckung des ersten und des letzten Paket durch das ExtraHop-System Paket der empfangenen Antworten. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen Datenbank Client einer Paket, für das eine sofortige Bestätigung erforderlich war und wann der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn ein Client langsam reagiert, können Sie
anhand von Leistungsübersichtsmetriken herausfinden, ob das Netzwerk oder die Server das Problem verursachen.
Diese Metriken zeigen das 95. Perzentil der Zeit, die Server für die Bearbeitung von
Anfragen vom Client benötigten, im Vergleich zur 95. Perzentilzeit, die Pakete aus diesen
Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten.
Hohe Serververarbeitungszeiten deuten darauf hin, dass der Client langsame Server kontaktiert. Hohe
TCP-Roundtrip-Zeiten deuten darauf hin, dass der Client über langsame
Netzwerke kommuniziert.
Metrisch Beschreibung Verarbeitungszeit des Datenbank-Client-Servers Die Zeit, die dieser Datenbankclient Client hat Empfangen Sie das erste Paket einer Antwort nach dem Senden des letzten Paket der abfragen. Zeit für Hin- und Rückfahrt Die Zeit zwischen Datenbank Client einer Paket, für das eine sofortige Bestätigung erforderlich war und wann der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Angaben zur Datenbank
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche Methoden der Client am häufigsten aufgerufen hat, indem die Gesamtzahl der Datenbankanfragen, die der Client nach Methode gesendet hat, aufgeschlüsselt wird.
- Die wichtigsten Statuscodes
- Dieses Diagramm zeigt, welche Statuscodes der Kunde am häufigsten erhalten hat, indem die Anzahl der an den Client zurückgegebenen Antworten nach Statuscode aufgeschlüsselt wird.
- Die besten Nutzer
- Dieses Diagramm zeigt, welche Benutzer auf dem Client am aktivsten waren, indem es die Gesamtzahl der vom Client gesendeten Datenbankanfragen nach Benutzern aufschlüsselt.
Datenbank-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des Datenbank-Client-Servers Die Zeit, die dieser Datenbankclient Client hat Empfangen Sie das erste Paket einer Antwort nach dem Senden des letzten Paket der abfragen. - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Bearbeitungszeit für den Client.
Metrisch Beschreibung Verarbeitungszeit des Datenbank-Client-Servers Die Zeit, die dieser Datenbankclient Client hat Empfangen Sie das erste Paket einer Antwort nach dem Senden des letzten Paket der abfragen. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen Datenbank Client einer Paket, für das eine sofortige Bestätigung erforderlich war und wann der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Hin- und Rückflugzeit für den Client.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen Datenbank Client einer Paket, für das eine sofortige Bestätigung erforderlich war und wann der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Gesamtwerte der Datenbankmetriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, sendet der Client möglicherweise mehr
Anfragen, als die Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen
, ob das Problem beim Netzwerk oder beim Server liegt, überprüfen Sie RTOs und Zero Windows in der
Netzwerk-Daten
Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Datenbankanfragen und -antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die von dieser Datenbank gesendet wurden Client. Anfragen decken eine Reihe von Vorgängen ab: Verbindungsverhandlungen, Sitzung Konfiguration, Datendefinitionssprache (DDL), Datenänderungssprache (DML) oder Daten werden gelesen (auswählen). Antworten Die Anzahl der Antworten, die von dieser Datenbank empfangen wurden Client. Die Antworten variieren je nach angefordertem Vorgang. Fehler Die Anzahl der Fehlermeldungen, die waren von Datenbankclients empfangen. Abgebrochene Anfragen Die Anzahl der Anfragen, die diese Datenbank Der Client begann zu senden, bevor die Verbindung abrupt geschlossen wurde. Dieser Client konnte nicht um die komplette Anfrage zu senden, weil die Verbindung abgelaufen ist oder die Verbindung geschlossen mit einem TCP-Reset (RST) oder FIN Abgebrochene Antworten Die Anzahl der Antworten, die diese Datenbank enthält Der Client begann zu empfangen, bevor die Verbindung abrupt geschlossen wurde. Dieser Client war kann die vollständige Antwort nicht empfangen, da das Verbindungszeitlimit überschritten wurde oder Die Verbindung wurde mit einem TCP-Reset (RST) oder FIN geschlossen - Größe der Anfrage und Antwort
- Dieses Diagramm zeigt die durchschnittliche Größe der Anfragen und Antworten.
Metrisch Beschreibung Größe der Anfrage Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät gesendet hat, als es als Datenbankclient agiert. Größe der Antwort Die Verteilung der Größen (in Byte) von Antworten, die das Gerät erhalten hat, als es als Datenbankclient agiert hat.
Datenbankserverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt Datenbank Serververkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur Datenbanksicherheit
- Erfahre mehr über mit Metriken arbeiten.
Datenbank Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann Datenbankfehler aufgetreten sind und wie viele Datenbankantworten der
Server gesendet hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Server zu dem Zeitpunkt war, als er die Fehler
zurückgab.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie sich Details zu jedem Fehler anzeigen lassen, einschließlich der von der Datenbank gemeldeten Rohfehlermeldung. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von Anfragen zu Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Hinweis: Um weitere Informationen zu Fehlern zu erhalten, klicken Sie auf Fehler Link oben auf der Seite. Antworten Die Anzahl der Antworten aller Datenbankinstanzen auf diesem Server. Die Antworten variieren je nach angefordertem Vorgang. Zum Beispiel eine Antwort kann Verbindungs- und Sitzungskonfigurationen, Erfolgs- oder Fehlerbenachrichtigungen enthalten, oder ein tabellarischer Datensatz Fehler Die Anzahl der gesendeten Fehlermeldungen von Datenbankservern. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der Datenbankantworten, die der Server gesendet hat, und wie
viele dieser Antworten Fehler enthielten.
Antworten Die Anzahl der Antworten aller Datenbankinstanzen auf diesem Server. Die Antworten variieren je nach angefordertem Vorgang. Zum Beispiel eine Antwort kann Verbindungs- und Sitzungskonfigurationen, Erfolgs- oder Fehlerbenachrichtigungen enthalten, oder ein tabellarischer Datensatz Fehler Die Anzahl der gesendeten Fehlermeldungen von Datenbankservern. - Leistung (95. Perzentil)
-
Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken
. Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer vollständigen
Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange Clients gebraucht haben, um Anfragen an
das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange der Server gebraucht hat, um Anfragen zu verarbeiten;
und die Antwortübertragungszeit zeigt, wie lange der Server gebraucht hat, um Antworten an das
Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Transferzeit anfragen Wenn das Gerät als Datenbank fungiert Server, die Zeit zwischen der Entdeckung des ersten und des letzten Paket durch das ExtraHop-System Paket eingegangener Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit des Servers Die Zeit, die dieser Datenbankserver benötigt hat sende das erste Paket einer Antwort, nachdem du das letzte Paket der abfragen. Übertragungszeit der Antwort Wenn das Gerät als Datenbank fungiert Server, die Zeit zwischen der Entdeckung des ersten und des letzten Paket durch das ExtraHop-System Paket gesendeter Antworten. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen Datenbankserver Senden einer Paket, das eine sofortige Bestätigung erforderte und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn ein Server langsam reagiert, können Sie
anhand von Leistungsübersichtsmetriken herausfinden, ob das
Problem vom Netzwerk oder vom Server verursacht wird. Die Leistungsübersichtsmetriken zeigen das 95. Perzentil der Zeit, die der
Server für die Verarbeitung von Anfragen von Clients benötigte, im Vergleich zur 95. Perzentilzeit, die
Pakete aus diesen Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten.
Hohe Serververarbeitungszeiten deuten darauf hin, dass der Server langsam ist.
Hohe RTTs weisen darauf hin, dass der Server über langsame Netzwerke kommuniziert.
Verarbeitungszeit des Servers Die Zeit, die dieser Datenbankserver benötigt hat sende das erste Paket einer Antwort, nachdem du das letzte Paket der abfragen. Zeit für Hin- und Rückfahrt Die Zeit zwischen Datenbankserver Senden einer Paket, das eine sofortige Bestätigung erforderte und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Angaben zur Datenbank
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche Datenbankmethoden auf dem Server am häufigsten aufgerufen wurden, indem die Gesamtzahl der Anfragen, die der Server erhalten hat, nach Methode aufgeteilt wird.
- Die wichtigsten Statuscodes
- Dieses Diagramm zeigt, welche Datenbankstatuscodes der Server am häufigsten zurückgegeben hat, indem die Gesamtzahl der vom Server gesendeten Antworten nach Statuscode aufgeschlüsselt wird.
- Die besten Nutzer
- Dieses Diagramm zeigt, welche Benutzer auf dem Server am aktivsten waren, indem die Gesamtzahl der vom Benutzer an den Server gesendeten Datenbankanforderungen aufgeschlüsselt wird.
Datenbank-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Verarbeitungszeit des Servers Die Zeit, die dieser Datenbankserver benötigt hat sende das erste Paket einer Antwort, nachdem du das letzte Paket der abfragen. - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Verarbeitungszeit für den Server.
Verarbeitungszeit des Servers Die Zeit, die dieser Datenbankserver benötigt hat sende das erste Paket einer Antwort, nachdem du das letzte Paket der abfragen. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Zeit für Hin- und Rückfahrt Die Zeit zwischen Datenbankserver Senden einer Paket, das eine sofortige Bestätigung erforderte und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Roundtrip-Zeit für den Server.
Zeit für Hin- und Rückfahrt Die Zeit zwischen Datenbankserver Senden einer Paket, das eine sofortige Bestätigung erforderte und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Gesamtwerte der Datenbankmetriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr
Anfragen, als der Server verarbeiten kann, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen
, ob das Problem beim Netzwerk oder beim Server liegt, überprüfen Sie RTOs und Zero Windows in der
Netzwerk-Daten
Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Datenbankanfragen und -antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Anfragen Die Anzahl der Anfragen, die von allen Datenbank empfangen wurden Instanzen auf diesem Server. Anfragen decken eine Reihe von Vorgängen ab: Verbindung Verhandlungen, Sitzungskonfiguration, Datendefinitionssprache (DDL), Daten Sprache ändern (DML) oder Daten lesen (auswählen) Antworten Die Anzahl der Antworten aller Datenbankinstanzen auf diesem Server. Die Antworten variieren je nach angefordertem Vorgang. Zum Beispiel eine Antwort kann Verbindungs- und Sitzungskonfigurationen, Erfolgs- oder Fehlerbenachrichtigungen enthalten, oder ein tabellarischer Datensatz Fehler Die Anzahl der gesendeten Fehlermeldungen von Datenbankservern. Abgebrochene Anfragen Die Anzahl der Anfragen dieses Datenbankserver begann zu empfangen, bevor die Verbindung abrupt geschlossen wurde. Dieser Server konnte nicht erhalte die komplette Anfrage, weil das Verbindungs-Timeout abgelaufen ist oder die Verbindung geschlossen mit einem TCP-Reset (RST) oder FIN Abgebrochene Antworten Die Anzahl der Antworten auf diesem Datenbankserver begann zu senden, bevor die Verbindung abrupt geschlossen wurde. Dieser Server konnte nicht senden die vollständige Antwort, weil das Zeitlimit für die Verbindung abgelaufen ist oder die Verbindung geschlossen wurde mit einem TCP-Reset (RST) oder FIN - Größe der Anfrage und Antwort
- Dieses Diagramm zeigt die durchschnittliche Größe der Anfragen und Antworten.
Größe der Anfrage Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät empfangen hat, als es als Datenbankserver fungierte. Größe der Antwort Die Verteilung der Größen (in Byte) von Antworten, die das Gerät gesendet hat, als es als Datenbankserver fungierte.
Seite Datenbank-Client-Gruppe
Auf dieser Seite werden Metrikdiagramme von angezeigt Datenbank Client-Verkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur Datenbanksicherheit
- Erfahre mehr über mit Metriken arbeiten.
Datenbank Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann Datenbankfehler aufgetreten sind und wie viele Datenbankantworten die
Server gesendet haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Server zu dem Zeitpunkt waren, als
sie die Fehler gemeldet haben.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie die spezifischen Statuscodes, die in den Anfragen zurückgegeben wurden, aufschlüsseln und herausfinden, warum Server die Anfragen nicht bearbeiten konnten. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von Datenbankanfragen zu Datenbankantworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie weiter unten im Abschnitt Metriken für Gruppen.
Hinweis: Um weitere Informationen zu Fehlern zu erhalten, klicken Sie auf Fehler Link oben auf der Seite. Metrisch Beschreibung Antworten Die Anzahl der Antworten, die von dieser Datenbank empfangen wurden Client. Die Antworten variieren je nach angefordertem Vorgang. Fehler Die Anzahl der Fehlermeldungen, die waren von Datenbankclients empfangen. - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele Datenbankantworten die Kunden erhalten haben und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die von dieser Datenbank empfangen wurden Client. Die Antworten variieren je nach angefordertem Vorgang. Fehler Die Anzahl der Fehlermeldungen, die waren von Datenbankclients empfangen.
Datenbankdetails für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (Datenbankclients)
- Dieses Diagramm zeigt, welche Datenbankclients in der Gruppe am aktivsten waren, indem es die Gesamtzahl der Datenbankanfragen aufschlüsselt, die die Gruppe vom Client gesendet hat.
- Die besten Methoden
- Dieses Diagramm zeigt, welche Datenbankmethoden die Gruppe am häufigsten aufgerufen hat, indem die Gesamtzahl der Anfragen, die die Gruppe gesendet hat, nach Methode aufgeteilt wird.
- Die wichtigsten Statuscodes
- Dieses Diagramm zeigt, welche Datenbank-Statuscodes die Gruppe am häufigsten erhalten hat, indem die Anzahl der an die Gruppe zurückgegebenen Antworten nach Statuscode aufgeschlüsselt wird.
Datenbankmetriken für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden die Clients möglicherweise mehr Anfragen, als Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die von dieser Datenbank gesendet wurden Client. Anfragen decken eine Reihe von Vorgängen ab: Verbindungsverhandlungen, Sitzung Konfiguration, Datendefinitionssprache (DDL), Datenänderungssprache (DML) oder Daten werden gelesen (auswählen). Antworten Die Anzahl der Antworten, die von dieser Datenbank empfangen wurden Client. Die Antworten variieren je nach angefordertem Vorgang. Fehler Die Anzahl der Fehlermeldungen, die waren von Datenbankclients empfangen. Abgebrochene Anfragen Die Anzahl der Anfragen, die diese Datenbank Der Client begann zu senden, bevor die Verbindung abrupt geschlossen wurde. Dieser Client konnte nicht um die komplette Anfrage zu senden, weil die Verbindung abgelaufen ist oder die Verbindung geschlossen mit einem TCP-Reset (RST) oder FIN Abgebrochene Antworten Die Anzahl der Antworten, die diese Datenbank enthält Der Client begann zu empfangen, bevor die Verbindung abrupt geschlossen wurde. Dieser Client war kann die vollständige Antwort nicht empfangen, da das Verbindungszeitlimit überschritten wurde oder Die Verbindung wurde mit einem TCP-Reset (RST) oder FIN geschlossen - Verarbeitungszeit des Servers
-
Wenn sich eine Client-Gruppe langsam verhält, können Sie anhand der Serververarbeitungszeit herausfinden,
ob das Problem bei den Servern liegt. Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche
Zeit, die Server für die Bearbeitung von Anfragen von den Clients benötigten. Hohe
Serververarbeitungszeiten deuten darauf hin, dass die Clients langsame Server kontaktieren.
Metrisch Beschreibung Verarbeitungszeit des Datenbank-Client-Servers Die Zeit, die dieser Datenbankclient Client hat Empfangen Sie das erste Paket einer Antwort nach dem Senden des letzten Paket der abfragen.
Seite Datenbankserver-Gruppe
Auf dieser Seite werden Metrikdiagramme von angezeigt Datenbank Serververkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur Datenbanksicherheit
- Erfahre mehr über mit Metriken arbeiten.
Datenbank Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wann Datenbankfehler aufgetreten sind und wie viele Datenbankantworten die
Server gesendet haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Server zu dem Zeitpunkt waren, als
sie die Fehler gemeldet haben.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie einen Drilldown durchführen, um den spezifischen Statuscode zu finden, der in der Anfrage zurückgegeben wurde, und zu erfahren, warum die Server die Anfragen nicht bearbeiten konnten. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von Datenbankanfragen zu Datenbankantworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie weiter unten im Abschnitt Metriken für Gruppen.
Hinweis: Um weitere Informationen zu Fehlern zu erhalten, klicken Sie auf Fehler Link oben auf der Seite. Antworten Die Anzahl der Antworten aller Datenbankinstanzen auf diesem Server. Die Antworten variieren je nach angefordertem Vorgang. Zum Beispiel eine Antwort kann Verbindungs- und Sitzungskonfigurationen, Erfolgs- oder Fehlerbenachrichtigungen enthalten, oder ein tabellarischer Datensatz Fehler Die Anzahl der gesendeten Fehlermeldungen von Datenbankservern. - Transaktionen insgesamt
- Dieses Diagramm zeigt, wie viele Datenbankantwortserver in der Gruppe gesendet haben und wie viele dieser
Antworten Fehler enthielten.
Antworten Die Anzahl der Antworten aller Datenbankinstanzen auf diesem Server. Die Antworten variieren je nach angefordertem Vorgang. Zum Beispiel eine Antwort kann Verbindungs- und Sitzungskonfigurationen, Erfolgs- oder Fehlerbenachrichtigungen enthalten, oder ein tabellarischer Datensatz Fehler Die Anzahl der gesendeten Fehlermeldungen von Datenbankservern.
Datenbankdetails für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (Datenbankserver)
- Dieses Diagramm zeigt, welche Datenbankserver in der Gruppe am aktivsten waren, indem es die Gesamtzahl der Datenbankantworten aufschlüsselt, die die Gruppe vom Server gesendet hat.
- Die besten Methoden
- Dieses Diagramm zeigt, welche Datenbankmethoden auf Servern in der Gruppe am häufigsten aufgerufen wurden, indem die Gesamtzahl der Anfragen, die die Gruppe erhalten hat, nach Methode aufgeteilt wird.
- Wichtigster Statuscode
- Dieses Diagramm zeigt, welche Datenbank-Statuscodes die Gruppen am häufigsten zurückgegeben haben, indem die Gesamtzahl der von der Gruppe gesendeten Antworten nach Statuscode aufgeschlüsselt wird.
Datenbankmetriken für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden Clients möglicherweise mehr Anfragen, als die Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Anfragen Die Anzahl der Anfragen, die von allen Datenbank empfangen wurden Instanzen auf diesem Server. Anfragen decken eine Reihe von Vorgängen ab: Verbindung Verhandlungen, Sitzungskonfiguration, Datendefinitionssprache (DDL), Daten Sprache ändern (DML) oder Daten lesen (auswählen) Antworten Die Anzahl der Antworten aller Datenbankinstanzen auf diesem Server. Die Antworten variieren je nach angefordertem Vorgang. Zum Beispiel eine Antwort kann Verbindungs- und Sitzungskonfigurationen, Erfolgs- oder Fehlerbenachrichtigungen enthalten, oder ein tabellarischer Datensatz Fehler Die Anzahl der gesendeten Fehlermeldungen von Datenbankservern. Abgebrochene Anfragen Die Anzahl der Anfragen dieses Datenbankserver begann zu empfangen, bevor die Verbindung abrupt geschlossen wurde. Dieser Server konnte nicht erhalte die komplette Anfrage, weil das Verbindungs-Timeout abgelaufen ist oder die Verbindung geschlossen mit einem TCP-Reset (RST) oder FIN Abgebrochene Antworten Die Anzahl der Antworten auf diesem Datenbankserver begann zu senden, bevor die Verbindung abrupt geschlossen wurde. Dieser Server konnte nicht senden die vollständige Antwort, weil das Zeitlimit für die Verbindung abgelaufen ist oder die Verbindung geschlossen wurde mit einem TCP-Reset (RST) oder FIN - Verarbeitungszeit des Servers
-
Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche Zeit, die die Server für die
Bearbeitung von Anfragen von Clients benötigten. Hohe Serververarbeitungszeiten deuten darauf hin, dass die Server in einer
Gruppe langsam sind.
Verarbeitungszeit des Servers Die Zeit, die dieser Datenbankserver benötigt hat sende das erste Paket einer Antwort, nachdem du das letzte Paket der abfragen.
DHCP
Das ExtraHop-System sammelt Metriken über Dynamisches Host-Konfigurationsprotokoll (DHCP) Aktivität. DHCP ist ein Protokoll zur dynamischen Verteilung von Netzwerkkonfigurationsparametern.
DHCP-Anwendungsseite
Auf dieser Seite werden Metrikdiagramme von angezeigt DHCP Datenverkehr, der einem Anwendungscontainer in Ihrem Netzwerk zugeordnet ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
DHCP Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann DHCP-Fehler und -Antworten mit der
Anwendung verknüpft waren. Anhand dieser Informationen können Sie feststellen, wie aktiv die Anwendung zum
Zeitpunkt des Auftretens der Fehler war.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der DHCP-Antworten. Fehler Die Anzahl der DHCP-Antworten Fehler. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der DHCP-Antworten, die mit der
Anwendung verknüpft waren, und wie viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der DHCP-Antworten. Fehler Die Anzahl der DHCP-Antworten Fehler. - Verarbeitungszeit des Servers
- Dieses Diagramm zeigt die Verarbeitungszeiten von DHCP-Servern, aufgeteilt nach Perzentilen.
Die Serververarbeitungszeit zeigt, wie lange Server gebraucht haben, um Anfragen von Clients zu verarbeiten. Die
Serververarbeitungszeit wird berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das letzte Paket einer
Anfrage und das erste Paket einer Antwort vom ExtraHop-System erkannt wird.
Metrisch Beschreibung Verarbeitungszeit des DHCP-Servers Wenn das Gerät als DHCP-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort. - Zusammenfassung der Serververarbeitungszeit
- Zeigt das 95. Perzentil für die Serververarbeitungszeit an.
Metrisch Beschreibung Verarbeitungszeit des DHCP-Servers Wenn das Gerät als DHCP-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort. Das Diagramm mit der Zusammenfassung der Serververarbeitungszeit konzentriert sich auf das 95. Perzentil, um den höchsten Wert für einen bestimmten Zeitraum anzuzeigen und gleichzeitig Ausreißer zu filtern. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Die folgende Tabelle zeigt, wie die Anzeige des 95. Werts anstelle des wahren Maximums zu einer genaueren Ansicht der Daten führen kann:
DHCP-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die häufigsten Arten von Anforderungsnachrichten
- Dieses Diagramm zeigt, welche DHCP-Nachrichtentypen die Anwendung am häufigsten gesendet hat, indem die Gesamtzahl der von der Anwendung gesendeten Anfragen nach Nachrichtentyp aufgeschlüsselt wird.
- Die häufigsten Arten von Antwortnachrichten
- Dieses Diagramm zeigt, welche DHCP-Nachrichtentypen die Anwendung am häufigsten erhalten hat, indem die Gesamtzahl der Antworten, die die Anwendung erhalten hat, nach Nachrichtentyp aufgeschlüsselt wird.
DHCP-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des DHCP-Servers Die Zeit zwischen der Erkennung durch das ExtraHop-System das letzte Paket von DHCP-Anfragen und das erste Paket der entsprechenden Anfragen Antworten. - Verarbeitungszeit des Servers
-
Diese Tabelle zeigt die durchschnittliche Bearbeitungszeit für den Anwendung.
Metrisch Beschreibung Verarbeitungszeit des DHCP-Servers Die Zeit zwischen der Erkennung durch das ExtraHop-System das letzte Paket von DHCP-Anfragen und das erste Paket der entsprechenden Anfragen Antworten.
Gesamtwerte der DHCP-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr Anfragen, als Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Datenbankanfragen und -antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der DHCP-Anfragen. Antworten Die Anzahl der DHCP-Antworten. Fehler Die Anzahl der DHCP-Antworten Fehler. - DHCP-Netzwerkmetriken
-
Metrisch Beschreibung L2-Byte anfordern Die Anzahl der L2-Bytes, die mit verknüpft sind DHCP-Anfragen Antwort L2 Byte Die Anzahl der L2-Bytes, die mit verknüpft sind DHCP-Antworten Pakete anfordern Die Anzahl der Pakete, die mit DHCP verknüpft sind Anfragen. Antwortpakete Die Anzahl der Pakete, die mit DHCP verknüpft sind Antworten.
DHCP-Client-Seite
Auf dieser Seite werden Metrikdiagramme von angezeigt DHCP Client-Verkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
DHCP-Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann DHCP-Fehler aufgetreten sind und wie viele Antworten der DHCP-Client
erhalten hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Client zum Zeitpunkt des
Eingangs der Fehler war.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als DHCP-Client agieren Fehler Wenn das Gerät als DHCP-Client fungiert, die Anzahl der Antworten, die mit einer Fehleroption empfangen wurden. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der DHCP-Antworten, die der Client erhalten hat, und wie
viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als DHCP-Client agieren Fehler Wenn das Gerät als DHCP-Client fungiert, die Anzahl der Antworten, die mit einer Fehleroption empfangen wurden. - Verarbeitungszeit des Servers
- Dieses Diagramm zeigt die Verarbeitungszeiten von DHCP-Servern, aufgeteilt nach Perzentilen.
Die Serververarbeitungszeit gibt an, wie lange Server gebraucht haben, um Anfragen vom Client zu verarbeiten. Die
Serververarbeitungszeit wird berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das letzte Paket einer
Anfrage und das erste Paket einer Antwort vom ExtraHop-System erkannt wird.
Metrisch Beschreibung Verarbeitungszeit des DHCP-Client-Servers Wenn das Gerät als DHCP-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort. - Verarbeitungszeit des Servers
- Zeigt das 95. Perzentil für die Serververarbeitungszeit an.
Metrisch Beschreibung Verarbeitungszeit des DHCP-Servers Wenn das Gerät als DHCP-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort. Das Diagramm mit der Zusammenfassung der Serververarbeitungszeit konzentriert sich auf das 95. Perzentil, um den höchsten Wert für einen bestimmten Zeitraum anzuzeigen und gleichzeitig Ausreißer zu filtern. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Die folgende Tabelle zeigt, wie die Anzeige des 95. Werts anstelle des wahren Maximums zu einer genaueren Ansicht der Daten führen kann:
DHCP-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die häufigsten Arten von Anforderungsnachrichten
- Dieses Diagramm zeigt, welche DHCP-Nachrichtentypen der Client am häufigsten gesendet hat, indem die Gesamtzahl der vom Client gesendeten Anfragen nach Nachrichtentyp aufgeschlüsselt wird.
- Die häufigsten Arten von Antwortnachrichten
- Dieses Diagramm zeigt, welche DHCP-Nachrichtentypen der Client am häufigsten erhalten hat, indem die Gesamtzahl der Antworten, die der Client erhalten hat, nach Nachrichtentyp aufgeschlüsselt wird.
DHCP-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des DHCP-Client-Servers Wenn das Gerät als DHCP-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort. - Verarbeitungszeit des Servers
- Dieses Diagramm zeigt die durchschnittliche Serververarbeitungszeit.
Metrisch Beschreibung Verarbeitungszeit des DHCP-Client-Servers Wenn das Gerät als DHCP-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort.
Gesamtwerte der DHCP-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, sendet der Client möglicherweise mehr
Anfragen, als die Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der DHCP-Anfragen und -Antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der von diesem DHCP gesendeten Anfragen Client. Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als DHCP-Client agieren Fehler Wenn das Gerät als DHCP-Client fungiert, die Anzahl der Antworten, die mit einer Fehleroption empfangen wurden.
DHCP-Serverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt DHCP Serververkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
DHCP-Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann DHCP-Fehler aufgetreten sind und wie viele DHCP-Antworten der Server
gesendet hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Server zu dem Zeitpunkt war, als er die Fehler
zurückgab.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als DHCP-Server Fehler Wenn das Gerät als DHCP-Server fungiert, die Anzahl der Antworten, die mit einer Fehleroption gesendet wurden. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der DHCP-Antworten, die der Server gesendet hat, und wie viele
dieser Antworten Fehler enthielten.
Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als DHCP-Server Fehler Wenn das Gerät als DHCP-Server fungiert, die Anzahl der Antworten, die mit einer Fehleroption gesendet wurden. - Verarbeitungszeit des Servers
- Dieses Diagramm zeigt die Verarbeitungszeiten von DHCP-Servern, aufgeteilt nach Perzentilen. Die
Serververarbeitungszeit gibt an, wie lange der Server gebraucht hat, um Anfragen von Clients zu verarbeiten. Die
Serververarbeitungszeit wird berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das letzte Paket einer
Anfrage und das erste Paket einer Antwort vom ExtraHop-System erkannt wird.
Metrisch Beschreibung Verarbeitungszeit des DHCP-Servers Wenn das Gerät als DHCP-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort. - Verarbeitungszeit des Servers
- Zeigt das 95. Perzentil für die Serververarbeitungszeit an.
Metrisch Beschreibung Verarbeitungszeit des DHCP-Servers Wenn das Gerät als DHCP-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort. Das Diagramm mit der Zusammenfassung der Serververarbeitungszeit konzentriert sich auf das 95. Perzentil, um den höchsten Wert für einen bestimmten Zeitraum anzuzeigen und gleichzeitig Ausreißer zu filtern. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Die folgende Tabelle zeigt, wie die Anzeige des 95. Werts anstelle des tatsächlichen Maximums zu einer genaueren Ansicht der Daten führen kann:
DHCP-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die häufigsten Arten von Anforderungsnachrichten
- Dieses Diagramm zeigt, welche DHCP-Nachrichtentypen der Server am häufigsten erhalten hat, indem die Gesamtzahl der Anfragen, die der Server erhalten hat, nach Nachrichtentyp aufgeschlüsselt wird.
- Die häufigsten Arten von Antwortnachrichten
- Dieses Diagramm zeigt, welche DHCP-Nachrichtentypen der Server am häufigsten gesendet hat, indem die Gesamtzahl der vom Server gesendeten Antworten nach Nachrichtentyp aufgeschlüsselt wird.
DHCP-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des DHCP-Servers Wenn das Gerät als DHCP-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort. - Verarbeitungszeit des Servers
- Dieses Diagramm zeigt die durchschnittliche Serververarbeitungszeit.
Metrisch Beschreibung Verarbeitungszeit des DHCP-Servers Wenn das Gerät als DHCP-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort.
Gesamtwerte der DHCP-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr Anfragen, als der Server verarbeiten kann, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der DHCP-Anfragen und -Antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät erhalten hat wenn Sie als DHCP-Server agieren Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als DHCP-Server Fehler Wenn das Gerät als DHCP-Server fungiert, die Anzahl der Antworten, die mit einer Fehleroption gesendet wurden.
DHCP-Clientgruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt DHCP Client-Verkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
DHCP Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wann DHCP-Fehler aufgetreten sind und wie viele Antworten die DHCP-Clients
erhalten haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Kunden zu dem Zeitpunkt waren, als sie die Fehler
erhielten.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie weiter unten im Abschnitt Metriken für Gruppen.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als DHCP-Client agieren Fehler Wenn das Gerät als DHCP-Client fungiert, die Anzahl der Antworten, die mit einer Fehleroption empfangen wurden. - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele DHCP-Antworten die Clients erhalten haben und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als DHCP-Client agieren Fehler Wenn das Gerät als DHCP-Client fungiert, die Anzahl der Antworten, die mit einer Fehleroption empfangen wurden.
DHCP-Details für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top Gruppenmitglieder (DHCP-Clients)
- Dieses Diagramm zeigt, welche DHCP-Clients in der Gruppe am aktivsten waren, indem es die Gesamtzahl der DHCP-Anfragen aufschlüsselt, die die Gruppe vom Client gesendet hat.
- Die häufigsten Arten von Anforderungsnachrichten
- Dieses Diagramm zeigt, welche DHCP-Nachrichtentypen die Gruppe am häufigsten gesendet hat, indem die Gesamtzahl der von der Gruppe gesendeten Anfragen nach Nachrichtentyp aufgeschlüsselt wird.
- Die häufigsten Arten von Antwortnachrichten
- Dieses Diagramm zeigt, welche DHCP-Nachrichtentypen die Gruppe am häufigsten erhalten hat, indem die Gesamtzahl der Antworten, die die Gruppe erhalten hat, nach Nachrichtentyp aufgeschlüsselt wird.
DHCP-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden die Clients möglicherweise mehr Anfragen, als Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der von diesem DHCP gesendeten Anfragen Client. Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als DHCP-Client agieren Fehler Wenn das Gerät als DHCP-Client fungiert, die Anzahl der Antworten, die mit einer Fehleroption empfangen wurden. - Verarbeitungszeit des Servers
-
Wenn sich eine Client-Gruppe langsam verhält, können Sie anhand der Serververarbeitungszeit herausfinden,
ob das Problem bei den Servern liegt. Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche
Zeit, die Server für die Bearbeitung von Anfragen von den Clients benötigten. Hohe
Serververarbeitungszeiten deuten darauf hin, dass die Clients langsame Server kontaktieren.
Metrisch Beschreibung Verarbeitungszeit des DHCP-Client-Servers Wenn das Gerät als DHCP-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort.
DHCP-Servergruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt DHCP Serververkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
DHCP Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann DHCP-Fehler aufgetreten sind und wie viele DHCP-Antworten die Server
gesendet haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Server zu dem Zeitpunkt waren, als sie
die Fehler gemeldet haben.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie weiter unten im Abschnitt Metriken für Gruppen.
Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als DHCP-Server Fehler Wenn das Gerät als DHCP-Server fungiert, die Anzahl der Antworten, die mit einer Fehleroption gesendet wurden. - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele DHCP-Antworten die Clients erhalten haben und wie viele
dieser Antworten Fehler enthielten.
Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als DHCP-Server Fehler Wenn das Gerät als DHCP-Server fungiert, die Anzahl der Antworten, die mit einer Fehleroption gesendet wurden.
DHCP-Details für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top Gruppenmitglieder (DHCP-Server)
- Dieses Diagramm zeigt, welche DHCP-Server in der Gruppe am aktivsten waren, indem die Gesamtzahl der DHCP-Antworten, die die Gruppe vom Server gesendet hat, aufgeschlüsselt wird.
- Die häufigsten Arten von Anforderungsnachrichten
- Dieses Diagramm zeigt, welche DHCP-Nachrichtentypen der Server am häufigsten erhalten hat, indem die Gesamtzahl der Anfragen, die der Server erhalten hat, nach Nachrichtentyp aufgeschlüsselt wird.
- Die häufigsten Arten von Antwortnachrichten
- Dieses Diagramm zeigt, welche DHCP-Nachrichtentypen der Server am häufigsten gesendet hat, indem die Gesamtzahl der Antwortserver in der Gruppe nach Nachrichtentyp aufgeschlüsselt wird.
DHCP-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Anfragen und Antworten
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden Clients möglicherweise mehr Anfragen, als die Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät erhalten hat wenn Sie als DHCP-Server agieren Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als DHCP-Server Fehler Wenn das Gerät als DHCP-Server fungiert, die Anzahl der Antworten, die mit einer Fehleroption gesendet wurden. - Verarbeitungszeit des Servers
-
Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche Zeit, die die Server für die
Bearbeitung von Anfragen von Clients benötigten. Hohe Serververarbeitungszeiten deuten darauf hin, dass die Server in einer
Gruppe langsam sind.
Metrisch Beschreibung Verarbeitungszeit des DHCP-Servers Wenn das Gerät als DHCP-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort.
DICOM
Das ExtraHop-System sammelt Kennzahlen zur digitalen Bildgebung und Kommunikation in der Medizin (DICOM) Aktivität. DICOM ist ein Standardprotokoll zum Speichern biomedizinischer Bilder und zur Übertragung dieser Bilder über ein Netzwerk.
| Hinweis: | Das ExtraHop-System enthält keine integrierten Metrikseiten für DICOM. Sie können jedoch DICOM-Metriken anzeigen, indem Sie sie zu einer benutzerdefinierten Seite hinzufügen oder Dashboard. |
DNS
Das ExtraHop-System sammelt Metriken über das Domain Name System (DNS) Protokollaktivität. DNS ist das Benennungssystem für Netzwerkhosts und Ressourcen, die mit dem Internet verbunden sind. DNS-Server ordnen IP-Adressen Hostnamen zu.
Erfahren Sie mehr, indem Sie an der DNS Quick Peek-Schulung teilnehmen.
Überlegungen zur Sicherheit
- DNS ist laut und es ist schwierig, es zu überwachen traditionelle Methoden.
- DNS-Übertragungen werden normalerweise über das User Datagram Protokoll (UDP) gesendet, das leicht gefälscht werden kann und anfällig für Angriffe ist.
- DNS-Schwächen können ausgenutzt werden um APT-Gruppen (Advanced Persistent Threat) dabei zu helfen, der Erkennung zu entgehen.
- DNS ist anfällig für DNS-Tunneling, Verstärkungsangriffe, Denial-of-Service-Angriffe (DoS), Hijacking, Cache-Poisoning, Umleitungsangriffe und mehr.
- DNS-Reverse-Lookup-Anfragen können die Aufzählung ermöglichen. Dabei handelt es sich um eine Aufklärungstechnik, mit der ein Angreifer interne Hostnamen ermitteln kann.
DNS-Anwendungsseite
Auf dieser Seite werden Metrikdiagramme von angezeigt DNS Verkehr, der mit einem Anwendungscontainer in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur DNS-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
DNS Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann DNS-Fehler und -Antworten mit der
Anwendung verknüpft waren. Anhand dieser Informationen können Sie feststellen, wie aktiv die Anwendung zum
Zeitpunkt des Auftretens der Fehler war.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der damit verbundenen DNS-Antworten Anwendung. Fehler Die Anzahl der DNS-Antworten mit Fehlern, die sind mit dieser Anwendung verknüpft. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der DNS-Antworten, die mit der
Anwendung verknüpft waren, und wie viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der damit verbundenen DNS-Antworten Anwendung. Fehler Die Anzahl der DNS-Antworten mit Fehlern, die sind mit dieser Anwendung verknüpft. - Anfragen und Timeouts
- Dieses Diagramm zeigt Ihnen, wann DNS-Anfragen und Anforderungs-Timeouts aufgetreten sind.
Metrisch Beschreibung Anfragen Die Anzahl der damit verbundenen DNS-Anfragen Anwendung. Timeouts anfordern Die Anzahl der Timeouts, die aufgetreten sind aufgrund von eine wiederholte unbeantwortete DNS-Anfrage, die von Clients an DNS-Server gesendet wurde. DNS-Timeouts können verursachen Verlangsamungen und Störungen - Gesamtzahl der Anfragen und Timeouts
- Dieses Diagramm zeigt Ihnen die Gesamtzahl der DNS-Anfragen und Anforderungs-Timeouts.
Metrisch Beschreibung Anfragen Die Anzahl der damit verbundenen DNS-Anfragen Anwendung. Timeouts anfordern Die Anzahl der Timeouts, die aufgetreten sind aufgrund von eine wiederholte unbeantwortete DNS-Anfrage, die von Clients an DNS-Server gesendet wurde. DNS-Timeouts können verursachen Verlangsamungen und Störungen - Verarbeitungszeit des Servers
- Dieses Diagramm zeigt die Verarbeitungszeiten von DNS-Servern, aufgeteilt nach Perzentilen.
Die Serververarbeitungszeit gibt an, wie lange Server gebraucht haben, um Anfragen von Clients zu verarbeiten. Die
Serververarbeitungszeit wird berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das letzte Paket einer
Anfrage und das erste Paket einer Antwort vom ExtraHop-System erkannt wird.
Metrisch Beschreibung Verarbeitungszeit des DNS-Servers Die Zeit, die dieser DNS-Client Client hat Empfangen Sie das erste Antwortpaket nach dem Senden einer Abfrageanforderung. Ein langwieriger Die Verarbeitungszeit kann auf eine Latenz hinweisen. Das Diagramm mit der Zusammenfassung der Serververarbeitungszeit konzentriert sich auf das 95. Perzentil, um den höchsten Wert für einen bestimmten Zeitraum anzuzeigen und gleichzeitig Ausreißer zu filtern. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Die folgende Tabelle zeigt, wie die Anzeige des 95. Werts anstelle des wahren Maximums zu einer genaueren Ansicht der Daten führen kann:
- Zusammenfassung der Serververarbeitungszeit
- Zeigt das 95. Perzentil für die Serververarbeitungszeit an.
Metrisch Beschreibung Verarbeitungszeit des DNS-Servers Die Zeit, die dieser DNS-Client Client hat Empfangen Sie das erste Antwortpaket nach dem Senden einer Abfrageanforderung. Ein langwieriger Die Verarbeitungszeit kann auf eine Latenz hinweisen.
DNS-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Opcodes
- Dieses Diagramm zeigt, welche DNS-Opcodes die Anwendung am häufigsten erhalten hat, indem die Anzahl der an die Anwendung zurückgegebenen Antworten nach Opcode aufgeschlüsselt wird.
- Häufigste Host-Anfragen
- Dieses Diagramm zeigt, welche Host-Abfragen die Anwendung am häufigsten gestellt hat, indem es die Gesamtzahl der Anfragen aufschlüsselt, die die Anwendung per Host-Abfrage gesendet hat.
- Die häufigsten Antwortcodes
- Dieses Diagramm zeigt, welche Antwortcodes die Anwendung am häufigsten erhalten hat, indem die Anzahl der an die Anwendung zurückgegebenen Antworten nach Antwortcode aufgeteilt wird.
DNS-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des DNS-Servers Die Zeit, die DNS-Server brauchten, um das zu senden erstes Paket einer Antwort nach dem Empfang des letzten Paket einer Anfrage. - Verarbeitungszeit des Servers
-
Diese Tabelle zeigt die durchschnittliche Bearbeitungszeit für den Anwendung.
Metrisch Beschreibung Verarbeitungszeit des DNS-Servers Die Zeit, die DNS-Server brauchten, um das zu senden erstes Paket einer Antwort nach dem Empfang des letzten Paket einer Anfrage.
Gesamtwerte der DNS-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Anfragen und Antworten
-
Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr Anfragen, als Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Datenbankanfragen und -antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der damit verbundenen DNS-Anfragen Anwendung. Antworten Die Anzahl der damit verbundenen DNS-Antworten Anwendung. Fehler Die Anzahl der DNS-Antworten mit Fehlern, die sind mit dieser Anwendung verknüpft. Timeouts anfordern Die Anzahl der Timeouts, die aufgetreten sind aufgrund von eine wiederholte unbeantwortete DNS-Anfrage, die von Clients an DNS-Server gesendet wurde. DNS-Timeouts können verursachen Verlangsamungen und Störungen Verkürzte Anfragen Die Anzahl der DNS-Anfragen, die gesendet wurden, aber wurden während des Transports gekürzt. Eine verkürzte Anfrage wird durch das verkürzte Bit in angezeigt die Nachricht und tritt auf, wenn die Nachricht größer ist als die zugrunde liegende Übertragung Kanal erlaubt. Verkürzte Antworten Die Anzahl der DNS-Antworten, die gesendet wurden, aber wurden während des Transports gekürzt. Eine verkürzte Anfrage wird durch das verkürzte Bit in angezeigt die Nachricht und tritt auf, wenn die Nachricht größer ist als die zugrunde liegende Übertragung Kanal erlaubt. - DNS-Netzwerkmetriken
-
Metrisch Beschreibung L2-Byte anfordern Die Anzahl der L2-Bytes, die mit DNS verknüpft sind Anfragen. Antwort L2 Byte Die Anzahl der L2-Bytes, die mit DNS verknüpft sind Antworten. Pakete anfordern Die Anzahl der mit DNS verknüpften Pakete Anfragen. Antwortpakete Die Anzahl der mit DNS verknüpften Pakete Antworten.
DNS-Client-Seite
Auf dieser Seite werden Metrikdiagramme von angezeigt DNS Client-Verkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur DNS-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
DNS-Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann DNS-Fehler aufgetreten sind. Das Diagramm zeigt Ihnen auch, wie viele
DNS-Antworten der Client erhalten hat, sodass Sie sehen können, wie aktiv der Client zum Zeitpunkt des
Eingangs der Fehler war.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Antworten Die Anzahl der Antworten, die von diesem DNS empfangen wurden Client. Fehler Die Häufigkeit, mit der dieser DNS-Client empfangen hat Fehlercodes als Antwort auf eine Anfrage. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der DNS-Antworten, die der Client erhalten hat, und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die von diesem DNS empfangen wurden Client. Fehler Die Häufigkeit, mit der dieser DNS-Client empfangen hat Fehlercodes als Antwort auf eine Anfrage. - Anfragen und Timeouts
- Dieses Diagramm zeigt Ihnen, wann Zeitüberschreitungen bei Anfragen aufgetreten sind. Das Diagramm zeigt Ihnen auch, wie viele
DNS-Anfragen der Client gesendet hat, sodass Sie sehen können, wie aktiv der Client zum Zeitpunkt
der Timeouts war.
Anfragen Die Anzahl der Anfragen, die von diesem DNS gesendet wurden Client. Timeouts anfordern Die Anzahl der Timeouts, die aufgrund von Fälligkeit aufgetreten sind zu einer wiederholten unbeantworteten DNS-Abfrageanfrage, die von diesem Client an DNS-Server gesendet wurde. DNS Zeitüberschreitungen bei Anfragen können zu Verlangsamungen und Störungen führen - Gesamtzahl der Anfragen und Timeouts
- Dieses Diagramm zeigt Ihnen die Gesamtzahl der Anfragen und Anforderungs-Timeouts.
Anfragen Die Anzahl der Anfragen, die von diesem DNS gesendet wurden Client. Timeouts anfordern Die Anzahl der Timeouts, die aufgrund von Fälligkeit aufgetreten sind zu einer wiederholten unbeantworteten DNS-Abfrageanfrage, die von diesem Client an DNS-Server gesendet wurde. DNS Zeitüberschreitungen bei Anfragen können zu Verlangsamungen und Störungen führen - Verarbeitungszeit des Servers
- Dieses Diagramm zeigt die Verarbeitungszeiten von DNS-Servern, aufgeteilt nach Perzentilen.
Die Serververarbeitungszeit gibt an, wie lange Server gebraucht haben, um Anfragen vom Client zu verarbeiten. Die
Serververarbeitungszeit wird berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das letzte Paket einer
Anfrage und das erste Paket einer Antwort vom ExtraHop-System erkannt wird. Dieses Diagramm
wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Metrisch Beschreibung Verarbeitungszeit des DNS-Clientservers Die Zeit, die dieser DNS-Client Client hat Empfangen Sie das erste Antwortpaket nach dem Senden einer Abfrageanforderung. Ein langwieriger Die Verarbeitungszeit kann auf eine Latenz hinweisen. Das Diagramm Serververarbeitungszeit konzentriert sich auf das 95. Perzentil, um den höchsten Wert für einen Zeitraum anzuzeigen und gleichzeitig Ausreißer zu filtern. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Die folgende Tabelle zeigt, wie die Anzeige des 95. Werts anstelle des wahren Maximums zu einer genaueren Ansicht der Daten führen kann:
- Zusammenfassung der Serververarbeitungszeit
- Zeigt das 95. Perzentil für die Serververarbeitungszeit an. Dieses Diagramm wird nicht angezeigt, wenn
sich das Gerät in Flow Analysis befindet.
Metrisch Beschreibung Verarbeitungszeit des DNS-Clientservers Die Zeit, die dieser DNS-Client Client hat Empfangen Sie das erste Antwortpaket nach dem Senden einer Abfrageanforderung. Ein langwieriger Die Verarbeitungszeit kann auf eine Latenz hinweisen.
DNS-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die wichtigsten Datensatztypen
- Dieses Diagramm zeigt, welche Datensatztypen der Client am häufigsten angefordert hat, indem die Gesamtzahl der vom Client gesendeten Anfragen nach Datensatztyp aufgeschlüsselt wird.
- Häufigste Host-Anfragen
- Dieses Diagramm zeigt, welche Host-Abfragen der Client am häufigsten gestellt hat, indem es die Gesamtzahl der Anfragen aufschlüsselt, die der Client per Host-Abfrage gesendet hat.
- Die häufigsten Antwortcodes
- Dieses Diagramm zeigt, welche Antwortcodes der Kunde am häufigsten erhalten hat, indem die Anzahl der an den Client zurückgegebenen Antworten nach Antwortcode aufgeteilt wird.
DNS-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar, sofern sich das Gerät nicht im Flow Analysis befindet:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des DNS-Clientservers Die Zeit, die dieser DNS-Client Client hat Empfangen Sie das erste Antwortpaket nach dem Senden einer Abfrageanforderung. Ein langwieriger Die Verarbeitungszeit kann auf eine Latenz hinweisen. - Verarbeitungszeit des Servers
- Dieses Diagramm zeigt die durchschnittliche Serververarbeitungszeit.
Metrisch Beschreibung Verarbeitungszeit des DNS-Clientservers Die Zeit, die dieser DNS-Client Client hat Empfangen Sie das erste Antwortpaket nach dem Senden einer Abfrageanforderung. Ein langwieriger Die Verarbeitungszeit kann auf eine Latenz hinweisen.
Gesamtwerte der DNS-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, sendet der Client möglicherweise mehr
Anfragen, als die Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der DNS-Anfragen und -Antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die von diesem DNS gesendet wurden Client. Antworten Die Anzahl der Anfragen, die von diesem DNS gesendet wurden Client. Fehler Die Häufigkeit, mit der dieser DNS-Client empfangen hat Fehlercodes als Antwort auf eine Anfrage. Timeouts anfordern Die Anzahl der Timeouts, die aufgrund von Fälligkeit aufgetreten sind zu einer wiederholten unbeantworteten DNS-Abfrageanfrage, die von diesem Client an DNS-Server gesendet wurde. DNS Zeitüberschreitungen bei Anfragen können zu Verlangsamungen und Störungen führen Verkürzte Anfragen Die Anzahl der gesendeten Anfragen, aber wurden während der Übertragung gekürzt, wenn das Gerät als DNS-Client fungiert. Eine verkürzte Die Anfrage wird durch das verkürzte Bit in der Nachricht angezeigt und tritt auf, wenn die Nachricht ist größer als es der zugrundeliegende Übertragungskanal zulässt. Verkürzte Antworten Wenn das Gerät als DNS-Client fungiert, die Anzahl der eingegangenen Antworten, die während der Übertragung gekürzt wurden. EIN Eine verkürzte Antwort wird durch das verkürzte Bit in der Nachricht angezeigt und tritt auf, wenn die Nachricht ist größer, als es der zugrunde liegende Übertragungskanal zulässt.
DNS-Serverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt DNS Serververkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur DNS-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
DNS-Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann DNS-Fehler aufgetreten sind. Das Diagramm zeigt Ihnen auch, wie viele
DNS-Antworten der Server gesendet hat, sodass Sie sehen können, wie aktiv der Server zu dem Zeitpunkt war, als er die Fehler
zurückgab.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der von diesem DNS gesendeten Antworten Server. Fehler Die Häufigkeit, mit der dieser DNS-Server gesendet hat Fehlercodes als Antwort auf eine Anfrage. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der DNS-Antworten, die der Server gesendet hat, und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der von diesem DNS gesendeten Antworten Server. Fehler Die Häufigkeit, mit der dieser DNS-Server gesendet hat Fehlercodes als Antwort auf eine Anfrage. - Anfragen und Timeouts
- Dieses Diagramm zeigt Ihnen, wann Zeitüberschreitungen bei Anfragen aufgetreten sind. Das Diagramm zeigt Ihnen auch, wie viele
DNS-Anfragen der Server gesendet hat, sodass Sie sehen können, wie aktiv der Server zum Zeitpunkt
der Timeouts war.
Anfragen Die Anzahl der Anfragen, die von diesem DNS empfangen wurden Server. Timeouts anfordern Die Anzahl der Timeouts, die mit verknüpft sind dieser DNS-Server, der nach einer wiederholten unbeantworteten DNS-Abfrageanfrage auftrat, war von Kunden gesendet. Timeouts bei DNS-Anfragen können zu Verlangsamungen führen und Störungen. - Gesamtzahl der Anfragen und Timeouts
- Dieses Diagramm zeigt Ihnen die Gesamtzahl der Anfragen und Anforderungs-Timeouts.
Anfragen Die Anzahl der Anfragen, die von diesem DNS empfangen wurden Server. Timeouts anfordern Die Anzahl der Timeouts, die mit verknüpft sind dieser DNS-Server, der nach einer wiederholten unbeantworteten DNS-Abfrageanfrage auftrat, war von Kunden gesendet. Timeouts bei DNS-Anfragen können zu Verlangsamungen führen und Störungen. - Verarbeitungszeiten des Servers
- Dieses Diagramm zeigt die Verarbeitungszeiten von DNS-Servern, aufgeteilt nach Perzentilen. Die
Serververarbeitungszeit gibt an, wie lange der Server gebraucht hat, um Anfragen von Clients zu verarbeiten. Die
Serververarbeitungszeit wird berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das letzte Paket einer
Anfrage und das erste Paket einer Antwort vom ExtraHop-System erkannt wird. Dieses Diagramm
wird nicht angezeigt, wenn sich das Gerät im Modus Flow Analysis befindet.
Metrisch Beschreibung Verarbeitungszeit des DNS-Servers Die Zeit, die dieser DNS-Server zum Senden benötigt hat das erste Antwortpaket nach dem Empfang einer Abfrageanforderung. Eine lange Bearbeitungszeit kann auf Latenz hinweisen. - Zusammenfassung der Serververarbeitungszeit
- Zeigt das 95. Perzentil für die Serververarbeitungszeit an. Dieses Diagramm wird nicht angezeigt, wenn
sich das Gerät in Flow Analysis befindet.
Metrisch Beschreibung Verarbeitungszeit des DNS-Servers Die Zeit, die dieser DNS-Server zum Senden benötigt hat das erste Antwortpaket nach dem Empfang einer Abfrageanforderung. Eine lange Bearbeitungszeit kann auf Latenz hinweisen.
DNS-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die wichtigsten Datensatztypen
- Dieses Diagramm zeigt, welche Datensatztypen auf dem Server am häufigsten angefordert wurden, indem die Gesamtzahl der Anfragen, die der Server erhalten hat, nach Datensatztyp aufgeschlüsselt wird.
- Häufigste Host-Anfragen
- Dieses Diagramm zeigt, welche Hostanfragen am häufigsten auf dem Server gestellt wurden, indem die Gesamtzahl der Anfragen, die der Server per Hostabfrage erhalten hat, aufgeschlüsselt wird.
- Die häufigsten Antwortcodes
- Dieses Diagramm zeigt, welche Antwortcodes der Server am häufigsten gesendet hat, indem die Anzahl der vom Server gesendeten Antworten nach Antwortcode aufgeteilt wird.
DNS-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar, sofern sich das Gerät nicht im Modus Flow Analysis befindet:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des DNS-Servers Die Zeit, die dieser DNS-Server zum Senden benötigt hat das erste Antwortpaket nach dem Empfang einer Abfrageanforderung. Eine lange Bearbeitungszeit kann auf Latenz hinweisen. - Verarbeitungszeit des Servers
- Dieses Diagramm zeigt die durchschnittliche Serververarbeitungszeit.
Metrisch Beschreibung Verarbeitungszeit des DNS-Servers Die Zeit, die dieser DNS-Server zum Senden benötigt hat das erste Antwortpaket nach dem Empfang einer Abfrageanforderung. Eine lange Bearbeitungszeit kann auf Latenz hinweisen.
Metrische Summen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, empfängt der Server möglicherweise mehr
Anfragen, als der Server verarbeiten kann, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der DNS-Anfragen und -Antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die von diesem DNS empfangen wurden Server. Antworten Die Anzahl der von diesem DNS gesendeten Antworten Server. Fehler Die Häufigkeit, mit der dieser DNS-Server gesendet hat Fehlercodes als Antwort auf eine Anfrage. Timeouts anfordern Die Anzahl der Timeouts, die mit verknüpft sind dieser DNS-Server, der nach einer wiederholten unbeantworteten DNS-Abfrageanfrage auftrat, war von Kunden gesendet. Timeouts bei DNS-Anfragen können zu Verlangsamungen führen und Störungen. Verkürzte Anfragen Die Anzahl der eingegangenen Anfragen, wurden aber während der Übertragung gekürzt, wenn das Gerät als DNS-Server fungiert. EIN Eine verkürzte Anfrage wird durch das verkürzte Bit in der Nachricht angezeigt und tritt auf, wenn die Nachricht ist größer, als es der zugrunde liegende Übertragungskanal zulässt. Verkürzte Antworten Die Anzahl der gesendeten Antworten, aber später gekürzt, wenn das Gerät als DNS-Server fungiert. Eine verkürzte Antwort ist wird durch das verkürzte Bit in der Nachricht angezeigt und tritt auf, wenn die Nachricht größer ist als es der zugrundeliegende Übertragungskanal zulässt.
Seite „DNS-Client-Gruppe"
Auf dieser Seite werden Metrikdiagramme von angezeigt DNS Client-Verkehr, der einer Gerätegruppe in Ihrem Netzwerk zugeordnet ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur DNS-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
DNS Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann DNS-Fehler aufgetreten sind und wie viele Antworten die DNS-Clients
erhalten haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Kunden zu dem Zeitpunkt waren, als sie die Fehler
erhielten.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie weiter unten im Abschnitt Metriken für Gruppen.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die von diesem DNS empfangen wurden Client. Fehler Die Häufigkeit, mit der dieser DNS-Client empfangen hat Fehlercodes als Antwort auf eine Anfrage. - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele DNS-Antworten die Clients erhalten haben und wie viele dieser
Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die von diesem DNS empfangen wurden Client. Fehler Die Häufigkeit, mit der dieser DNS-Client empfangen hat Fehlercodes als Antwort auf eine Anfrage.
DNS-Details für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (DNS-Clients)
- Dieses Diagramm zeigt, welche DNS-Clients in der Gruppe am aktivsten waren, indem es die Gesamtzahl der DNS-Anfragen aufschlüsselt, die die Gruppe vom Client gesendet hat.
- Die wichtigsten Datensatztypen
- Dieses Diagramm zeigt, welche Datensatztypen die Gruppe am häufigsten angefordert hat, indem die Gesamtzahl der von der Gruppe gesendeten Anfragen nach Datensatztyp aufgeschlüsselt wird.
- Die häufigsten Antwortcodes
- Dieses Diagramm zeigt, welche Antwortcodes die Gruppe am häufigsten erhalten hat, indem die Anzahl der an die Gruppe zurückgegebenen Antworten nach Antwortcode aufgeschlüsselt wird.
DNS-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar, sofern sich nicht alle Geräte in der Gruppe in Flow Analysis befinden:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden die Clients möglicherweise mehr Anfragen, als Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die von diesem DNS gesendet wurden Client. Antworten Die Anzahl der Antworten, die von diesem DNS empfangen wurden Client. Fehler Die Häufigkeit, mit der dieser DNS-Client empfangen hat Fehlercodes als Antwort auf eine Anfrage. - Verarbeitungszeit des Servers
-
Wenn sich eine Client-Gruppe langsam verhält, können Sie anhand der Serververarbeitungszeit herausfinden,
ob das Problem bei den Servern liegt. Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche
Zeit, die Server für die Bearbeitung von Anfragen von den Clients benötigten. Hohe
Serververarbeitungszeiten deuten darauf hin, dass die Clients langsame Server kontaktieren.
Metrisch Beschreibung Verarbeitungszeit des DNS-Clientservers Die Zeit, die dieser DNS-Client Client hat Empfangen Sie das erste Antwortpaket nach dem Senden einer Abfrageanforderung. Ein langwieriger Die Verarbeitungszeit kann auf eine Latenz hinweisen.
DNS-Servergruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt DNS Serververkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur DNS-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
DNS Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wann DNS-Fehler aufgetreten sind und wie viele DNS-Antworten die Server
gesendet haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Server zu dem Zeitpunkt waren, als sie
die Fehler gemeldet haben.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie weiter unten im Abschnitt Metriken für Gruppen.
Metrisch Beschreibung Antworten Die Anzahl der von diesem DNS gesendeten Antworten Server. Fehler Die Häufigkeit, mit der dieser DNS-Server gesendet hat Fehlercodes als Antwort auf eine Anfrage. - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele DNS-Antwortserver in der Gruppe gesendet haben und wie viele dieser
Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der von diesem DNS gesendeten Antworten Server. Fehler Die Häufigkeit, mit der dieser DNS-Server gesendet hat Fehlercodes als Antwort auf eine Anfrage.
DNS-Details für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (DNS-Server)
- Dieses Diagramm zeigt, welche DNS-Server in der Gruppe am aktivsten waren, indem die Gesamtzahl der DNS-Antworten, die die Gruppe vom Server gesendet hat, aufgeschlüsselt wird.
- Die wichtigsten Datensatztypen
- Dieses Diagramm zeigt, welche Datensatztypen auf Servern in der Gruppe am häufigsten angefordert wurden, indem die Gesamtzahl der Anfragen, die die Gruppe erhalten hat, nach Datensatztyp aufgeschlüsselt wird.
- Die häufigsten Antwortcodes
- Dieses Diagramm zeigt, welche Antwortcodes die Gruppe am häufigsten gesendet hat, indem die Anzahl der Antworten, die die Gruppe gesendet hat, nach Antwortcode aufgeteilt wird.
DNS-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar, sofern sich nicht alle Geräte in der Gruppe in Flow Analysis befinden:
- Gesamtzahl der Anfragen und Antworten
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden Clients möglicherweise mehr Anfragen, als die Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die von diesem DNS empfangen wurden Server. Antworten Die Anzahl der von diesem DNS gesendeten Antworten Server. Fehler Die Häufigkeit, mit der dieser DNS-Server gesendet hat Fehlercodes als Antwort auf eine Anfrage. Timeouts anfordern Die Anzahl der Timeouts, die mit verknüpft sind dieser DNS-Server, der nach einer wiederholten unbeantworteten DNS-Abfrageanfrage auftrat, war von Kunden gesendet. Timeouts bei DNS-Anfragen können zu Verlangsamungen führen und Störungen. Verkürzte Anfragen Die Anzahl der eingegangenen Anfragen, wurden aber während der Übertragung gekürzt, wenn das Gerät als DNS-Server fungiert. EIN Eine verkürzte Anfrage wird durch das verkürzte Bit in der Nachricht angezeigt und tritt auf, wenn die Nachricht ist größer, als es der zugrunde liegende Übertragungskanal zulässt. Verkürzte Antworten Die Anzahl der gesendeten Antworten, aber später gekürzt, wenn das Gerät als DNS-Server fungiert. Eine verkürzte Antwort ist wird durch das verkürzte Bit in der Nachricht angezeigt und tritt auf, wenn die Nachricht größer ist als es der zugrundeliegende Übertragungskanal zulässt. - Verarbeitungszeit des Servers
-
Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche Zeit, die die Server für die
Bearbeitung von Anfragen von Clients benötigten. Hohe Serververarbeitungszeiten deuten darauf hin, dass die Server in einer
Gruppe langsam sind.
Metrisch Beschreibung Verarbeitungszeit des DNS-Servers Die Zeit, die dieser DNS-Server zum Senden benötigt hat das erste Antwortpaket nach dem Empfang einer Abfrageanforderung. Eine lange Bearbeitungszeit kann auf Latenz hinweisen.
FIX
Das ExtraHop-System sammelt Kennzahlen zum Finanzinformationsaustausch (FIX) Protokollaktivität. FIX bietet Informationen über den Austausch von Finanztransaktionen in Echtzeit.
FIX-Anwendungsseite
Auf dieser Seite werden Metrikdiagramme von angezeigt FIX Datenverkehr im Zusammenhang mit Anwendungscontainern in Ihrem Netzwerk.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
FIX Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann FIX-Fehler und -Antworten mit der
Anwendung verknüpft waren. Anhand dieser Informationen können Sie feststellen, wie aktiv die Anwendung zum
Zeitpunkt des Auftretens der Fehler war.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der FIX-Antworten. Fehler Die Anzahl der FIX-Antworten Fehler. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der FIX-Antworten, die mit der
Anwendung verknüpft waren, und wie viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der FIX-Antworten. Fehler Die Anzahl der FIX-Antworten Fehler. - Leistung (95. Perzentil)
-
Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken.
Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer vollständigen
Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange Clients gebraucht haben, um Anfragen an
das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange die Server für die Bearbeitung von Anfragen gebraucht haben;
und die Antwortübertragungszeit zeigt, wie lange die Server gebraucht haben, um Antworten an
das Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Transferzeit anfragen Die Zeit zwischen der Erkennung durch das ExtraHop-System das erste Paket und das letzte Paket von FIX-Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit des Servers Die Zeit zwischen der Erkennung durch das ExtraHop-System das letzte Paket von FIX-Anfragen und das erste Paket der entsprechenden Anfragen Antworten. Übertragungszeit der Antwort Die Zeit zwischen der Erkennung durch das ExtraHop-System das erste Paket und das letzte Paket von FIX-Antworten. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines FIX-Clients oder Server Paket, das sofort bestätigt werden muss und wann die Bestätigung erfolgte erhalten. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn eine Anwendung langsam reagiert, können Sie anhand
von Leistungsübersichtsmetriken herausfinden, ob das Netzwerk oder die Server das
Problem verursachen. Diese Metriken zeigen das 95. Perzentil der Zeit, die Server für die Bearbeitung von
Anfragen von Clients benötigten, im Vergleich zum 95. Perzentil der Zeit, die Pakete aus diesen Anfragen
(und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten. Hohe
Serververarbeitungszeiten deuten darauf hin, dass Clients langsame Server kontaktieren. Hohe
TCP-Roundtrip-Zeiten deuten darauf hin, dass Clients über langsame Netzwerke kommunizieren.
Metrisch Beschreibung Verarbeitungszeit des Servers Die Zeit zwischen der Erkennung durch das ExtraHop-System das letzte Paket von FIX-Anfragen und das erste Paket der entsprechenden Anfragen Antworten. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines FIX-Clients oder Server Paket, das sofort bestätigt werden muss und wann die Bestätigung erfolgte erhalten.
FIX-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche FIX-Methoden mit der Anwendung verknüpft waren, indem die Gesamtzahl der FIX-Anfragen nach Methoden aufgeschlüsselt wird.
- Die besten Absender
- Dieses Diagramm zeigt die wichtigsten FIX-Absender für die Anwendung, aufgeschlüsselt nach der Gesamtzahl der FIX-Anfragen nach Absendern.
- Die wichtigsten Ziele
- Dieses Diagramm zeigt die wichtigsten FIX-Ziele für die Anwendung, indem die Gesamtzahl der FIX-Anfragen nach Zielen aufgeschlüsselt ist.
FIX-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung FIX Serververarbeitungszeit Die Zeit zwischen der Erkennung durch das ExtraHop-System das letzte Paket von FIX-Anfragen und das erste Paket der entsprechenden Anfragen Antworten. - Verarbeitungszeit des Servers
-
Diese Tabelle zeigt die durchschnittliche Bearbeitungszeit für den Anwendung.
Metrisch Beschreibung FIX Serververarbeitungszeit Die Zeit zwischen der Erkennung durch das ExtraHop-System das letzte Paket von FIX-Anfragen und das erste Paket der entsprechenden Anfragen Antworten. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines FIX-Clients oder Server Paket, das sofort bestätigt werden muss und wann die Bestätigung erfolgte erhalten. - Zeit für Hin- und Rückfahrt
-
Diese Tabelle zeigt
die durchschnittliche Hin- und Rückflugzeit für die Anwendung.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines FIX-Clients oder Server Paket, das sofort bestätigt werden muss und wann die Bestätigung erfolgte erhalten.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass ein Problem mit einem Server oder einem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
-
Dieses Diagramm zeigt die Anzahl der Nullfenster, die einer Anwendung
zugeordnet waren. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der Pakete
angeben, die über einen bestimmten Zeitraum an sie gesendet werden können.
Wenn an ein Gerät mehr Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein
Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig einzustellen, bis das Gerät den Vorgang
aufholt. Wenn Sie eine große Anzahl von Nullfenstern sehen, ist ein Server oder Client möglicherweise
nicht schnell genug, um die empfangene Datenmenge zu unterstützen.
Metrisch Definition Zero Windows anfordern Die Anzahl der gesendeten Null-Window-Anzeigen von FIX-Kunden. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl eingehender Zero-Windows weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Antwort Null Windows Die Anzahl der gesendeten Null-Window-Anzeigen von Servern beim Empfang von FIX-Anfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von ausgehenden Zero-Windows weist darauf hin, dass ein Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Gesamtzahl der Host-Stände
- Dieses Diagramm zeigt die durchschnittliche Anzahl von Zero-Window-Werbeanzeigen, die von Geräten gesendet wurden.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen
Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu
viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät
eine Anfrage oder Antwort sendet und innerhalb einer bestimmten
Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen
nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise
zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, als Clients FIX-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server FIX-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
- Gesamtzahl der Netzwerkausfälle
-
Dieses Diagramm zeigt die durchschnittliche Anzahl von Timeouts bei der
erneuten Übertragung, die durch Überlastung beim Senden von Anfragen durch Clients und Server verursacht wurden.
Metrisch Definition RTOs Ein Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, als Clients FIX-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server FIX-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
FIX Metrische Summen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr Anfragen, als Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um herauszufinden, ob das Problem mit dem Netzwerk oder einem Server zusammenhängt, überprüfen Sie RTOs und Zero Windows in der Netzwerk-Daten Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der FIX-Anfragen und -Antworten exakt gleich sein wird, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der FIX-Anfragen. Antworten Die Anzahl der FIX-Antworten. Fehler Die Anzahl der FIX-Antworten Fehler. - FIX-Netzwerkmetriken
-
Metrisch Beschreibung Zero Windows anfordern Die Anzahl der gesendeten Null-Window-Anzeigen von FIX-Kunden. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Antwort Null Windows Die Anzahl der gesendeten Null-Window-Anzeigen von Servern beim Empfang von FIX-Anfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. RTOs Ein Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, als Clients FIX-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. RTOs raus Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server FIX-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. L2-Byte anfordern Die Anzahl der L2-Bytes, die mit FIX verknüpft sind Anfragen. Antwort L2 Byte Die Anzahl der L2-Bytes, die mit FIX verknüpft sind Antworten. Goodput Bytes anfordern Die Anzahl der Goodput-Bytes, die mit verknüpft sind FIX-Anfragen. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Antwort Goodput Bytes Die Anzahl der Goodput-Bytes, die mit verknüpft sind Antworten FIX. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Pakete anfordern Die Anzahl der Pakete, die mit FIX verknüpft sind Anfragen. Antwortpakete Die Anzahl der Pakete, die mit FIX verknüpft sind Antworten.
FIX-Kundenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt FIX Serververkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
FIX Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Diese Tabelle zeigt Ihnen, wann FIX-Fehler aufgetreten sind. Das Diagramm zeigt Ihnen auch, wie viele
FIX-Antworten der Kunde erhalten hat, sodass Sie sehen können, wie aktiv der Client zum Zeitpunkt des
Eingangs der Fehler war.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als FIX-Client agieren. Fehler Wenn das Gerät als FIX-Client fungiert, die Anzahl der erhaltenen Fehlerantworten. Diese Metriken beinhalten nicht die Verarbeitung von Bestell- und Handelsfehlern. - Transaktionen insgesamt
-
Dieses Diagramm zeigt die Gesamtzahl der FIX-Antworten, die der Client erhalten hat, und wie viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als FIX-Client agieren. Fehler Wenn das Gerät als FIX-Client fungiert, die Anzahl der erhaltenen Fehlerantworten. Diese Metriken beinhalten nicht die Verarbeitung von Bestell- und Handelsfehlern. - Leistung (95. Perzentil)
-
Dieses Diagramm zeigt das
95. Perzentil der Timing-Metriken. Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer
vollständigen Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange der Client gebraucht hat, um
Anfragen an das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange Server gebraucht haben, um
die Anfragen zu verarbeiten; und die Antwortübertragungszeit zeigt, wie lange Server gebraucht haben, um
Antworten an das Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung FIX Übertragungszeit der Kundenanfrage Wenn das Gerät als FIX-Client fungiert, die Zeit zwischen der Erkennung des ersten Pakets und des letzten Pakets durch das ExtraHop-System von gesendete Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. FIX Verarbeitungszeit des Client-Servers Wenn das Gerät als FIX-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort. FIX Übertragungszeit der Kundenantwort Wenn das Gerät als FIX-Client fungiert, die Zeit zwischen der Erkennung des ersten Pakets und des letzten Pakets durch das ExtraHop-System von erhaltene Antworten. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen FIX-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn ein Client langsam reagiert, können Sie
anhand von Leistungsübersichtsmetriken herausfinden, ob das Netzwerk oder die Server das Problem verursachen.
Diese Metriken zeigen das 95. Perzentil der Zeit, die Server für die Bearbeitung von
Anfragen vom Client benötigten, im Vergleich zur 95. Perzentilzeit, die Pakete aus diesen
Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten.
Hohe Serververarbeitungszeiten deuten darauf hin, dass der Client langsame Server kontaktiert. Hohe
TCP-Roundtrip-Zeiten deuten darauf hin, dass der Client über langsame
Netzwerke kommuniziert.
Metrisch Beschreibung FIX Verarbeitungszeit des Client-Servers Wenn das Gerät als FIX-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen FIX-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
FIX-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche FIX-Methoden der Client am häufigsten aufgerufen hat, indem die Gesamtzahl der Anfragen, die der Client nach Methode gesendet hat, aufgeschlüsselt wird.
- Die besten Versionen
- Dieses Diagramm zeigt, über welche Versionen des FIX-Protokolls der Client am meisten kommuniziert hat, indem es die Gesamtzahl der Anfragen aufschlüsselt, die der Client von der FIX-Version gesendet hat.
- Die wichtigsten Ziele
- Dieses Diagramm zeigt die wichtigsten FIX-Ziele für den Client, indem die Gesamtzahl der vom Client gesendeten Anfragen nach Ziel aufgeschlüsselt wird.
FIX-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung FIX Verarbeitungszeit des Client-Servers Wenn das Gerät als FIX-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort. - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Bearbeitungszeit für den Client.
Metrisch Beschreibung FIX Verarbeitungszeit des Client-Servers Wenn das Gerät als FIX-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen FIX-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Hin- und Rückflugzeit für den Client.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen FIX-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
FIX Metrische Summen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Anfragen und Antworten
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, sendet der Client möglicherweise mehr
Anfragen, als die Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen
, ob das Problem beim Netzwerk oder beim Server liegt, überprüfen Sie RTOs und Zero Windows in der
Netzwerk-Daten
Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der FIX-Anfragen und -Antworten exakt gleich sein wird, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät gesendet hat, als fungiert als FIX-Kunde. Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als FIX-Client agieren. Fehler Wenn das Gerät als FIX-Client fungiert, die Anzahl der erhaltenen Fehlerantworten. Diese Metriken beinhalten nicht die Verarbeitung von Bestell- und Handelsfehlern. Abgebrochene Anfragen Die Anzahl der Anfragen, die dieser FIX-Client begann zu senden, sendete aber nicht vollständig. Abgebrochene Antworten Die Anzahl der Antworten, die dieser FIX-Client Das Gerät begann zu empfangen, empfing aber nicht vollständig. POS-Duplikat Die Anzahl möglicher doppelter Nachrichten, die das Gerät, das gesendet wurde, wenn es als FIX-Client fungiert. Wenn ein FIX-Motor nicht sicher ist, ob ein Nachricht wurde erfolgreich an ihrem vorgesehenen Ziel oder bei der Beantwortung von Bei einer erneuten Sendeanforderung wird eine mögliche doppelte (PossDup) -Nachricht generiert POS erneut senden Die Anzahl der möglichen Nachrichten, die erneut gesendet werden das Gerät, das gesendet wurde, wenn es als FIX-Client fungiert. Mehrdeutige Meldungen auf Anwendungsebene kann erneut versendet werden, wenn eine Bestellung über einen übermäßigen Zeitraum von unbestätigt bleibt Zeit. - Größe der Anfrage und Antwort
- Dieses Diagramm zeigt die durchschnittliche Größe der Anfragen und Antworten.
Metrisch Beschreibung Größe der Anfrage Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät gesendet hat, als es als FIX-Client fungiert. Größe der Antwort Die Verteilung der Größen (in Byte) von Antworten, die empfangen werden, wenn das Gerät als FIX-Client fungiert.
FIX-Serverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt FIX Serververkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
FIX-Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Diese Tabelle zeigt Ihnen, wann FIX-Fehler aufgetreten sind. Das Diagramm zeigt Ihnen auch, wie viele
FIX-Antworten der Server gesendet hat, sodass Sie sehen können, wie aktiv der Server zu dem Zeitpunkt war, als er die Fehler
zurückgab.
Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von Anfragen zu Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als FIX-Server. Fehler Wenn das Gerät als FIX-Server fungiert, die Anzahl der gesendeten Fehlerantworten. Diese Metriken beinhalten nicht die Verarbeitung von Bestell- und Handelsfehler. - Transaktionen insgesamt
-
Dieses Diagramm zeigt die Gesamtzahl der FIX-Antworten, die der Server gesendet hat, und wie viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als FIX-Server. Fehler Wenn das Gerät als FIX-Server fungiert, die Anzahl der gesendeten Fehlerantworten. Diese Metriken beinhalten nicht die Verarbeitung von Bestell- und Handelsfehler. - Leistung (95. Perzentil)
-
Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken
. Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer vollständigen
Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange Clients gebraucht haben, um Anfragen an
das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange der Server gebraucht hat, um Anfragen zu verarbeiten;
und die Antwortübertragungszeit zeigt, wie lange der Server gebraucht hat, um Antworten an das
Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung FIX Übertragungszeit der Serveranfrage Wenn das Gerät als FIX-Server fungiert, die Zeit zwischen der Erkennung des ersten Pakets und des letzten Pakets durch das ExtraHop-System von eingegangene Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. FIX Verarbeitungszeit des Serverservers Wenn das Gerät als FIX-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort. FIX Übertragungszeit der Serverantwort Wenn das Gerät als FIX-Server fungiert, die Zeit zwischen der Erkennung des ersten Pakets und des letzten Pakets durch das ExtraHop-System von gesendete Antworten. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen FIX-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn ein Server langsam reagiert, können Sie
anhand von Leistungsübersichtsmetriken herausfinden, ob das
Problem vom Netzwerk oder vom Server verursacht wird. Die Leistungsübersichtsmetriken zeigen das 95. Perzentil der Zeit, die der
Server für die Verarbeitung von Anfragen von Clients benötigte, im Vergleich zur 95. Perzentilzeit, die
Pakete aus diesen Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten.
Hohe Serververarbeitungszeiten deuten darauf hin, dass der Server langsam ist.
Hohe RTTs weisen darauf hin, dass der Server über langsame Netzwerke kommuniziert.
Metrisch Beschreibung FIX Verarbeitungszeit des Serverservers Wenn das Gerät als FIX-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen FIX-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
FIX-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche FIX-Methoden auf dem Server am häufigsten aufgerufen wurden, indem die Gesamtzahl der Anfragen, die der Server erhalten hat, nach Methode aufgeteilt wird.
- Die besten Versionen
- Dieses Diagramm zeigt, über welche Versionen des FIX-Protokolls der Server am meisten kommuniziert hat, indem es die Gesamtzahl der Anfragen aufschlüsselt, die der Server von der FIX-Version erhalten hat.
- Die wichtigsten Ziele
- Dieses Diagramm zeigt die wichtigsten FIX-Ziele für den Server, indem die Gesamtzahl der Anfragen, die der Server erhalten hat, nach Ziel aufgeteilt wird.
FIX-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung FIX Verarbeitungszeit des Serverservers Wenn das Gerät als FIX-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort. - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Verarbeitungszeit für den Server.
Metrisch Beschreibung FIX Verarbeitungszeit des Serverservers Wenn das Gerät als FIX-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort. - Verteilung von Hin- und Rückflügen
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen FIX-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Roundtrip-Zeit für den Server.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen FIX-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
FIX Metrische Summen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr
Anfragen, als der Server verarbeiten kann, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen
, ob das Problem beim Netzwerk oder beim Server liegt, überprüfen Sie RTOs und Zero Windows in der
Netzwerk-Daten
Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der FIX-Anfragen und -Antworten exakt gleich sein wird, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät erhalten hat wenn Sie als FIX-Server agieren. Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als FIX-Server. Fehler Wenn das Gerät als FIX-Server fungiert, die Anzahl der gesendeten Fehlerantworten. Diese Metriken beinhalten nicht die Verarbeitung von Bestell- und Handelsfehler. Abgebrochene Anfragen Die Anzahl der Anfragen, die dieser FIX-Server begann zu empfangen, erhielt aber nicht vollständig. Abgebrochene Antworten Die Anzahl der Antworten, die dieser FIX-Server begann zu senden, sendete aber nicht vollständig. POS-Duplikat Die Anzahl möglicher doppelter gesendeter Nachrichten wenn das Gerät als FIX-Server fungiert. Wenn eine FIX-Engine nicht sicher ist, ob eine Meldung wurde erfolgreich am vorgesehenen Ziel oder als Antwort auf ein erneutes Senden empfangen Bei einer Anfrage wird eine mögliche doppelte (PossDup) -Nachricht generiert POS erneut senden Die Anzahl der möglichen gesendeten Nachrichten zum erneuten Senden wenn das Gerät als FIX-Server fungiert. Mehrdeutige Meldungen auf Anwendungsebene kann erneut versendet werden, wenn eine Bestellung über einen übermäßigen Zeitraum von unbestätigt bleibt Zeit. - Durchschnittliche Anfrage- und Antwortgröße
- Dieses Diagramm zeigt die durchschnittliche Größe der Anfragen und Antworten.
Metrisch Beschreibung Größe der Anfrage Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät empfangen hat, als es als FIX-Server fungierte. Größe der Antwort Die Verteilung der Größen (in Byte) von Antworten, die empfangen werden, wenn das Gerät als FIX-Server fungiert.
FIX-Kundengruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt FIX Serververkehr, der einer Gerätegruppe in Ihrem Netzwerk zugeordnet ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
FIX Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann FIX-Fehler aufgetreten sind und wie viele Antworten die FIX-Clients
erhalten haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Kunden zu dem Zeitpunkt waren, als sie die Fehler
erhielten.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie weiter unten im Abschnitt Metriken für Gruppen.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als FIX-Client agieren. Fehler Wenn das Gerät als FIX-Client fungiert, die Anzahl der erhaltenen Fehlerantworten. Diese Metriken beinhalten nicht die Verarbeitung von Bestell- und Handelsfehlern. - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele FIX-Antworten die Kunden erhalten haben und wie viele dieser
Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als FIX-Client agieren. Fehler Wenn das Gerät als FIX-Client fungiert, die Anzahl der erhaltenen Fehlerantworten. Diese Metriken beinhalten nicht die Verarbeitung von Bestell- und Handelsfehlern.
FIX-Details für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (FIX-Kunden)
- Dieses Diagramm zeigt, welche FIX-Clients in der Gruppe am aktivsten waren, indem es die Gesamtzahl der FIX-Anfragen aufschlüsselt, die die Gruppe vom Client gesendet hat.
- Die besten Methoden
- Dieses Diagramm zeigt, welche FIX-Methoden die Gruppe am häufigsten aufgerufen hat, indem die Gesamtzahl der Anfragen, die die Gruppe gesendet hat, nach Methode aufgeteilt wird.
- Die besten Versionen
- Dieses Diagramm zeigt die wichtigsten FIX-Ziele für die Gruppe, indem die Gesamtzahl der Anfragen, die die Gruppe gesendet hat, nach Ziel aufgeteilt wird.
FIX-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden die Clients möglicherweise mehr Anfragen, als Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät gesendet hat, als fungiert als FIX-Kunde. Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als FIX-Client agieren. Fehler Wenn das Gerät als FIX-Client fungiert, die Anzahl der erhaltenen Fehlerantworten. Diese Metriken beinhalten nicht die Verarbeitung von Bestell- und Handelsfehlern. Abgebrochene Anfragen Die Anzahl der Anfragen, die dieser FIX-Client begann zu senden, sendete aber nicht vollständig. Abgebrochene Antworten Die Anzahl der Antworten, die dieser FIX-Client Das Gerät begann zu empfangen, empfing aber nicht vollständig. POS-Duplikat Die Anzahl möglicher doppelter Nachrichten, die das Gerät, das gesendet wurde, wenn es als FIX-Client fungiert. Wenn ein FIX-Motor nicht sicher ist, ob ein Nachricht wurde erfolgreich an ihrem vorgesehenen Ziel oder bei der Beantwortung von Bei einer erneuten Sendeanforderung wird eine mögliche doppelte (PossDup) -Nachricht generiert POS erneut senden Die Anzahl der möglichen Nachrichten, die erneut gesendet werden das Gerät, das gesendet wurde, wenn es als FIX-Client fungiert. Mehrdeutige Meldungen auf Anwendungsebene kann erneut versendet werden, wenn eine Bestellung über einen übermäßigen Zeitraum von unbestätigt bleibt Zeit. - Verarbeitungszeit des Servers
-
Wenn sich eine Client-Gruppe langsam verhält, können Sie anhand der Serververarbeitungszeit herausfinden,
ob das Problem bei den Servern liegt. Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche
Zeit, die Server für die Bearbeitung von Anfragen von den Clients benötigten. Hohe
Serververarbeitungszeiten deuten darauf hin, dass die Clients langsame Server kontaktieren.
Metrisch Beschreibung FIX Verarbeitungszeit des Client-Servers Wenn das Gerät als FIX-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort.
FIX-Servergruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt FIX Serververkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
FIX Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann FIX-Fehler aufgetreten sind und wie viele FIX-Antworten die Server
gesendet haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Server zu dem Zeitpunkt waren, als sie
die Fehler gemeldet haben.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie weiter unten im Abschnitt Metriken für Gruppen.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als FIX-Server. Fehler Wenn das Gerät als FIX-Server fungiert, die Anzahl der gesendeten Fehlerantworten. Diese Metriken beinhalten nicht die Verarbeitung von Bestell- und Handelsfehler. - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele FIX-Antwortserver in der Gruppe gesendet haben und wie viele dieser
Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als FIX-Server. Fehler Wenn das Gerät als FIX-Server fungiert, die Anzahl der gesendeten Fehlerantworten. Diese Metriken beinhalten nicht die Verarbeitung von Bestell- und Handelsfehler.
FIX-Details für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (FIX-Server)
- Dieses Diagramm zeigt, welche FIX-Server in der Gruppe am aktivsten waren, indem die Gesamtzahl der FIX-Antworten, die die Gruppe vom Server gesendet hat, aufgeschlüsselt wird.
- Die besten Methoden
- Dieses Diagramm zeigt, welche FIX-Methoden auf Servern in der Gruppe am häufigsten aufgerufen wurden, indem die Gesamtzahl der Anfragen, die die Gruppe erhalten hat, nach Methode aufgeteilt wird.
- Die besten Versionen
- Dieses Diagramm zeigt die wichtigsten FIX-Ziele für die Gruppe, indem die Gesamtzahl der Anfragen, die die Gruppe erhalten hat, nach Zielen aufgeteilt wird.
Metriken für Gruppe korrigieren
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden Clients möglicherweise mehr Anfragen, als die Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät erhalten hat wenn Sie als FIX-Server agieren. Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als FIX-Server. Fehler Wenn das Gerät als FIX-Server fungiert, die Anzahl der gesendeten Fehlerantworten. Diese Metriken beinhalten nicht die Verarbeitung von Bestell- und Handelsfehler. Abgebrochene Anfragen Die Anzahl der Anfragen, die dieser FIX-Server begann zu empfangen, erhielt aber nicht vollständig. Abgebrochene Antworten Die Anzahl der Antworten, die dieser FIX-Server begann zu senden, sendete aber nicht vollständig. POS-Duplikat Die Anzahl möglicher doppelter gesendeter Nachrichten wenn das Gerät als FIX-Server fungiert. Wenn eine FIX-Engine nicht sicher ist, ob eine Meldung wurde erfolgreich am vorgesehenen Ziel oder als Antwort auf ein erneutes Senden empfangen Bei einer Anfrage wird eine mögliche doppelte (PossDup) -Nachricht generiert POS erneut senden Die Anzahl der möglichen gesendeten Nachrichten zum erneuten Senden wenn das Gerät als FIX-Server fungiert. Mehrdeutige Meldungen auf Anwendungsebene kann erneut versendet werden, wenn eine Bestellung über einen übermäßigen Zeitraum von unbestätigt bleibt Zeit. - Verarbeitungszeit des Servers
-
Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche Zeit, die die Server für die
Bearbeitung von Anfragen von Clients benötigten. Hohe Serververarbeitungszeiten deuten darauf hin, dass die Server in einer
Gruppe langsam sind.
Metrisch Beschreibung FIX Verarbeitungszeit des Serverservers Wenn das Gerät als FIX-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort.
FTP
Das ExtraHop-System sammelt Metriken über das FTP (FTP) Aktivität. FTP) ist ein Standard-Netzwerkprotokoll für die Übertragung von Dateien zwischen einem Client und einem Server.
Erfahren Sie mehr, indem Sie an der FTP Quick Peek-Schulung teilnehmen.
Überlegungen zur Sicherheit
- Die FTP-Authentifizierung kann anfällig sein für Brute-Force, bei der es sich um eine Methode zum Erraten von Anmeldedaten handelt, indem zahlreiche Authentifizierungsanfragen mit unterschiedlichen Kombinationen aus Benutzername und Passwort eingereicht werden.
- Durch die anonyme FTP-Authentifizierung können vertrauliche Daten unbefugten Benutzern zugänglich gemacht werden.
FTP-Anwendungsseite
Auf dieser Seite werden Metrikdiagramme von angezeigt FTP Verkehr, der mit einem Anwendungscontainer in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur FTP-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
FTP Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann FTP-Fehler, -Warnungen und -Antworten mit der
Anwendung verknüpft waren. Anhand dieser Informationen können Sie feststellen, wie aktiv die Anwendung zum
Zeitpunkt des Auftretens der Fehler und Warnungen war.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Warnungen Die Anzahl der Antworten mit einem FTP-Status Code von 4xx Antworten Die Anzahl der FTP-Antworten. Fehler Die Anzahl der FTP-Antworten Fehler. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der FTP-Antworten, die mit der
Anwendung verknüpft waren, und wie viele dieser Antworten Warnungen und Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der FTP-Antworten. Fehler Die Anzahl der FTP-Antworten Fehler. - Leistung (95. Perzentil)
-
Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken.
Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer vollständigen
Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange Clients gebraucht haben, um Anfragen an
das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange die Server für die Bearbeitung von Anfragen gebraucht haben;
und die Antwortübertragungszeit zeigt, wie lange die Server gebraucht haben, um Antworten an
das Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Transferzeit anfragen Die Zeit zwischen der Erkennung durch das ExtraHop-System das erste Paket und das letzte Paket von FTP-Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit des Servers Die Zeit zwischen der Erkennung durch das ExtraHop-System das letzte Paket von FTP-Anfragen und das erste Paket der entsprechenden Anfragen Antworten. Übertragungszeit der Antwort Die Zeit zwischen der Erkennung durch das ExtraHop-System das erste Paket und das letzte Paket von FTP-Antworten. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines FTP-Clients oder Server Paket, das sofort bestätigt werden muss und wann die Bestätigung erfolgte erhalten. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn eine Anwendung langsam reagiert, können Sie anhand
von Leistungsübersichtsmetriken herausfinden, ob das Netzwerk oder die Server das
Problem verursachen. Diese Metriken zeigen das 95. Perzentil der Zeit, die Server für die Bearbeitung von
Anfragen von Clients benötigten, im Vergleich zum 95. Perzentil der Zeit, die Pakete aus diesen Anfragen
(und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten. Hohe
Serververarbeitungszeiten deuten darauf hin, dass Clients langsame Server kontaktieren. Hohe
TCP-Roundtrip-Zeiten deuten darauf hin, dass Clients über langsame Netzwerke kommunizieren.
Metrisch Beschreibung Verarbeitungszeit des Servers Die Zeit zwischen der Erkennung durch das ExtraHop-System das letzte Paket von FTP-Anfragen und das erste Paket der entsprechenden Anfragen Antworten. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines FTP-Clients oder Server Paket, das sofort bestätigt werden muss und wann die Bestätigung erfolgte erhalten.
FTP-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche FTP-Methoden mit der Anwendung verknüpft waren, indem die Gesamtzahl der FTP-Anfragen nach Methoden aufgeschlüsselt wird.
- Die wichtigsten Statuscodes
- Dieses Diagramm zeigt, welche FTP-Statuscodes der Server am häufigsten zurückgegeben hat, indem die Gesamtzahl der Antworten, die die Anwendung gesendet hat, nach Statuscode aufgeteilt wird.
- Die besten Nutzer
- Dieses Diagramm zeigt, welche Benutzer in der Anwendung am aktivsten waren, indem es die Gesamtzahl der von der Anwendung gesendeten FTP-Anfragen aufschlüsselt.
FTP-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des FTP-Servers Die Zeit zwischen der Erkennung durch das ExtraHop-System das letzte Paket von FTP-Anfragen und das erste Paket der entsprechenden Anfragen Antworten. - Verarbeitungszeit des Servers
-
Diese Tabelle zeigt die durchschnittliche Bearbeitungszeit für den Anwendung.
Metrisch Beschreibung Verarbeitungszeit des FTP-Servers Die Zeit zwischen der Erkennung durch das ExtraHop-System das letzte Paket von FTP-Anfragen und das erste Paket der entsprechenden Anfragen Antworten. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines FTP-Clients oder Server Paket, das sofort bestätigt werden muss und wann die Bestätigung erfolgte erhalten. - Zeit für Hin- und Rückfahrt
-
Diese Tabelle zeigt
die durchschnittliche Hin- und Rückflugzeit für die Anwendung.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines FTP-Clients oder Server Paket, das sofort bestätigt werden muss und wann die Bestätigung erfolgte erhalten.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass ein Problem mit einem Server oder einem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
-
Dieses Diagramm zeigt die Anzahl der Nullfenster, die einer Anwendung
zugeordnet waren. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der Pakete
angeben, die über einen bestimmten Zeitraum an sie gesendet werden können.
Wenn an ein Gerät mehr Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein
Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig einzustellen, bis das Gerät den Vorgang
aufholt. Wenn Sie eine große Anzahl von Nullfenstern sehen, ist ein Server oder Client möglicherweise
nicht schnell genug, um die empfangene Datenmenge zu unterstützen.
Metrisch Definition Zero Windows anfordern Die Anzahl der gesendeten Null-Window-Anzeigen von FTP-Clients. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl eingehender Zero-Windows weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Antwort Null Windows Die Anzahl der gesendeten Null-Window-Anzeigen von Servern beim Empfang von FTP-Anfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von ausgehenden Zero-Windows weist darauf hin, dass ein Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Gesamtzahl der Host-Stände
- Dieses Diagramm zeigt die durchschnittliche Anzahl von Zero-Window-Werbeanzeigen, die von Geräten gesendet wurden.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen
Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu
viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät
eine Anfrage oder Antwort sendet und innerhalb einer bestimmten
Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen
nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise
zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Timeouts für die erneute Übertragung (RTOs) verursacht durch eine Überlastung, als Clients FTP-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server FTP-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
- Gesamtzahl der Netzwerkausfälle
-
Dieses Diagramm zeigt die durchschnittliche Anzahl von Timeouts bei der
erneuten Übertragung, die durch Überlastung beim Senden von Anfragen durch Clients und Server verursacht wurden.
Metrisch Definition RTOs Ein Die Anzahl der Timeouts für die erneute Übertragung (RTOs) verursacht durch eine Überlastung, als Clients FTP-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server FTP-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Gesamtwerte der FTP-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr Anfragen, als Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um herauszufinden, ob das Problem mit dem Netzwerk oder einem Server zusammenhängt, überprüfen Sie RTOs und Zero Windows in der Netzwerk-Daten Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der FTP-Anfragen und -Antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der FTP-Anfragen. Antworten Die Anzahl der FTP-Antworten. Fehler Die Anzahl der FTP-Antworten Fehler. Warnungen Die Anzahl der Antworten mit einem FTP-Status Code von 4xx - FTP-Netzwerkmetriken
-
Metrisch Beschreibung Zero Windows anfordern Die Anzahl der gesendeten Null-Window-Anzeigen von FTP-Clients. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Antwort Null Windows Die Anzahl der gesendeten Null-Window-Anzeigen von Servern beim Empfang von FTP-Anfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. RTOs anfragen Die Anzahl der Timeouts für die erneute Übertragung (RTOs) verursacht durch eine Überlastung, als Clients FTP-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Antwort-RTOs Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server FTP-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. L2-Byte anfordern Die Anzahl der mit FTP verknüpften L2-Bytes Anfragen. Antwort L2 Byte Die Anzahl der mit FTP verknüpften L2-Bytes Antworten. Goodput Bytes anfordern Die Anzahl der Goodput-Bytes, die mit verknüpft sind FTP-Anfragen. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Antwort Goodput Bytes Die Anzahl der Goodput-Bytes, die mit verknüpft sind FTP-Antworten. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Pakete anfordern Die Anzahl der mit FTP verknüpften Pakete Anfragen. Antwortpakete Die Anzahl der mit FTP verknüpften Pakete Antworten.
FTP-Client-Seite
Auf dieser Seite werden Metrikdiagramme von angezeigt FTP Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur FTP-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
FTP Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann FTP-Fehler aufgetreten sind und wie viele Antworten der FTP-Client
erhalten hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Client zu dem Zeitpunkt war, als er die Fehler
empfing.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Warnungen Die Anzahl der Antworten mit einem Statuscode von 4xx, die das Gerät empfangen hat, als es als FTP-Client fungierte Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als FTP-Client agieren. Fehler Die Anzahl der Fehler, die das Gerät hat empfangen, wenn ich als FTP-Client agiere. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der FTP-Antworten, die der Client erhalten hat, und wie viele
dieser Antworten Fehler und Warnungen enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als FTP-Client agieren. Fehler Die Anzahl der Fehler, die das Gerät hat empfangen, wenn ich als FTP-Client agiere. Warnungen Die Anzahl der Antworten mit einem Statuscode von 4xx, die das Gerät empfangen hat, als es als FTP-Client fungierte - Leistung (95. Perzentil)
- Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken. Die Serververarbeitungszeit
gibt an, wie lange Server gebraucht haben, um Anfragen vom Client zu verarbeiten. Die Metrik Round Trip Time
(RTT) misst, wie lange es gedauert hat, bis Pakete
vom Client oder Server sofort bestätigt wurden. Das ExtraHop-System berechnet RTT, indem es die Zeit
zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt
:
RTT misst nur, wie lange es dauert, bis eine sofortige Bestätigung gesendet wird; es wartet nicht, bis alle Pakete zugestellt sind. Daher ist RTT ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Verarbeitungszeiten sehen, aber die TCP-RTT niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die TCP-RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Übertragungszeit der FTP-Client-Anfrage Wenn das Gerät als FTP-Client fungiert, die Zeit zwischen der Erkennung des ersten Pakets und des letzten Pakets durch das ExtraHop-System von gesendete Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit des FTP-Client-Servers Wenn das Gerät als FTP-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort. Übertragungszeit der FTP-Client-Antwort Wenn das Gerät als FTP-Client fungiert, die Zeit zwischen der Erkennung des ersten Pakets und des letzten Pakets durch das ExtraHop-System von erhaltene Antworten. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen FTP-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn ein Client langsam reagiert, können Sie
anhand von Leistungsübersichtsmetriken herausfinden, ob das Netzwerk oder die Server das Problem verursachen.
Diese Metriken zeigen das 95. Perzentil der Zeit, die Server für die Bearbeitung von
Anfragen vom Client benötigten, im Vergleich zur 95. Perzentilzeit, die Pakete aus diesen
Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten.
Hohe Serververarbeitungszeiten deuten darauf hin, dass der Client langsame Server kontaktiert. Hohe
TCP-Roundtrip-Zeiten deuten darauf hin, dass der Client über langsame
Netzwerke kommuniziert.
Metrisch Beschreibung Verarbeitungszeit des FTP-Client-Servers Wenn das Gerät als FTP-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen FTP-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
FTP-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche FTP-Methoden der Client am häufigsten aufgerufen hat, indem die Gesamtzahl der Anfragen, die der Client gesendet hat, nach Methode aufgeteilt wird.
- Die wichtigsten Statuscodes
- Dieses Diagramm zeigt, welche FTP-Statuscodes der Client am häufigsten erhalten hat, indem die Anzahl der an den Client zurückgegebenen Antworten nach Statuscode aufgeteilt wird.
- Die besten Nutzer
- Dieses Diagramm zeigt, welche Benutzer auf dem Client am aktivsten waren, indem es die Gesamtzahl der vom Client gesendeten FTP-Anfragen nach Benutzern aufschlüsselt.
FTP-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Aufschlüsselung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des FTP-Client-Servers Wenn das Gerät als FTP-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort. - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Bearbeitungszeit für den Client.
Metrisch Beschreibung Verarbeitungszeit des FTP-Client-Servers Wenn das Gerät als FTP-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen FTP-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Hin- und Rückflugzeit für den Client.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen FTP-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Gesamtwerte der FTP-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, sendet der Client möglicherweise mehr
Anfragen, als die Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen
, ob das Problem am Netzwerk oder am Server liegt, überprüfen Sie RTOs und Zero Windows in der
Netzwerk-Daten
Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der FTP-Anfragen und -Antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der FTP-Anfragen, die mit dem Befehl gesendet wurden Verbindung, wenn das Gerät als FTP-Client fungiert. Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als FTP-Client agieren. Warnungen Die Anzahl der Antworten mit einem Statuscode von 4xx, die das Gerät empfangen hat, als es als FTP-Client fungierte Fehler Die Anzahl der Fehler, die das Gerät hat empfangen, wenn ich als FTP-Client agiere. Datenanfragen Die Anzahl der Datenanfragen, die das Gerät anfordert gesendet, wenn Sie als FTP-Client agieren. Daten verbinden Die Anzahl der Datenverbindungen wird eingerichtet, wenn das Gerät als FTP-Client fungiert. - Größe der Anfrage und Antwort
- Dieses Diagramm zeigt die durchschnittliche Größe der Anfragen und Antworten.
Metrisch Beschreibung Größe der Anfrage Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät gesendet hat, als es als Datenbankclient agiert. Größe der Antwort Die Verteilung der Größen (in Byte) von Antworten, die das Gerät erhalten hat, als es als Datenbankclient agiert hat.
FTP-Serverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt FTP Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur FTP-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
FTP-Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt die Gesamtzahl der FTP-Antworten, die der Server gesendet hat, und wie viele
dieser Antworten Fehler und Warnungen enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als FTP-Server. Fehler Die Anzahl der Fehler, die das Gerät gesendet hat wenn Sie als FTP-Server agieren. Warnungen Die Anzahl der Antworten mit einem Statuscode von 4xx, die das Gerät gesendet hat, als es als FTP-Server fungierte - Zusammenfassung der Transaktion
- Dieses Diagramm zeigt Ihnen, wann FTP-Fehler aufgetreten sind und wie viele FTP-Antworten der Server
gesendet hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Server zu dem Zeitpunkt war, als er die Fehler
zurückgab.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als FTP-Server. Fehler Die Anzahl der Fehler, die das Gerät gesendet hat wenn Sie als FTP-Server agieren. Warnungen Die Anzahl der Antworten mit einem Statuscode von 4xx, die das Gerät gesendet hat, als es als FTP-Server fungierte - Leistung (95. Perzentil)
- Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken. Die Serververarbeitungszeit
gibt an, wie lange der Server gebraucht hat, um Anfragen von Clients zu verarbeiten. Die Metrik Round Trip Time
(RTT) misst, wie lange es gedauert hat, bis Pakete
vom Client oder Server sofort bestätigt wurden. Das ExtraHop-System berechnet RTT, indem es die Zeit
zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt
:
RTT misst nur, wie lange es dauert, bis eine sofortige Bestätigung gesendet wird; es wartet nicht, bis alle Pakete zugestellt sind. Daher ist RTT ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Verarbeitungszeiten feststellen, die TCP-RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die TCP-RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Übertragungszeit der FTP-Serveranfrage Wenn das Gerät als FTP-Server fungiert, die Zeit zwischen der Erkennung des ersten Pakets und des letzten Pakets durch das ExtraHop-System von eingegangene Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit des FTP-Servers Wenn das Gerät als FTP-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort. Übertragungszeit der FTP-Server-Antwort Wenn das Gerät als FTP-Server fungiert, die Zeit zwischen der Erkennung des ersten Pakets und des letzten Pakets durch das ExtraHop-System von gesendete Antworten. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen FTP-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn ein Server langsam reagiert, können Sie
anhand von Leistungsübersichtsmetriken herausfinden, ob das
Problem vom Netzwerk oder vom Server verursacht wird. Die Leistungsübersichtsmetriken zeigen das 95. Perzentil der Zeit, die der
Server für die Verarbeitung von Anfragen von Clients benötigte, im Vergleich zur 95. Perzentilzeit, die
Pakete aus diesen Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten.
Hohe Serververarbeitungszeiten deuten darauf hin, dass der Server langsam ist.
Hohe RTTs weisen darauf hin, dass der Server über langsame Netzwerke kommuniziert.
Metrisch Beschreibung Verarbeitungszeit des FTP-Servers Wenn das Gerät als FTP-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen FTP-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
FTP-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche FTP-Methoden auf dem Server am häufigsten aufgerufen wurden, indem die Gesamtzahl der Anfragen, die der Server erhalten hat, nach Methode aufgeteilt wird.
- Die wichtigsten Statuscodes
- Dieses Diagramm zeigt, welche FTP-Statuscodes der Server am häufigsten zurückgegeben hat, indem die Gesamtzahl der vom Server gesendeten Antworten nach Statuscode aufgeschlüsselt wird.
- Die besten Nutzer
- Dieses Diagramm zeigt, welche Benutzer auf dem Server am aktivsten waren, indem die Gesamtzahl der vom Benutzer an den Server gesendeten FTP-Anfragen aufgeschlüsselt wird.
FTP-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des FTP-Servers Wenn das Gerät als FTP-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort. - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Verarbeitungszeit für den Server.
Metrisch Beschreibung Verarbeitungszeit des FTP-Servers Wenn das Gerät als FTP-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort. - Verteilung von Hin- und Rückflügen
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen FTP-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Roundtrip-Zeit für den Server.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen FTP-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Gesamtwerte der FTP-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr
Anfragen, als der Server verarbeiten kann, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen
, ob das Problem am Netzwerk oder am Server liegt, überprüfen Sie RTOs und Zero Windows in der
Netzwerk-Daten
Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der FTP-Anfragen und -Antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der FTP-Anfragen, die mit dem Befehl empfangen wurden Verbindung, wenn das Gerät als FTP-Server fungiert. Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als FTP-Server. Fehler Die Anzahl der Fehler, die das Gerät gesendet hat wenn Sie als FTP-Server agieren. Warnungen Die Anzahl der Antworten mit einem Statuscode von 4xx, die das Gerät gesendet hat, als es als FTP-Server fungierte Datenanfragen Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät empfangen hat, als es als FTP-Server fungiert. Daten verbinden Die Verteilung der Größen (in Byte) von Antworten, die das Gerät gesendet hat, als es als FTP-Server fungiert. - Größe der Anfrage und Antwort
- Dieses Diagramm zeigt die durchschnittliche Größe der Anfragen und Antworten.
Metrisch Beschreibung Größe der Anfrage Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät empfangen hat, als es als Datenbankserver fungierte. Größe der Antwort Die Verteilung der Größen (in Byte) von Antworten, die das Gerät gesendet hat, als es als Datenbankserver fungierte.
FTP-Client-Gruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt FTP Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur FTP-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
FTP Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann FTP-Fehler aufgetreten sind und wie viele Antworten die FTP-Clients
erhalten haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Kunden zu dem Zeitpunkt waren, als sie die Fehler
erhielten.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie weiter unten im Abschnitt Metriken für Gruppen.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als FTP-Client agieren. Fehler Die Anzahl der Fehler, die das Gerät hat empfangen, wenn ich als FTP-Client agiere. - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele FTP-Antworten die Clients erhalten haben und wie viele dieser
Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als FTP-Client agieren. Fehler Die Anzahl der Fehler, die das Gerät hat empfangen, wenn ich als FTP-Client agiere.
FTP-Details für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (FTP-Clients)
- Dieses Diagramm zeigt, welche FTP-Clients in der Gruppe am aktivsten waren, indem es die Gesamtzahl der FTP-Anfragen aufschlüsselt, die die Gruppe vom Client gesendet hat.
- Die besten Methoden
- Dieses Diagramm zeigt, welche FTP-Methoden die Gruppe am häufigsten aufgerufen hat, indem die Gesamtzahl der Anfragen, die die Gruppe gesendet hat, nach Methode aufgeteilt wird.
- Die wichtigsten Statuscodes
- Dieses Diagramm zeigt, welche FTP-Statuscodes die Gruppe am häufigsten erhalten hat, indem die Anzahl der an die Gruppe zurückgegebenen Antworten nach Statuscode aufgeschlüsselt wird.
FTP-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden die Clients möglicherweise mehr Anfragen, als Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der FTP-Anfragen, die mit dem Befehl gesendet wurden Verbindung, wenn das Gerät als FTP-Client fungiert. Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als FTP-Client agieren. Warnungen Die Anzahl der Antworten mit einem Statuscode von 4xx, die das Gerät empfangen hat, als es als FTP-Client fungierte Fehler Die Anzahl der Fehler, die das Gerät hat empfangen, wenn ich als FTP-Client agiere. Datenanfragen Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät gesendet hat, als es als FTP-Client fungiert. Daten verbinden Die Verteilung der Größen (in Byte) von Antworten, die das Gerät erhalten hat, als es als FTP-Client agiert hat. - Verarbeitungszeit des Servers
-
Wenn sich eine Client-Gruppe langsam verhält, können Sie anhand der Serververarbeitungszeit herausfinden,
ob das Problem bei den Servern liegt. Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche
Zeit, die Server für die Bearbeitung von Anfragen von den Clients benötigten. Hohe
Serververarbeitungszeiten deuten darauf hin, dass die Clients langsame Server kontaktieren.
Metrisch Beschreibung Verarbeitungszeit des FTP-Client-Servers Wenn das Gerät als FTP-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort.
FTP-Servergruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt FTP Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur FTP-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
FTP Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann FTP-Fehler aufgetreten sind und wie viele FTP-Antworten die Server
gesendet haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Server zu dem Zeitpunkt waren, als sie
die Fehler gemeldet haben.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie weiter unten im Abschnitt Metriken für Gruppen.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als FTP-Server. Fehler Die Anzahl der Fehler, die das Gerät gesendet hat wenn Sie als FTP-Server agieren. - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele FTP-Antwortserver in der Gruppe gesendet haben und wie viele dieser
Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als FTP-Server. Fehler Die Anzahl der Fehler, die das Gerät gesendet hat wenn Sie als FTP-Server agieren.
FTP-Details für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (FTP-Server)
- Dieses Diagramm zeigt, welche FTP-Server in der Gruppe am aktivsten waren, indem es die Gesamtzahl der FTP-Antworten aufschlüsselt, die die Gruppe vom Server gesendet hat.
- Die besten Methoden
- Dieses Diagramm zeigt, welche FTP-Methoden auf Servern in der Gruppe am häufigsten aufgerufen wurden, indem die Gesamtzahl der Anfragen, die die Gruppe erhalten hat, nach Methode aufgeteilt wird.
- Wichtigster Statuscode
- Dieses Diagramm zeigt, welche FTP-Statuscodes die Gruppen am häufigsten zurückgegeben haben, indem die Gesamtzahl der von der Gruppe gesendeten Antworten nach Statuscode aufgeschlüsselt wird.
FTP-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden Clients möglicherweise mehr Anfragen, als die Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der FTP-Anfragen, die mit dem Befehl empfangen wurden Verbindung, wenn das Gerät als FTP-Server fungiert. Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als FTP-Server. Fehler Die Anzahl der Fehler, die das Gerät gesendet hat wenn Sie als FTP-Server agieren. Warnungen Die Anzahl der Antworten mit einem Statuscode von 4xx, die das Gerät gesendet hat, als es als FTP-Server fungierte Datenanfragen Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät empfangen hat, als es als FTP-Server fungiert. Daten verbinden Die Verteilung der Größen (in Byte) von Antworten, die das Gerät gesendet hat, als es als FTP-Server fungiert. - Verarbeitungszeit des Servers
-
Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche Zeit, die die Server für die
Bearbeitung von Anfragen von Clients benötigten. Hohe Serververarbeitungszeiten deuten darauf hin, dass die Server in einer
Gruppe langsam sind.
Metrisch Beschreibung Verarbeitungszeit des FTP-Servers Wenn das Gerät als FTP-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort.
HL7
Das ExtraHop-System sammelt Messwerte über Health Level-7 (HL7) Aktivität. HL7 ist ein Standardprotokoll für den Austausch von elektronischen Gesundheitsinformationen zwischen Softwareanwendungen.
| Hinweis: | Das ExtraHop-System enthält keine integrierten Metrikseiten für HL7. Sie können HL7-Metriken jedoch anzeigen, indem Sie sie zu einer benutzerdefinierten Seite hinzufügen oder Dashboard. |
HTTP
Das ExtraHop-System sammelt Metriken über das Hypertext Transfer Protocol (HTTP) Aktivität. HTTP ist ein Kommunikationsprotokoll für Informationssysteme, das es Benutzern ermöglicht, Daten im World Wide Web bereitzustellen. Die HTTPS-Aktivität wird entschlüsselt und dann als HTTP-Aktivität angezeigt.
Überlegungen zur Sicherheit
- HTTP-Anfragen und -Antworten können mit bösartigen Skripten in einem Siteübergreifendes Scripting (XSS) Angriff.
- Schmuggel von HTTP-Anfragen ist ein Angriff auf Webanwendung, der Inkonsistenzen in der Art und Weise ausnutzt, wie Front-End-Server (Proxys) und Back-End-Server Anfragen von mehr als einem Absender verarbeiten.
- Malware kann sich tarnen Command-and-Control-Beaconing (C&C) zwischen einem kompromittierten Gerät und einem von einem Angreifer kontrollierten Server als legitimer HTTP-Verkehr.
- Unverschlüsselter HTTP-Verkehr könnte sensible Daten für Angreifer preisgeben, die den HTTP-Verkehr abfangen.
- Verschlüsselter HTTPS-Verkehr ist ein zunehmend verbreiteter Vektor für bösartige Aktivität. Sie können das ExtraHop-System so konfigurieren SSL-/TLS-Verkehr entschlüsseln um Erkennungen zu ermöglichen, mit denen verdächtiges Verhalten und potenzielle Angriffe identifiziert werden können.
HTTP-Anwendungsseite
Auf dieser Seite werden Metrikdiagramme von angezeigt HTTP Verkehr, der mit einem Anwendungscontainer in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur HTTP-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
HTTP Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann HTTP-Fehler und -Antworten mit der
Anwendung verknüpft waren. Anhand dieser Informationen können Sie feststellen, wie aktiv die Anwendung zum
Zeitpunkt des Auftretens der Fehler war.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der von HTTP-Servern gesendeten HTTP-Antworten die mit der Anwendung verknüpft sind. Eine HTTP-Antwort kann einen Statuscode enthalten und den Inhaltstyp. Ein HTTP/2-Server-Push zählt als eine Antwort Fehler Die Anzahl der HTTP-Antwortnachrichten mit einem 500-599 Statuscode, der darauf hinweist, dass der Server offenbar einen Fehler nicht erfüllt hat gültige Anfrage. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der HTTP-Antworten, die mit der
Anwendung verknüpft waren, und wie viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der von HTTP-Servern gesendeten HTTP-Antworten die mit der Anwendung verknüpft sind. Eine HTTP-Antwort kann einen Statuscode enthalten und den Inhaltstyp. Ein HTTP/2-Server-Push zählt als eine Antwort Fehler Die Anzahl der HTTP-Antwortnachrichten mit einem 500-599 Statuscode, der darauf hinweist, dass der Server offenbar einen Fehler nicht erfüllt hat gültige Anfrage. - Leistung (95. Perzentil)
-
Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken.
Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer vollständigen
Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange Clients gebraucht haben, um Anfragen an
das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange die Server für die Bearbeitung von Anfragen gebraucht haben;
und die Antwortübertragungszeit zeigt, wie lange die Server gebraucht haben, um Antworten an
das Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Transferzeit anfragen Die Zeit zwischen der Erkennung durch das ExtraHop-System das erste Paket und das letzte Paket von HTTP-Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit des Servers Die Zeit, die HTTP-Server brauchten, um das zu senden erstes Paket einer Antwort nach dem Empfang des letzten Paket einer Anfrage. Übertragungszeit der Antwort Die Zeit zwischen der Erkennung durch das ExtraHop-System das erste Paket und das letzte Paket von HTTP-Antworten. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Round Trip Time (RTT) ist ein Maß für die Gesamtzahl Netzwerklatenz. Das ExtraHop-System berechnet RTT, indem es die benötigte Zeit misst für HTTP-Geräte, um Pakete zu senden und sofortige Bestätigungen (ACK) über eine TCP-Verbindung. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn eine Anwendung langsam reagiert, können Sie anhand
von Leistungsübersichtsmetriken herausfinden, ob das Netzwerk oder die Server das
Problem verursachen. Diese Metriken zeigen das 95. Perzentil der Zeit, die Server für die Bearbeitung von
Anfragen von Clients benötigten, im Vergleich zum 95. Perzentil der Zeit, die Pakete aus diesen Anfragen
(und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten. Hohe
Serververarbeitungszeiten deuten darauf hin, dass Clients langsame Server kontaktieren. Hohe
TCP-Roundtrip-Zeiten deuten darauf hin, dass Clients über langsame Netzwerke kommunizieren.
Metrisch Beschreibung Verarbeitungszeit des Servers Die Zeit, die HTTP-Server brauchten, um das zu senden erstes Paket einer Antwort nach dem Empfang des letzten Paket einer Anfrage. Zeit für Hin- und Rückfahrt Round Trip Time (RTT) ist ein Maß für die Gesamtzahl Netzwerklatenz. Das ExtraHop-System berechnet RTT, indem es die benötigte Zeit misst für HTTP-Geräte, um Pakete zu senden und sofortige Bestätigungen (ACK) über eine TCP-Verbindung.
HTTP-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche HTTP-Methoden mit der Anwendung verknüpft waren, indem die Gesamtzahl der HTTP-Anfragen nach Methoden aufgeschlüsselt wird.
- Die häufigsten Fehlertypen
- Dieses Diagramm zeigt, welche HTTP-Statuscodes der Server am häufigsten zurückgegeben hat, indem die Gesamtzahl der Antworten, die die Anwendung gesendet hat, nach Statuscode aufgeteilt wird.
- Die besten URIs
- Dieses Diagramm zeigt, auf welche URIs die Anwendung am häufigsten zugegriffen hat, indem die Gesamtzahl der Antworten, die die Anwendung per URI erhalten hat, aufgeschlüsselt wird.
HTTP-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des HTTP-Servers Die Zeit, die HTTP-Server brauchten, um das zu senden erstes Paket einer Antwort nach dem Empfang des letzten Paket einer Anfrage. - Verarbeitungszeit des Servers
-
Diese Tabelle zeigt die durchschnittliche Bearbeitungszeit für den Anwendung.
Metrisch Beschreibung Verarbeitungszeit des HTTP-Servers Die Zeit, die HTTP-Server brauchten, um das zu senden erstes Paket einer Antwort nach dem Empfang des letzten Paket einer Anfrage. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Round Trip Time (RTT) ist ein Maß für die Gesamtzahl Netzwerklatenz. Das ExtraHop-System berechnet RTT, indem es die benötigte Zeit misst für HTTP-Geräte, um Pakete zu senden und sofortige Bestätigungen (ACK) über eine TCP-Verbindung. - Zeit für Hin- und Rückfahrt
-
Diese Tabelle zeigt
die durchschnittliche Hin- und Rückflugzeit für die Anwendung.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Round Trip Time (RTT) ist ein Maß für die Gesamtzahl Netzwerklatenz. Das ExtraHop-System berechnet RTT, indem es die benötigte Zeit misst für HTTP-Geräte, um Pakete zu senden und sofortige Bestätigungen (ACK) über eine TCP-Verbindung.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass ein Problem mit einem Server oder einem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
-
Dieses Diagramm zeigt die Anzahl der Nullfenster, die einer Anwendung
zugeordnet waren. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der Pakete
angeben, die über einen bestimmten Zeitraum an sie gesendet werden können.
Wenn an ein Gerät mehr Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein
Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig einzustellen, bis das Gerät den Vorgang
aufholt. Wenn Sie eine große Anzahl von Nullfenstern sehen, ist ein Server oder Client möglicherweise
nicht schnell genug, um die empfangene Datenmenge zu unterstützen.
Metrisch Definition Zero Windows anfordern Die Gesamtzahl der Null-Window-Werbungen gesendet von HTTP-Clients beim Empfangen von HTTP-Antworten. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl eingehender Zero-Windows weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Antwort Null Windows Die Gesamtzahl der Null-Window-Werbungen gesendet von Servern beim Empfang von HTTP-Anfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von ausgehenden Zero-Windows weist darauf hin, dass ein Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Gesamtzahl der Host-Stände
- Dieses Diagramm zeigt die durchschnittliche Anzahl von Zero-Window-Werbeanzeigen, die von Geräten gesendet wurden.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen
Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu
viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät
eine Anfrage oder Antwort sendet und innerhalb einer bestimmten
Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen
nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise
zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Timeouts für die erneute Übertragung (RTOs) erkannt, d. h. Stillstände von 1—5 Sekunden, die bei einer erneuten Übertragung der HTTP-Anfrage auftreten Pakete werden nicht sofort bestätigt (ACK). Eine hohe Anzahl von RTOs kann es Ihnen sagen Diese Netzwerküberlastung verlangsamt wahrscheinlich die Anfragetransaktionen Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der Timeouts für die erneute Übertragung (RTOs) erkannt, d. h. Stillstände von 1—5 Sekunden, die bei einer erneuten Übertragung der HTTP-Antwort auftreten Pakete werden nicht sofort bestätigt (ACK). Eine hohe Anzahl von RTOs kann es Ihnen sagen Diese Netzwerküberlastung verlangsamt wahrscheinlich die Anfragetransaktionen Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
- Gesamtzahl der Netzwerkausfälle
-
Dieses Diagramm zeigt die durchschnittliche Anzahl von Timeouts bei der
erneuten Übertragung, die durch Überlastung beim Senden von Anfragen durch Clients und Server verursacht wurden.
Metrisch Definition RTOs Ein Die Anzahl der Timeouts für die erneute Übertragung (RTOs) erkannt, d. h. Stillstände von 1—5 Sekunden, die bei einer erneuten Übertragung der HTTP-Anfrage auftreten Pakete werden nicht sofort bestätigt (ACK). Eine hohe Anzahl von RTOs kann es Ihnen sagen Diese Netzwerküberlastung verlangsamt wahrscheinlich die Anfragetransaktionen Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der Timeouts für die erneute Übertragung (RTOs) erkannt, d. h. Stillstände von 1—5 Sekunden, die bei einer erneuten Übertragung der HTTP-Antwort auftreten Pakete werden nicht sofort bestätigt (ACK). Eine hohe Anzahl von RTOs kann es Ihnen sagen Diese Netzwerküberlastung verlangsamt wahrscheinlich die Anfragetransaktionen Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Gesamtwerte der HTTP-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr Anfragen, als Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um herauszufinden, ob das Problem mit dem Netzwerk oder einem Server zusammenhängt, überprüfen Sie RTOs und Zero Windows in der Netzwerk-Daten Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der HTTP-Anfragen und -Antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der von HTTP-Clients gesendeten HTTP-Anfragen die mit der Anwendung verknüpft sind. Eine HTTP-Anfrage kann eine Methode beinhalten, eine eindeutiger Ressourcenbezeichner (URI) und Header, die Benutzerinformationen enthalten. Ein HTTP/2 Der von Servern gesendete PUSH_PROMISE-Frame zählt als eine Anfrage Antworten Die Anzahl der von HTTP-Servern gesendeten HTTP-Antworten die mit der Anwendung verknüpft sind. Eine HTTP-Antwort kann einen Statuscode enthalten und den Inhaltstyp. Ein HTTP/2-Server-Push zählt als eine Antwort Fehler Die Anzahl der HTTP-Antwortnachrichten mit einem 500-599 Statuscode, der darauf hinweist, dass der Server offenbar einen Fehler nicht erfüllt hat gültige Anfrage. Abgebrochene Anfragen Die Anzahl der HTTP-Anfragen, die nicht vollständig zwischen Geräten übertragen, weil die Verbindung unterbrochen wurde oder Die Verbindung wurde mit einem TCP-Reset (RST) oder FIN geschlossen Abgebrochene Antworten Die Anzahl der HTTP-Antworten, die nicht vollständig zwischen Geräten übertragen, weil die Verbindung unterbrochen wurde oder Die Verbindung wurde mit einem TCP-Reset (RST) oder FIN geschlossen - HTTP-Netzwerkmetriken
-
Metrisch Beschreibung Zero Windows anfordern Die Gesamtzahl der Null-Window-Werbungen gesendet von HTTP-Clients beim Empfangen von HTTP-Antworten. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Antwort Null Windows Die Gesamtzahl der Null-Window-Werbungen gesendet von Servern beim Empfang von HTTP-Anfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. RTOs anfragen Die Anzahl der Timeouts für die erneute Übertragung (RTOs) erkannt, d. h. Stillstände von 1—5 Sekunden, die bei einer erneuten Übertragung der HTTP-Anfrage auftreten Pakete werden nicht sofort bestätigt (ACK). Eine hohe Anzahl von RTOs kann es Ihnen sagen Diese Netzwerküberlastung verlangsamt wahrscheinlich die Anfragetransaktionen Antwort-RTOs Die Anzahl der Timeouts für die erneute Übertragung (RTOs) erkannt, d. h. Stillstände von 1—5 Sekunden, die bei einer erneuten Übertragung der HTTP-Antwort auftreten Pakete werden nicht sofort bestätigt (ACK). Eine hohe Anzahl von RTOs kann es Ihnen sagen Diese Netzwerküberlastung verlangsamt wahrscheinlich die Anfragetransaktionen L2-Byte anfordern Die Anzahl der L2-Bytes, die mit verknüpft sind HTTP-Anfragen. Antwort L2 Byte Die Anzahl der L2-Bytes, die mit verknüpft sind HTTP-Antworten. Goodput Bytes anfordern Die Anzahl der Goodput-Bytes, die mit verknüpft sind HTTP-Anfragen. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Antwort Goodput Bytes Die Anzahl der Goodput-Bytes, die mit verknüpft sind HTTP-Antworten. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Pakete anfordern Die Anzahl der Pakete, die mit HTTP verknüpft sind Anfragen. Antwortpakete Die Anzahl der Pakete, die mit HTTP verknüpft sind Antworten.
HTTP-Client-Seite
Auf dieser Seite werden Metrikdiagramme von angezeigt HTTP Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur HTTP-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
HTTP Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann HTTP-Fehler aufgetreten sind und wie viele Antworten der HTTP-Client
erhalten hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Client zum Zeitpunkt des
Eingangs der Fehler war.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie einen Drilldown durchführen, um den spezifischen Statuscode zu finden, der in der Anfrage zurückgegeben wurde, und zu erfahren, warum der Server die Anfrage nicht erfüllen konnte. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von HTTP-Anfragen zu HTTP-Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Hinweis: Um eine Aufschlüsselung nach Statuscode durchzuführen, klicken Sie auf die Gesamtzahl der Antworten und wählen Sie Statuscode aus der Speisekarte. Alle mit diesem HTTP-Client verknüpften Statuscodes werden angezeigt. Fehler der Stufe 500 weisen auf Serverfehler hin. Metrisch Beschreibung Antworten Die Anzahl der Antworten, die von diesem HTTP empfangen wurden Client. Fehler Die Häufigkeit, mit der dieser HTTP-Client erhielt einen Antwortstatuscode mit 500 Stufen, der angibt, dass der antwortende Server möglicherweise ist ein interner Serverfehler aufgetreten. Wenn der Client einen Statuscode der Stufe 400 erhält (was darauf hinweist, dass die Client-Anfrage in irgendeiner Weise ungültig war), klassifiziert das ExtraHop-System die Antwort nicht als HTTP-Fehler. Wenn Sie jedoch sehen möchten, wie oft der Client Statuscodes der Stufe 400 erhalten hat, können Sie die Die wichtigsten Statuscodes Diagramm.
- Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der HTTP-Antworten, die der Client erhalten hat, und wie
viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die von diesem HTTP empfangen wurden Client. Fehler Die Häufigkeit, mit der dieser HTTP-Client erhielt einen Antwortstatuscode mit 500 Stufen, der angibt, dass der antwortende Server möglicherweise ist ein interner Serverfehler aufgetreten. - Leistung (95. Perzentil)
-
Dieses Diagramm zeigt das
95. Perzentil der Timing-Metriken. Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer
vollständigen Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange der Client gebraucht hat, um
Anfragen an das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange Server gebraucht haben, um
die Anfragen zu verarbeiten; und die Antwortübertragungszeit zeigt, wie lange Server gebraucht haben, um
Antworten an das Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Transferzeit anfragen Wenn das Gerät als HTTP-Client fungiert, die Zeit zwischen der Erkennung des ersten Pakets und des letzten Pakets durch das ExtraHop-System von gesendete Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit des Servers Die Zeit, die dieser HTTP-Client Client hat empfängt das erste Paket einer Antwort, nachdem es das letzte Paket einer Anfrage gesendet hat. Übertragungszeit der Antwort Wenn das Gerät als HTTP-Client fungiert, die Zeit zwischen der Erkennung des ersten Pakets und des letzten Pakets durch das ExtraHop-System von erhaltene Antworten. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines HTTP-Clients an Paket, das eine sofortige Bestätigung erforderte und wann der Client das erhielt Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn ein Client langsam reagiert, können Sie
anhand von Leistungsübersichtsmetriken herausfinden, ob das Netzwerk oder die Server das Problem verursachen.
Diese Metriken zeigen das 95. Perzentil der Zeit, die Server für die Bearbeitung von
Anfragen vom Client benötigten, im Vergleich zur 95. Perzentilzeit, die Pakete aus diesen
Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten.
Hohe Serververarbeitungszeiten deuten darauf hin, dass der Client langsame Server kontaktiert. Hohe
TCP-Roundtrip-Zeiten deuten darauf hin, dass der Client über langsame
Netzwerke kommuniziert.
Metrisch Beschreibung Verarbeitungszeit des Servers Die Zeit, die dieser HTTP-Client Client hat empfängt das erste Paket einer Antwort, nachdem es das letzte Paket einer Anfrage gesendet hat. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines HTTP-Clients an Paket, das eine sofortige Bestätigung erforderte und wann der Client das erhielt Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
HTTP-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
Der Abschnitt mit den HTTP-Details unterteilt die Transaktionsinformationen nach einigen der beliebtesten Kriterien. Sie können beispielsweise sehen, welche HTTP-Methoden der Client am häufigsten aufgerufen hat.
- Die besten Methoden
- Dieses Diagramm zeigt, welche HTTP-Methoden der Client am häufigsten aufgerufen hat, indem die Gesamtzahl der Anfragen, die der Client nach Methode gesendet hat, aufgeschlüsselt wird.
- Die wichtigsten Statuscodes
- Dieses Diagramm zeigt, welche HTTP-Statuscodes der Client am häufigsten erhalten hat, indem
die Anzahl der an den Client zurückgegebenen Antworten nach Statuscode aufgeteilt wird.
Hinweis: Sie können dieses Diagramm anhand des Statuscodes aufschlüsseln. Um beispielsweise nur Statuscodes mit 400 Stufen zu sehen, klicken Sie auf Die wichtigsten Statuscodes, wählen Diagramm erstellen aus, und geben Sie im Feld Drilldown nach Statuscode den folgenden regulären Ausdruck ein: (4[0-8][0-9]|49[0-9]) - Die wichtigsten Inhaltstypen
- Dieses Diagramm zeigt, auf welche Inhaltstypen der Kunde am häufigsten zugegriffen hat, indem die Gesamtzahl der an den Client zurückgegebenen Antworten nach Inhaltstyp aufgeschlüsselt wird.
HTTP-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des Servers Die Zeit, die dieser HTTP-Client Client hat empfängt das erste Paket einer Antwort, nachdem es das letzte Paket einer Anfrage gesendet hat. - Verarbeitungszeit des Servers
- Dieses Diagramm zeigt die durchschnittliche Serververarbeitungszeit für den Client.
Metrisch Beschreibung Verarbeitungszeit des Servers Die Zeit, die dieser HTTP-Client Client hat empfängt das erste Paket einer Antwort, nachdem es das letzte Paket einer Anfrage gesendet hat. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines HTTP-Clients an Paket, das eine sofortige Bestätigung erforderte und wann der Client das erhielt Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Hin- und Rückflugzeit für den Client.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines HTTP-Clients an Paket, das eine sofortige Bestätigung erforderte und wann der Client das erhielt Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Gesamtwerte der HTTP-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, sendet der Client möglicherweise mehr Anfragen, als Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen, ob das Problem am Netzwerk oder am Server liegt, überprüfen Sie RTOs und Zero Windows in der Netzwerk-Daten Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der HTTP-Anfragen und -Antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Definition Anfragen Die Anzahl der Anfragen, die von diesem HTTP-Client gesendet wurden. Eine HTTP-Anfrage kann eine Methode, einen eindeutigen Ressourcenbezeichner (URI) enthalten und Header, die Benutzerinformationen enthalten. Ein HTTP/2-PUSH_PROMISE-Frame, empfangen von Kunden zählen als eine Anfrage. Antworten Die Anzahl der Antworten, die von diesem HTTP empfangen wurden Client. Fehler Die Häufigkeit, mit der dieser HTTP-Client erhielt einen Antwortstatuscode mit 500 Stufen, der angibt, dass der antwortende Server möglicherweise ist ein interner Serverfehler aufgetreten. Abgebrochene Anfragen Die Anzahl der Anfragen dieses HTTP-Clients begann zu senden, bevor die Verbindung abrupt geschlossen wurde. Dieser Client konnte nicht senden die komplette Anfrage, weil die Verbindung abgelaufen ist oder die Verbindung geschlossen wurde mit einem TCP-Reset (RST) oder FIN Abgebrochene Antworten Die Anzahl der Antworten dieses HTTP-Clients begann zu empfangen, bevor die Verbindung abrupt geschlossen wurde. Dieser Client konnte nicht erhalte die vollständige Antwort, weil das Verbindungs-Timeout aufgetreten ist oder die Verbindung geschlossen mit einem TCP-Reset (RST) oder FIN Authentifizierte Antworten Die Anzahl der erhaltenen authentifizierten Antworten wenn das Gerät als HTTP-Client fungiert. Anfragen in der Pipeline Die Anzahl der Pipeline-Anfragen, die der Gerät, das gesendet wird, wenn es als HTTP-Client fungiert. Pipeline-Anfragen bestehen aus mehreren Anfragen, die auf dieselbe Verbindung geschrieben wurden, ohne auf die entsprechende Verbindung zu warten Antworten. Gebündelte Übertragung Die Anzahl der eingegangenen Antworten, die verwendet wurden Chunked-Übertragungscodierung, wenn das Gerät als HTTP-Client fungiert Komprimierte Antworten Die Anzahl der eingegangenen Antworten, die verwendet wurden Inhaltscodierung „gzip" oder „deflate", wenn das Gerät als HTTP fungiert Client. Größe der Anfrage: Median Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät gesendet hat, als es als HTTP-Client fungiert. Maße der Größe schließt HTTP-Nutzdaten ein, aber keine Header Median der Antwortgröße Die Verteilung der Größen (in Byte) von Antworten, die empfangen werden, wenn das Gerät als HTTP-Client fungiert. Maße der Größe schließt HTTP-Nutzdaten ein, aber keine Header - Durchschnittliche Anfragen- und Antwortgrößen
- Zeigt die durchschnittliche Größe der Anfragen und Antworten an.
Metrisch Beschreibung Größe der Anfrage Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät gesendet hat, als es als HTTP-Client fungiert. Maße der Größe schließt HTTP-Nutzdaten ein, aber keine Header Größe der Antwort Die Verteilung der Größen (in Byte) von Antworten, die empfangen werden, wenn das Gerät als HTTP-Client fungiert. Maße der Größe schließt HTTP-Nutzdaten ein, aber keine Header
HTTP-Serverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt HTTP Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur HTTP-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
HTTP Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann HTTP-Fehler aufgetreten sind und wie viele HTTP-Antworten der Server
gesendet hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Server zu dem Zeitpunkt war, als er die Fehler
zurückgab.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie einen Drilldown durchführen, um den spezifischen Statuscode zu finden, der in der Anfrage zurückgegeben wurde, und zu erfahren, warum der Server die Anfrage nicht erfüllen konnte. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von HTTP-Anfragen zu HTTP-Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Hinweis: Um eine Aufschlüsselung nach Statuscode durchzuführen, klicken Sie auf die Gesamtzahl der Antworten und wählen Sie Statuscode aus der Speisekarte. Alle mit diesem HTTP-Server verknüpften Statuscodes werden angezeigt. Fehler der Stufe 500 weisen auf Serverfehler hin. Metrisch Beschreibung Antworten Die Anzahl der Antworten, die von diesem HTTP-Server gesendet wurden. Eine HTTP-Antwort kann einen Statuscode und den Inhaltstyp enthalten. Ein HTTP/2-Server Push zählt als eine Antwort. Fehler Wie oft dieser HTTP-Server gab einen Antwortstatuscode mit 500 Stufen zurück, der auf einen potenziellen internen Server hinweist Fehler. Wenn der Client einen 400-Level-Statuscode erhält (was darauf hinweist, dass die Anfrage des Kunden in irgendeiner Weise ungültig war), klassifiziert das ExtraHop-System die Antwort nicht als HTTP-Fehler. Wenn Sie jedoch sehen möchten, wie oft der Client Statuscodes der Stufe 400 erhalten hat, können Sie die Die wichtigsten Statuscodes Diagramm.
- Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der HTTP-Antworten, die der Server gesendet hat, und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die von diesem HTTP-Server gesendet wurden. Eine HTTP-Antwort kann einen Statuscode und den Inhaltstyp enthalten. Ein HTTP/2-Server Push zählt als eine Antwort. Fehler Wie oft dieser HTTP-Server gab einen Antwortstatuscode mit 500 Stufen zurück, der auf einen potenziellen internen Server hinweist Fehler. - Leistung (95. Perzentil)
-
Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken
. Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer vollständigen
Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange Clients gebraucht haben, um Anfragen an
das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange der Server gebraucht hat, um Anfragen zu verarbeiten;
und die Antwortübertragungszeit zeigt, wie lange der Server gebraucht hat, um Antworten an das
Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Transferzeit anfragen Wenn das Gerät als HTTP-Server fungiert, die Zeit zwischen der Erkennung des ersten Pakets und des letzten Pakets durch das ExtraHop-System von eingegangene Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit des Servers Die Zeit, die dieser HTTP-Server Server hat sende das erste Paket der Antwort, nachdem du das letzte Paket der Anfrage. Übertragungszeit der Antwort Wenn das Gerät als HTTP-Server fungiert, die Zeit zwischen der Erkennung des ersten Pakets und des letzten Pakets durch das ExtraHop-System von gesendete Antworten. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines HTTP-Servers an Paket, das eine sofortige Bestätigung erforderte und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn ein Server langsam reagiert, können Sie
anhand von Leistungsübersichtsmetriken herausfinden, ob das
Problem vom Netzwerk oder vom Server verursacht wird. Die Leistungsübersichtsmetriken zeigen das 95. Perzentil der Zeit, die der
Server für die Verarbeitung von Anfragen von Clients benötigte, im Vergleich zur 95. Perzentilzeit, die
Pakete aus diesen Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten.
Hohe Serververarbeitungszeiten deuten darauf hin, dass der Server langsam ist.
Hohe RTTs weisen darauf hin, dass der Server über langsame Netzwerke kommuniziert.
Metrisch Beschreibung Verarbeitungszeit des Servers Die Zeit, die dieser HTTP-Server Server hat sende das erste Paket der Antwort, nachdem du das letzte Paket der Anfrage. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines HTTP-Servers an Paket, das eine sofortige Bestätigung erforderte und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
HTTP Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
Das HTTP Einzelheiten In diesem Abschnitt werden die Transaktionsinformationen nach einigen der beliebtesten Kriterien unterteilt. Sie können beispielsweise sehen, welche HTTP-Methoden am häufigsten aufgerufen wurden.
- Die besten Methoden
- Dieses Diagramm zeigt, welche HTTP-Methoden auf dem Server am häufigsten aufgerufen wurden, indem die Gesamtzahl der Anfragen, die der Server erhalten hat, nach Methode aufgeteilt wird.
- Die wichtigsten Statuscodes
- Dieses Diagramm zeigt, welche HTTP-Statuscodes der Server am häufigsten zurückgegeben hat, indem
die Gesamtzahl der vom Server gesendeten Antworten nach Statuscode aufgeschlüsselt wird.
Hinweis: Sie können dieses Diagramm anhand des Statuscodes aufschlüsseln. Um beispielsweise nur Statuscodes mit 400 Stufen zu sehen, klicken Sie auf Die wichtigsten Statuscodes, wählen Diagramm erstellen aus, und geben Sie im Feld Drilldown nach Statuscode den folgenden regulären Ausdruck ein: (4[0-8][0-9]|49[0-9]) - Die wichtigsten Inhaltstypen
- Dieses Diagramm zeigt, auf welche Inhaltstypen Clients am häufigsten auf dem Server zugegriffen haben, indem die Gesamtzahl der vom Server gesendeten Antworten nach Inhaltstyp aufgeschlüsselt wird.
HTTP Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des Servers Die Zeit, die dieser HTTP-Server Server hat sende das erste Paket der Antwort, nachdem du das letzte Paket der Anfrage. - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Verarbeitungszeit für den Server.
Metrisch Beschreibung Verarbeitungszeit des Servers Die Zeit, die dieser HTTP-Server Server hat sende das erste Paket der Antwort, nachdem du das letzte Paket der Anfrage. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines HTTP-Servers an Paket, das eine sofortige Bestätigung erforderte und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Hin- und Rückflugzeit für den Client.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines HTTP-Servers an Paket, das eine sofortige Bestätigung erforderte und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
HTTP Metrische Summen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr
Anfragen, als der Server verarbeiten kann, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen
, ob das Problem beim Netzwerk oder beim Server liegt, überprüfen Sie RTOs und Zero Windows in der
Netzwerk-Daten
Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der HTTP-Anfragen und -Antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Definition Anfragen Die Anzahl der Anfragen, die von diesem HTTP empfangen wurden Server. Eine HTTP-Anfrage kann eine Methode, einen eindeutigen Ressourcenbezeichner (URI), enthalten und Header, die Benutzerinformationen enthalten. Ein HTTP/2-PUSH_PROMISE-Frame, gesendet von Server zählen als eine Anfrage. Antworten Die Anzahl der Antworten, die von diesem HTTP-Server gesendet wurden. Eine HTTP-Antwort kann einen Statuscode und den Inhaltstyp enthalten. Ein HTTP/2-Server Push zählt als eine Antwort. Fehler Wie oft dieser HTTP-Server gab einen Antwortstatuscode mit 500 Stufen zurück, der auf einen potenziellen internen Server hinweist Fehler. Abgebrochene Anfragen Die Anzahl der Anfragen dieses HTTP-Servers begann zu empfangen, bevor die Verbindung abrupt geschlossen wurde. Dieser Server konnte nicht erhalte die komplette Anfrage, weil das Verbindungs-Timeout abgelaufen ist oder die Verbindung geschlossen mit einem TCP-Reset (RST) oder FIN Abgebrochene Antworten Die Anzahl der Antworten auf diesem HTTP-Server begann zu senden, bevor die Verbindung abrupt geschlossen wurde. Dieser Server konnte nicht senden die vollständige Antwort, weil das Zeitlimit für die Verbindung abgelaufen ist oder die Verbindung geschlossen wurde mit einem TCP-Reset (RST) oder FIN Authentifizierte Antworten Die Anzahl der gesendeten Authentifizierungsantworten wenn das Gerät als HTTP-Server fungiert. Anfragen in der Pipeline Die Anzahl der Pipeline-Anfragen, die der Gerät, das empfangen wurde, wenn es als HTTP-Server fungiert. Pipeline-Anfragen bestehen aus mehrere Anfragen, die an dieselbe Verbindung geschrieben wurden, ohne auf die entsprechende Antworten. Gebündelte Übertragung Die Anzahl der gesendeten Antworten, die verwendet wurden Chunked Transfer-Codierung, wenn das Gerät als HTTP-Server fungiert Komprimierte Antworten Die Anzahl der gesendeten Antworten, die verwendet wurden Inhaltscodierung „gzip" oder „deflate", wenn das Gerät als HTTP fungiert Server. Größe der Anfrage: Median Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät empfangen hat, als es als HTTP-Server fungiert. Maße der Größe schließt HTTP-Nutzdaten ein, aber keine Header Median der Antwortgröße Die Verteilung der Größen (in Byte) von Antworten, die das Gerät gesendet hat, als es als HTTP-Server fungiert. Maße der Größe schließt HTTP-Nutzdaten ein, aber keine Header - Durchschnittliche Anfragen- und Antwortgrößen
- Zeigt die durchschnittliche Größe der Anfragen und Antworten an.
Metrisch Beschreibung Größe der Anfrage Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät empfangen hat, als es als HTTP-Server fungiert. Maße der Größe schließt HTTP-Nutzdaten ein, aber keine Header Größe der Antwort Die Verteilung der Größen (in Byte) von Antworten, die das Gerät gesendet hat, als es als HTTP-Server fungiert. Maße der Größe schließt HTTP-Nutzdaten ein, aber keine Header
HTTP-Client-Gruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt HTTP Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur HTTP-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
HTTP Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann HTTP-Fehler aufgetreten sind und wie viele Antworten die HTTP-Clients
erhalten haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Kunden zu dem Zeitpunkt waren, als sie die Fehler
erhielten.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie die spezifischen Statuscodes, die in den Anfragen zurückgegeben wurden, aufschlüsseln und herausfinden, warum Server die Anfragen nicht bearbeiten konnten . Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von HTTP-Anfragen zu HTTP-Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie weiter unten im Abschnitt Metriken für Gruppen.
Hinweis: Um eine Aufschlüsselung nach Statuscode durchzuführen, klicken Sie auf die Gesamtzahl der Antworten und wählen Sie Statuscode aus der Speisekarte. Alle mit diesen HTTP-Clients verknüpften Statuscodes werden angezeigt. Fehler der Stufe 500 weisen auf Serverfehler hin. Metrisch Beschreibung Antworten Die Anzahl der Antworten, die von diesem HTTP empfangen wurden Client. Fehler Die Häufigkeit, mit der dieser HTTP-Client erhielt einen Antwortstatuscode mit 500 Stufen, der angibt, dass der antwortende Server möglicherweise ist ein interner Serverfehler aufgetreten. Wenn der Client einen Statuscode der Stufe 400 erhält (was darauf hinweist, dass die Anfrage des Kunden in irgendeiner Weise ungültig war), klassifiziert das ExtraHop-System die Antwort nicht als HTTP-Fehler. Wenn Sie jedoch sehen möchten, wie oft der Client Statuscodes der Stufe 400 erhalten hat, können Sie sich das Diagramm mit den wichtigsten Statuscodes genauer ansehen.
- Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele HTTP-Antworten die Clients erhalten haben und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die von diesem HTTP empfangen wurden Client. Fehler Die Häufigkeit, mit der dieser HTTP-Client erhielt einen Antwortstatuscode mit 500 Stufen, der angibt, dass der antwortende Server möglicherweise ist ein interner Serverfehler aufgetreten. Wenn der Client einen Statuscode der Stufe 400 erhält (was darauf hinweist, dass die Anfrage des Kunden in irgendeiner Weise ungültig war), klassifiziert das ExtraHop-System die Antwort nicht als HTTP-Fehler. Wenn Sie jedoch sehen möchten, wie oft der Client Statuscodes der Stufe 400 erhalten hat, können Sie sich das Diagramm mit den wichtigsten Statuscodes genauer ansehen.
HTTP-Transaktionsdetails für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (HTTP-Clients)
- Dieses Diagramm zeigt, welche HTTP-Clients in der Gruppe am aktivsten waren, indem es die Gesamtzahl der HTTP-Anfragen aufschlüsselt, die die Gruppe vom Client gesendet hat.
- Die besten Methoden
- Dieses Diagramm zeigt, welche HTTP-Methoden die Gruppe am häufigsten aufgerufen hat, indem die Gesamtzahl der Anfragen, die die Gruppe nach Methode gesendet hat, aufgeschlüsselt wird.
- Wichtigster Statuscode
- Dieses Diagramm zeigt, welche HTTP-Statuscodes die Gruppe am häufigsten erhalten hat, indem die Anzahl der an die Gruppe zurückgegebenen Antworten nach Statuscode aufgeschlüsselt wird.
HTTP-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden die Clients möglicherweise mehr Anfragen, als Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Definition Anfragen Die Anzahl der Anfragen, die von diesem HTTP-Client gesendet wurden. Eine HTTP-Anfrage kann eine Methode, einen eindeutigen Ressourcenbezeichner (URI) enthalten und Header, die Benutzerinformationen enthalten. Ein HTTP/2-PUSH_PROMISE-Frame, empfangen von Kunden zählen als eine Anfrage. Antworten Die Anzahl der Antworten, die von diesem HTTP empfangen wurden Client. Fehler Die Häufigkeit, mit der dieser HTTP-Client erhielt einen Antwortstatuscode mit 500 Stufen, der angibt, dass der antwortende Server möglicherweise ist ein interner Serverfehler aufgetreten. Abgebrochene Anfragen Die Anzahl der Anfragen dieses HTTP-Clients begann zu senden, bevor die Verbindung abrupt geschlossen wurde. Dieser Client konnte nicht senden die komplette Anfrage, weil die Verbindung abgelaufen ist oder die Verbindung geschlossen wurde mit einem TCP-Reset (RST) oder FIN Abgebrochene Antworten Die Anzahl der Antworten dieses HTTP-Clients begann zu empfangen, bevor die Verbindung abrupt geschlossen wurde. Dieser Client konnte nicht erhalte die vollständige Antwort, weil das Verbindungs-Timeout aufgetreten ist oder die Verbindung geschlossen mit einem TCP-Reset (RST) oder FIN Authentifizierte Antworten Die Anzahl der erhaltenen authentifizierten Antworten wenn das Gerät als HTTP-Client fungiert. Anfragen in der Pipeline Die Anzahl der Pipeline-Anfragen, die der Gerät, das gesendet wird, wenn es als HTTP-Client fungiert. Pipeline-Anfragen bestehen aus mehreren Anfragen, die auf dieselbe Verbindung geschrieben wurden, ohne auf die entsprechende Verbindung zu warten Antworten. Gebündelte Übertragung Die Anzahl der eingegangenen Antworten, die verwendet wurden Chunked-Übertragungscodierung, wenn das Gerät als HTTP-Client fungiert Komprimierte Antworten Die Anzahl der eingegangenen Antworten, die verwendet wurden Inhaltscodierung „gzip" oder „deflate", wenn das Gerät als HTTP fungiert Client. - Verarbeitungszeit des Servers
-
Wenn sich eine Client-Gruppe langsam verhält, können Sie anhand der Serververarbeitungszeit herausfinden,
ob das Problem bei den Servern liegt. Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche
Zeit, die Server für die Bearbeitung von Anfragen von den Clients benötigten. Hohe
Serververarbeitungszeiten deuten darauf hin, dass die Clients langsame Server kontaktieren.
Metrisch Beschreibung Verarbeitungszeit des Servers Die Zeit, die dieser HTTP-Client Client hat empfängt das erste Paket einer Antwort, nachdem es das letzte Paket einer Anfrage gesendet hat.
HTTP-Servergruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt HTTP Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur HTTP-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
HTTP Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wann HTTP-Fehler aufgetreten sind und wie viele HTTP-Antworten die Server
gesendet haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Server zu dem Zeitpunkt waren, als sie
die Fehler gemeldet haben.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie einen Drilldown durchführen, um den spezifischen Statuscode zu finden, der in der Anfrage zurückgegeben wurde, und zu erfahren, warum die Server die Anfragen nicht bearbeiten konnten. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von HTTP-Anfragen zu HTTP-Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie weiter unten im Abschnitt Metriken für Gruppen.
Hinweis: Um eine Aufschlüsselung nach Statuscode durchzuführen, klicken Sie auf die Gesamtzahl der Antworten und wählen Sie Statuscode aus der Speisekarte. Alle mit diesem HTTP-Server verknüpften Statuscodes werden angezeigt. Fehler der Stufe 500 weisen auf Serverfehler hin. Metrisch Beschreibung Antworten Die Anzahl der Antworten, die von diesem HTTP-Server gesendet wurden. Eine HTTP-Antwort kann einen Statuscode und den Inhaltstyp enthalten. Ein HTTP/2-Server Push zählt als eine Antwort. Fehler Wie oft dieser HTTP-Server gab einen Antwortstatuscode mit 500 Stufen zurück, der auf einen potenziellen internen Server hinweist Fehler. Wenn der Client einen Statuscode der Stufe 400 erhält (was darauf hinweist, dass die Anfrage des Kunden in irgendeiner Weise ungültig war), klassifiziert das ExtraHop-System die Antwort nicht als HTTP-Fehler. Wenn Sie jedoch sehen möchten, wie oft der Client Statuscodes der Stufe 400 erhalten hat, können Sie die Die wichtigsten Statuscodes Diagramm.
- Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele HTTP-Antworten Server in der Gruppe gesendet haben und wie viele dieser
Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die von diesem HTTP-Server gesendet wurden. Eine HTTP-Antwort kann einen Statuscode und den Inhaltstyp enthalten. Ein HTTP/2-Server Push zählt als eine Antwort. Fehler Wie oft dieser HTTP-Server gab einen Antwortstatuscode mit 500 Stufen zurück, der auf einen potenziellen internen Server hinweist Fehler. Wenn der Client einen Statuscode der Stufe 400 erhält (was darauf hinweist, dass die Anfrage des Kunden in irgendeiner Weise ungültig war), klassifiziert das ExtraHop-System die Antwort nicht als HTTP-Fehler. Wenn Sie jedoch sehen möchten, wie oft der Client Statuscodes der Stufe 400 erhalten hat, können Sie die Die wichtigsten Statuscodes Diagramm.
HTTP-Transaktionsdetails für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (HTTP-Server)
- Dieses Diagramm zeigt, welche HTTP-Server in der Gruppe am aktivsten waren, indem die Gesamtzahl der HTTP-Antworten, die die Gruppe vom Server gesendet hat, aufgeschlüsselt wird.
- Die besten Methoden
- Dieses Diagramm zeigt, welche HTTP-Methoden auf Servern in der Gruppe am häufigsten aufgerufen wurden, indem die Gesamtzahl der Anfragen, die die Gruppe erhalten hat, nach Methode aufgeteilt wird.
- Oberster Statuscode
- Dieses Diagramm zeigt, welche HTTP-Statuscodes die Gruppen am häufigsten zurückgegeben haben, indem die Gesamtzahl der von der Gruppe gesendeten Antworten nach Statuscode aufgeschlüsselt wird.
HTTP-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden Clients möglicherweise mehr Anfragen, als die Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Definition Anfragen Die Anzahl der Anfragen, die von diesem HTTP empfangen wurden Server. Eine HTTP-Anfrage kann eine Methode, einen eindeutigen Ressourcenbezeichner (URI), enthalten und Header, die Benutzerinformationen enthalten. Ein HTTP/2-PUSH_PROMISE-Frame, gesendet von Server zählen als eine Anfrage. Antworten Die Anzahl der Antworten, die von diesem HTTP-Server gesendet wurden. Eine HTTP-Antwort kann einen Statuscode und den Inhaltstyp enthalten. Ein HTTP/2-Server Push zählt als eine Antwort. Fehler Wie oft dieser HTTP-Server gab einen Antwortstatuscode mit 500 Stufen zurück, der auf einen potenziellen internen Server hinweist Fehler. Abgebrochene Anfragen Die Anzahl der Anfragen dieses HTTP-Servers begann zu empfangen, bevor die Verbindung abrupt geschlossen wurde. Dieser Server konnte nicht erhalte die komplette Anfrage, weil das Verbindungs-Timeout abgelaufen ist oder die Verbindung geschlossen mit einem TCP-Reset (RST) oder FIN Abgebrochene Antworten Die Anzahl der Antworten auf diesem HTTP-Server begann zu senden, bevor die Verbindung abrupt geschlossen wurde. Dieser Server konnte nicht senden die vollständige Antwort, weil das Zeitlimit für die Verbindung abgelaufen ist oder die Verbindung geschlossen wurde mit einem TCP-Reset (RST) oder FIN Authentifizierte Antworten Die Anzahl der gesendeten Authentifizierungsantworten wenn das Gerät als HTTP-Server fungiert. Anfragen in der Pipeline Die Anzahl der Pipeline-Anfragen, die der Gerät, das empfangen wurde, wenn es als HTTP-Server fungiert. Pipeline-Anfragen bestehen aus mehrere Anfragen, die an dieselbe Verbindung geschrieben wurden, ohne auf die entsprechende Antworten. Gebündelte Übertragung Die Anzahl der gesendeten Antworten, die verwendet wurden Chunked Transfer-Codierung, wenn das Gerät als HTTP-Server fungiert Komprimierte Antworten Die Anzahl der gesendeten Antworten, die verwendet wurden Inhaltscodierung „gzip" oder „deflate", wenn das Gerät als HTTP fungiert Server. - Verarbeitungszeit des Servers
-
Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche Zeit, die die Server für die
Bearbeitung von Anfragen von Clients benötigten. Hohe Serververarbeitungszeiten deuten darauf hin, dass die Server in einer
Gruppe langsam sind.
Metrisch Beschreibung Verarbeitungszeit des Servers Die Zeit, die dieser HTTP-Server Server hat sende das erste Paket der Antwort, nachdem du das letzte Paket der Anfrage.
IBMMQ
Das ExtraHop-System sammelt Metriken zur IBM Message Queue (IBMMQ) Aktivität. IBM MQ ist ein Message-Queuing-Protokoll für IBM Enterprise- und Message-Middleware-Produkte.
IBM MQ-Anwendungsseite
Auf dieser Seite werden Metrikdiagramme von angezeigt IBMMQ Verkehr, der mit einem Anwendungscontainer in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
IBMMQ Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann IBM MQ-Fehler und -Antworten mit der
Anwendung verknüpft waren. Anhand dieser Informationen können Sie feststellen, wie aktiv die Anwendung zum
Zeitpunkt des Auftretens der Fehler war.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der IBMMQ-Antworten. Fehler Die Anzahl der IBMMQ-Antworten Fehler. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der IBM MQ-Antworten, die mit der
Anwendung verknüpft waren, und wie viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der IBMMQ-Antworten. Fehler Die Anzahl der IBMMQ-Antworten Fehler. - Arten von Anfragen
- Dieses Diagramm zeigt, wann die Anwendung IBM MQ GET- und PUT-Anfragen gesendet hat.
Metrisch Beschreibung BEKOMMEN Die Anzahl der gesendeten IBMMQ GET-Anfragen. GET wird verwendet um einen Artikel aus der Warteschlange zu entfernen. SETZEN Die Anzahl der IBMMQ PUT-Anfragen, die das Gerät gesendet. PUT wird verwendet, um ein Element aus der Warteschlange zu entfernen. - Zusammenfassung der Art der Anfrage
- Dieses Diagramm zeigt, welche Arten von IBM MQ-Anfragen die Anwendung gesendet hat.
Metrisch Beschreibung BEKOMMEN Die Anzahl der gesendeten IBMMQ GET-Anfragen. GET wird verwendet um einen Artikel aus der Warteschlange zu entfernen. SETZEN Die Anzahl der IBMMQ PUT-Anfragen, die das Gerät gesendet. PUT wird verwendet, um ein Element aus der Warteschlange zu entfernen.
IBM MQ Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche IBMMQ-Methoden mit der Anwendung verknüpft waren, indem die Gesamtzahl der IBMMQ-Anfragen nach Methoden aufgeschlüsselt wird.
- Top-Kanäle
- Dieses Diagramm zeigt die wichtigsten IBMMQ-Kanäle, indem die Gesamtzahl der IBMMQ-Antworten nach Kanälen aufgeschlüsselt ist.
- Die häufigsten Warteschlangen
- Dieses Diagramm zeigt die wichtigsten IBMMQ-Warteschlangen, aufgeschlüsselt nach der Gesamtzahl der IBMMQ-Anfragen nach Warteschlangen.
IBM MQ-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Zeitpunkt, an dem ein IBMMQ-Client oder Server hat ein Paket gesendet, das eine sofortige Bestätigung erfordert, und wann die Bestätigung erfolgte erhalten. - Zeit für Hin- und Rückfahrt
-
Diese Tabelle zeigt
die durchschnittliche Hin- und Rückflugzeit für die Anwendung.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Zeitpunkt, an dem ein IBMMQ-Client oder Server hat ein Paket gesendet, das eine sofortige Bestätigung erfordert, und wann die Bestätigung erfolgte erhalten.
IBMMQ Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass ein Problem mit einem Server oder einem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
-
Dieses Diagramm zeigt die Anzahl der Nullfenster, die einer Anwendung
zugeordnet waren. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der Pakete
angeben, die über einen bestimmten Zeitraum an sie gesendet werden können.
Wenn an ein Gerät mehr Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein
Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig einzustellen, bis das Gerät den Vorgang
aufholt. Wenn Sie eine große Anzahl von Nullfenstern sehen, ist ein Server oder Client möglicherweise
nicht schnell genug, um die empfangene Datenmenge zu unterstützen.
Metrisch Definition Zero Windows anfordern Die Anzahl der gesendeten Null-Window-Anzeigen von IBM MQ-Kunden. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl eingehender Zero-Windows weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Antwort Null Windows Die Anzahl der gesendeten Null-Window-Anzeigen von Servern beim Empfang von IBMMQ-Anfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von ausgehenden Zero-Windows weist darauf hin, dass ein Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Gesamtzahl der Host-Stände
- Dieses Diagramm zeigt die durchschnittliche Anzahl von Zero-Window-Werbeanzeigen, die von Geräten gesendet wurden.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen
Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu
viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät
eine Anfrage oder Antwort sendet und innerhalb einer bestimmten
Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen
nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise
zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der verursachten Timeouts bei der erneuten Übertragung durch Überlastung, als Clients IBMMQ-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Timeouts bei der erneuten Übertragung durch Überlastung, als Server IBMMQ-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
- Gesamtzahl der Netzwerkausfälle
-
Dieses Diagramm zeigt die durchschnittliche Anzahl von Timeouts bei der
erneuten Übertragung, die durch Überlastung beim Senden von Anfragen durch Clients und Server verursacht wurden.
Metrisch Definition RTOs Ein Die Anzahl der verursachten Timeouts bei der erneuten Übertragung durch Überlastung, als Clients IBMMQ-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Timeouts bei der erneuten Übertragung durch Überlastung, als Server IBMMQ-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
IBM MQ Metrische Gesamtwerte
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr Anfragen, als Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um herauszufinden, ob das Problem mit dem Netzwerk oder einem Server zusammenhängt, überprüfen Sie RTOs und Zero Windows in der Netzwerk-Daten Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der IBMMQ-Anfragen und -Antworten exakt gleich sein wird, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der IBMMQ-Anfragen. Antworten Die Anzahl der IBMMQ-Antworten. Fehler Die Anzahl der IBMMQ-Antworten Fehler. Warnungen Die Anzahl der IBMMQ-Warnantworten erhalten. GETs Die Anzahl der gesendeten IBMMQ GET-Anfragen. GET wird verwendet um einen Artikel aus der Warteschlange zu entfernen. PUTs Die Anzahl der IBMMQ PUT-Anfragen, die das Gerät gesendet. PUT wird verwendet, um ein Element aus der Warteschlange zu entfernen. Server-Meldungen Die Anzahl der IBMMQ-Servernachrichten übertragen. Kundennachrichten Die Anzahl der gesendeten IBMMQ-Clientnachrichten oder erhalten. Server-zu-Server-Nachrichten Die Anzahl der IBMMQ-Server-zu-Server übertragene Nachrichtentypen. Client-zu-Server-Nachrichten Die Anzahl der IBMMQ-Client-zu-Server übertragene Nachrichtentypen. - IBM MQ-Netzwerkmetriken
-
Metrisch Beschreibung Zero Windows anfordern Die Anzahl der gesendeten Null-Window-Anzeigen von IBM MQ-Kunden. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Antwort Null Windows Die Anzahl der gesendeten Null-Window-Anzeigen von Servern beim Empfang von IBMMQ-Anfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. RTOs Ein Die Anzahl der verursachten Timeouts bei der erneuten Übertragung durch Überlastung, als Clients IBMMQ-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. RTOs raus Die Anzahl der verursachten Timeouts bei der erneuten Übertragung durch Überlastung, als Server IBMMQ-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. L2-Byte anfordern Die Anzahl der L2-Bytes, die mit verknüpft sind IBMQ-Anfragen Antwort L2 Byte Die Anzahl der L2-Bytes, die mit verknüpft sind IBMQ-Antworten Goodput Bytes anfordern Die Anzahl der Goodput-Bytes, die mit verknüpft sind IBMQ-Anfragen. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Antwort Goodput Bytes Die Anzahl der Goodput-Bytes, die mit verknüpft sind IBMQ-Antworten. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Pakete anfordern Die Anzahl der Pakete, die mit IBMMQ verknüpft sind Anfragen. Antwortpakete Die Anzahl der Pakete, die mit IBMMQ verknüpft sind Antworten.
IBM MQ-Clientseite
Auf dieser Seite werden Metrikdiagramme von angezeigt IBMMQ Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
IBM MQ-Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann IBMMQ-Fehler aufgetreten sind und wie viele Antworten der
IBMMQ-Client erhalten hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Client zum Zeitpunkt des
Eingangs der Fehler war.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als IBM MQ-Client agieren Fehler Wenn das Gerät als IBM MQ fungiert Client, die Anzahl der gesendeten oder empfangenen Nachrichten mit dem Abschlusscode Error, aufgeschlüsselt nach einem bestimmten Ursachencode. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der IBM MQ-Antworten, die der Client erhalten hat, und wie
viele dieser Antworten Warnungen und Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als IBM MQ-Client agieren Fehler Wenn das Gerät als IBM MQ fungiert Client, die Anzahl der gesendeten oder empfangenen Nachrichten mit dem Abschlusscode Error, aufgeschlüsselt nach einem bestimmten Ursachencode. Warnungen Die Liste der gesendeten oder empfangenen Nachrichten mit dem Abschlusscode Warnung, wenn das Gerät als IBM MQ fungiert Client. - Arten von Anfragen
- Dieses Diagramm zeigt, wann der Client IBM MQ GET- und PUT-Anfragen gesendet hat.
Metrisch Beschreibung BEKOMMEN Die Anzahl der GET-Anfragen, die das Gerät gesendet hat wenn Sie als IBM MQ-Client agieren. GET wird verwendet, um ein Element aus dem zu entfernen Warteschlange. SETZEN Die Anzahl der PUT-Anfragen, die das Gerät gesendet hat wenn Sie als IBM MQ-Client agieren. PUT wird verwendet, um ein Objekt aus dem zu entfernen Warteschlange. - Anfragetypen insgesamt
- Dieses Diagramm zeigt, welche Arten von IBM MQ-Anfragen der Client gesendet hat.
Metrisch Beschreibung BEKOMMEN Die Anzahl der GET-Anfragen, die das Gerät gesendet hat wenn Sie als IBM MQ-Client agieren. GET wird verwendet, um ein Element aus dem zu entfernen Warteschlange. SETZEN Die Anzahl der PUT-Anfragen, die das Gerät gesendet hat wenn Sie als IBM MQ-Client agieren. PUT wird verwendet, um ein Objekt aus dem zu entfernen Warteschlange.
IBM MQ Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche IBM MQ-Methoden der Client am häufigsten aufgerufen hat, indem die Gesamtzahl der Anfragen, die der Client nach Methode gesendet hat, aufgeschlüsselt wird.
- Die wichtigsten Nachrichtenformate
- Dieses Diagramm zeigt, welche IBM MQ-Nachrichtenformate der Client am häufigsten erhalten hat, indem die Anzahl der an den Client zurückgegebenen Antworten nach Nachrichtenformat aufgeteilt wird.
- Die häufigsten Warteschlangen
- Dieses Diagramm zeigt, wo die meisten Client-Nachrichten gespeichert sind, indem die Anzahl der vom Client zurückgegebenen Antworten in die Warteschlange aufgeteilt wird.
IBM MQ-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Hin- und Rückflugzeit für den Client.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Versand eines Paket durch einen IBM MQ-Client, für das eine sofortige Bestätigung erforderlich war, und dem Empfang der Bestätigung durch den Client. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Versand eines Paket durch einen IBM MQ-Client, für das eine sofortige Bestätigung erforderlich war, und dem Empfang der Bestätigung durch den Client. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
IBM MQ Metrische Gesamtwerte
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, sendet der Client möglicherweise mehr
Anfragen, als die Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen
, ob das Problem beim Netzwerk oder beim Server liegt, überprüfen Sie RTOs und Zero Windows in der
Netzwerk-Daten
Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der IBMMQ-Anfragen und -Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät gesendet hat, als fungiert als IBM MQ-Client Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als IBM MQ-Client agieren Fehler Wenn das Gerät als IBM MQ fungiert Client, die Anzahl der gesendeten oder empfangenen Nachrichten mit dem Abschlusscode Error, aufgeschlüsselt nach einem bestimmten Ursachencode. Warnungen Die Liste der gesendeten oder empfangenen Nachrichten mit dem Abschlusscode Warnung, wenn das Gerät als IBM MQ fungiert Client. PCF-Anfragen Wenn das Gerät als IBM MQ fungiert client, die Anzahl der gesendeten PCF-Anfragen. Programmierbare Befehlsformate (PCFs) bieten eine Möglichkeit, Warteschlangen-Manager-Objekte wie Warteschlangen, Namenslisten und Kanäle. PCF-Antworten Wenn das Gerät als IBM MQ fungiert Client, die Anzahl der PCF-Antworten. Programmierbare Befehlsformate (PCFs) bieten eine Möglichkeit, Warteschlangen-Manager-Objekte wie Warteschlangen, Namenslisten und Kanäle. PCF-Warnungen Wenn das Gerät als IBM MQ fungiert Client, die Anzahl der eingegangenen Antworten, die auf eine PCF-Warnung hindeuten, aufgeschlüsselt nach spezifische Warnmeldung. Programmierbare Befehlsformate (PCFs) bieten eine Möglichkeit manipulieren Sie Warteschlangen-Manager-Objekte wie Warteschlangen, Namenslisten und Kanäle. PCF-Fehler Die Anzahl der Antworten, die auf eine hinweisen PCF-Fehler, den das Gerät empfangen hat, als es als IBM MQ-Client fungierte GETs Die Anzahl der GET-Anfragen, die das Gerät gesendet hat wenn Sie als IBM MQ-Client agieren. GET wird verwendet, um ein Element aus dem zu entfernen Warteschlange. PUTs Die Anzahl der PUT-Anfragen, die das Gerät gesendet hat wenn Sie als IBM MQ-Client agieren. PUT wird verwendet, um ein Objekt aus dem zu entfernen Warteschlange. Server-zu-Server-Nachrichten Die Anzahl von Server-zu-Servern Nachrichtentypen, die übertragen werden, wenn das Gerät als IBM MQ fungiert Client. Client-zu-Server-Nachrichten Die Anzahl der Client-zu-Server-Verbindungen Nachrichtentypen, die übertragen werden, wenn das Gerät als IBM MQ fungiert Client. - Größe der Anfrage und Antwort
- Dieses Diagramm zeigt, welche Arten von IBM MQ-Anfragen der Client gesendet hat.
Metrisch Beschreibung Größe der Anfrage Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät gesendet hat, als es als IBM MQ-Client agiert Größe der Antwort Die Verteilung der Größen (in Byte) von Antworten, die das Gerät erhalten hat, als es als IBM MQ-Client agiert
IBM MQ-Serverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt IBMMQ Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
IBMMQ Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann IBMMQ-Fehler aufgetreten sind und wie viele IBMMQ-Antworten der Server gesendet hat.
Anhand dieser Informationen können Sie feststellen, wie aktiv der Server zu dem Zeitpunkt war, als er die Fehler
zurückgab.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn Sie als IBM MQ-Server agieren Fehler Wenn das Gerät als IBM MQ fungiert Server, die Anzahl der gesendeten oder empfangenen Nachrichten mit dem Abschlusscode Error, aufgeschlüsselt nach einem bestimmten Ursachencode. - Transaktionen insgesamt
-
Dieses Diagramm zeigt die Gesamtzahl der IBM MQ-Antworten, die der Server gesendet hat, und wie viele dieser Antworten Warnungen und Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn Sie als IBM MQ-Server agieren Fehler Wenn das Gerät als IBM MQ fungiert Server, die Anzahl der gesendeten oder empfangenen Nachrichten mit dem Abschlusscode Error, aufgeschlüsselt nach einem bestimmten Ursachencode. Warnungen Die Liste der Nachrichten mit einer Vervollständigung Warncode, den das Gerät gesendet oder empfangen hat, wenn es als IBM MQ agiert Server. - Arten von Anfragen
- Dieses Diagramm zeigt, wann der Server IBM MQ GET- und PUT-Anfragen empfangen hat.
Metrisch Beschreibung BEKOMMEN Die Anzahl der GET-Anfragen, die das Gerät empfangen, wenn er als IBM MQ-Server fungiert. GET wird verwendet, um ein Element aus dem zu entfernen Warteschlange. SETZEN Die Anzahl der PUT-Anfragen, die das Gerät empfangen, wenn er als IBM MQ-Server fungiert. PUT wird verwendet, um ein Objekt aus dem zu entfernen Warteschlange. - Anfragetypen insgesamt
- Dieses Diagramm zeigt, welche Typen von IBM MQ-Anfragen der Server empfangen hat.
Metrisch Beschreibung BEKOMMEN Die Anzahl der GET-Anfragen, die das Gerät empfangen, wenn er als IBM MQ-Server fungiert. GET wird verwendet, um ein Element aus dem zu entfernen Warteschlange. SETZEN Die Anzahl der PUT-Anfragen, die das Gerät empfangen, wenn er als IBM MQ-Server fungiert. PUT wird verwendet, um ein Objekt aus dem zu entfernen Warteschlange.
IBM MQ Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche IBM MQ-Methoden auf dem Server am häufigsten aufgerufen wurden, indem die Gesamtzahl der Anfragen, die der Server erhalten hat, nach Methode aufgeteilt wird.
- Die wichtigsten Nachrichtenformate
- Dieses Diagramm zeigt, welche IBM MQ-Nachrichtenformate der Server am häufigsten gesendet hat, indem die Anzahl der vom Server zurückgegebenen Antworten nach Nachrichtenformat aufgeteilt wird.
- Die häufigsten Warteschlangen
- Dieses Diagramm zeigt, welche Warteschlangen auf dem Server am aktivsten sind, indem die Anzahl der vom Server zurückgegebenen Antworten pro Warteschlange aufgeschlüsselt wird.
IBM MQ-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Roundtrip-Zeit für den Server.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Versand eines Paket durch einen IBM MQ-Server, für das eine sofortige Bestätigung erforderlich war, und dem Empfang der Bestätigung durch den Server. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Versand eines Paket durch einen IBM MQ-Server, für das eine sofortige Bestätigung erforderlich war, und dem Empfang der Bestätigung durch den Server. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
IBM MQ Metrische Gesamtwerte
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Anfragen und Antworten
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, sendet der Client möglicherweise mehr
Anfragen, als die Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen
, ob das Problem beim Netzwerk oder beim Server liegt, überprüfen Sie RTOs und Zero Windows in der
Netzwerk-Daten
Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der IBMMQ-Anfragen und -Antworten exakt gleich sein wird, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät erhalten hat wenn Sie als IBM MQ-Server agieren Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn Sie als IBM MQ-Server agieren Fehler Wenn das Gerät als IBM MQ fungiert Server, die Anzahl der gesendeten oder empfangenen Nachrichten mit dem Abschlusscode Error, aufgeschlüsselt nach einem bestimmten Ursachencode. Warnungen Die Liste der Nachrichten mit einer Vervollständigung Warncode, den das Gerät gesendet oder empfangen hat, wenn es als IBM MQ agiert Server. PCF-Anfragen Wenn das Gerät als IBM MQ fungiert Server, die Anzahl der empfangenen PCF-Anfragen. Programmierbare Befehlsformate (PCFs) bieten eine Möglichkeit, Warteschlangen-Manager-Objekte wie Warteschlangen, Namenslisten und Kanäle. PCF-Antworten Wenn das Gerät als IBM MQ fungiert Server, die Anzahl der PCF-Antworten. Programmierbare Befehlsformate (PCFs) bieten eine Möglichkeit, Warteschlangen-Manager-Objekte wie Warteschlangen, Namenslisten und Kanäle. PCF-Warnungen Wenn das Gerät als IBM MQ fungiert Server, die Anzahl der gesendeten Antworten, die auf eine PCF-Warnung hinweisen, aufgeschlüsselt nach spezifische Warnmeldung. Programmierbare Befehlsformate (PCFs) bieten eine Möglichkeit manipulieren Sie Warteschlangen-Manager-Objekte wie Warteschlangen, Namenslisten und Kanäle. PCF-Fehler Die Anzahl der Antworten, die der Gerät gesendet, das einen PCF-Fehler anzeigt, wenn es als IBM MQ-Server fungiert GETs Die Anzahl der GET-Anfragen, die das Gerät empfangen, wenn er als IBM MQ-Server fungiert. GET wird verwendet, um ein Element aus dem zu entfernen Warteschlange. PUTs Die Anzahl der PUT-Anfragen, die das Gerät empfangen, wenn er als IBM MQ-Server fungiert. PUT wird verwendet, um ein Objekt aus dem zu entfernen Warteschlange. Kundennachrichten Die Anzahl der Server-zu-Server Nachrichtentypen, die übertragen werden, wenn das Gerät als IBM MQ fungiert Server. Client-zu-Server-Nachrichten Die Anzahl der Client-zu-Server-Verbindungen Nachrichtentypen, die übertragen werden, wenn das Gerät als IBM MQ fungiert Server. - Größe der Anfrage und Antwort
- Dieses Diagramm zeigt, welche Arten von IBM MQ-Anfragen der Client gesendet hat.
Metrisch Beschreibung Größe der Anfrage Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät empfangen hat, als es als IBM MQ-Server fungiert Größe der Antwort Die Verteilung der Größen (in Byte) von Antworten, die das Gerät gesendet hat, als es als IBM MQ-Server fungiert
IBM MQ-Clientgruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt IBMMQ Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
IBMMQ Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann IBMMQ-Fehler aufgetreten sind und wie viele Antworten die
IBMMQ-Clients erhalten haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Kunden zu dem
Zeitpunkt waren, als sie die Fehler erhielten.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als IBM MQ-Client agieren Fehler Wenn das Gerät als IBM MQ fungiert Client, die Anzahl der gesendeten oder empfangenen Nachrichten mit dem Abschlusscode Error, aufgeschlüsselt nach einem bestimmten Ursachencode. - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele IBM MQ-Antworten die Kunden erhalten haben und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als IBM MQ-Client agieren Fehler Wenn das Gerät als IBM MQ fungiert Client, die Anzahl der gesendeten oder empfangenen Nachrichten mit dem Abschlusscode Error, aufgeschlüsselt nach einem bestimmten Ursachencode.
IBM MQ-Details für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top IBMMQ-Mitglieder (IBMMQ-Kunden)
- Dieses Diagramm zeigt, welche IBMMQ-Clients in der Gruppe am aktivsten waren, indem die Gesamtzahl der IBMMQ-Anfragen, die die Gruppe vom Client gesendet hat, aufgeschlüsselt wird.
- Die besten Methoden
- Dieses Diagramm zeigt, welche IBMMQ-Methoden die Gruppe am häufigsten aufgerufen hat, indem die Gesamtzahl der von der Gruppe gesendeten Anfragen nach Methode aufgeschlüsselt wird.
- Die wichtigsten Nachrichtenformate
- Dieses Diagramm zeigt, welche IBMMQ-Nachrichtenformate die Gruppe am häufigsten erhalten hat, indem die Anzahl der an die Gruppe zurückgegebenen Antworten nach Nachrichtenformat aufgeschlüsselt wird.
IBM MQ-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden die Clients möglicherweise mehr Anfragen, als Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät gesendet hat, als fungiert als IBM MQ-Client Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als IBM MQ-Client agieren Fehler Wenn das Gerät als IBM MQ fungiert Client, die Anzahl der gesendeten oder empfangenen Nachrichten mit dem Abschlusscode Error, aufgeschlüsselt nach einem bestimmten Ursachencode. Warnungen Die Liste der gesendeten oder empfangenen Nachrichten mit dem Abschlusscode Warnung, wenn das Gerät als IBM MQ fungiert Client. PCF-Anfragen Wenn das Gerät als IBM MQ fungiert client, die Anzahl der gesendeten PCF-Anfragen. Programmierbare Befehlsformate (PCFs) bieten eine Möglichkeit, Warteschlangen-Manager-Objekte wie Warteschlangen, Namenslisten und Kanäle. PCF-Antworten Wenn das Gerät als IBM MQ fungiert Client, die Anzahl der PCF-Antworten. Programmierbare Befehlsformate (PCFs) bieten eine Möglichkeit, Warteschlangen-Manager-Objekte wie Warteschlangen, Namenslisten und Kanäle. PCF-Warnungen Wenn das Gerät als IBM MQ fungiert Client, die Anzahl der eingegangenen Antworten, die auf eine PCF-Warnung hindeuten, aufgeschlüsselt nach spezifische Warnmeldung. Programmierbare Befehlsformate (PCFs) bieten eine Möglichkeit manipulieren Sie Warteschlangen-Manager-Objekte wie Warteschlangen, Namenslisten und Kanäle. PCF-Fehler Die Anzahl der Antworten, die auf eine hinweisen PCF-Fehler, den das Gerät empfangen hat, als es als IBM MQ-Client fungierte Kundennachrichten Die Anzahl der Client-Nachrichten, die Gerät, das gesendet oder empfangen wurde, während es als IBM MQ-Server fungiert Client-zu-Server-Nachrichten Die Anzahl der Client-zu-Server-Verbindungen Nachrichtentypen, die übertragen werden, wenn das Gerät als IBM MQ fungiert Client.
IBM MQ-Servergruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt IBMMQ Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
IBMMQ Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann IBMMQ-Fehler aufgetreten sind und wie viele IBMMQ-Antworten die Server gesendet haben.
Anhand dieser Informationen können Sie feststellen, wie aktiv die Server zu dem Zeitpunkt waren, als
sie die Fehler gemeldet haben.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn Sie als IBM MQ-Server agieren Fehler Wenn das Gerät als IBM MQ fungiert Server, die Anzahl der gesendeten oder empfangenen Nachrichten mit dem Abschlusscode Error, aufgeschlüsselt nach einem bestimmten Ursachencode. - Transaktionen insgesamt
- Dieses Diagramm zeigt, wie viele IBM MQ-Antwortserver in der Gruppe gesendet haben und wie viele dieser
Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn Sie als IBM MQ-Server agieren Fehler Wenn das Gerät als IBM MQ fungiert Server, die Anzahl der gesendeten oder empfangenen Nachrichten mit dem Abschlusscode Error, aufgeschlüsselt nach einem bestimmten Ursachencode.
IBM MQ-Details für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top Gruppenmitglieder (IBM MQ Server)
- Dieses Diagramm zeigt, welche IBMMQ-Server in der Gruppe am aktivsten waren, indem die Gesamtzahl der IBMMQ-Antworten, die die Gruppe vom Server gesendet hat, aufgeschlüsselt wird.
- Die besten Methoden
- Dieses Diagramm zeigt, welche IBM MQ-Methoden auf Servern in der Gruppe am häufigsten aufgerufen wurden, indem die Gesamtzahl der Anfragen, die die Gruppe erhalten hat, nach Methode aufgeteilt wird.
- Die wichtigsten Nachrichtenformate
- Dieses Diagramm zeigt, welche IBMMQ-Nachrichtenformate die Gruppe am häufigsten gesendet hat, indem die Anzahl der von der Gruppe zurückgegebenen Antworten nach Nachrichtenformat aufgeschlüsselt wird.
IBM MQ-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden Clients möglicherweise mehr Anfragen, als die Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät erhalten hat wenn Sie als IBM MQ-Server agieren Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn Sie als IBM MQ-Server agieren Fehler Wenn das Gerät als IBM MQ fungiert Server, die Anzahl der gesendeten oder empfangenen Nachrichten mit dem Abschlusscode Error, aufgeschlüsselt nach einem bestimmten Ursachencode. Warnungen Die Liste der Nachrichten mit einer Vervollständigung Warncode, den das Gerät gesendet oder empfangen hat, wenn es als IBM MQ agiert Server. PCF-Anfragen Wenn das Gerät als IBM MQ fungiert Server, die Anzahl der empfangenen PCF-Anfragen. Programmierbare Befehlsformate (PCFs) bieten eine Möglichkeit, Warteschlangen-Manager-Objekte wie Warteschlangen, Namenslisten und Kanäle. PCF-Antworten Wenn das Gerät als IBM MQ fungiert Server, die Anzahl der PCF-Antworten. Programmierbare Befehlsformate (PCFs) bieten eine Möglichkeit, Warteschlangen-Manager-Objekte wie Warteschlangen, Namenslisten und Kanäle. PCF-Warnungen Wenn das Gerät als IBM MQ fungiert Server, die Anzahl der gesendeten Antworten, die auf eine PCF-Warnung hinweisen, aufgeschlüsselt nach spezifische Warnmeldung. Programmierbare Befehlsformate (PCFs) bieten eine Möglichkeit manipulieren Sie Warteschlangen-Manager-Objekte wie Warteschlangen, Namenslisten und Kanäle. PCF-Fehler Die Anzahl der Antworten, die der Gerät gesendet, das einen PCF-Fehler anzeigt, wenn es als IBM MQ-Server fungiert Kundennachrichten Die Anzahl der Server-zu-Server Nachrichtentypen, die übertragen werden, wenn das Gerät als IBM MQ fungiert Server. Client-zu-Server-Nachrichten Die Anzahl der Client-zu-Server-Verbindungen Nachrichtentypen, die übertragen werden, wenn das Gerät als IBM MQ fungiert Server.
ICA
Das ExtraHop-System sammelt Metriken zur Independent Computing Architecture (ICA) Aktivität. ICA ist ein Citrix-Systemprotokoll, das Daten zwischen Clients und Servern überträgt.
ICA-Anwendungsseite
Auf dieser Seite werden Metrikdiagramme von angezeigt ICA Verkehr, der mit einem Anwendungscontainer in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
ICA-Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Sessions
- Dieses Diagramm zeigt, wann die Anwendung Citrix
ICA-Sitzungen gestartet und abgebrochen hat.
Metrisch Beschreibung Startet Die Anzahl der Citrix ICA-Sitzungen, die gestartet. Diese Anzahl beinhaltet verschlüsselte Sitzungen. Aborte Die Anzahl der Citrix ICA-Sitzungen, die initiiert, aber geschlossen, bevor eine Citrix-Anwendung vollständig geladen wurde. - Zusammenfassung der Sitzung
- Dieses Diagramm zeigt, wie viele Citrix ICA-Sitzungen die Anwendung gestartet und
abgebrochen hat.
Metrisch Beschreibung Startet Die Anzahl der Citrix ICA-Sitzungen, die gestartet. Diese Anzahl beinhaltet verschlüsselte Sitzungen. Aborte Die Anzahl der Citrix ICA-Sitzungen, die initiiert, aber geschlossen, bevor eine Citrix-Anwendung vollständig geladen wurde. - Leistung (95. Perzentil)
- Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken.
Metrisch Beschreibung Zeit der Anmeldung Die Zeit zwischen dem Senden eines Citrix ICA-Clients Anmeldedaten für den Citrix ICA-Server und Empfangen der Authentifizierungsantwort. Ladezeit Die Zeitspanne seit dem Beginn des Fluss, bis das ExtraHop-System Datenverkehr auf einer der folgenden virtuellen Kanäle: Zwischenablage, Citrix Windows Multimedia-Umleitung, Citrix Control Virtual Kanal oder Schrift und Tastatur ohne Latenz. Client-Latenz Die Zeit, gemessen und gemeldet von Citrix ICA-Client, zwischen dem ein Benutzer eine Aktion in einer Citrix-Anwendung initiiert und wenn das Ergebnis auf dem Bildschirm erscheint. Netzwerklatenz Die Netzwerklatenz, gemessen und wird sowohl von Citrix ICA-Clients als auch von Citrix ICA-Servern gemeldet. Die Netzwerklatenz ist ein Citrix-Messung. Ein großer Wert sollte untersucht werden. - Leistungsübersicht (95. Perzentil)
- Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken.
Metrisch Beschreibung Zeit der Anmeldung Die Zeit zwischen dem Senden eines Citrix ICA-Clients Anmeldedaten für den Citrix ICA-Server und Empfangen der Authentifizierungsantwort. Ladezeit Die Zeitspanne seit dem Beginn des Fluss, bis das ExtraHop-System Datenverkehr auf einer der folgenden virtuellen Kanäle: Zwischenablage, Citrix Windows Multimedia-Umleitung, Citrix Control Virtual Kanal oder Schrift und Tastatur ohne Latenz. Client-Latenz Die Zeit, gemessen und gemeldet von Citrix ICA-Client, zwischen dem ein Benutzer eine Aktion in einer Citrix-Anwendung initiiert und wenn das Ergebnis auf dem Bildschirm erscheint. Netzwerklatenz Die Netzwerklatenz, gemessen und wird sowohl von Citrix ICA-Clients als auch von Citrix ICA-Servern gemeldet. Die Netzwerklatenz ist ein Citrix-Messung. Ein großer Wert sollte untersucht werden. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
ICA-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Anmeldezeit
- In diesem Diagramm werden die Anmeldezeiten in einem Histogramm dargestellt.
Metrisch Beschreibung Zeit der Anmeldung Die Zeit zwischen dem Senden eines Citrix ICA-Clients Anmeldedaten für den Citrix ICA-Server und Empfangen der Authentifizierungsantwort. - Zeit der Anmeldung
- Dieses Diagramm zeigt die durchschnittliche Anmeldezeit für die Anwendung.
Metrisch Beschreibung Zeit der Anmeldung Die Zeit zwischen dem Senden eines Citrix ICA-Clients Anmeldedaten für den Citrix ICA-Server und Empfangen der Authentifizierungsantwort. - Verteilung der Ladezeit
- In diesem Diagramm werden die Ladezeiten in einem Histogramm dargestellt.
Metrisch Beschreibung Ladezeit Die Zeitspanne seit dem Beginn des Fluss, bis das ExtraHop-System Datenverkehr auf einer der folgenden virtuellen Kanäle: Zwischenablage, Citrix Windows Multimedia-Umleitung, Citrix Control Virtual Kanal oder Schrift und Tastatur ohne Latenz. - Ladezeit
- Dieses Diagramm zeigt die durchschnittliche Ladezeit für die Anwendung.
Metrisch Beschreibung Ladezeit Die Zeitspanne seit dem Beginn des Fluss, bis das ExtraHop-System Datenverkehr auf einer der folgenden virtuellen Kanäle: Zwischenablage, Citrix Windows Multimedia-Umleitung, Citrix Control Virtual Kanal oder Schrift und Tastatur ohne Latenz. - Verteilung der Client-Latenz
- In diesem Diagramm wird die Latenz der Client in einem Histogramm dargestellt.
Metrisch Beschreibung Client-Latenz Die Zeit, gemessen und gemeldet von Citrix ICA-Client, zwischen dem ein Benutzer eine Aktion in einer Citrix-Anwendung initiiert und wenn das Ergebnis auf dem Bildschirm erscheint. - Client-Latenz
- Dieses Diagramm zeigt die durchschnittliche Latenz von Load-Clients.
Metrisch Beschreibung Client-Latenz Die Zeit, gemessen und gemeldet von Citrix ICA-Client, zwischen dem ein Benutzer eine Aktion in einer Citrix-Anwendung initiiert und wenn das Ergebnis auf dem Bildschirm erscheint. - Verteilung der Netzwerklatenz
- In diesem Diagramm wird die Netzwerklatenz in einem Histogramm dargestellt.
Metrisch Beschreibung Netzwerklatenz Die Netzwerklatenz, gemessen und wird sowohl von Citrix ICA-Clients als auch von Citrix ICA-Servern gemeldet. Die Netzwerklatenz ist ein Citrix-Messung. Ein großer Wert sollte untersucht werden. - Netzwerklatenz
- Dieses Diagramm zeigt die durchschnittliche Netzwerklatenz für die Anwendung.
Metrisch Beschreibung Netzwerklatenz Die Netzwerklatenz, gemessen und wird sowohl von Citrix ICA-Clients als auch von Citrix ICA-Servern gemeldet. Die Netzwerklatenz ist ein Citrix-Messung. Ein großer Wert sollte untersucht werden.
Einzelheiten zur Markteinführung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Nutzer
- Dieses Diagramm zeigt, welche Benutzer die meisten Sitzungen gestartet haben, indem die Gesamtzahl der von der Anwendung gestarteten Sitzungen pro Benutzer aufgeschlüsselt wird.
- Die besten Server
- Dieses Diagramm zeigt, auf welchen Servern die Anwendung die meisten Sitzungen gestartet hat, indem die Gesamtzahl der von der Anwendung gestarteten Sitzungen pro Server aufgeschlüsselt wird.
- Die besten Programme
- Dieses Diagramm zeigt, welche Programme die Anwendung am häufigsten gestartet hat, indem die Gesamtzahl der von der Anwendung gestarteten Sitzungen pro Programm aufgeschlüsselt wird.
Einzelheiten zum Abbruch
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Nutzer
- Dieses Diagramm zeigt, welche Benutzer die meisten Sitzungen abgebrochen haben, indem die Gesamtzahl der abgebrochenen Sitzungen pro Benutzer aufgeschlüsselt wird.
- Die besten Server
- Dieses Diagramm zeigt, welche Serversitzungen am häufigsten abgebrochen wurden, indem die Gesamtzahl der abgebrochenen Sitzungen nach Server aufgeschlüsselt wird.
- Die besten Programme
- Dieses Diagramm zeigt, welche Programme die Anwendung am häufigsten abgebrochen hat, indem die Gesamtzahl der abgebrochenen Sitzungen nach Server aufgeschlüsselt wird.
Details zur ICA-Ladezeit
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Nutzer
- Dieses Diagramm zeigt, welche Benutzer die höchsten Ladezeiten hatten, indem die durchschnittlichen Ladezeiten nach Benutzern aufgeschlüsselt wurden.
- Die besten Server
- Dieses Diagramm zeigt, welche Server die höchsten Ladezeiten aufwiesen, indem die durchschnittlichen Ladezeiten nach Servern aufgeschlüsselt wurden.
- Die besten Programme
- Dieses Diagramm zeigt, welche Programme die höchsten Ladezeiten aufwiesen, indem die durchschnittlichen Ladezeiten nach Programmen aufgeschlüsselt wurden.
Virtuelle ICA-Kanäle
Die folgenden Diagramme sind in dieser Region verfügbar:
- Kunden-Goodput-Bytes nach virtuellem Kanal
- Dieses Diagramm zeigt Ihnen Goodput-Bytes, die von Citrix ICA-Clients übertragen wurden, aufgeteilt nach
virtuellen Kanälen.
Metrisch Beschreibung Kunden-Goodput-Bytes nach virtuellem Kanal Die Anzahl der Byte, die vom Citrix ICA-Client. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. - Server-Goodput-Bytes nach virtuellem Kanal
- Dieses Diagramm zeigt Ihnen Goodput-Bytes, die von Citrix ICA-Servern übertragen wurden, aufgeteilt nach
virtuellen Kanälen.
Metrisch Beschreibung Server-Goodput-Bytes nach virtuellem Kanal Die Anzahl der Goodput-Bytes, die von übertragen wurden der Citrix ICA-Server. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass ein Problem mit einem Server oder einem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
-
Dieses Diagramm zeigt die Anzahl der Nullfenster, die einer Anwendung
zugeordnet waren. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der Pakete
angeben, die über einen bestimmten Zeitraum an sie gesendet werden können.
Wenn an ein Gerät mehr Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein
Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig einzustellen, bis das Gerät den Vorgang
aufholt. Wenn Sie eine große Anzahl von Nullfenstern sehen, ist ein Server oder Client möglicherweise
nicht schnell genug, um die empfangene Datenmenge zu unterstützen.
Metrisch Definition Kunde Zero Windows Die Anzahl der Null-Window-Werbungen gesendet von Citrix ICA-Clients. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl eingehender Zero-Windows weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Server Zero Windows Die Anzahl der Null-Window-Werbungen gesendet von Citrix ICA-Servern. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von ausgehenden Zero-Windows weist darauf hin, dass ein Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Gesamtzahl der Host-Stände
- Dieses Diagramm zeigt die durchschnittliche Anzahl von Zero-Window-Werbeanzeigen, die von Geräten gesendet wurden.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen
Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu
viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät
eine Anfrage oder Antwort sendet und innerhalb einer bestimmten
Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen
nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise
zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der verursachten Timeouts bei der erneuten Übertragung durch Überlastung, als Clients Citrix ICA-Nachrichten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Timeouts bei der erneuten Übertragung durch Überlastung, wenn Server Citrix ICA-Nachrichten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
- Gesamtzahl der Netzwerkausfälle
-
Dieses Diagramm zeigt die durchschnittliche Anzahl von Timeouts bei der
erneuten Übertragung, die durch Überlastung beim Senden von Anfragen durch Clients und Server verursacht wurden.
Metrisch Definition RTOs Ein Die Anzahl der verursachten Timeouts bei der erneuten Übertragung durch Überlastung, als Clients Citrix ICA-Nachrichten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Timeouts bei der erneuten Übertragung durch Überlastung, wenn Server Citrix ICA-Nachrichten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Gesamtwerte der ICA-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr Anfragen, als Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um herauszufinden, ob das Problem mit dem Netzwerk oder einem Server zusammenhängt, überprüfen Sie RTOs und Zero Windows in der Netzwerk-Daten Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der ICA-Anfragen und -Antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Startet Die Anzahl der Citrix ICA-Sitzungen, die gestartet. Diese Anzahl beinhaltet verschlüsselte Sitzungen. Aborte Die Anzahl der Citrix ICA-Sitzungen, die initiiert, aber geschlossen, bevor eine Citrix-Anwendung vollständig geladen wurde. Bildschirmaktualisierungen Wie oft der Citrix ICA-Server aktualisiert den Client-Bildschirm Verschlüsselte Sitzungen Die Anzahl der Citrix ICA-Sitzungen, in denen ein verwendet wurde Eine andere Verschlüsselungsmethode als Basic. Bestimmte Metriken sind für diese nicht verfügbar Sitzungen. Kundennachrichten Die Anzahl der Citrix ICA-Clientnachrichten übertragen. Servernachrichten Die Anzahl der Citrix ICA-Servermeldungen übertragen. Client-CGP-Nachrichten Die Anzahl der CGP-Meldungen, die vom Citrix ICA-Client. Das Client Gateway Protocol (CGP) kapselt den Citrix ICA-Verkehr zur Unterstützung der Sitzungszuverlässigkeit. Server-CGP-Nachrichten Die Anzahl der CGP-Meldungen, die vom Citrix ICA-Server. Das Client Gateway Protocol (CGP) kapselt den Citrix ICA-Verkehr zur Unterstützung der Sitzungszuverlässigkeit. - ICA-Netzwerkmetriken
-
Metrisch Beschreibung Kunde Zero Windows Die Anzahl der Null-Window-Werbungen gesendet von Citrix ICA-Clients. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Server Zero Windows Die Anzahl der Null-Window-Werbungen gesendet von Citrix ICA-Servern. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. RTOs für Kunden Die Anzahl der verursachten Timeouts bei der erneuten Übertragung durch Überlastung, als Clients Citrix ICA-Nachrichten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Server-RTOs Die Anzahl der verursachten Timeouts bei der erneuten Übertragung durch Überlastung, wenn Server Citrix ICA-Nachrichten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. L2-Byte für den Client Die Anzahl der L2-Bytes, die von übertragen wurden der Citrix ICA-Client. L2-Byte des Servers Die Anzahl der L2-Bytes, die von übertragen wurden der Citrix ICA-Server. Kunde Goodput Bytes Die Anzahl der Byte, die vom Citrix ICA-Client. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Goodput-Bytes für Server Die Anzahl der Goodput-Bytes, die von übertragen wurden der Citrix ICA-Server. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Client-Pakete Die Anzahl der von Citrix übertragenen Pakete ICA-Clients. Server-Pakete Die Anzahl der Pakete, die von der übertragen wurden Citrix ICA-Server. Kunde Nagle Delays Die Anzahl der Citrix ICA-Verbindungsverzögerungen für den Client aufgrund einer schlechten Interaktion zwischen Nagles Algorithmus und verzögert Hacks. Server-Nagle-Verzögerungen Die Anzahl der Citrix ICA-Verbindungsverzögerungen für den Server aufgrund einer schlechten Interaktion zwischen Nagles Algorithmus und verzögert ACKs.
ICA-Clientseite
Auf dieser Seite werden Metrikdiagramme von angezeigt ICA Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
ICA-Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Sessions
- Dieses Diagramm zeigt, wann der Client Citrix ICA-Sitzungen gestartet und abgebrochen hat.
Metrisch Beschreibung Startet Die Anzahl der Citrix ICA-Sitzungen, die Gerät wurde als Client gestartet. Diese Anzahl beinhaltet verschlüsselte Sitzungen. Aborte Die Anzahl der Citrix ICA-Sitzungen, die begonnen wurden von diese Citrix ICA-Clients, die von einem der Endpoints vor einem geschlossen wurden Anwendung wurde geladen. - Sitzungen insgesamt
- Dieses Diagramm zeigt, wie viele Citrix ICA-Sitzungen der Client gestartet und
abgebrochen hat.
Metrisch Beschreibung Startet Die Anzahl der Citrix ICA-Sitzungen, die Gerät wurde als Client gestartet. Diese Anzahl beinhaltet verschlüsselte Sitzungen. Aborte Die Anzahl der Citrix ICA-Sitzungen, die begonnen wurden von diese Citrix ICA-Clients, die von einem der Endpoints vor einem geschlossen wurden Anwendung wurde geladen. - Leistung (95. Perzentil)
- Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken.
Metrisch Beschreibung Zeit der Anmeldung Die Zeit zwischen der Übertragung des Citrix ICA-Paket, das der Client mit seinen Anmeldedaten an den Server sendet, und Citrix ICA-Paket, das der Server mit dem Benutzer an den Client zurücksendet Name. Ladezeit Die Zeitspanne seit dem Beginn des Fluss, bis das ExtraHop-System Datenverkehr auf einer der folgenden virtuellen Kanäle: Zwischenablage, Citrix Windows Multimedia-Umleitung, Citrix Control Virtual Kanal oder Schrift und Tastatur ohne Latenz. Client-Latenz Wenn das Gerät als Citrix fungiert ICA-Client, die Zeit zwischen der Initiierung einer Interaktion durch einen Benutzer mit einer Anwendung und wenn das Ergebnis auf dem Bildschirm erscheint. Diese Metrik ist nur verfügbar in Umgebungen, in denen Citrix EUEM aktiviert ist Netzwerklatenz Die erkannte Netzwerklatenz zwischen die Server und das Gerät, wenn es als Citrix ICA-Server fungiert, ohne Verarbeitung Zeit auf dem Client oder Server. - Aufführung (95.)
- Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken.
Metrisch Beschreibung Zeit der Anmeldung Die Zeit zwischen der Übertragung des Citrix ICA-Paket, das der Client mit seinen Anmeldedaten an den Server sendet, und Citrix ICA-Paket, das der Server mit dem Benutzer an den Client zurücksendet Name. Ladezeit Die Zeitspanne seit dem Beginn des Fluss, bis das ExtraHop-System Datenverkehr auf einer der folgenden virtuellen Kanäle: Zwischenablage, Citrix Windows Multimedia-Umleitung, Citrix Control Virtual Kanal oder Schrift und Tastatur ohne Latenz. Client-Latenz Wenn das Gerät als Citrix fungiert ICA-Client, die Zeit zwischen der Initiierung einer Interaktion durch einen Benutzer mit einer Anwendung und wenn das Ergebnis auf dem Bildschirm erscheint. Diese Metrik ist nur verfügbar in Umgebungen, in denen Citrix EUEM aktiviert ist Netzwerklatenz Die erkannte Netzwerklatenz zwischen die Server und das Gerät, wenn es als Citrix ICA-Server fungiert, ohne Verarbeitung Zeit auf dem Client oder Server. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
ICA-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Anmeldezeit
- In diesem Diagramm werden die Anmeldezeiten in einem Histogramm dargestellt.
Metrisch Beschreibung Zeit der Anmeldung Die Zeit zwischen der Übertragung des Citrix ICA-Paket, das der Client mit seinen Anmeldedaten an den Server sendet, und Citrix ICA-Paket, das der Server mit dem Benutzer an den Client zurücksendet Name. - Zeit der Anmeldung
- Dieses Diagramm zeigt die durchschnittliche Anmeldezeit für den Client.
Metrisch Beschreibung Zeit der Anmeldung Die Zeit zwischen der Übertragung des Citrix ICA-Paket, das der Client mit seinen Anmeldedaten an den Server sendet, und Citrix ICA-Paket, das der Server mit dem Benutzer an den Client zurücksendet Name. - Verteilung der Ladezeit
- In diesem Diagramm werden die Ladezeiten in einem Histogramm dargestellt.
Metrisch Beschreibung Ladezeit Die Zeitspanne seit dem Beginn des Fluss, bis das ExtraHop-System Datenverkehr auf einer der folgenden virtuellen Kanäle: Zwischenablage, Citrix Windows Multimedia-Umleitung, Citrix Control Virtual Kanal oder Schrift und Tastatur ohne Latenz. - Ladezeit
- Dieses Diagramm zeigt die durchschnittliche Ladezeit für den Client.
Metrisch Beschreibung Ladezeit Die Zeitspanne seit dem Beginn des Fluss, bis das ExtraHop-System Datenverkehr auf einer der folgenden virtuellen Kanäle: Zwischenablage, Citrix Windows Multimedia-Umleitung, Citrix Control Virtual Kanal oder Schrift und Tastatur ohne Latenz. - Verteilung der Client-Latenz
- In diesem Diagramm wird die Latenz der Client in einem Histogramm dargestellt.
Metrisch Beschreibung Client-Latenz Wenn das Gerät als Citrix fungiert ICA-Client, die Zeit zwischen der Initiierung einer Interaktion durch einen Benutzer mit einer Anwendung und wenn das Ergebnis auf dem Bildschirm erscheint. Diese Metrik ist nur verfügbar in Umgebungen, in denen Citrix EUEM aktiviert ist - Client-Latenz
- Dieses Diagramm zeigt die durchschnittliche Latenz von Load-Clients.
Metrisch Beschreibung Client-Latenz Wenn das Gerät als Citrix fungiert ICA-Client, die Zeit zwischen der Initiierung einer Interaktion durch einen Benutzer mit einer Anwendung und wenn das Ergebnis auf dem Bildschirm erscheint. Diese Metrik ist nur verfügbar in Umgebungen, in denen Citrix EUEM aktiviert ist - Verteilung der Netzwerklatenz
- In diesem Diagramm wird die Netzwerklatenz in einem Histogramm dargestellt.
Metrisch Beschreibung Netzwerklatenz Die erkannte Netzwerklatenz zwischen die Server und das Gerät, wenn es als Citrix ICA-Server fungiert, ohne Verarbeitung Zeit auf dem Client oder Server. - Netzwerklatenz
- Dieses Diagramm zeigt die durchschnittliche Netzwerklatenz für den Client.
Metrisch Beschreibung Netzwerklatenz Die erkannte Netzwerklatenz zwischen die Server und das Gerät, wenn es als Citrix ICA-Server fungiert, ohne Verarbeitung Zeit auf dem Client oder Server.
Einzelheiten zur Markteinführung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Nutzer
- Dieses Diagramm zeigt, welche Benutzer die meisten Sitzungen gestartet haben, indem die Gesamtzahl der vom Client gestarteten Sitzungen pro Benutzer aufgeschlüsselt wird.
- Die besten Server
- Dieses Diagramm zeigt, auf welchen Servern der Client die meisten Sitzungen gestartet hat, indem die Gesamtzahl der vom Client gestarteten Sitzungen pro Server aufgeschlüsselt wird.
- Die besten Programme
- Dieses Diagramm zeigt, welche Programme der Client am häufigsten gestartet hat, indem die Gesamtzahl der vom Client gestarteten Sitzungen pro Programm aufgeschlüsselt wird.
Einzelheiten zum Abbruch
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Nutzer
- Dieses Diagramm zeigt, welche Benutzer die meisten Sitzungen abgebrochen haben, indem die Gesamtzahl der abgebrochenen Sitzungen pro Benutzer aufgeschlüsselt wird.
- Die besten Server
- Dieses Diagramm zeigt, welche Serversitzungen am häufigsten abgebrochen wurden, indem die Gesamtzahl der abgebrochenen Sitzungen nach Server aufgeschlüsselt wird.
- Die besten Programme
- Dieses Diagramm zeigt, welche Programme der Client am häufigsten abgebrochen hat, indem die Gesamtzahl der abgebrochenen Sitzungen nach Server aufgeschlüsselt wird.
Details zur ICA-Ladezeit
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Nutzer
- Dieses Diagramm zeigt, welche Benutzer die höchsten Ladezeiten hatten, indem die durchschnittlichen Ladezeiten nach Benutzern aufgeschlüsselt wurden.
- Die besten Server
- Dieses Diagramm zeigt, welche Server die höchsten Ladezeiten aufwiesen, indem die durchschnittlichen Ladezeiten nach Servern aufgeschlüsselt wurden.
- Die besten Programme
- Dieses Diagramm zeigt, welche Programme die höchsten Ladezeiten aufwiesen, indem die durchschnittlichen Ladezeiten nach Programmen aufgeschlüsselt wurden.
Virtuelle ICA-Kanäle
Die folgenden Diagramme sind in dieser Region verfügbar:
- Goodput Byte per virtuellem Kanal
- Dieses Diagramm zeigt Ihnen die im Laufe der Zeit empfangenen Goodput-Bytes, aufgeschlüsselt nach virtuellen Kanälen.
Metrisch Beschreibung Goodput Byte per virtuellem Kanal Die Anzahl der empfangenen Goodput-Bytes wenn das Gerät als Citrix ICA-Client fungiert, aufgeschlüsselt nach virtuellem Kanal. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Ein virtueller Kanal ist eine Teilmenge der ICA-Kommunikation, die sich auf eine bestimmte Aufgabe bezieht. Ein virtueller Kanal ist eine Teilmenge der ICA-Kommunikation, die sich auf eine bestimmte Aufgabe bezieht. - Goodput-Bytes werden per virtuellem Kanal ausgegeben
- Dieses Diagramm zeigt die im Laufe der Zeit gesendeten Goodput-Bytes, aufgeschlüsselt nach virtuellen Kanälen.
Metrisch Beschreibung Goodput-Bytes werden per virtuellem Kanal ausgegeben Die Anzahl der gesendeten Goodput-Bytes wenn das Gerät als Citrix ICA-Client fungiert, aufgeschlüsselt nach virtuellem Kanal. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Ein virtueller Kanal ist eine Teilmenge der ICA-Kommunikation, die sich auf eine bestimmte Aufgabe bezieht.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Gesamtwerte der ICA-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Sitzungen
- Zeigt die Gesamtzahl der vom
Client initiierten Starts, Abbrüche und Bildschirmaktualisierungen an.
Metrisch Beschreibung Startet Die Anzahl der Citrix ICA-Sitzungen, die Gerät wurde als Client gestartet. Diese Anzahl beinhaltet verschlüsselte Sitzungen. Aborte Die Anzahl der Citrix ICA-Sitzungen, die begonnen wurden von diese Citrix ICA-Clients, die von einem der Endpoints vor einem geschlossen wurden Anwendung wurde geladen. Bildschirmaktualisierungen Die Häufigkeit, mit der ein Server aktualisiert wurde der Bildschirm, als das Gerät als Citrix ICA-Client fungierte. Verschlüsselte Sitzungen Die Anzahl der Sitzungen, die Gerät, das als Citrix ICA-Client teilgenommen hat und das eine Verschlüsselungsmethode verwendet hat außer Basic. Bestimmte Metriken sind für diese Sitzungen nicht verfügbar. - Sitzungen und Nachrichten
- Zeigt an, an wie vielen Sitzungen der Client teilgenommen hat und wie viele Nachrichten der Client
gesendet und empfangen hat.
Metrisch Beschreibung Kundennachrichten Die Anzahl der Citrix ICA-Clientnachrichten gesendet vom Gerät, wenn es als Citrix ICA-Client fungiert. Servernachrichten Die Anzahl der Citrix ICA-Servermeldungen wird an das Gerät gesendet, wenn es als Citrix ICA-Client fungiert. Client-CGP-Nachrichten Die Anzahl der CGP-Meldungen, die gesendet wurden, wenn das Gerät fungiert als Citrix ICA-Client. Das Client Gateway Protocol (CGP) kapselt den Citrix ICA-Verkehr zur Unterstützung der Sitzungszuverlässigkeit Server-CGP-Nachrichten Die Anzahl der CGP-Servernachrichten wird ausgetauscht, wenn das Gerät als Citrix ICA-Client fungiert. Das Client Gateway Das Protokoll (CGP) kapselt den Citrix ICA-Verkehr zur Unterstützung von Session Zuverlässigkeit.
ICA-Serverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt ICA Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
ICA Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Sessions
- Dieses Diagramm zeigt, wann der Server Citrix ICA-Sitzungen gestartet und abgebrochen hat.
Metrisch Beschreibung Startet Die Anzahl der Citrix ICA-Sitzungen, die Gerät wurde als Server gestartet. Diese Anzahl beinhaltet verschlüsselte Sitzungen. Aborte Die Anzahl der Citrix ICA-Sitzungen, die begonnen wurden von diese Citrix ICA-Server, die von einem der Endpoints vor einem geschlossen wurden Anwendung wurde geladen. - Gesamtzahl der Sitzungen
- Dieses Diagramm zeigt, wie viele Citrix ICA-Sitzungen der Server gestartet und
abgebrochen hat.
Metrisch Beschreibung Startet Die Anzahl der Citrix ICA-Sitzungen, die Gerät wurde als Server gestartet. Diese Anzahl beinhaltet verschlüsselte Sitzungen. Aborte Die Anzahl der Citrix ICA-Sitzungen, die begonnen wurden von diese Citrix ICA-Server, die von einem der Endpoints vor einem geschlossen wurden Anwendung wurde geladen. - Leistung (95. Perzentil)
- Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken.
Metrisch Beschreibung Zeit der Anmeldung Die Zeit zwischen der Übertragung des Citrix ICA-Paket, das der Client mit seinen Anmeldedaten an den Server sendet, und Citrix ICA-Paket, das der Server mit dem Benutzer an den Client zurücksendet Name. Ladezeit Die Zeitspanne seit dem Beginn des Fluss, bis das ExtraHop-System Datenverkehr auf einer der folgenden virtuellen Kanäle: Zwischenablage, Citrix Windows Multimedia-Umleitung, Citrix Control Virtual Kanal oder Schrift und Tastatur ohne Latenz. Server-Latenz Wenn das Gerät als Citrix fungiert ICA-Server, die Zeit zwischen Benutzern, die eine Interaktion mit einer Anwendung initiieren, und wenn das Ergebnis auf dem Bildschirm erscheint. Diese Metrik ist nur in Umgebungen verfügbar wo Citrix EUEM aktiviert ist Netzwerklatenz Die erkannte Netzwerklatenz zwischen die Server und das Gerät, wenn es als Citrix ICA-Server fungiert, ohne Verarbeitung Zeit auf dem Client oder Server. - Aufführung (95.)
- Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken.
Metrisch Beschreibung Zeit der Anmeldung Die Zeit zwischen der Übertragung des Citrix ICA-Paket, das der Client mit seinen Anmeldedaten an den Server sendet, und Citrix ICA-Paket, das der Server mit dem Benutzer an den Client zurücksendet Name. Ladezeit Die Zeitspanne seit dem Beginn des Fluss, bis das ExtraHop-System Datenverkehr auf einer der folgenden virtuellen Kanäle: Zwischenablage, Citrix Windows Multimedia-Umleitung, Citrix Control Virtual Kanal oder Schrift und Tastatur ohne Latenz. Server-Latenz Wenn das Gerät als Citrix fungiert ICA-Server, die Zeit zwischen Benutzern, die eine Interaktion mit einer Anwendung initiieren, und wenn das Ergebnis auf dem Bildschirm erscheint. Diese Metrik ist nur in Umgebungen verfügbar wo Citrix EUEM aktiviert ist Netzwerklatenz Die erkannte Netzwerklatenz zwischen die Server und das Gerät, wenn es als Citrix ICA-Server fungiert, ohne Verarbeitung Zeit auf dem Client oder Server. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
ICA-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Anmeldezeit
- In diesem Diagramm werden die Anmeldezeiten in einem Histogramm dargestellt.
Metrisch Beschreibung Zeit der Anmeldung Die Zeit zwischen der Übertragung des Citrix ICA-Paket, das der Client mit seinen Anmeldedaten an den Server sendet, und Citrix ICA-Paket, das der Server mit dem Benutzer an den Client zurücksendet Name. - Zeit der Anmeldung
- Dieses Diagramm zeigt die durchschnittliche Anmeldezeit für den Server.
Metrisch Beschreibung Zeit der Anmeldung Die Zeit zwischen der Übertragung des Citrix ICA-Paket, das der Client mit seinen Anmeldedaten an den Server sendet, und Citrix ICA-Paket, das der Server mit dem Benutzer an den Client zurücksendet Name. - Verteilung der Ladezeit
- Dieses Diagramm zeigt die durchschnittliche Anmeldezeit für den Server.
Metrisch Beschreibung Ladezeit Die Zeitspanne seit dem Beginn des Fluss, bis das ExtraHop-System Datenverkehr auf einer der folgenden virtuellen Kanäle: Zwischenablage, Citrix Windows Multimedia-Umleitung, Citrix Control Virtual Kanal oder Schrift und Tastatur ohne Latenz. - Ladezeit
- Dieses Diagramm zeigt die durchschnittliche Ladezeit für den Server.
Metrisch Beschreibung Ladezeit Die Zeitspanne seit dem Beginn des Fluss, bis das ExtraHop-System Datenverkehr auf einer der folgenden virtuellen Kanäle: Zwischenablage, Citrix Windows Multimedia-Umleitung, Citrix Control Virtual Kanal oder Schrift und Tastatur ohne Latenz. - Verteilung der Client-Latenz
- In diesem Diagramm wird die Latenz der Client in einem Histogramm dargestellt.
Metrisch Beschreibung Client-Latenz Wenn das Gerät als Citrix fungiert ICA-Server, die Zeit zwischen Benutzern, die eine Interaktion mit einer Anwendung initiieren, und wenn das Ergebnis auf dem Bildschirm erscheint. Diese Metrik ist nur in Umgebungen verfügbar wo Citrix EUEM aktiviert ist - Client-Latenz
- Dieses Diagramm zeigt die durchschnittliche Latenz von Load-Clients.
Metrisch Beschreibung Client-Latenz Wenn das Gerät als Citrix fungiert ICA-Server, die Zeit zwischen Benutzern, die eine Interaktion mit einer Anwendung initiieren, und wenn das Ergebnis auf dem Bildschirm erscheint. Diese Metrik ist nur in Umgebungen verfügbar wo Citrix EUEM aktiviert ist - Verteilung der Netzwerklatenz
- In diesem Diagramm wird die Netzwerklatenz in einem Histogramm dargestellt.
Metrisch Beschreibung Netzwerklatenz Die erkannte Netzwerklatenz zwischen die Server und das Gerät, wenn es als Citrix ICA-Server fungiert, ohne Verarbeitung Zeit auf dem Client oder Server. - Netzwerklatenz
- Dieses Diagramm zeigt die mittlere Netzwerklatenz für den Server.
Metrisch Beschreibung Netzwerklatenz Die erkannte Netzwerklatenz zwischen die Server und das Gerät, wenn es als Citrix ICA-Server fungiert, ohne Verarbeitung Zeit auf dem Client oder Server.
Einzelheiten zur Markteinführung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Nutzer
- Dieses Diagramm zeigt, welche Benutzer die meisten Sitzungen gestartet haben, indem die Gesamtzahl der abgebrochenen Sitzungen pro Benutzer aufgeschlüsselt wird.
- Top-Kunden
- Dieses Diagramm zeigt, welche Clients die meisten Sitzungen auf dem Server gestartet haben, indem die Gesamtzahl der vom Client gestarteten Sitzungen aufgeschlüsselt wird.
- Die besten Programme
- Dieses Diagramm zeigt anhand der Gesamtzahl der pro Programm gestarteten Sitzungen, welche Programme am häufigsten auf dem Server gestartet wurden.
Einzelheiten zum Abbruch
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Nutzer
- Dieses Diagramm zeigt, welche Benutzer die meisten Sitzungen abgebrochen haben, indem die Gesamtzahl der abgebrochenen Sitzungen pro Benutzer aufgeschlüsselt wird.
- Top-Kunden
- Dieses Diagramm zeigt, welche Clients die meisten Sitzungen auf dem Server abgebrochen haben, indem die Gesamtzahl der abgebrochenen Sitzungen pro Client aufgeschlüsselt wird.
- Die besten Programme
- Dieses Diagramm zeigt, welche Programme auf dem Server am häufigsten abgebrochen wurden, indem die Gesamtzahl der abgebrochenen Sitzungen pro Programm aufgeschlüsselt wird.
Details zur Ladezeit
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Nutzer
- Dieses Diagramm zeigt, welche Benutzer die höchsten Ladezeiten hatten, indem die durchschnittlichen Ladezeiten nach Benutzern aufgeschlüsselt wurden.
- Top-Kunden
- Dieses Diagramm zeigt, welche Clients die höchsten Ladezeiten hatten, indem die durchschnittlichen Ladezeiten nach Client aufgeschlüsselt wurden.
- Die besten Programme
- Dieses Diagramm zeigt, welche Programme die höchsten Ladezeiten aufwiesen, indem die durchschnittlichen Ladezeiten nach Programmen aufgeschlüsselt wurden.
Virtuelle ICA-Kanäle
Die folgenden Diagramme sind in dieser Region verfügbar:
- Goodput Byte Input pro Kanal
- Dieses Diagramm zeigt Ihnen die im Laufe der Zeit empfangenen Goodput-Bytes, aufgeschlüsselt nach virtuellen Kanälen.
Metrisch Beschreibung Goodput Byte per virtuellem Kanal Die Anzahl der empfangenen Goodput-Bytes wenn das Gerät als Citrix ICA-Server fungiert, aufgeschlüsselt nach virtuellem Kanal. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Ein virtueller Kanal ist eine Teilmenge der ICA-Kommunikation, die sich auf eine bestimmte Aufgabe bezieht. - Goodput-Bytes nach Kanal
- Dieses Diagramm zeigt die im Laufe der Zeit gesendeten Goodput-Bytes, aufgeschlüsselt nach virtuellen Kanälen.
Metrisch Beschreibung Goodput-Bytes werden per virtuellem Kanal ausgegeben Die Anzahl der empfangenen Goodput-Bytes wenn das Gerät als Citrix ICA-Server fungiert, aufgeschlüsselt nach virtuellem Kanal. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Ein virtueller Kanal ist eine Teilmenge der ICA-Kommunikation, die sich auf eine bestimmte Aufgabe bezieht.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Gesamtwerte der ICA-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Sitzungen
- Zeigt die Gesamtzahl der vom
Server initiierten Starts, Abbrüche und Bildschirmaktualisierungen an.
Metrisch Beschreibung Startet Die Anzahl der Citrix ICA-Sitzungen, die Gerät wurde als Server gestartet. Diese Anzahl beinhaltet verschlüsselte Sitzungen. Aborte Die Anzahl der Citrix ICA-Sitzungen, die begonnen wurden von diese Citrix ICA-Server, die von einem der Endpoints vor einem geschlossen wurden Anwendung wurde geladen. Bildschirmaktualisierungen Die Häufigkeit, mit der das Gerät wann hat als Citrix ICA-Server fungiert und den Bildschirm eines Client aktualisiert Verschlüsselte Sitzungen Die Anzahl der Sitzungen, die Gerät, an dem ein Citrix ICA-Server beteiligt war und das eine Verschlüsselungsmethode verwendete außer Basic. Bestimmte Metriken sind für diese Sitzungen nicht verfügbar. - Nachrichten insgesamt
- Zeigt an, an wie vielen Sitzungen der Server teilgenommen hat und wie viele Nachrichten der Server
gesendet und empfangen hat.
Metrisch Beschreibung Kundennachrichten Die Anzahl der Citrix ICA-Clientnachrichten vom Gerät empfangen, wenn es als Citrix ICA-Server fungiert. Server-Meldungen Die Anzahl der Citrix ICA-Servermeldungen wird vom Gerät gesendet, wenn es als Citrix ICA-Server fungiert. Client-CGP-Nachrichten Die Anzahl der CGP-Meldungen, die gesendet wurden, wenn das Gerät fungiert als Citrix ICA-Server. Das Client Gateway Protocol (CGP) kapselt den Citrix ICA-Verkehr zur Unterstützung der Sitzungszuverlässigkeit Server-CGP-Nachrichten Die Anzahl der CGP-Servernachrichten wird ausgetauscht, wenn das Gerät als Citrix ICA-Server fungiert. Das Client Gateway Das Protokoll (CGP) kapselt den Citrix ICA-Verkehr zur Unterstützung von Session Zuverlässigkeit.
ICA-Clientgruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt ICA Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
DNS Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Sessions
- Dieses Diagramm zeigt, wann Clients in der Gruppe Citrix
ICA-Sitzungen gestartet und abgebrochen haben.
Metrisch Beschreibung Startet Die Anzahl der Citrix ICA-Sitzungen, die Gerät wurde als Client gestartet. Diese Anzahl beinhaltet verschlüsselte Sitzungen. Aborte Die Anzahl der Citrix ICA-Sitzungen, die begonnen wurden von diese Citrix ICA-Clients, die von einem der Endpoints vor einem geschlossen wurden Anwendung wurde geladen. - Gesamtzahl der Sitzungen
- Dieses Diagramm zeigt, wie oft Clients in der Gruppe Citrix
ICA-Sitzungen gestartet und abgebrochen haben.
Metrisch Beschreibung Startet Die Anzahl der Citrix ICA-Sitzungen, die Gerät wurde als Client gestartet. Diese Anzahl beinhaltet verschlüsselte Sitzungen. Aborte Die Anzahl der Citrix ICA-Sitzungen, die begonnen wurden von diese Citrix ICA-Clients, die von einem der Endpoints vor einem geschlossen wurden Anwendung wurde geladen.
Informationen ICA ICA-Start für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (ICA-Clients)
- Dieses Diagramm zeigt, welche ICA-Clients in der Gruppe am aktivsten waren, indem die Gesamtzahl der ICA-Sitzungsstarts pro Client aufgeschlüsselt wird.
- Die besten Nutzer
- Dieses Diagramm zeigt, welche ICA-Benutzer in der Gruppe am aktivsten waren, indem die Gesamtzahl der ICA-Sitzungsstarts pro Benutzer aufgeschlüsselt wird.
- Die besten Programme
- Dieses Diagramm zeigt, welche ICA-Programme die Gruppe am aktivsten gestartet hat, indem die Gesamtzahl der ICA-Sitzungsstarts nach Programmen aufgeschlüsselt wird.
ICA-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Sessions
- Zeigt an, wie viele Sitzungen Clients in der Gruppe gestartet und abgebrochen haben.
Metrisch Beschreibung Startet Die Anzahl der Citrix ICA-Sitzungen, die Gerät wurde als Client gestartet. Diese Anzahl beinhaltet verschlüsselte Sitzungen. Aborte Die Anzahl der Citrix ICA-Sitzungen, die begonnen wurden von diese Citrix ICA-Clients, die von einem der Endpoints vor einem geschlossen wurden Anwendung wurde geladen. Bildschirmaktualisierungen Die Häufigkeit, mit der ein Server aktualisiert wurde der Bildschirm, als das Gerät als Citrix ICA-Client fungierte. Verschlüsselte Sitzungen Die Anzahl der Sitzungen, die Gerät, das als Citrix ICA-Client teilgenommen hat und das eine Verschlüsselungsmethode verwendet hat außer Basic. Bestimmte Metriken sind für diese Sitzungen nicht verfügbar. - Nachrichten insgesamt
- Zeigt an, an wie vielen Sitzungen die Clients in der Gruppe teilgenommen haben und wie viele
Nachrichten die Clients gesendet und empfangen haben.
Metrisch Beschreibung Verschlüsselte Sitzungen Die Anzahl der Sitzungen, die Gerät, das als Citrix ICA-Client teilgenommen hat und das eine Verschlüsselungsmethode verwendet hat außer Basic. Bestimmte Metriken sind für diese Sitzungen nicht verfügbar. Kundennachrichten Die Anzahl der Citrix ICA-Clientnachrichten gesendet vom Gerät, wenn es als Citrix ICA-Client fungiert. Servernachrichten Die Anzahl der Citrix ICA-Servermeldungen wird an das Gerät gesendet, wenn es als Citrix ICA-Client fungiert. Client-CGP-Nachrichten Die Anzahl der CGP-Meldungen, die gesendet wurden, wenn das Gerät fungiert als Citrix ICA-Client. Das Client Gateway Protocol (CGP) kapselt den Citrix ICA-Verkehr zur Unterstützung der Sitzungszuverlässigkeit Server-CGP-Nachrichten Die Anzahl der CGP-Servernachrichten wird ausgetauscht, wenn das Gerät als Citrix ICA-Client fungiert. Das Client Gateway Das Protokoll (CGP) kapselt den Citrix ICA-Verkehr zur Unterstützung von Session Zuverlässigkeit. - Anmelde- und Ladezeit (95. Perzentil)
- Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken.
Metrisch Beschreibung Zeit der Anmeldung Die Zeit zwischen der Übertragung des Citrix ICA-Paket, das der Client mit seinen Anmeldedaten an den Server sendet, und Citrix ICA-Paket, das der Server mit dem Benutzer an den Client zurücksendet Name. Ladezeit Die Zeitspanne seit dem Beginn des Fluss, bis das ExtraHop-System Datenverkehr auf einer der folgenden virtuellen Kanäle: Zwischenablage, Citrix Windows Multimedia-Umleitung, Citrix Control Virtual Kanal oder Schrift und Tastatur ohne Latenz.
ICA-Servergruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt ICA Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
ICA Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Sessions
- Dieses Diagramm zeigt, wann Server in der Gruppe Citrix
ICA-Sitzungen gestartet und abgebrochen haben.
Metrisch Beschreibung Startet Die Anzahl der Citrix ICA-Sitzungen, die Gerät wurde als Server gestartet. Diese Anzahl beinhaltet verschlüsselte Sitzungen. Aborte Die Anzahl der Citrix ICA-Sitzungen, die begonnen wurden von diese Citrix ICA-Server, die von einem der Endpoints vor einem geschlossen wurden Anwendung wurde geladen. - Gesamtzahl der Sitzungen
- Dieses Diagramm zeigt, wie oft Server in der Gruppe Citrix
ICA-Sitzungen gestartet und abgebrochen haben.
Metrisch Beschreibung Startet Die Anzahl der Citrix ICA-Sitzungen, die Gerät wurde als Server gestartet. Diese Anzahl beinhaltet verschlüsselte Sitzungen. Aborte Die Anzahl der Citrix ICA-Sitzungen, die begonnen wurden von diese Citrix ICA-Server, die von einem der Endpoints vor einem geschlossen wurden Anwendung wurde geladen.
Informationen ICA ICA-Start für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (ICA-Server)
- Dieses Diagramm zeigt, welche ICA-Server in der Gruppe am aktivsten waren, indem die Gesamtzahl der ICA-Antworten, die die Gruppe vom Server gesendet hat, aufgeschlüsselt wird.
- Die besten Nutzer
- Dieses Diagramm zeigt, welche ICA-Benutzer in der Gruppe am aktivsten waren, indem die Gesamtzahl der ICA-Sitzungsstarts nach Benutzern aufgeschlüsselt wird.
- Die besten Programme
- Dieses Diagramm zeigt, welche ICA-Programme in der Gruppe am aktivsten gestartet wurden, indem die Gesamtzahl der ICA-Sitzungsstarts nach Programmen aufgeschlüsselt wird.
ICA-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Sitzungen
- Dieses Diagramm zeigt, wie viele Sitzungsserver in der Gruppe gestartet und abgebrochen wurden.
Metrisch Beschreibung Startet Die Anzahl der Citrix ICA-Sitzungen, die Gerät wurde als Server gestartet. Diese Anzahl beinhaltet verschlüsselte Sitzungen. Aborte Die Anzahl der Citrix ICA-Sitzungen, die begonnen wurden von diese Citrix ICA-Server, die von einem der Endpoints vor einem geschlossen wurden Anwendung wurde geladen. Bildschirmaktualisierungen Die Häufigkeit, mit der das Gerät wann hat als Citrix ICA-Server fungiert und den Bildschirm eines Client aktualisiert Verschlüsselte Sitzungen Die Anzahl der Sitzungen, die Gerät, an dem ein Citrix ICA-Server beteiligt war und das eine Verschlüsselungsmethode verwendete außer Basic. Bestimmte Metriken sind für diese Sitzungen nicht verfügbar. - Nachrichten insgesamt
- Zeigt an, an wie vielen Sitzungen die Server in der Gruppe teilgenommen haben und wie viele
Nachrichten die Server gesendet und empfangen haben.
Metrisch Beschreibung Verschlüsselte Sitzungen Die Anzahl der Sitzungen, die Gerät, an dem ein Citrix ICA-Server beteiligt war und das eine Verschlüsselungsmethode verwendete außer Basic. Bestimmte Metriken sind für diese Sitzungen nicht verfügbar. Kundennachrichten Die Anzahl der Citrix ICA-Clientnachrichten vom Gerät empfangen, wenn es als Citrix ICA-Server fungiert. Servernachrichten Die Anzahl der Citrix ICA-Servermeldungen wird vom Gerät gesendet, wenn es als Citrix ICA-Server fungiert. Client-CGP-Nachrichten Die Anzahl der CGP-Meldungen, die gesendet wurden, wenn das Gerät fungiert als Citrix ICA-Server. Das Client Gateway Protocol (CGP) kapselt den Citrix ICA-Verkehr zur Unterstützung der Sitzungszuverlässigkeit Server-CGP-Nachrichten Die Anzahl der CGP-Servernachrichten wird ausgetauscht, wenn das Gerät als Citrix ICA-Server fungiert. Das Client Gateway Das Protokoll (CGP) kapselt den Citrix ICA-Verkehr zur Unterstützung von Session Zuverlässigkeit. - Anmelde- und Ladezeit (95. Perzentil)
- Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken.
Metrisch Beschreibung Zeit der Anmeldung Die Zeit zwischen der Übertragung des Citrix ICA-Paket, das der Client mit seinen Anmeldedaten an den Server sendet, und Citrix ICA-Paket, das der Server mit dem Benutzer an den Client zurücksendet Name. Ladezeit Die Zeitspanne seit dem Beginn des Fluss, bis das ExtraHop-System Datenverkehr auf einer der folgenden virtuellen Kanäle: Zwischenablage, Citrix Windows Multimedia-Umleitung, Citrix Control Virtual Kanal oder Schrift und Tastatur ohne Latenz.
iSCSI
Das ExtraHop-System sammelt Messwerte zur Internet Small Computer System Interface (iSCSI) Aktivität. iSCSI ist ein Protokoll auf TCP-Ebene, mit dem SCSI-Befehle über ein lokales Netzwerk (LAN) oder ein Weitverkehrsnetzwerk (WAN) gesendet werden können.
iSCSI-Client-Seite
Auf dieser Seite werden Metrikdiagramme von angezeigt iSCSI Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
iSCSI Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann iSCSI-Fehler aufgetreten sind und wie viele Antworten der
iSCSI-Client erhalten hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Client zum Zeitpunkt des
Eingangs der Fehler war.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn er als iSCSI-Initiator fungiert Fehler Wenn das Gerät als iSCSI fungiert Initiator, die Summe der abgelehnten PDUs und der erfolglosen Anmeldeantworten erhalten. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der iSCSI-Sitzungen, die der Client initiiert hat, die
Anzahl der Antworten, die der Client erhalten hat, und wie viele dieser Antworten
Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn er als iSCSI-Initiator fungiert Fehler Wenn das Gerät als iSCSI fungiert Initiator, die Summe der abgelehnten PDUs und der erfolglosen Anmeldeantworten erhalten. Sessions Die Anzahl der iSCSI-Sitzungen, die das Gerät hat begann, als ich als iSCSI-Initiator fungierte - Operationen
- Dieses Diagramm zeigt, wann der iSCSI-Client Lese-, Schreib-, Header-Digest- und
Datendigest-Operationen ausgeführt hat.
Metrisch Beschreibung Liest (ausgehende Daten) Die Anzahl der Lesevorgänge, die der Gerät, das gesendet wird, wenn es als iSCSI-Initiator fungiert Schreibt (Daten eingehend) Die Anzahl der Schreiboperationsanfragen, die das Gerät, das gesendet wurde, wenn es als iSCSI-Initiator fungiert Header-Zusammenfassung Die Anzahl der Operationen, die beinhalteten optionale Header-Digests, wenn das Gerät als iSCSI fungiert Initiator. Datenübersicht Die Anzahl der Operationen, die beinhalteten optionale Datendigests, wenn das Gerät als iSCSI-Initiator fungiert - Operationen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele Lese- und Schreibvorgänge der iSCSI-Client
ausgeführt hat.
Metrisch Beschreibung Liest (ausgehende Daten) Die Anzahl der Lesevorgänge, die der Gerät, das gesendet wird, wenn es als iSCSI-Initiator fungiert Schreibt (Daten eingehend) Die Anzahl der Schreiboperationsanfragen, die das Gerät, das gesendet wurde, wenn es als iSCSI-Initiator fungiert Header-Zusammenfassung Die Anzahl der Operationen, die beinhalteten optionale Header-Digests, wenn das Gerät als iSCSI fungiert Initiator. Datenübersicht Die Anzahl der Operationen, die beinhalteten optionale Datendigests, wenn das Gerät als iSCSI-Initiator fungiert
iSCSI-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Opcodes
- Dieses Diagramm zeigt, welche iSCSI-Opcodes der Client am häufigsten erhalten hat, indem die Anzahl der an den Client zurückgegebenen Antworten nach Opcode aufgeschlüsselt wird.
- Die häufigsten Anmeldefehler
- Dieses Diagramm zeigt, welche iSCSI-Anmeldefehler der Client am häufigsten erhalten hat, indem die Anzahl der Antworten, die aufgrund von Anmeldefehlern an den Client zurückgegeben wurden, aufgeschlüsselt wird.
- Die häufigsten Ablehnungsgründe
- Dieses Diagramm zeigt, welche Ablehnungsgründe der Client am häufigsten erhalten hat, indem die Anzahl der an den Client zurückgegebenen Antworten nach Gründen aufgeschlüsselt wird.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Gesamtwerte der iSCSI-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Antworten und Operationen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der Antworten, die der Kunde erhalten hat, und die
Gesamtzahl der vom Client ausgeführten Operationen.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn er als iSCSI-Initiator fungiert Sessions Die Anzahl der iSCSI-Sitzungen, die das Gerät hat begann, als ich als iSCSI-Initiator fungierte Fehler Wenn das Gerät als iSCSI fungiert Initiator, die Summe der abgelehnten PDUs und der erfolglosen Anmeldeantworten erhalten. Liest (ausgehende Daten) Die Anzahl der Lesevorgänge, die der Gerät, das gesendet wird, wenn es als iSCSI-Initiator fungiert Schreibt (Daten eingehend) Die Anzahl der Schreiboperationsanfragen, die das Gerät, das gesendet wurde, wenn es als iSCSI-Initiator fungiert Header-Zusammenfassung Die Anzahl der Operationen, die beinhalteten optionale Header-Digests, wenn das Gerät als iSCSI fungiert Initiator. Datenübersicht Die Anzahl der Operationen, die beinhalteten optionale Datendigests, wenn das Gerät als iSCSI-Initiator fungiert PDUs ablehnen Die Anzahl der Reject-PDUs, die das Gerät hat empfangen, wenn er als iSCSI-Initiator agiert - Goodput-Bytes insgesamt
- In diesem Diagramm wird die Gesamtzahl der vom
Client gelesenen und geschriebenen Goodput-Bytes angezeigt.
Metrisch Beschreibung Gelesene Goodput-Bytes Die Anzahl der Goodput-Bytes, die zum Lesen gesendet wurden Operationen, wenn das Gerät als iSCSI-Ziel fungiert. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Geschriebene Goodput-Bytes Die Anzahl der Goodput-Bytes des Gerät wurde für Schreibvorgänge empfangen, wenn es als iSCSI-Ziel fungiert. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus.
iSCSI-Serverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt iSCSI Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
iSCSI-Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann iSCSI-Fehler aufgetreten sind und wie viele iSCSI-Antworten der
Server gesendet hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Server zu dem Zeitpunkt war, als er die Fehler
zurückgab.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn es als iSCSI-Ziel fungiert Fehler Wenn das Gerät als iSCSI fungiert Ziel, die kombinierte Summe der abgelehnten PDUs und der erfolglosen Anmeldeantworten gesendet. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der iSCSI-Sitzungen, die der Server gestartet hat, die Anzahl
der Antworten, die der Server gesendet hat, und wie viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn es als iSCSI-Ziel fungiert Fehler Wenn das Gerät als iSCSI fungiert Ziel, die kombinierte Summe der abgelehnten PDUs und der erfolglosen Anmeldeantworten gesendet. Sessions Die Anzahl der iSCSI-Sitzungen, die das Gerät begann, als ich als iSCSI-Ziel fungierte - Operationen
- Dieses Diagramm zeigt, wann Lese-, Schreib-, Header-Digest- und Datendigest-Operationen auf dem iSCSI-Server
ausgeführt wurden.
Metrisch Beschreibung Liest (ausgehende Daten) Die Anzahl der Lesevorgänge, die der Gerät, das gesendet wird, wenn es als iSCSI-Initiator fungiert Schreibt (Daten eingehend) Die Anzahl der Schreiboperationsanfragen, die das Gerät, das gesendet wurde, wenn es als iSCSI-Initiator fungiert Header-Zusammenfassung Die Anzahl der Operationen, die beinhalteten optionale Header-Digests, wenn das Gerät als iSCSI fungiert Initiator. Datenübersicht Die Anzahl der Operationen, die beinhalteten optionale Datendigests, wenn das Gerät als iSCSI-Initiator fungiert - Operationen insgesamt
- Dieses Diagramm zeigt, wie viele Lese- und Schreibvorgänge auf dem
iSCSI-Server ausgeführt wurden.
Metrisch Beschreibung Liest (ausgehende Daten) Die Anzahl der Lesevorgänge, die der Gerät, das gesendet wird, wenn es als iSCSI-Initiator fungiert Schreibt (Daten eingehend) Die Anzahl der Schreiboperationsanfragen, die das Gerät, das gesendet wurde, wenn es als iSCSI-Initiator fungiert Header-Zusammenfassung Die Anzahl der Operationen, die beinhalteten optionale Header-Digests, wenn das Gerät als iSCSI fungiert Initiator. Datenübersicht Die Anzahl der Operationen, die beinhalteten optionale Datendigests, wenn das Gerät als iSCSI-Initiator fungiert
iSCSI-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Opcodes
- Dieses Diagramm zeigt, welche iSCSI-Opcodes der Server am häufigsten zurückgegeben hat, indem die Gesamtzahl der Antworten, die der Server per Opcode gesendet hat, aufgeschlüsselt wird.
- Die häufigsten Anmeldefehler
- Dieses Diagramm zeigt, welche iSCSI-Anmeldefehler der Server am häufigsten zurückgegeben hat, indem die Gesamtzahl der Antworten, die der Server aufgrund eines Anmeldefehlers gesendet hat, aufgeschlüsselt wird.
- Die häufigsten Ablehnungsgründe
- Dieses Diagramm zeigt, welche iSCSI-Ablehnungsgründe der Server am häufigsten zurückgegeben hat, indem die Gesamtzahl der vom Server gesendeten Antworten nach Gründen aufgeschlüsselt wird.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Gesamtwerte der iSCSI-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Antworten und Operationen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der Antworten, die der Server gesendet hat, und die Gesamtzahl
der Operationen, die auf dem Server ausgeführt wurden.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn es als iSCSI-Ziel fungiert Sessions Die Anzahl der iSCSI-Sitzungen, die das Gerät begann, als ich als iSCSI-Ziel fungierte Fehler Wenn das Gerät als iSCSI fungiert Ziel, die kombinierte Summe der abgelehnten PDUs und der erfolglosen Anmeldeantworten gesendet. Liest (ausgehende Daten) Die Anzahl der Lesevorgänge, die der Gerät, das empfangen wurde, wenn es als iSCSI-Ziel fungiert Schreibt (Daten eingehend) Die Anzahl der Schreiboperationsanfragen, die das Gerät wurde empfangen, wenn es als iSCSI-Ziel fungiert Header-Zusammenfassung Die Anzahl der Operationen, die beinhalteten optionale Header-Digests, wenn das Gerät als iSCSI-Ziel fungiert Datenübersicht Die Anzahl der Operationen, die beinhalteten optionale Datendigests, wenn das Gerät als iSCSI-Ziel fungiert PDUs ablehnen Die Anzahl der Reject-PDUs, die das Gerät hat gesendet, wenn es als iSCSI-Ziel fungiert - Goodput-Bytes insgesamt
- In diesem Diagramm wird die Gesamtzahl der vom
Server gelesenen und geschriebenen Goodput-Bytes angezeigt.
Metrisch Beschreibung Gelesene Goodput-Bytes Die Anzahl der Goodput-Bytes, die empfangen wurden für Lesevorgänge, wenn das Gerät als iSCSI-Initiator fungiert. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Geschriebene Goodput-Bytes Die Anzahl der Goodput-Bytes, für die gesendet wurde Schreibvorgänge, wenn das Gerät als iSCSI-Initiator fungiert. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus.
iSCSI-Client-Gruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt iSCSI Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
iSCSI Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann iSCSI-Fehler aufgetreten sind und wie viele Antworten die
iSCSI-Clients erhalten haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Kunden zu dem
Zeitpunkt waren, als sie die Fehler erhielten.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn er als iSCSI-Initiator fungiert Fehler Wenn das Gerät als iSCSI fungiert Initiator, die Summe der abgelehnten PDUs und der erfolglosen Anmeldeantworten erhalten. - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele iSCSI-Antworten die Clients erhalten haben und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn er als iSCSI-Initiator fungiert Fehler Wenn das Gerät als iSCSI fungiert Initiator, die Summe der abgelehnten PDUs und der erfolglosen Anmeldeantworten erhalten.
iSCSI-Details für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (iSCSI-Clients)
- Dieses Diagramm zeigt, welche iSCSI-Clients in der Gruppe am aktivsten waren, indem es die Gesamtzahl der iSCSI-Anfragen aufschlüsselt, die die Gruppe vom Client gesendet hat.
- Die besten Opcodes
- Dieses Diagramm zeigt, welche iSCSI-Opcodes die Gruppe am meisten erhalten hat, indem die Anzahl der an die Gruppe zurückgegebenen Antworten nach Opcode aufgeschlüsselt wird.
- Die häufigsten Anmeldefehler
- Dieses Diagramm zeigt, welche iSCSI-Anmeldefehler die Gruppe am häufigsten erhalten hat, indem die Anzahl der Antworten, die nach Anmeldefehlern an die Gruppe zurückgegeben wurden, aufgeschlüsselt wird.
iSCSI-Metriken für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Antworten und Operationen insgesamt
-
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn er als iSCSI-Initiator fungiert Sessions Die Anzahl der iSCSI-Sitzungen, die das Gerät hat begann, als ich als iSCSI-Initiator fungierte Fehler Wenn das Gerät als iSCSI fungiert Initiator, die Summe der abgelehnten PDUs und der erfolglosen Anmeldeantworten erhalten. Liest (ausgehende Daten) Die Anzahl der Lesevorgänge, die der Gerät, das gesendet wird, wenn es als iSCSI-Initiator fungiert Schreibt (Daten eingehend) Die Anzahl der Schreiboperationsanfragen, die das Gerät, das gesendet wurde, wenn es als iSCSI-Initiator fungiert Header-Zusammenfassung Die Anzahl der Operationen, die beinhalteten optionale Header-Digests, wenn das Gerät als iSCSI fungiert Initiator. Datenübersicht Die Anzahl der Operationen, die beinhalteten optionale Datendigests, wenn das Gerät als iSCSI-Initiator fungiert PDUs ablehnen Die Anzahl der Reject-PDUs, die das Gerät hat empfangen, wenn er als iSCSI-Initiator agiert
iSCSI-Servergruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt iSCSI Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
iSCSI Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann iSCSI-Fehler aufgetreten sind und wie viele iSCSI-Antworten die
Server gesendet haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Server zu dem Zeitpunkt waren, als
sie die Fehler gemeldet haben.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn es als iSCSI-Ziel fungiert Fehler Wenn das Gerät als iSCSI fungiert Ziel, die kombinierte Summe der abgelehnten PDUs und der erfolglosen Anmeldeantworten gesendet. - Transaktionen insgesamt
- Dieses Diagramm zeigt, wie viele iSCSI-Antworten Server in der Gruppe gesendet haben und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn es als iSCSI-Ziel fungiert Fehler Wenn das Gerät als iSCSI fungiert Ziel, die kombinierte Summe der abgelehnten PDUs und der erfolglosen Anmeldeantworten gesendet.
iSCSI-Details für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (iSCSI-Server)
- Dieses Diagramm zeigt, welche iSCSI-Server in der Gruppe am aktivsten waren, indem die Gesamtzahl der von der Gruppe gesendeten iSCSI-Antworten vom Server aufgeschlüsselt wird.
- Die besten Opcodes
- Dieses Diagramm zeigt, welche iSCSI-Opcodes die Gruppen am häufigsten zurückgegeben haben, indem die Gesamtzahl der Antworten, die die Gruppe per Opcode gesendet hat, aufgeschlüsselt wird.
- Die häufigsten Anmeldefehler
- Dieses Diagramm zeigt, welche iSCSI-Anmeldefehler die Gruppen am häufigsten zurückgegeben haben, indem die Gesamtzahl der Antworten, die die Gruppe aufgrund eines Anmeldefehlers gesendet hat, aufgeschlüsselt wird.
iSCSI-Metriken für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Antworten und Operationen insgesamt
-
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn es als iSCSI-Ziel fungiert Sessions Die Anzahl der iSCSI-Sitzungen, die das Gerät begann, als ich als iSCSI-Ziel fungierte Fehler Wenn das Gerät als iSCSI fungiert Ziel, die kombinierte Summe der abgelehnten PDUs und der erfolglosen Anmeldeantworten gesendet. Liest (ausgehende Daten) Die Anzahl der Lesevorgänge, die der Gerät, das empfangen wurde, wenn es als iSCSI-Ziel fungiert Schreibt (Daten eingehend) Die Anzahl der Schreiboperationsanfragen, die das Gerät wurde empfangen, wenn es als iSCSI-Ziel fungiert Header-Zusammenfassung Die Anzahl der Operationen, die beinhalteten optionale Header-Digests, wenn das Gerät als iSCSI-Ziel fungiert Datenübersicht Die Anzahl der Operationen, die beinhalteten optionale Datendigests, wenn das Gerät als iSCSI-Ziel fungiert PDUs ablehnen Die Anzahl der Reject-PDUs, die das Gerät hat gesendet, wenn es als iSCSI-Ziel fungiert
Kerberos
Das ExtraHop-System sammelt Messwerte zur Kerberos-Aktivität. Kerberos ist ein Sicherheitsprotokoll, das bei der Client- und Serverauthentifizierung gegenseitige Kryptografie mit geheimen Schlüsseln anwendet, sodass sowohl der Benutzer als auch der Server ihre Identität nachweisen müssen.
Überlegungen zur Sicherheit
- Kerberos Ticket Granting Tickets (TGTs), die mit einem gestohlenen KRBTGT-Hash gefälscht wurden, sind bekannt als goldene Tickets. Ein Golden Ticket ermöglicht es einem Angreifer, sich als Domain-Administrator auszugeben und Zugriff auf alle Dienste in einer Domain zu erhalten.
- Kerberos Ticket Granting Service (TGS) -Tickets, die mit gestohlenen Serviceschlüsseln gefälscht wurden, werden als Silbertickets bezeichnet. Ein Silver-Ticket ermöglicht es einem Angreifer, sich als Domain-Administrator auszugeben und Zugriff auf einen bestimmten Dienst zu erhalten.
- Kerberos-TGS-Tickets können bei einem Kerberoasting-Angriff gestohlen werden, bei dem ein Angreifer versucht, die verschlüsselten TGS-Tickets offline zu knacken, um die Passwörter von Dienstkonten zu stehlen.
- Kerberos-AS-REP-Antworten können bei einem AS-REP-Roasting-Angriff gestohlen werden, bei dem ein Angreifer versucht, das verschlüsselte Benutzerkontokennwort aus der AS-REP-Antwort offline zu knacken.
- Die Kerberos-Authentifizierung kann anfällig sein für Brute-Force, bei der es sich um eine Methode zum Erraten von Anmeldedaten handelt, indem zahlreiche Authentifizierungsanfragen mit unterschiedlichen Kombinationen aus Benutzername und Passwort eingereicht werden.
- Angriffstools wie Impaket, kann Kerberos-Angriffe ermöglichen.
- Verschlüsselter Kerberos-Verkehr ist ein zunehmend verbreiteter Vektor für bösartige Aktivitäten. Sie können das ExtraHop-System so konfigurieren Domain-Traffic entschlüsseln um verdächtiges Verhalten und potenzielle Angriffe zu identifizieren.
Kerberos-Anwendungsseite
Auf dieser Seite werden Metrikdiagramme von angezeigt Kerberos Verkehr, der mit einem Anwendungscontainer in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur Kerberos-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
Kerberos Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann Kerberos-Fehler und -Antworten mit der
Anwendung verknüpft waren. Anhand dieser Informationen können Sie feststellen, wie aktiv die Anwendung zum
Zeitpunkt des Auftretens der Fehler war.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die gesendet wurden von Kerberos-Server Fehler Die Anzahl der Kerberos-Antworten Fehler. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der Kerberos-Antworten, die mit
der Anwendung verknüpft waren, und wie viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die gesendet wurden von Kerberos-Server Fehler Die Anzahl der Kerberos-Antworten Fehler. - Leistung (95. Perzentil)
-
Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken.
Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer vollständigen
Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange Clients gebraucht haben, um Anfragen an
das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange die Server für die Bearbeitung von Anfragen gebraucht haben;
und die Antwortübertragungszeit zeigt, wie lange die Server gebraucht haben, um Antworten an
das Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Transferzeit anfragen Die Zeit zwischen wann das ExtraHop-System hat das erste Paket und das letzte Paket einer Kerberos-Anfrage erkannt. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit des Servers Die Zeit, die ein Kerberos-Server benötigt sende das erste Paket einer Antwort, nachdem du das letzte Paket einer Anfrage. Übertragungszeit der Antwort Die Zeit zwischen wann das ExtraHop-System hat das erste Paket und das letzte Paket einer Kerberos-Antwort erkannt. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Dauer, die für den Kerberos benötigt wurde Server oder Client, um eine Bestätigung zu erhalten, nachdem das letzte Paket über die gesendet wurde TCP-Verbindung. Eine lange Roundtrip-Zeit (RTT) weist auf eine Netzwerklatenz Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn eine Anwendung langsam reagiert, können Sie anhand
von Leistungsübersichtsmetriken herausfinden, ob das Netzwerk oder die Server das
Problem verursachen. Diese Metriken zeigen das 95. Perzentil der Zeit, die Server für die Bearbeitung von
Anfragen von Clients benötigten, im Vergleich zum 95. Perzentil der Zeit, die Pakete aus diesen Anfragen
(und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten. Hohe
Serververarbeitungszeiten deuten darauf hin, dass Clients langsame Server kontaktieren. Hohe
TCP-Roundtrip-Zeiten deuten darauf hin, dass Clients über langsame Netzwerke kommunizieren.
Metrisch Beschreibung Verarbeitungszeit des Servers Die Zeit, die ein Kerberos-Server benötigt sende das erste Paket einer Antwort, nachdem du das letzte Paket einer Anfrage. Zeit für Hin- und Rückfahrt Die Dauer, die für den Kerberos benötigt wurde Server oder Client, um eine Bestätigung zu erhalten, nachdem das letzte Paket über die gesendet wurde TCP-Verbindung. Eine lange Roundtrip-Zeit (RTT) weist auf eine Netzwerklatenz
Kerberos-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die häufigsten Arten von Anforderungsnachrichten
- Dieses Diagramm zeigt, welche Kerberos-Nachrichtentypen die Anwendung am häufigsten gesendet hat, indem die Gesamtzahl der von der Anwendung gesendeten Anfragen nach Nachrichtentyp aufgeschlüsselt wird.
- Die häufigsten Arten von Antwortnachrichten
- Dieses Diagramm zeigt, welche Kerberos-Nachrichtentypen der Client am häufigsten erhalten hat, indem die Gesamtzahl der Antworten, die der Client erhalten hat, nach Nachrichtentyp aufgeschlüsselt wird.
- Die häufigsten Fehlertypen
- Dieses Diagramm zeigt, welche Kerberos-Fehlertypen der Client am häufigsten erhalten hat, indem die Anzahl der an den Client zurückgegebenen Antworten nach Fehlertyp aufgeschlüsselt wird.
Kerberos-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des Kerberos-Servers Die Zeit, die ein Kerberos-Server benötigt sende das erste Paket einer Antwort, nachdem du das letzte Paket einer Anfrage. - Verarbeitungszeit des Servers
-
Diese Tabelle zeigt die durchschnittliche Bearbeitungszeit für den Anwendung.
Metrisch Beschreibung Verarbeitungszeit des Kerberos-Servers Die Zeit, die ein Kerberos-Server benötigt sende das erste Paket einer Antwort, nachdem du das letzte Paket einer Anfrage. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Dauer, die für den Kerberos benötigt wurde Server oder Client, um eine Bestätigung zu erhalten, nachdem das letzte Paket über die gesendet wurde TCP-Verbindung. Eine lange Roundtrip-Zeit (RTT) weist auf eine Netzwerklatenz - Zeit für Hin- und Rückfahrt
-
Diese Tabelle zeigt
die durchschnittliche Hin- und Rückflugzeit für die Anwendung.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Dauer, die für den Kerberos benötigt wurde Server oder Client, um eine Bestätigung zu erhalten, nachdem das letzte Paket über die gesendet wurde TCP-Verbindung. Eine lange Roundtrip-Zeit (RTT) weist auf eine Netzwerklatenz
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass ein Problem mit einem Server oder einem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
-
Dieses Diagramm zeigt die Anzahl der Nullfenster, die einer Anwendung
zugeordnet waren. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der Pakete
angeben, die über einen bestimmten Zeitraum an sie gesendet werden können.
Wenn an ein Gerät mehr Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein
Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig einzustellen, bis das Gerät den Vorgang
aufholt. Wenn Sie eine große Anzahl von Nullfenstern sehen, ist ein Server oder Client möglicherweise
nicht schnell genug, um die empfangene Datenmenge zu unterstützen.
Metrisch Definition Zero Windows anfordern Die Anzahl der Zero Window Window-Anzeigen die von Kerberos-Clients gesendet wurden. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl eingehender Zero-Windows weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Antwort Null Windows Die Anzahl der Zero Window Window-Anzeigen die von Servern beim Empfang von Kerberos-Anfragen gesendet wurden. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von ausgehenden Zero-Windows weist darauf hin, dass ein Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Gesamtzahl der Host-Stände
- Dieses Diagramm zeigt die durchschnittliche Anzahl von Zero-Window-Werbeanzeigen, die von Geräten gesendet wurden.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen
Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu
viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät
eine Anfrage oder Antwort sendet und innerhalb einer bestimmten
Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen
nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise
zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Timeouts für die erneute Übertragung, die wurden durch eine Überlastung verursacht, als Clients Kerberos-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der Timeouts für die erneute Übertragung, die wurden durch eine Überlastung verursacht, als Server Kerberos-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
- Gesamtzahl der Netzwerkausfälle
-
Dieses Diagramm zeigt die durchschnittliche Anzahl von Timeouts bei der
erneuten Übertragung, die durch Überlastung beim Senden von Anfragen durch Clients und Server verursacht wurden.
Metrisch Definition RTOs Ein Die Anzahl der Timeouts für die erneute Übertragung, die wurden durch eine Überlastung verursacht, als Clients Kerberos-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der Timeouts für die erneute Übertragung, die wurden durch eine Überlastung verursacht, als Server Kerberos-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Metrische Kerberos-Summen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr Anfragen, als Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um herauszufinden, ob das Problem mit dem Netzwerk oder einem Server zusammenhängt, überprüfen Sie RTOs und Zero Windows in der Netzwerk-Daten Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Kerberos-Anfragen und -Antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die gesendet wurden von Kerberos-Clients Antworten Die Anzahl der Antworten, die gesendet wurden von Kerberos-Server Fehler Die Anzahl der Kerberos-Antworten Fehler. - Kerberos-Netzwerkmetriken
-
Metrisch Beschreibung Zero Windows anfordern Die Anzahl der Zero Window Window-Anzeigen die von Kerberos-Clients gesendet wurden. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Antwort Null Windows Die Anzahl der Zero Window Window-Anzeigen die von Servern beim Empfang von Kerberos-Anfragen gesendet wurden. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. RTOs anfragen Die Anzahl der Timeouts für die erneute Übertragung, die wurden durch eine Überlastung verursacht, als Clients Kerberos-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Antwort-RTOs Die Anzahl der Timeouts für die erneute Übertragung, die wurden durch eine Überlastung verursacht, als Server Kerberos-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. L2-Byte anfordern Die Anzahl der gesendeten L2-Bytes von Kerberos-Clients, die mit Kerberos-Anfragen verknüpft waren Antwort L2 Byte Die Anzahl der L2-Bytes, die waren verknüpft mit Kerberos-Antworten Goodput Bytes anfordern Die Anzahl der zugehörigen Goodput-Bytes mit Kerberos-Anfragen. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Antwort Goodput Bytes Die Anzahl der zugehörigen Goodput-Bytes mit Kerberos-Antworten. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Pakete anfordern Die Anzahl der Pakete, die gesendet wurden von Kerberos-Clients, die mit Kerberos-Anfragen verknüpft waren Antwortpakete Die Anzahl der Pakete, die mit verknüpft sind Antworten, die von Kerberos-Servern gesendet wurden
Kerberos-Clientseite
Auf dieser Seite werden Metrikdiagramme von angezeigt Kerberos Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur Kerberos-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
Kerberos Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann Kerberos-Fehler aufgetreten sind und wie viele Antworten der
Kerberos-Client erhalten hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Client zum Zeitpunkt des
Eingangs der Fehler war.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie sich Details zu jedem Fehler anzeigen lassen, einschließlich des Fehlercodes. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von Anfragen zu Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Hinweis: Um eine Aufschlüsselung nach dem Fehlercode durchzuführen, klicken Sie auf Fehler und wähle Fehler aus der Speisekarte. Metrisch Beschreibung Antworten Die Anzahl der Antworten, die eingegangen sind von dieser Kerberos-Client Fehler Die Anzahl der Antwortfehler, die waren von diesem Kerberos-Client empfangen - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der Kerberos-Antworten, die der Client erhalten hat, und wie
viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die eingegangen sind von dieser Kerberos-Client Fehler Die Anzahl der Antwortfehler, die waren von diesem Kerberos-Client empfangen - Leistungsübersicht (95. Perzentil)
-
Dieses Diagramm zeigt das
95. Perzentil der Timing-Metriken. Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer
vollständigen Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange der Client gebraucht hat, um
Anfragen an das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange Server gebraucht haben, um
die Anfragen zu verarbeiten; und die Antwortübertragungszeit zeigt, wie lange Server gebraucht haben, um
Antworten an das Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Übertragungszeit der Kerberos-Anfrage Die Zeit zwischen wann der ExtraHop System hat das erste Paket und das letzte Paket einer Anfrage erkannt, die gesendet wurde von dieser Kerberos-Client. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit des Kerberos-Client-Servers Die für diesen Kerberos-Client benötigte Zeit um das erste Paket einer Antwort nach dem Senden des letzten Paket einer Anfrage. Übertragungszeit der Kerberos-Serverantwort Die Zeit zwischen wann der ExtraHop Das System hat das erste Paket und das letzte Paket einer Antwort erkannt, die gesendet wurde an dieser Kerberos-Client. Hohe Werte können auf eine große Antwort oder ein großes Netzwerk hinweisen verzögern. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Kerberos-Clients ein Paket, das eine sofortige Bestätigung erforderte und wann die Bestätigung erfolgte erhalten. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn ein Client langsam reagiert, können Sie
anhand von Leistungsübersichtsmetriken herausfinden, ob das Netzwerk oder die Server das Problem verursachen.
Diese Metriken zeigen das 95. Perzentil der Zeit, die Server für die Bearbeitung von
Anfragen vom Client benötigten, im Vergleich zur 95. Perzentilzeit, die Pakete aus diesen
Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten.
Hohe Serververarbeitungszeiten deuten darauf hin, dass der Client langsame Server kontaktiert. Hohe
TCP-Roundtrip-Zeiten deuten darauf hin, dass der Client über langsame
Netzwerke kommuniziert.
Metrisch Beschreibung Verarbeitungszeit des Kerberos-Client-Servers Die für diesen Kerberos-Client benötigte Zeit um das erste Paket einer Antwort nach dem Senden des letzten Paket einer Anfrage. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Kerberos-Clients ein Paket, das eine sofortige Bestätigung erforderte und wann die Bestätigung erfolgte erhalten. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz
Kerberos-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Hauptnamen der wichtigsten Kunden
- Dieses Diagramm zeigt, welche Kerberos-Benutzer auf diesem Client am aktivsten waren, indem die Gesamtzahl der an den Client zurückgegebenen Kerberos-Antworten nach dem Clientprinzipalnamen aufgeschlüsselt wird.
- Die häufigsten Arten von Anforderungsnachrichten
- Dieses Diagramm zeigt, welche Kerberos-Nachrichtentypen der Client am häufigsten gesendet hat, indem die Gesamtzahl der vom Client gesendeten Anfragen nach Nachrichtentyp aufgeschlüsselt wird.
- Die häufigsten Fehlertypen
- Dieses Diagramm zeigt, welche Kerberos-Fehlertypen der Client am häufigsten erhalten hat, indem die Anzahl der an den Client zurückgegebenen Antworten nach Fehlertyp aufgeschlüsselt wird.
- Die häufigsten Serverprinzipalnamen
- Dieses Diagramm zeigt, welche Kerberos-Dienste von diesem Client am häufigsten angefordert wurden, indem die Gesamtzahl der an den Client zurückgegebenen Kerberos-Antworten nach Serverprinzipalname aufgeschlüsselt wird.
- Die häufigsten Arten von Antwortnachrichten
- Dieses Diagramm zeigt, welche Kerberos-Nachrichtentypen der Client am häufigsten erhalten hat, indem die Gesamtzahl der Antworten, die der Client erhalten hat, nach Nachrichtentyp aufgeschlüsselt wird.
Kerberos-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des Kerberos-Client-Servers Die für diesen Kerberos-Client benötigte Zeit um das erste Paket einer Antwort nach dem Senden des letzten Paket einer Anfrage. - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Bearbeitungszeit für den Client.
Metrisch Beschreibung Verarbeitungszeit des Kerberos-Client-Servers Die für diesen Kerberos-Client benötigte Zeit um das erste Paket einer Antwort nach dem Senden des letzten Paket einer Anfrage. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Kerberos-Clients ein Paket, das eine sofortige Bestätigung erforderte und wann die Bestätigung erfolgte erhalten. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Hin- und Rückflugzeit für den Client.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Kerberos-Clients ein Paket, das eine sofortige Bestätigung erforderte und wann die Bestätigung erfolgte erhalten. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Metrische Kerberos-Summen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, sendet der Client möglicherweise mehr
Anfragen, als die Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen
, ob das Problem beim Netzwerk oder beim Server liegt, überprüfen Sie RTOs und Zero Windows in der
Netzwerk-Daten
Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Kerberos-Anfragen und -Antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die von diesem gesendet wurden Kerberos-Client Antworten Die Anzahl der Antworten, die eingegangen sind von dieser Kerberos-Client Fehler Die Anzahl der Antwortfehler, die waren von diesem Kerberos-Client empfangen
Kerberos-Serverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt Kerberos Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur Kerberos-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
Kerberos Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann Kerberos-Fehler aufgetreten sind und wie viele Kerberos-Antworten der Server gesendet hat.
Anhand dieser Informationen können Sie feststellen, wie aktiv der Server zu dem Zeitpunkt war, als er die Fehler
zurückgab.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie sich Details zu jedem Fehler anzeigen lassen, einschließlich des Fehlercodes. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von Anfragen zu Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Hinweis: Um eine Aufschlüsselung nach dem Fehlercode durchzuführen, klicken Sie auf Fehler und wähle Fehler aus der Speisekarte. Metrisch Beschreibung Antworten Die Anzahl der Antworten, die gesendet wurden von dieser Kerberos-Server Fehler Die Anzahl der Antwortfehler, die waren gesendet von diesem Kerberos-Server - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der Kerberos-Antworten, die der Server gesendet hat, und wie
viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die gesendet wurden von dieser Kerberos-Server Fehler Die Anzahl der Antwortfehler, die waren gesendet von diesem Kerberos-Server - Leistung (95. Perzentil)
- Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken. Die Metriken für Transfer und
Bearbeitungszeit zeigen Teile einer vollständigen Transaktion. Die Anforderungsübertragungszeit gibt an, wie
lange Clients gebraucht haben, um Anfragen an das Netzwerk zu übertragen; die Serververarbeitungszeit
zeigt, wie lange der Server gebraucht hat, um die Anfragen zu verarbeiten; und die Antwortübertragungszeit
zeigt, wie lange der Server gebraucht hat, um Antworten an das Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Übertragungszeit der Kerberos-Anfrage Die Zeit zwischen wann der ExtraHop System hat das erste Paket und das letzte Paket einer Anfrage erkannt, die gesendet wurde von dieser Kerberos-Client. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit des Kerberos-Servers Die Zeit, die zum Senden des ersten Paket benötigt wurde einer Antwort nach Erhalt des letzten Paket einer Anfrage, die von diesem empfangen wurde Kerberos-Server Übertragungszeit der Kerberos-Serverantwort Die Zeit zwischen wann der ExtraHop System hat das erste Paket und das letzte Paket einer Antwort erkannt, die gesendet wurde von dieser Kerberos-Server. Ein hoher Wert kann auf eine große Antwort oder ein großes Netzwerk hinweisen verzögern. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Kerberos-Servers ein Paket, das eine sofortige Bestätigung erforderte und wann die Bestätigung erfolgte erhalten. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Leistungsübersicht (95. Perzentil)
- Dieses Diagramm zeigt die Gesamtzahl der Kerberos-Antworten, die der Client erhalten hat, und wie
viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Verarbeitungszeit des Kerberos-Servers Die Zeit, die zum Senden des ersten Paket benötigt wurde einer Antwort nach Erhalt des letzten Paket einer Anfrage, die von diesem empfangen wurde Kerberos-Server Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Kerberos-Servers ein Paket, das eine sofortige Bestätigung erforderte und wann die Bestätigung erfolgte erhalten. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz
Kerberos-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Hauptnamen der wichtigsten Kunden
- Dieses Diagramm zeigt, welche Kerberos-Benutzer auf diesem Server am aktivsten waren, indem die Gesamtzahl der Kerberos-Antworten, die der Server nach dem Client-Prinzipalnamen gesendet hat, aufgeschlüsselt wird.
- Die häufigsten Arten von Anforderungsnachrichten
- Dieses Diagramm zeigt, welche Kerberos-Nachrichtentypen der Server am häufigsten erhalten hat, indem die Gesamtzahl der Anfragen, die der Server erhalten hat, nach Nachrichtentyp aufgeschlüsselt wird.
- Die häufigsten Arten von Antwortnachrichten
- Dieses Diagramm zeigt, welche Kerberos-Nachrichtentypen der Server am häufigsten gesendet hat, indem die Gesamtzahl der vom Server gesendeten Antworten nach Nachrichtentyp aufgeschlüsselt wird.
- Die häufigsten Serverprinzipalnamen
- Dieses Diagramm zeigt, welche Kerberos-Dienste auf diesem Server am häufigsten angefordert wurden, indem die Gesamtzahl der vom Server gesendeten Kerberos-Antworten anhand des Serverprinzipalnamens aufgeschlüsselt wird.
- Die häufigsten Fehlertypen
- Dieses Diagramm zeigt, welche Kerberos-Fehlertypen der Server am häufigsten zurückgegeben hat, indem die Gesamtzahl der vom Server gesendeten Antworten nach Fehlertyp aufgeschlüsselt wird.
Kerberos-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des Kerberos-Servers Die Zeit, die zum Senden des ersten Paket benötigt wurde einer Antwort nach Erhalt des letzten Paket einer Anfrage, die von diesem empfangen wurde Kerberos-Server - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Verarbeitungszeit für den Server.
Metrisch Beschreibung Verarbeitungszeit des Kerberos-Servers Die Zeit, die zum Senden des ersten Paket benötigt wurde einer Antwort nach Erhalt des letzten Paket einer Anfrage, die von diesem empfangen wurde Kerberos-Server - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Kerberos-Servers ein Paket, das eine sofortige Bestätigung erforderte und wann die Bestätigung erfolgte erhalten. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Hin- und Rückflugzeit für den Client.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Kerberos-Servers ein Paket, das eine sofortige Bestätigung erforderte und wann die Bestätigung erfolgte erhalten. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Metrische Kerberos-Summen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr
Anfragen, als der Server verarbeiten kann, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen
, ob das Problem beim Netzwerk oder beim Server liegt, überprüfen Sie RTOs und Zero Windows in der
Netzwerk-Daten
Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Kerberos-Anfragen und -Antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die eingegangen sind von dieser Kerberos-Server Antworten Die Anzahl der Antworten, die gesendet wurden von dieser Kerberos-Server Fehler Die Anzahl der Antwortfehler, die waren gesendet von diesem Kerberos-Server
Kerberos-Clientgruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt Kerberos Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur Kerberos-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
Kerberos Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann Kerberos-Fehler aufgetreten sind und wie viele Antworten die
Kerberos-Clients erhalten haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Kunden zu dem
Zeitpunkt waren, als sie die Fehler erhielten.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie sich Details zu jedem Fehler anzeigen lassen, einschließlich des Fehlercodes. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von Kerberos-Anfragen zu Kerberos-Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie im Diagramm Kerberos-Metriken für Gruppen.
Hinweis: Um eine Aufschlüsselung nach dem Fehlercode durchzuführen, klicken Sie auf Fehler und wähle Fehler aus der Speisekarte. Metrisch Beschreibung Antworten Die Anzahl der Antworten, die eingegangen sind von dieser Kerberos-Client Fehler Die Anzahl der Antwortfehler, die waren von diesem Kerberos-Client empfangen - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele Kerberos-Antworten die Clients erhalten haben und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die eingegangen sind von dieser Kerberos-Client Fehler Die Anzahl der Antwortfehler, die waren von diesem Kerberos-Client empfangen
Kerberos-Details für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (Kerberos-Clients)
- Dieses Diagramm zeigt, welche Kerberos-Clients in der Gruppe am aktivsten waren, indem es die Gesamtzahl der Kerberos-Anfragen aufschlüsselt, die die Gruppe vom Client gesendet hat.
- Hauptnamen der wichtigsten Kunden
- Dieses Diagramm zeigt, welche Kerberos-Benutzer auf den Clients in der Gruppe am aktivsten waren, indem die Gesamtzahl der Kerberos-Antworten, die die Gruppe erhalten hat, nach Client Principal Name aufgeschlüsselt wird.
- Die häufigsten Arten von Anforderungsnachrichten
- Dieses Diagramm zeigt, welche Kerberos-Nachrichtentypen die Gruppe am häufigsten gesendet hat, indem die Gesamtzahl der von der Gruppe gesendeten Anfragen nach Nachrichtentyp aufgeschlüsselt wird.
- Die häufigsten Fehlertypen
- Dieses Diagramm zeigt, welche Kerberos-Fehlertypen die Gruppe am häufigsten erhalten hat, indem die Anzahl der an die Gruppe zurückgegebenen Antworten nach Fehlertyp aufgeschlüsselt wird.
- Die häufigsten Serverprinzipalnamen
- Dieses Diagramm zeigt, welche Kerberos-Dienste von Clients in der Gruppe angefordert wurden, indem die Gesamtzahl der Kerberos-Antworten, die die Gruppe erhalten hat, anhand des Serverprinzipalnamens aufgeschlüsselt wird.
- Die häufigsten Arten von Antwortnachrichten
- Dieses Diagramm zeigt, welche Kerberos-Nachrichtentypen die Gruppe am häufigsten erhalten hat, indem die Gesamtzahl der Antworten, die die Gruppe erhalten hat, nach Nachrichtentyp aufgeschlüsselt wird.
Kerberos-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden die Clients möglicherweise mehr Anfragen, als Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die von diesem gesendet wurden Kerberos-Client Antworten Die Anzahl der Antworten, die eingegangen sind von dieser Kerberos-Client Fehler Die Anzahl der Antwortfehler, die waren von diesem Kerberos-Client empfangen - Verarbeitungszeit des Servers
-
Wenn sich eine Client-Gruppe langsam verhält, können Sie anhand der Serververarbeitungszeit herausfinden,
ob das Problem bei den Servern liegt. Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche
Zeit, die Server für die Bearbeitung von Anfragen von den Clients benötigten. Hohe
Serververarbeitungszeiten deuten darauf hin, dass die Clients langsame Server kontaktieren.
Metrisch Beschreibung Verarbeitungszeit des Kerberos-Client-Servers Die für diesen Kerberos-Client benötigte Zeit um das erste Paket einer Antwort nach dem Senden des letzten Paket einer Anfrage.
Seite „Kerberos-Servergruppe"
Auf dieser Seite werden Metrikdiagramme von angezeigt Kerberos Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur Kerberos-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
Kerberos Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann Kerberos-Fehler aufgetreten sind und wie viele Kerberos-Antworten die Server gesendet haben.
Anhand dieser Informationen können Sie feststellen, wie aktiv die Server zu dem Zeitpunkt waren, als
sie die Fehler gemeldet haben.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie sich Details zu jedem Fehler anzeigen lassen, einschließlich des Fehlercodes. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von Kerberos-Anfragen zu Kerberos-Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie im Diagramm Kerberos-Metriken für Gruppen .
Hinweis: Um eine Aufschlüsselung nach dem Fehlercode durchzuführen, klicken Sie auf Fehler und wähle Fehler aus der Speisekarte. Metrisch Beschreibung Antworten Die Anzahl der Antworten, die gesendet wurden von dieser Kerberos-Server Fehler Die Anzahl der Antwortfehler, die waren gesendet von diesem Kerberos-Server - Transaktionen insgesamt
- Dieses Diagramm zeigt, wie viele Kerberos-Antwortserver in der Gruppe gesendet haben und wie
viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die gesendet wurden von dieser Kerberos-Server Fehler Die Anzahl der Antwortfehler, die waren gesendet von diesem Kerberos-Server
Kerberos-Details für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (Kerberos-Server)
- Dieses Diagramm zeigt, welche Kerberos-Server in der Gruppe am aktivsten waren, indem die Gesamtzahl der von der Gruppe gesendeten Kerberos-Antworten pro Server aufgeschlüsselt wird.
- Hauptnamen der wichtigsten Kunden
- Dieses Diagramm zeigt, welche Kerberos-Benutzer auf Servern in der Gruppe am aktivsten waren, indem die Gesamtzahl der von der Gruppe gesendeten Kerberos-Antworten nach dem Client-Prinzipalnamen aufgeschlüsselt wird.
- Die häufigsten Arten von Anforderungsnachrichten
- Dieses Diagramm zeigt, welche Kerberos-Nachrichtentypen Server in der Gruppe am meisten erhalten haben, indem die Gesamtzahl der Anfragen, die die Gruppe erhalten hat, nach Nachrichtentyp aufgeschlüsselt wird.
- Die häufigsten Fehlertypen
- Dieses Diagramm zeigt, welche Kerberos-Fehlertypen Server in der Gruppe am meisten zurückgegeben haben, indem die Gesamtzahl der von der Gruppe gesendeten Antworten nach Fehlertyp aufgeschlüsselt wird.
- Die häufigsten Serverprinzipalnamen
- Dieses Diagramm zeigt, welche Kerberos-Dienste auf Servern in der Gruppe am häufigsten angefordert wurden, indem die Gesamtzahl der Kerberos-Antworten, die die Gruppe gesendet hat, anhand des Dienstprinzipalnamens aufgeschlüsselt wird.
- Die häufigsten Arten von Antwortnachrichten
- Dieses Diagramm zeigt, welche Kerberos-Nachrichtentypen der Server am häufigsten gesendet hat, indem die Gesamtzahl der Antwortserver in der Gruppe nach Nachrichtentyp aufgeschlüsselt wird.
Kerberos-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden Clients möglicherweise mehr Anfragen, als die Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die eingegangen sind von dieser Kerberos-Server Antworten Die Anzahl der Antworten, die gesendet wurden von dieser Kerberos-Server Fehler Die Anzahl der Antwortfehler, die waren gesendet von diesem Kerberos-Server - Verarbeitungszeit des Servers
-
Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche Zeit, die die Server für die
Bearbeitung von Anfragen von Clients benötigten. Hohe Serververarbeitungszeiten deuten darauf hin, dass die Server in einer
Gruppe langsam sind.
Metrisch Beschreibung Verarbeitungszeit des Kerberos-Servers Die Zeit, die zum Senden des ersten Paket benötigt wurde einer Antwort nach Erhalt des letzten Paket einer Anfrage, die von diesem empfangen wurde Kerberos-Server
LDAP
Das ExtraHop-System sammelt Metriken über das Lightweight Directory Access Protocol (LDAP) activity. ist ein herstellerneutrales Protokoll, das ein verteiltes Verzeichnis verwaltet und einen einfachen Zugriff darauf ermöglicht. Lesen Sie den ExtraHop-Blogbeitrag: Was ist LDAP und wer braucht es überhaupt?
Überlegungen zur Sicherheit
- LDAP-Abfragen können die Aufzählung ermöglichen. Dabei handelt es sich um eine Aufklärungstechnik, mit der Angreifer Kontoinformationen ermitteln können.
- Angriffstools wie BloodHound, senden Sie LDAP-Abfragen, um Active Directory Directory-Objekte wie Benutzer, Domänenadministratoren, Arbeitsstationen und Domänencontroller aufzulisten, die zu zukünftigen Zielen werden können.
- Unverschlüsselte LDAP-Verbindungen können vertrauliche Daten für Angreifer offenlegen, die den LDAP-Verkehr abfangen .
LDAP-Anwendungsseite
Auf dieser Seite werden Metrikdiagramme von angezeigt LDAP Verkehr, der mit einem Anwendungscontainer in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur LDAP-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
LDAP Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann LDAP-Fehler und -Antworten mit der
Anwendung verknüpft waren. Anhand dieser Informationen können Sie feststellen, wie aktiv die Anwendung zum
Zeitpunkt des Auftretens der Fehler war.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der damit verbundenen LDAP-Antworten Anwendung. Fehler Die Anzahl der LDAP-Antworten mit Ergebnis Codes, die darauf hinweisen, dass ein Fehler aufgetreten ist. Antworten mit fehlerfreien Ergebniscodes, wie als Erfolg und Empfehlung, sind nicht enthalten. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der LDAP-Antworten, die mit der
Anwendung verknüpft waren, und wie viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der damit verbundenen LDAP-Antworten Anwendung. Fehler Die Anzahl der LDAP-Antworten mit Ergebnis Codes, die darauf hinweisen, dass ein Fehler aufgetreten ist. Antworten mit fehlerfreien Ergebniscodes, wie als Erfolg und Empfehlung, sind nicht enthalten. - Leistung (95. Perzentil)
-
Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken.
Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer vollständigen
Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange Clients gebraucht haben, um Anfragen an
das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange die Server für die Bearbeitung von Anfragen gebraucht haben;
und die Antwortübertragungszeit zeigt, wie lange die Server gebraucht haben, um Antworten an
das Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Transferzeit anfragen Die Zeit zwischen der Erkennung durch das ExtraHop-System das erste Paket und das letzte Paket von LDAP-Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit des Servers Die Zeit, die Geräte brauchten, um den ersten zu senden Paket in einer Antwort nach Erhalt des letzten Paket der Anfrage. Ein langer Server Die Verarbeitungszeit kann auf eine serverseitige Latenz hinweisen Übertragungszeit der Antwort Die Zeit zwischen der Erkennung durch das ExtraHop-System das erste Paket und das letzte Paket von LDAP-Antworten. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit, die der LDAP-Server oder Client hat senden Sie ein Paket und erhalten Sie eine sofortige Bestätigung (ACK). Eine lange Hin- und Rückreisezeit (RTT) gibt die Netzwerklatenz Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn eine Anwendung langsam reagiert, können Sie anhand
von Leistungsübersichtsmetriken herausfinden, ob das Netzwerk oder die Server das
Problem verursachen. Diese Metriken zeigen das 95. Perzentil der Zeit, die Server für die Bearbeitung von
Anfragen von Clients benötigten, im Vergleich zum 95. Perzentil der Zeit, die Pakete aus diesen Anfragen
(und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten. Hohe
Serververarbeitungszeiten deuten darauf hin, dass Clients langsame Server kontaktieren. Hohe
TCP-Roundtrip-Zeiten deuten darauf hin, dass Clients über langsame Netzwerke kommunizieren.
Metrisch Beschreibung Verarbeitungszeit des Servers Die Zeit, die Geräte brauchten, um den ersten zu senden Paket in einer Antwort nach Erhalt des letzten Paket der Anfrage. Ein langer Server Die Verarbeitungszeit kann auf eine serverseitige Latenz hinweisen Zeit für Hin- und Rückfahrt Die Zeit, die der LDAP-Server oder Client hat senden Sie ein Paket und erhalten Sie eine sofortige Bestätigung (ACK). Eine lange Hin- und Rückreisezeit (RTT) gibt die Netzwerklatenz
LDAP-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Kunden
- Dieses Diagramm zeigt, mit welchen LDAP-Clients die Anwendung am meisten kommunizierte, indem die Gesamtzahl der Anfragen, die die Anwendung erhalten hat, aufgeschlüsselt wird.
- Die bekanntesten Namen von Bind
- Dieses Diagramm zeigt, welche Benutzer in der Anwendung am aktivsten waren, indem die Gesamtzahl der LDAP-Anfragen nach Benutzernamen aufgeschlüsselt wird.
- Die häufigsten Fehlercodes
- Dieses Diagramm zeigt, welche LDAP-Fehlercodes die Anwendung am häufigsten zurückgegeben hat, indem die Anzahl der Antworten, die die Anwendung zurückgegeben hat, nach Fehlercode aufgeteilt wird.
- Die wichtigsten SASL-Authentifizierungsmechanismen
- Dieses Diagramm zeigt, über welchen SASL-Mechanismus die Anwendung am häufigsten authentifiziert wurde, indem die Gesamtzahl der LDAP-Anfragen nach Authentifizierungsmechanismus aufgeschlüsselt wird.
- Die besten Methoden
- Dieses Diagramm zeigt, welche LDAP-Methoden mit der Anwendung verknüpft waren, indem die Gesamtzahl der LDAP-Anfragen nach Methoden aufgeschlüsselt wird.
LDAP-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des LDAP-Servers Die Zeit, die Geräte brauchten, um den ersten zu senden Paket in einer Antwort nach Erhalt des letzten Paket der Anfrage. Ein langer Server Die Verarbeitungszeit kann auf eine serverseitige Latenz hinweisen - Verarbeitungszeit des Servers
-
Diese Tabelle zeigt die durchschnittliche Bearbeitungszeit für den Anwendung.
Metrisch Beschreibung Verarbeitungszeit des LDAP-Servers Die Zeit, die Geräte brauchten, um den ersten zu senden Paket in einer Antwort nach Erhalt des letzten Paket der Anfrage. Ein langer Server Die Verarbeitungszeit kann auf eine serverseitige Latenz hinweisen - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit, die der LDAP-Server oder Client hat senden Sie ein Paket und erhalten Sie eine sofortige Bestätigung (ACK). Eine lange Hin- und Rückreisezeit (RTT) gibt die Netzwerklatenz - Zeit für Hin- und Rückfahrt
-
Diese Tabelle zeigt
die durchschnittliche Hin- und Rückflugzeit für die Anwendung.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit, die der LDAP-Server oder Client hat senden Sie ein Paket und erhalten Sie eine sofortige Bestätigung (ACK). Eine lange Hin- und Rückreisezeit (RTT) gibt die Netzwerklatenz
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass ein Problem mit einem Server oder einem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
-
Dieses Diagramm zeigt die Anzahl der Nullfenster, die einer Anwendung
zugeordnet waren. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der Pakete
angeben, die über einen bestimmten Zeitraum an sie gesendet werden können.
Wenn an ein Gerät mehr Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein
Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig einzustellen, bis das Gerät den Vorgang
aufholt. Wenn Sie eine große Anzahl von Nullfenstern sehen, ist ein Server oder Client möglicherweise
nicht schnell genug, um die empfangene Datenmenge zu unterstützen.
Metrisch Definition Zero Windows anfordern Die Anzahl der gesendeten Null-Window-Anzeigen von LDAP-Clients. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl eingehender Zero-Windows weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Antwort Null Windows Die Anzahl der gesendeten Null-Window-Anzeigen von Servern beim Empfang von LDAP-Anfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von ausgehenden Zero-Windows weist darauf hin, dass ein Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Gesamtzahl der Host-Stände
- Dieses Diagramm zeigt die durchschnittliche Anzahl von Zero-Window-Werbeanzeigen, die von Geräten gesendet wurden.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen
Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu
viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät
eine Anfrage oder Antwort sendet und innerhalb einer bestimmten
Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen
nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise
zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, als Clients LDAP-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server LDAP-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
- Gesamtzahl der Netzwerkausfälle
-
Dieses Diagramm zeigt die durchschnittliche Anzahl von Timeouts bei der
erneuten Übertragung, die durch Überlastung beim Senden von Anfragen durch Clients und Server verursacht wurden.
Metrisch Definition RTOs Ein Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, als Clients LDAP-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server LDAP-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Gesamtwerte der LDAP-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr Anfragen, als Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um herauszufinden, ob das Problem mit dem Netzwerk oder einem Server zusammenhängt, überprüfen Sie RTOs und Zero Windows in der Netzwerk-Daten Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der LDAP-Anfragen und -Antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der damit verbundenen LDAP-Anfragen Anwendung. Antworten Die Anzahl der damit verbundenen LDAP-Antworten Anwendung. Fehler Die Anzahl der LDAP-Antworten mit Ergebnis Codes, die darauf hinweisen, dass ein Fehler aufgetreten ist. Antworten mit fehlerfreien Ergebniscodes, wie als Erfolg und Empfehlung, sind nicht enthalten. RTOs anfragen Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, als Clients LDAP-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Antwort-RTOs Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server LDAP-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Zero Windows anfordern Die Anzahl der gesendeten Null-Window-Anzeigen von LDAP-Clients. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Antwort Null Windows Die Anzahl der gesendeten Null-Window-Anzeigen von Servern beim Empfang von LDAP-Anfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. L2-Byte anfordern Die Anzahl der L2-Bytes, die mit verknüpft sind LDAP-Anfragen Antwort L2 Byte Die Anzahl der L2-Bytes, die mit verknüpft sind LDAP-Antworten Goodput Bytes anfordern Die Anzahl der Goodput-Bytes, die mit verknüpft sind LDAP-Anfragen. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Antwort Goodput Bytes Die Anzahl der Goodput-Bytes, die mit verknüpft sind LDAP-Antworten. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Pakete anfordern Die Anzahl der mit LDAP verknüpften Pakete Anfragen. Antwortpakete Die Anzahl der mit LDAP verknüpften Pakete Antworten. - LDAP-Netzwerkmetriken
-
Metrisch Beschreibung Nur-Text-Nachrichten Die Anzahl der ausgetauschten Klartext-Nachrichten sind mit dieser Anwendung verknüpft. SASL-Nachrichten Die Anzahl der verschlüsselten Nachrichten, die ausgetauscht wurden sind mit dieser Anwendung verknüpft.
LDAP-Client-Seite
Auf dieser Seite werden Metrikdiagramme von angezeigt LDAP Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur LDAP-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
LDAP Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann LDAP-Fehler aufgetreten sind und wie viele Antworten der LDAP-Client
erhalten hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Client zu dem Zeitpunkt war, als er die Fehler
empfing.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie sich Details zu jedem Fehler anzeigen lassen, einschließlich des Fehlercodes. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von Anfragen zu Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Hinweis: Um zu sehen, welche Fehlercodes an den Client zurückgegeben wurden, klicken Sie auf Antworten und wähle Fehlercode aus der Speisekarte. Metrisch Beschreibung Antworten Die Anzahl der von diesem LDAP empfangenen Antworten Client. Fehler Die Anzahl der eingegangenen Antworten LDAP-Client, der gemeldet hat, dass ein Fehler aufgetreten ist. Antworten mit fehlerfreien Ergebniscodes, wie Erfolg und Weiterempfehlung sind nicht enthalten. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der LDAP-Antworten, die der Client erhalten hat, und wie
viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der von diesem LDAP empfangenen Antworten Client. Fehler Die Anzahl der eingegangenen Antworten LDAP-Client, der gemeldet hat, dass ein Fehler aufgetreten ist. Antworten mit fehlerfreien Ergebniscodes, wie Erfolg und Weiterempfehlung sind nicht enthalten. - Leistungsübersicht (95. Perzentil)
- Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken. Die Serververarbeitungszeit
gibt an, wie lange Server gebraucht haben, um Anfragen von Clients zu verarbeiten. Die Verarbeitungszeiten werden
berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und
Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, allein anhand der Verarbeitungszeit zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Metrik allein ein unvollständiges Bild liefert. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Verarbeitungszeiten sehen, aber die RTT niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn jedoch sowohl die RTT- als auch die Verarbeitungszeiten hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
RTT misst nur, wie lange es dauert, bis eine sofortige Bestätigung gesendet wird; es wartet nicht, bis alle Pakete zugestellt sind. Daher ist RTT ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Verarbeitungszeiten sehen, aber die TCP-RTT niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Überprüfen Sie das Netzwerk auf Latenzprobleme, wenn sowohl TCP-RTT als auch Verarbeitungszeiten übereinstimmen.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Die Verarbeitungszeit kann hoch sein, weil der Server lange gebraucht hat, um die Antwort zu übertragen (möglicherweise, weil die Antwort sehr umfangreich war). Die Verarbeitungszeit kann jedoch auch hoch sein, weil die Antwort lange Zeit benötigt hat, bis die Antwort im Netzwerk übertragen wurde (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Übertragungszeit der LDAP-Client-Anfrage Wenn das Gerät als LDAP-Client fungiert, Zeit zwischen der Erkennung des ersten Pakets durch das ExtraHop-System und dem letzten gesendeten Paket Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit des LDAP-Client-Servers Die Zeit, die das Gerät zum Empfangen benötigt hat das erste Paket als Antwort nach dem Senden des letzten Paket der Anfrage. Ein langer Die Verarbeitungszeit Server kann auf eine serverseitige Latenz hinweisen Übertragungszeit der Antwort auf den LDAP-Client Wenn das Gerät als LDAP-Client fungiert, Zeit zwischen der Erkennung des ersten Pakets und des letzten Pakets durch das ExtraHop-System von erhaltene Antworten. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen LDAP-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn ein Client langsam reagiert, können Sie
anhand von Leistungsübersichtsmetriken herausfinden, ob das Netzwerk oder die Server das Problem verursachen.
Diese Metriken zeigen das 95. Perzentil der Zeit, die Server für die Bearbeitung von
Anfragen vom Client benötigten, im Vergleich zur 95. Perzentilzeit, die Pakete aus diesen
Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten.
Hohe Serververarbeitungszeiten deuten darauf hin, dass der Client langsame Server kontaktiert. Hohe
TCP-Roundtrip-Zeiten deuten darauf hin, dass der Client über langsame
Netzwerke kommuniziert.
Metrisch Beschreibung Verarbeitungszeit des LDAP-Client-Servers Die Zeit, die das Gerät zum Empfangen benötigt hat das erste Paket als Antwort nach dem Senden des letzten Paket der Anfrage. Ein langer Die Verarbeitungszeit Server kann auf eine serverseitige Latenz hinweisen Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen LDAP-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz
LDAP-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Server
- Dieses Diagramm zeigt, mit welchen LDAP-Servern der Client am meisten kommunizierte, indem es die Gesamtzahl der Anfragen aufschlüsselt, die der Client vom Server gesendet hat.
- Die bekanntesten Namen von Bind
- Dieses Diagramm zeigt, welche Benutzer am häufigsten auf dem Client aktiv waren, indem die Gesamtzahl der Anfragen, die der Client gesendet hat, nach Benutzernamen aufgeteilt wird.
- Die häufigsten Fehlercodes
- Dieses Diagramm zeigt, welche LDAP-Fehlercodes der Client am häufigsten erhalten hat, indem die Anzahl der an den Client zurückgegebenen Antworten nach Fehlercode aufgeschlüsselt wird.
- Die wichtigsten SASL-Authentifizierungsmechanismen
- Dieses Diagramm zeigt, über welchen SASL-Mechanismus der Client am häufigsten authentifiziert wurde, indem die Gesamtzahl der Anfragen, die der Client über den Authentifizierungsmechanismus gesendet hat, aufgeschlüsselt wird.
- Top-Nachrichten
- Dieses Diagramm zeigt, welche LDAP-Nachrichten der Client am häufigsten erhalten hat, indem die Anzahl der an den Client zurückgegebenen Antworten pro Nachricht aufgeschlüsselt wird.
LDAP-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des LDAP-Client-Servers Die Zeit, die das Gerät zum Empfangen benötigt hat das erste Paket als Antwort nach dem Senden des letzten Paket der Anfrage. Ein langer Die Verarbeitungszeit Server kann auf eine serverseitige Latenz hinweisen - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Bearbeitungszeit für den Client.
Metrisch Beschreibung Verarbeitungszeit des LDAP-Client-Servers Die Zeit, die das Gerät zum Empfangen benötigt hat das erste Paket als Antwort nach dem Senden des letzten Paket der Anfrage. Ein langer Die Verarbeitungszeit Server kann auf eine serverseitige Latenz hinweisen - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen LDAP-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Hin- und Rückflugzeit für den Client.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen LDAP-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Gesamtwerte der LDAP-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, sendet der Client möglicherweise mehr
Anfragen, als die Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen
, ob das Problem am Netzwerk oder am Server liegt, überprüfen Sie RTOs und Zero Windows in der
Netzwerk-Daten
Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der LDAP-Anfragen und -Antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die von diesem LDAP gesendet wurden Client. Antworten Die Anzahl der von diesem LDAP empfangenen Antworten Client. Fehler Die Anzahl der eingegangenen Antworten LDAP-Client, der gemeldet hat, dass ein Fehler aufgetreten ist. Antworten mit fehlerfreien Ergebniscodes, wie Erfolg und Weiterempfehlung sind nicht enthalten. - Nachrichten insgesamt
- Zeigt die Gesamtzahl der Nachrichten an, die der Client ausgetauscht hat.
Metrisch Beschreibung Nur-Text-Nachrichten Die Anzahl der Klartextnachrichten, die ausgetauscht wurden von dieser LDAP-Client SASL-Nachrichten Die Anzahl der verschlüsselten Nachrichten, die ausgetauscht wurden von dieser LDAP-Client
LDAP-Serverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt LDAP Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur LDAP-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
LDAP Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann LDAP-Fehler aufgetreten sind und wie viele LDAP-Antworten der Server
gesendet hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Server zu dem Zeitpunkt war, als er die Fehler
zurückgab.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie sich Details zu jedem Fehler anzeigen lassen, einschließlich des Fehlercodes. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von Anfragen zu Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Hinweis: Um zu sehen, welche Fehlercodes der Server gesendet hat, klicken Sie auf Antworten und wähle Fehlercode aus der Speisekarte. Metrisch Beschreibung Antworten Die Anzahl der von diesem LDAP gesendeten Antworten Server. Fehler Die Anzahl der vom LDAP gesendeten Antworten Server, der gemeldet hat, dass ein Fehler aufgetreten ist. Antworten mit fehlerfreien LDAP-Ergebniscodes, wie Erfolg und Weiterempfehlung sind nicht enthalten. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der LDAP-Antworten, die der Server gesendet hat, und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der von diesem LDAP gesendeten Antworten Server. Fehler Die Anzahl der vom LDAP gesendeten Antworten Server, der gemeldet hat, dass ein Fehler aufgetreten ist. Antworten mit fehlerfreien LDAP-Ergebniscodes, wie Erfolg und Weiterempfehlung sind nicht enthalten. Nur-Text-Nachrichten Die Anzahl der Klartextnachrichten, die ausgetauscht wurden von dieser LDAP-Server - Leistungsübersicht (95. Perzentil)
- Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken. Die Serververarbeitungszeit
gibt an, wie lange Server gebraucht haben, um Anfragen von Clients zu verarbeiten. Die Verarbeitungszeiten werden
berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und
Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, allein anhand der Verarbeitungszeit zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Metrik allein ein unvollständiges Bild liefert. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Verarbeitungszeiten sehen, aber die RTT niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn jedoch sowohl die RTT- als auch die Verarbeitungszeiten hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
RTT misst nur, wie lange es dauert, bis eine sofortige Bestätigung gesendet wird; es wartet nicht, bis alle Pakete zugestellt sind. Daher ist RTT ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Verarbeitungszeiten sehen, aber die TCP-RTT niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Überprüfen Sie das Netzwerk auf Latenzprobleme, wenn sowohl TCP-RTT als auch Verarbeitungszeiten übereinstimmen.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Die Verarbeitungszeit kann hoch sein, weil der Server lange gebraucht hat, um die Antwort zu übertragen (möglicherweise, weil die Antwort sehr umfangreich war). Die Verarbeitungszeit kann jedoch auch hoch sein, weil die Antwort lange Zeit benötigt hat, bis die Antwort im Netzwerk übertragen wurde (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Übertragungszeit der LDAP-Serveranforderung Wenn das Gerät als LDAP-Server fungiert, Zeit zwischen der Erkennung des ersten Pakets durch das ExtraHop-System und dem letzten gesendeten Paket Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit des LDAP-Servers Die Zeit, die das Gerät zum Senden der erstes Paket als Antwort nach Erhalt des letzten Paket der Anfrage. Ein langer Die Verarbeitungszeit Server kann auf eine serverseitige Latenz hinweisen Übertragungszeit der Antwort des LDAP-Servers Wenn das Gerät als LDAP-Server fungiert, wird der Zeit zwischen der Erkennung des ersten Pakets und des letzten Pakets durch das ExtraHop-System von erhaltene Antworten. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen LDAP-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn ein Server langsam reagiert, können Sie
anhand von Leistungsübersichtsmetriken herausfinden, ob das
Problem vom Netzwerk oder vom Server verursacht wird. Die Leistungsübersichtsmetriken zeigen das 95. Perzentil der Zeit, die der
Server für die Verarbeitung von Anfragen von Clients benötigte, im Vergleich zur 95. Perzentilzeit, die
Pakete aus diesen Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten.
Hohe Serververarbeitungszeiten deuten darauf hin, dass der Server langsam ist.
Hohe RTTs weisen darauf hin, dass der Server über langsame Netzwerke kommuniziert.
Metrisch Beschreibung Verarbeitungszeit des LDAP-Servers Die Zeit, die das Gerät zum Senden der erstes Paket als Antwort nach Erhalt des letzten Paket der Anfrage. Ein langer Die Verarbeitungszeit Server kann auf eine serverseitige Latenz hinweisen Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen LDAP-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz
LDAP-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Kunden
- Dieses Diagramm zeigt, mit welchen LDAP-Clients der Server am meisten kommunizierte, indem es die Gesamtzahl der Anfragen aufschlüsselt, die der Server vom Client erhalten hat.
- Die bekanntesten Namen von Bind
- Dieses Diagramm zeigt, welche Benutzer am häufigsten auf dem Server aktiv waren, indem die Gesamtzahl der Anfragen, die der Server erhalten hat, nach Benutzernamen aufgeteilt wird.
- Die häufigsten Fehlercodes
- Dieses Diagramm zeigt, welche LDAP-Fehlercodes der Server am häufigsten zurückgegeben hat, indem die Anzahl der vom Server zurückgegebenen Antworten nach Fehlercode aufgeschlüsselt wird.
- Die wichtigsten SASL-Authentifizierungsmechanismen
- Dieses Diagramm zeigt, über welchen SASL-Mechanismus der Server am häufigsten authentifiziert wurde, indem die Gesamtzahl der Anfragen, die der Server über den Authentifizierungsmechanismus erhalten hat, aufgeschlüsselt wird.
- Die wichtigsten Nachrichten
- Dieses Diagramm zeigt, welche LDAP-Nachrichten der Server am häufigsten gesendet hat, indem die Anzahl der Antworten, die der Server per Nachricht gesendet hat, aufgeschlüsselt wird.
LDAP-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des LDAP-Servers Die Zeit, die das Gerät zum Senden der erstes Paket als Antwort nach Erhalt des letzten Paket der Anfrage. Ein langer Die Verarbeitungszeit Server kann auf eine serverseitige Latenz hinweisen - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Verarbeitungszeit für den Server.
Metrisch Beschreibung Verarbeitungszeit des LDAP-Servers Die Zeit, die das Gerät zum Senden der erstes Paket als Antwort nach Erhalt des letzten Paket der Anfrage. Ein langer Die Verarbeitungszeit Server kann auf eine serverseitige Latenz hinweisen - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen LDAP-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Hin- und Rückflugzeit für den Client.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen LDAP-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für die Netzwerklatenz
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Gesamtwerte der LDAP-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr
Anfragen, als der Server verarbeiten kann, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen
, ob das Problem am Netzwerk oder am Server liegt, überprüfen Sie RTOs und Zero Windows in der
Netzwerk-Daten
Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der LDAP-Anfragen und -Antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die von diesem LDAP empfangen wurden Server. Antworten Die Anzahl der von diesem LDAP gesendeten Antworten Server. Fehler Die Anzahl der vom LDAP gesendeten Antworten Server, der gemeldet hat, dass ein Fehler aufgetreten ist. Antworten mit fehlerfreien LDAP-Ergebniscodes, wie Erfolg und Weiterempfehlung sind nicht enthalten. - Nachrichten insgesamt
- Zeigt die Gesamtzahl der Nachrichten an, die der Server ausgetauscht hat.
Metrisch Beschreibung Nur-Text-Nachrichten Die Anzahl der Klartextnachrichten, die ausgetauscht wurden von dieser LDAP-Server SASL-Nachrichten Die Anzahl der verschlüsselten Nachrichten, die ausgetauscht wurden von dieser LDAP-Server
LDAP-Clientgruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt LDAP Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur LDAP-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
LDAP Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann LDAP-Fehler aufgetreten sind und wie viele Antworten die LDAP-Clients
erhalten haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Kunden zu dem Zeitpunkt waren, als sie die Fehler
erhielten.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie sich Details zu jedem Fehler anzeigen lassen, einschließlich des Fehlercodes. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von LDAP-Anfragen zu LDAP-Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie in der Tabelle LDAP-Metriken für Gruppen.
Hinweis: Um zu sehen, welche Fehlercodes an den Client zurückgegeben wurden, klicken Sie auf Antworten und wähle Fehlercode aus der Speisekarte. Metrisch Beschreibung Antworten Die Anzahl der von diesem LDAP empfangenen Antworten Client. Fehler Die Anzahl der eingegangenen Antworten LDAP-Client, der gemeldet hat, dass ein Fehler aufgetreten ist. Antworten mit fehlerfreien Ergebniscodes, wie Erfolg und Weiterempfehlung sind nicht enthalten. - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele LDAP-Antworten die Clients erhalten haben und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der von diesem LDAP empfangenen Antworten Client. Fehler Die Anzahl der eingegangenen Antworten LDAP-Client, der gemeldet hat, dass ein Fehler aufgetreten ist. Antworten mit fehlerfreien Ergebniscodes, wie Erfolg und Weiterempfehlung sind nicht enthalten.
LDAP-Details für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (LDAP-Clients)
- Dieses Diagramm zeigt, welche LDAP-Clients in der Gruppe am aktivsten waren, indem es die Gesamtzahl der LDAP-Anfragen aufschlüsselt, die die Gruppe vom Client gesendet hat.
- Die bekanntesten Namen von Bind
- Dieses Diagramm zeigt, welche Benutzer in der Gruppe am meisten aktiv waren, indem die Gesamtzahl der Anfragen, die die Gruppe gesendet hat, nach Benutzernamen aufgeteilt wird.
- Die häufigsten Fehlercodes
- Dieses Diagramm zeigt, welche LDAP-Fehlercodes die Gruppe am häufigsten erhalten hat, indem die Anzahl der an die Gruppe zurückgegebenen Antworten nach Fehlercode aufgeschlüsselt wird.
- Die wichtigsten SASL-Authentifizierungsmechanismen
- Dieses Diagramm zeigt, bei welchem SASL-Mechanismus die Gruppe am häufigsten authentifiziert wurde, indem die Gesamtzahl der Anfragen, die die Gruppe über den Authentifizierungsmechanismus gesendet hat, aufgeschlüsselt wird.
- Die besten Methoden
- Dieses Diagramm zeigt, welche LDAP-Methoden die Gruppe am häufigsten aufgerufen hat, indem die Gesamtzahl der Anfragen, die die Gruppe nach Methode gesendet hat, aufgeschlüsselt wird.
LDAP-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden die Clients möglicherweise mehr Anfragen, als Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die von diesem LDAP gesendet wurden Client. Antworten Die Anzahl der von diesem LDAP empfangenen Antworten Client. Fehler Die Anzahl der eingegangenen Antworten LDAP-Client, der gemeldet hat, dass ein Fehler aufgetreten ist. Antworten mit fehlerfreien Ergebniscodes, wie Erfolg und Weiterempfehlung sind nicht enthalten. Nur-Text-Nachrichten Die Anzahl der Klartextnachrichten, die ausgetauscht wurden von dieser LDAP-Client SASL-Nachrichten Die Anzahl der verschlüsselten Nachrichten, die ausgetauscht wurden von dieser LDAP-Client - Verarbeitungszeit des Servers
-
Wenn sich eine Client-Gruppe langsam verhält, können Sie anhand der Serververarbeitungszeit herausfinden,
ob das Problem bei den Servern liegt. Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche
Zeit, die Server für die Bearbeitung von Anfragen von den Clients benötigten. Hohe
Serververarbeitungszeiten deuten darauf hin, dass die Clients langsame Server kontaktieren.
Metrisch Beschreibung Verarbeitungszeit des LDAP-Client-Servers Die Zeit, die das Gerät zum Empfangen benötigt hat das erste Paket als Antwort nach dem Senden des letzten Paket der Anfrage. Ein langer Die Verarbeitungszeit Server kann auf eine serverseitige Latenz hinweisen
LDAP-Servergruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt LDAP Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur LDAP-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
LDAP Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wann LDAP-Fehler aufgetreten sind und wie viele LDAP-Antworten die Server
gesendet haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Server zu dem Zeitpunkt waren, als sie
die Fehler gemeldet haben.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie sich Details zu jedem Fehler anzeigen lassen, einschließlich des Fehlercodes. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von LDAP-Anfragen zu LDAP-Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie in der Tabelle LDAP-Metriken für Gruppen.
Hinweis: Um zu sehen, welche Fehlercodes der Server gesendet hat, klicken Sie auf Antworten und wähle Fehlercode aus der Speisekarte. Metrisch Beschreibung Antworten Die Anzahl der von diesem LDAP gesendeten Antworten Server. Fehler Die Anzahl der vom LDAP gesendeten Antworten Server, der gemeldet hat, dass ein Fehler aufgetreten ist. Antworten mit fehlerfreien LDAP-Ergebniscodes, wie Erfolg und Weiterempfehlung sind nicht enthalten. - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele LDAP-Antwortserver in der Gruppe gesendet haben und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der von diesem LDAP gesendeten Antworten Server. Fehler Die Anzahl der vom LDAP gesendeten Antworten Server, der gemeldet hat, dass ein Fehler aufgetreten ist. Antworten mit fehlerfreien LDAP-Ergebniscodes, wie Erfolg und Weiterempfehlung sind nicht enthalten.
LDAP-Details für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (LDAP-Server)
- Dieses Diagramm zeigt, welche LDAP-Server in der Gruppe am aktivsten waren, indem die Gesamtzahl der LDAP-Antworten, die die Gruppe vom Server gesendet hat, aufgeschlüsselt wird.
- Die bekanntesten Namen von Bind
- Dieses Diagramm zeigt, welche Benutzer in der Gruppe am aktivsten waren, indem die Gesamtzahl der Anfragen, die die Gruppe erhalten hat, nach Benutzernamen aufgeschlüsselt wird.
- Die häufigsten Fehlercodes
- Dieses Diagramm zeigt, welche LDAP-Fehlercodes die Gruppen am häufigsten zurückgegeben haben, indem die Gesamtzahl der von der Gruppe gesendeten Antworten nach Fehlercode aufgeschlüsselt wird.
- Die wichtigsten SASL-Authentifizierungsmechanismen
- Dieses Diagramm zeigt, bei welchem SASL-Mechanismus die Gruppe am häufigsten authentifiziert wurde, indem die Gesamtzahl der Anfragen, die die Gruppe über den Authentifizierungsmechanismus erhalten hat, aufgeschlüsselt wird.
- Die wichtigsten Nachrichten
- Dieses Diagramm zeigt, welche LDAP-Nachrichten am häufigsten an Server in der Gruppe gesendet wurden, indem die Gesamtzahl der Anfragen, die die Gruppe per Nachricht erhalten hat, aufgeschlüsselt wird.
LDAP-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden Clients möglicherweise mehr Anfragen, als die Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die von diesem LDAP empfangen wurden Server. Antworten Die Anzahl der von diesem LDAP gesendeten Antworten Server. Fehler Die Anzahl der vom LDAP gesendeten Antworten Server, der gemeldet hat, dass ein Fehler aufgetreten ist. Antworten mit fehlerfreien LDAP-Ergebniscodes, wie Erfolg und Weiterempfehlung sind nicht enthalten. Nur-Text-Nachrichten Die Anzahl der Klartextnachrichten, die ausgetauscht wurden von dieser LDAP-Server SASL-Nachrichten Die Anzahl der verschlüsselten Nachrichten, die ausgetauscht wurden von dieser LDAP-Server - Verarbeitungszeit des Servers
-
Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche Zeit, die die Server für die
Bearbeitung von Anfragen von Clients benötigten. Hohe Serververarbeitungszeiten deuten darauf hin, dass die Server in einer
Gruppe langsam sind.
Metrisch Beschreibung Verarbeitungszeit des LDAP-Client-Servers Die Zeit, die das Gerät zum Senden der erstes Paket als Antwort nach Erhalt des letzten Paket der Anfrage. Ein langer Die Verarbeitungszeit Server kann auf eine serverseitige Latenz hinweisen
LLMNR
Das ExtraHop-System sammelt Metriken zur LLMNR (LLMNR) Aktivität. LLMNR ist ein Protokoll, das auf dem DNS-Format (Domain Name System) basiert und die Namensauflösung für Hosts auf demselben lokalen Link ermöglicht, wenn die DNS-Namensauflösung fehlschlägt. LLMNR ist in Microsoft Windows-Systemen enthalten.
| Hinweis: | Das ExtraHop-System enthält keine integrierten Metrikseiten für LLMNR. Sie können jedoch LLMNR-Metriken anzeigen, indem Sie sie zu einer benutzerdefinierten Seite hinzufügen oder Dashboard. |
Überlegungen zur Sicherheit
- LLMNR ist anfällig für LLMNR-Vergiftung Angriffe.
Memcache
Das ExtraHop-System sammelt Metriken über Memcache Aktivität. Memcache ist ein Protokoll, das den Zugriff auf leistungsstarke, verteilte Speicherobjekt-Caching-Systeme über eine TCP-Verbindung ermöglicht.
Memcache-Anwendungsseite
Auf dieser Seite werden Metrikdiagramme von angezeigt Memcache Verkehr, der mit einem Anwendungscontainer in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
Memcache Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann Memcache-Fehler und -Antworten mit der
Anwendung verknüpft waren. Anhand dieser Informationen können Sie feststellen, wie aktiv die Anwendung zum
Zeitpunkt des Auftretens der Fehler war.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der Memcache-Antworten. Fehler Die Anzahl der Memcache-Antworten Fehler. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der Memcache-Antworten, die mit
der Anwendung verknüpft waren, und wie viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Memcache-Antworten. Fehler Die Anzahl der Memcache-Antworten Fehler. - Treffer und Fehlschläge im Cache
- Dieses Diagramm zeigt Ihnen, wann Memcache-Treffer und Fehlschläge aufgetreten sind.
Metrisch Beschreibung Treffer Die Anzahl der übereinstimmenden Artikel und dass Gerät, das als Antwort auf GET-Anfragen empfangen wurde, wenn es als Memcache fungiert Client. Fehlschläge Die Anzahl der angeforderten Artikel, aber nicht wird als Antwort auf Get-Befehle empfangen, wenn das Gerät als Memcache-Client fungiert. Fehlschläge werden gezählt, auch wenn der Server den Client nicht ausdrücklich darüber informiert hat Miss (zum Beispiel, wenn das Get eine stille Anfrage war). - Treffer und Fehlschläge im Cache
- Dieses Diagramm zeigt Ihnen die Gesamtzahl der aufgetretenen Memcache-Treffer und -Fehlschläge.
Metrisch Beschreibung Treffer Die Anzahl der übereinstimmenden Artikel und dass Gerät, das als Antwort auf GET-Anfragen empfangen wurde, wenn es als Memcache fungiert Client. Fehlschläge Die Anzahl der angeforderten Artikel, aber nicht wird als Antwort auf Get-Befehle empfangen, wenn das Gerät als Memcache-Client fungiert. Fehlschläge werden gezählt, auch wenn der Server den Client nicht ausdrücklich darüber informiert hat Miss (zum Beispiel, wenn das Get eine stille Anfrage war). - Zeit für Hin- und Rückfahrt
- Dieses Diagramm zeigt die Perzentile der Round Trip Time (RTT). Die RTT-Metrik misst, wie
lange es gedauert hat, bis Pakete vom Client oder Server sofort bestätigt wurden.
Daher ist RTT ein guter Indikator für die Leistung Ihres Netzwerk.
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Memcache-Clients ein Paket, das eine sofortige Bestätigung erforderte und wann der Client das erhielt Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
- Diese Grafik zeigt das 95. Perzentil für RTT.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Memcache-Clients ein Paket, das eine sofortige Bestätigung erforderte und wann der Client das erhielt Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
Memcache-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche Memcache-Methoden der Anwendung zugeordnet wurden, indem die Gesamtzahl der Memcache-Anfragen nach Methoden aufgeschlüsselt wird.
- Die wichtigsten Statuscodes
- Dieses Diagramm zeigt, welche Memcache-Statuscodes der Server am häufigsten zurückgegeben hat, indem die Gesamtzahl der von der Anwendung gesendeten Antworten nach Statuscode aufgeschlüsselt wird.
- Die häufigsten Fehler
- Dieses Diagramm zeigt, welche Memcache-Fehler die Anwendung am häufigsten erhalten hat, indem die Anzahl der fehlerhaft zurückgegebenen Antworten aufgeschlüsselt wird.
Memcache-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Zeitpunkt, an dem ein Memcache-Client oder Der Server hat ein Paket gesendet, das eine sofortige Bestätigung erfordert, und wann die Bestätigung wurde empfangen. - Zeit für Hin- und Rückfahrt
-
Diese Tabelle zeigt
die durchschnittliche Hin- und Rückflugzeit für die Anwendung.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Zeitpunkt, an dem ein Memcache-Client oder Der Server hat ein Paket gesendet, das eine sofortige Bestätigung erfordert, und wann die Bestätigung wurde empfangen.
Memcache Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass ein Problem mit einem Server oder einem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
-
Dieses Diagramm zeigt die Anzahl der Nullfenster, die einer Anwendung
zugeordnet waren. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der Pakete
angeben, die über einen bestimmten Zeitraum an sie gesendet werden können.
Wenn an ein Gerät mehr Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein
Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig einzustellen, bis das Gerät den Vorgang
aufholt. Wenn Sie eine große Anzahl von Nullfenstern sehen, ist ein Server oder Client möglicherweise
nicht schnell genug, um die empfangene Datenmenge zu unterstützen.
Metrisch Definition Zero Windows anfordern Die Anzahl der Null-Window-Werbungen gesendet von Memcache-Clients. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl eingehender Zero-Windows weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Antwort Null Windows Die Anzahl der Null-Window-Werbungen gesendet von Servern beim Empfang von Memcache-Anfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von ausgehenden Zero-Windows weist darauf hin, dass ein Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Gesamtzahl der Host-Stände
- Dieses Diagramm zeigt die durchschnittliche Anzahl von Zero-Window-Werbeanzeigen, die von Geräten gesendet wurden.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen
Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu
viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät
eine Anfrage oder Antwort sendet und innerhalb einer bestimmten
Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen
nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise
zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Timeouts für die erneute Übertragung verursacht durch eine Überlastung, als Clients Memcache-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der Timeouts für die erneute Übertragung verursacht durch eine Überlastung, als Server Memcache-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
- Gesamtzahl der Netzwerkausfälle
-
Dieses Diagramm zeigt die durchschnittliche Anzahl von Timeouts bei der
erneuten Übertragung, die durch Überlastung beim Senden von Anfragen durch Clients und Server verursacht wurden.
Metrisch Definition RTOs Ein Die Anzahl der Timeouts für die erneute Übertragung verursacht durch eine Überlastung, als Clients Memcache-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der Timeouts für die erneute Übertragung verursacht durch eine Überlastung, als Server Memcache-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Gesamtwerte der Memcache-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr Anfragen, als Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um herauszufinden, ob das Problem mit dem Netzwerk oder einem Server zusammenhängt, überprüfen Sie RTOs und Zero Windows in der Netzwerk-Daten Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Memcache-Anfragen. Antworten Die Anzahl der Memcache-Antworten. Treffer Die Anzahl der übereinstimmenden und zurückgegebenen Artikel Antwort auf Memcache-GET-Anfragen Fehlschläge Die Anzahl der angeforderten, aber nicht erhaltenen Artikel als Antwort auf Memcache-GET-Anfragen. Fehlschläge werden gezählt, auch wenn der Server dies nicht getan hat informiere den Client ausdrücklich über den Fehlschlag (zum Beispiel, wenn der GET ein leiser war Anfrage). Keine Antworten Die Anzahl der Memcache-Anfragen, für die ein Eine Antwort wurde nicht unbedingt erwartet und es wurde auch keine erhalten. - Memcache-Netzwerkmetriken
-
Metrisch Beschreibung Zero Windows anfordern Die Anzahl der Null-Window-Werbungen gesendet von Memcache-Clients. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Antwort Null Windows Die Anzahl der Null-Window-Werbungen gesendet von Servern beim Empfang von Memcache-Anfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. RTOs Ein Die Anzahl der Timeouts für die erneute Übertragung verursacht durch eine Überlastung, als Clients Memcache-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. RTOs raus Die Anzahl der Timeouts für die erneute Übertragung verursacht durch eine Überlastung, als Server Memcache-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. L2-Byte anfordern Die Anzahl der L2-Bytes, die mit verknüpft sind Memcache-Anfragen Antwort L2 Byte Die Anzahl der L2-Bytes, die mit verknüpft sind Memcache-Antworten Goodput Bytes anfordern Die Anzahl der zugehörigen Goodput-Bytes mit Memcache-Anfragen. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Antwort Goodput Bytes Die Anzahl der zugehörigen Goodput-Bytes mit Memcache-Antworten. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Pakete anfordern Die Anzahl der Pakete, die mit verknüpft sind Memcache-Anfragen Antwortpakete Die Anzahl der Pakete, die mit verknüpft sind Memcache-Antworten
Memcache-Client-Seite
Auf dieser Seite werden Metrikdiagramme von angezeigt Memcache Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
Memcache Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann Memcache-Fehler aufgetreten sind und wie viele Antworten der
Memcache-Client erhalten hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Client zu dem Zeitpunkt war, als
er die Fehler empfing.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät empfangen, wenn ich als Memcache-Client Fehler Die Anzahl der Fehler, die das Gerät hat empfangen, wenn ich als Memcache-Client - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der Memcache-Antworten, die der Client erhalten hat, und wie
viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät empfangen, wenn ich als Memcache-Client Fehler Die Anzahl der Fehler, die das Gerät hat empfangen, wenn ich als Memcache-Client - Treffer und Fehlschläge im Cache
- Dieses Diagramm zeigt Ihnen, wann Memcache-Treffer und Fehlschläge aufgetreten sind.
Metrisch Beschreibung Treffer Die Anzahl der übereinstimmenden Artikel und dass Gerät, das als Antwort auf GET-Anfragen empfangen wurde, wenn es als Memcache fungiert Client. Fehlschläge Die Anzahl der angeforderten Artikel, aber nicht wird als Antwort auf Get-Befehle empfangen, wenn das Gerät als Memcache-Client fungiert. Fehlschläge werden gezählt, auch wenn der Server den Client nicht ausdrücklich darüber informiert hat Miss (zum Beispiel, wenn das Get eine stille Anfrage war). - Gesamtzahl der Cache-Treffer und Fehlschläge
- Dieses Diagramm zeigt Ihnen die Gesamtzahl der aufgetretenen Memcache-Treffer und -Fehlschläge.
Metrisch Beschreibung Treffer Die Anzahl der übereinstimmenden Artikel und dass Gerät, das als Antwort auf GET-Anfragen empfangen wurde, wenn es als Memcache fungiert Client. Fehlschläge Die Anzahl der angeforderten Artikel, aber nicht wird als Antwort auf Get-Befehle empfangen, wenn das Gerät als Memcache-Client fungiert. Fehlschläge werden gezählt, auch wenn der Server den Client nicht ausdrücklich darüber informiert hat Miss (zum Beispiel, wenn das Get eine stille Anfrage war). - Leistungsübersicht (95. Perzentil)
- Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken. Die Zugriffszeit gibt an, wie lange
Server gebraucht haben, um Lese- oder Schreibvorgänge zu verarbeiten, die auf Blockdaten innerhalb einer Datei zugegriffen haben.
Die Zugriffszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte
Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der
folgenden Abbildung dargestellt:
Es kann schwierig sein, allein anhand der Zugriffszeit zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Metrik allein ein unvollständiges Bild liefert. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Zugriffszeiten sehen, aber die RTT niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn jedoch sowohl die RTT- als auch die Zugriffszeiten hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Zugriffszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
RTT misst nur, wie lange es dauert, bis eine sofortige Bestätigung gesendet wird; es wartet nicht, bis alle Pakete zugestellt sind. Daher ist RTT ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Zugriffszeiten sehen, aber die TCP-RTT niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Überprüfen Sie das Netzwerk auf Latenzprobleme, wenn sowohl die TCP-RTT- als auch die Zugriffszeiten stimmen.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Die Zugriffszeit kann hoch sein, weil der Server lange gebraucht hat, um die Antwort zu übertragen (möglicherweise, weil die Antwort sehr umfangreich war). Die Zugriffszeit kann jedoch auch hoch sein, weil die Antwort lange Zeit benötigt hat, bis die Antwort im Netzwerk übertragen wurde (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Zugriffszeit des Memcache-Clients Wenn das Gerät als Memcache fungiert client, die Zeit zwischen der Entdeckung des letzten Pakets des gesendeten Pakets durch das ExtraHop-System Anfrage und erstes Paket der empfangenen Antwort. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Memcache-Clients ein Paket, das eine sofortige Bestätigung erforderte und wann der Client das erhielt Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
- Wenn ein Client langsam reagiert, können Sie anhand von Leistungsübersichtsmetriken herausfinden
, ob das Netzwerk oder die Server das Problem verursachen. Die Leistungsübersichtsmetriken
zeigen die durchschnittliche Zeit, die Server für die Bearbeitung von Anfragen vom Client benötigten,
im Vergleich zur durchschnittlichen Zeit, die Pakete aus diesen Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten
. Hohe Serverzugriffszeiten deuten darauf hin, dass der Client
langsame Server kontaktiert. Hohe TCP-Roundtrip-Zeiten deuten darauf hin, dass der Client über langsame Netzwerke
kommuniziert.
Metrisch Beschreibung Zugriffszeit des Memcache-Clients Wenn das Gerät als Memcache fungiert client, die Zeit zwischen der Entdeckung des letzten Pakets des gesendeten Pakets durch das ExtraHop-System Anfrage und erstes Paket der empfangenen Antwort. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Memcache-Clients ein Paket, das eine sofortige Bestätigung erforderte und wann der Client das erhielt Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Memcache-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche Memcache-Methoden der Client am häufigsten aufgerufen hat, indem die Gesamtzahl der Anfragen, die der Client nach Methode gesendet hat, aufgeschlüsselt wird.
- Die wichtigsten Statuscodes
- Dieses Diagramm zeigt, welche Memcache-Statuscodes der Client am häufigsten erhalten hat, indem die Anzahl der an den Client zurückgegebenen Antworten nach Statuscode aufgeteilt wird.
- Häufigster Fehler
- Dieses Diagramm zeigt, welche Memcache-Fehler der Client am häufigsten erhalten hat, indem die Anzahl der irrtümlich an den Client zurückgegebenen Antworten aufgeschlüsselt wird.
Memcache-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serverzugriffszeit
- In diesem Diagramm werden die Zugriffszeiten in einem Histogramm dargestellt, um die häufigsten
Zugriffszeiten anzuzeigen.
Metrisch Beschreibung Zugriffszeit des Memcache-Clients Wenn das Gerät als Memcache fungiert client, die Zeit zwischen der Entdeckung des letzten Pakets des gesendeten Pakets durch das ExtraHop-System Anfrage und erstes Paket der empfangenen Antwort. - Serverzugriffszeit
- Dieses Diagramm zeigt die durchschnittliche Zugriffszeit für den Client.
Metrisch Beschreibung Zugriffszeit des Memcache-Clients Wenn das Gerät als Memcache fungiert client, die Zeit zwischen der Entdeckung des letzten Pakets des gesendeten Pakets durch das ExtraHop-System Anfrage und erstes Paket der empfangenen Antwort. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Memcache-Clients ein Paket, das eine sofortige Bestätigung erforderte und wann der Client das erhielt Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Hin- und Rückflugzeit für den Client.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Memcache-Clients ein Paket, das eine sofortige Bestätigung erforderte und wann der Client das erhielt Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Gesamtwerte der Memcache-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, sendet der Client möglicherweise mehr
Anfragen, als die Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen
, ob das Problem am Netzwerk oder am Server liegt, überprüfen Sie RTOs und Zero Windows in der
Netzwerk-Daten
Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Memcache-Anfragen und -Antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät gesendet hat wenn Sie als Memcache-Client agieren Antworten Die Anzahl der Antworten, die das Gerät empfangen, wenn ich als Memcache-Client Treffer Die Anzahl der übereinstimmenden Artikel und dass Gerät, das als Antwort auf GET-Anfragen empfangen wurde, wenn es als Memcache fungiert Client. Fehlschläge Die Anzahl der angeforderten Artikel, aber nicht wird als Antwort auf Get-Befehle empfangen, wenn das Gerät als Memcache-Client fungiert. Fehlschläge werden gezählt, auch wenn der Server den Client nicht ausdrücklich darüber informiert hat Miss (zum Beispiel, wenn das Get eine stille Anfrage war). Keine Antworten Die Anzahl der gesendeten Anfragen, für die ein Eine Antwort wurde nicht unbedingt erwartet, und es wurde keine empfangen, als das Gerät fungiert als Memcache-Client - Anfragen- und Antwortgrößen
- Dieses Diagramm zeigt die durchschnittliche Größe der Anfragen und Antworten.
Metrisch Beschreibung Größe der Anfrage Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät gesendet hat, als es als Memcache-Client agiert Größe der Antwort Die Verteilung der Größen (in Byte) von Antworten, die das Gerät erhalten hat, als es als Memcache-Client agiert
Memcache-Serverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt Memcache Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
Memcache Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann Memcache-Fehler aufgetreten sind und wie viele Memcache-Antworten der
Server gesendet hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Server zu dem Zeitpunkt war, als er die Fehler
zurückgab.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn Sie als Memcache-Server agieren Fehler Die Anzahl der Fehler, die das Gerät hat wird gesendet, wenn es als Memcache-Server fungiert - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der Memcache-Antworten, die der Server gesendet hat, und wie
viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn Sie als Memcache-Server agieren Fehler Die Anzahl der Fehler, die das Gerät hat wird gesendet, wenn es als Memcache-Server fungiert - Treffer und Fehlschläge im Cache
- Dieses Diagramm zeigt Ihnen, wann Memcache-Treffer und Fehlschläge aufgetreten sind.
Metrisch Beschreibung Treffer Die Anzahl der übereinstimmenden Artikel und dass Gerät, das als Antwort auf GET-Anfragen gesendet wird, wenn es als Memcache fungiert Server. Fehlschläge Die Anzahl der angeforderten, aber nicht gesendeten Artikel als Reaktion auf Get-Befehle, wenn das Gerät als Memcache-Server fungiert. Fehlschüsse werden gezählt, auch wenn der Server den Client nicht explizit über den Fehlschlag informiert hat (für Beispiel, wenn das Abrufen eine stille Anfrage war). - Gesamtzahl der Cache-Treffer und Fehlschläge
- Dieses Diagramm zeigt Ihnen die Gesamtzahl der aufgetretenen Memcache-Treffer und -Fehlschläge.
Metrisch Beschreibung Treffer Die Anzahl der übereinstimmenden Artikel und dass Gerät, das als Antwort auf GET-Anfragen gesendet wird, wenn es als Memcache fungiert Server. Fehlschläge Die Anzahl der angeforderten, aber nicht gesendeten Artikel als Reaktion auf Get-Befehle, wenn das Gerät als Memcache-Server fungiert. Fehlschüsse werden gezählt, auch wenn der Server den Client nicht explizit über den Fehlschlag informiert hat (für Beispiel, wenn das Abrufen eine stille Anfrage war). - Leistungsübersicht (95. Perzentil)
- Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken. Die Zugriffszeit gibt an, wie lange
Server gebraucht haben, um Lese- oder Schreibvorgänge zu verarbeiten, die auf Blockdaten innerhalb einer Datei zugegriffen haben.
Die Zugriffszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte
Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der
folgenden Abbildung dargestellt:
Es kann schwierig sein, allein anhand der Zugriffszeit zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Metrik allein ein unvollständiges Bild liefert. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Zugriffszeiten sehen, aber die RTT niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn jedoch sowohl die RTT- als auch die Zugriffszeiten hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Zugriffszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
RTT misst nur, wie lange es dauert, bis eine sofortige Bestätigung gesendet wird; es wartet nicht, bis alle Pakete zugestellt sind. Daher ist RTT ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Zugriffszeiten sehen, aber die TCP-RTT niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Überprüfen Sie das Netzwerk auf Latenzprobleme, wenn sowohl die TCP-RTT- als auch die Zugriffszeiten stimmen.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Die Zugriffszeit kann hoch sein, weil der Server lange gebraucht hat, um die Antwort zu übertragen (möglicherweise, weil die Antwort sehr umfangreich war). Die Zugriffszeit kann jedoch auch hoch sein, weil die Antwort lange Zeit benötigt hat, bis die Antwort im Netzwerk übertragen wurde (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Zugriffszeit des Memcache-Servers Wenn das Gerät als Memcache-Server, die Zeit zwischen der Entdeckung des letzten Paket von durch das ExtraHop-System die empfangene Anfrage und das erste Paket der gesendeten Antwort. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Memcache-Servers ein Paket, das eine sofortige Bestätigung erforderte und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
- Wenn ein Server langsam reagiert, können Sie anhand von Leistungsübersichtsmetriken herausfinden
, ob das Problem vom Netzwerk oder vom Server verursacht wird. Die Leistungsübersichtsmetriken
zeigen die durchschnittliche Zeit, die der Server für die Bearbeitung von Anfragen von Clients benötigte,
im Vergleich zur durchschnittlichen Zeit, die Pakete aus diesen Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten
. Hohe Serverzugriffszeiten deuten darauf hin, dass der Server langsam
ist. Hohe RTTs weisen darauf hin, dass der Server über langsame Netzwerke kommuniziert.
Metrisch Beschreibung Zugriffszeit des Memcache-Servers Wenn das Gerät als Memcache-Server, die Zeit zwischen der Entdeckung des letzten Paket von durch das ExtraHop-System die empfangene Anfrage und das erste Paket der gesendeten Antwort. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Memcache-Servers ein Paket, das eine sofortige Bestätigung erforderte und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Memcache-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche Memcache-Methoden auf dem Server am häufigsten aufgerufen wurden, indem die Gesamtzahl der Anfragen, die der Server erhalten hat, nach Methode aufgeteilt wird.
- Die wichtigsten Statuscodes
- Dieses Diagramm zeigt, welche Memcache-Statuscodes der Server am häufigsten zurückgegeben hat, indem die Gesamtzahl der vom Server gesendeten Antworten nach Statuscode aufgeschlüsselt wird.
- Häufigster Fehler
- Dieses Diagramm zeigt, welche Memcache-Fehler der Server am häufigsten zurückgegeben hat, indem die Anzahl der Antworten, die der Server fehlerhaft zurückgegeben hat, aufgeschlüsselt wird.
Memcache-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serverzugriffszeit
- In diesem Diagramm werden die Zugriffszeiten in einem Histogramm dargestellt, um die häufigsten
Zugriffszeiten anzuzeigen.
Metrisch Beschreibung Zugriffszeit des Memcache-Servers Wenn das Gerät als Memcache-Server, die Zeit zwischen der Entdeckung des letzten Paket von durch das ExtraHop-System die empfangene Anfrage und das erste Paket der gesendeten Antwort. - Serverzugriffszeit
- Dieses Diagramm zeigt die durchschnittliche Zugriffszeit für den Client.
Metrisch Beschreibung Zugriffszeit des Memcache-Servers Wenn das Gerät als Memcache-Server, die Zeit zwischen der Entdeckung des letzten Paket von durch das ExtraHop-System die empfangene Anfrage und das erste Paket der gesendeten Antwort. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Memcache-Servers ein Paket, das eine sofortige Bestätigung erforderte und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Roundtrip-Zeit für den Server.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Memcache-Servers ein Paket, das eine sofortige Bestätigung erforderte und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Gesamtwerte der Memcache-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr
Anfragen, als der Server verarbeiten kann, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen
, ob das Problem am Netzwerk oder am Server liegt, überprüfen Sie RTOs und Zero Windows in der
Netzwerk-Daten
Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Memcache-Anfragen und -Antworten exakt gleich ist, selbst in einer fehlerfreien Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät empfangen, wenn er als Memcache-Server fungiert Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn Sie als Memcache-Server agieren Treffer Die Anzahl der übereinstimmenden Artikel und dass Gerät, das als Antwort auf GET-Anfragen gesendet wird, wenn es als Memcache fungiert Server. Fehlschläge Die Anzahl der angeforderten, aber nicht gesendeten Artikel als Reaktion auf Get-Befehle, wenn das Gerät als Memcache-Server fungiert. Fehlschüsse werden gezählt, auch wenn der Server den Client nicht explizit über den Fehlschlag informiert hat (für Beispiel, wenn das Abrufen eine stille Anfrage war). Keine Antworten Die Anzahl der gesendeten Anfragen, für die ein Eine Antwort wurde nicht unbedingt erwartet, und es wurde keine empfangen, als das Gerät fungiert als Memcache-Server - Anfragen- und Antwortgrößen
- Dieses Diagramm zeigt die durchschnittliche Größe der Anfragen und Antworten.
Metrisch Beschreibung Größe der Anfrage Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät empfangen hat, als es als Memcache-Server fungiert Größe der Antwort Die Verteilung der Größen (in Byte) von Antworten, die das Gerät gesendet hat, als es als Memcache-Server fungierte
Memcache-Client-Gruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt Memcache Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
Memcache Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann Memcache-Fehler aufgetreten sind und wie viele Antworten die
Memcache-Clients erhalten haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Kunden zu dem
Zeitpunkt waren, als sie die Fehler erhielten.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie im Abschnitt Memcache-Metriken für Gruppen.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät empfangen, wenn ich als Memcache-Client Fehler Die Anzahl der Fehler, die das Gerät hat empfangen, wenn ich als Memcache-Client - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele Memcache-Antworten die Clients erhalten haben und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät empfangen, wenn ich als Memcache-Client Fehler Die Anzahl der Fehler, die das Gerät hat empfangen, wenn ich als Memcache-Client
Memcache-Details für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (Memcache-Clients)
- Dieses Diagramm zeigt, welche Memcache-Clients in der Gruppe am aktivsten waren, indem es die Gesamtzahl der Memcache-Anfragen aufschlüsselt, die die Gruppe vom Client gesendet hat.
- Die besten Methoden
- Dieses Diagramm zeigt, welche Memcache-Methoden die Gruppe am häufigsten aufgerufen hat, indem die Gesamtzahl der Anfragen, die die Gruppe nach Methode gesendet hat, aufgeschlüsselt wird.
- Die wichtigsten Statuscodes
- Dieses Diagramm zeigt, welche Memcache-Statuscodes die Gruppe am häufigsten erhalten hat, indem die Anzahl der an die Gruppe zurückgegebenen Antworten nach Statuscode aufgeschlüsselt wird.
Memcache-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden die Clients möglicherweise mehr Anfragen, als Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät gesendet hat wenn Sie als Memcache-Client agieren Antworten Die Anzahl der Antworten, die das Gerät empfangen, wenn ich als Memcache-Client Treffer Die Anzahl der übereinstimmenden Artikel und dass Gerät, das als Antwort auf GET-Anfragen empfangen wurde, wenn es als Memcache fungiert Client. Fehlschläge Die Anzahl der angeforderten Artikel, aber nicht wird als Antwort auf Get-Befehle empfangen, wenn das Gerät als Memcache-Client fungiert. Fehlschläge werden gezählt, auch wenn der Server den Client nicht ausdrücklich darüber informiert hat Miss (zum Beispiel, wenn das Get eine stille Anfrage war). Keine Antworten Die Anzahl der gesendeten Anfragen, für die ein Eine Antwort wurde nicht unbedingt erwartet, und es wurde keine empfangen, als das Gerät fungiert als Memcache-Client - Zeit des Zugriffs
- Wenn sich eine Client-Gruppe langsam verhält, können Sie anhand der Zugriffszeit herausfinden, ob das
Problem bei den Servern liegt. Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche
Zeit, die Server für die Bearbeitung von Anfragen von den Clients benötigten. Hohe Zugriffszeiten deuten darauf hin, dass
die Clients langsame Server kontaktieren.
Metrisch Beschreibung Zugriffszeit des Memcache-Clients Wenn das Gerät als Memcache fungiert client, die Zeit zwischen der Entdeckung des letzten Pakets des gesendeten Pakets durch das ExtraHop-System Anfrage und erstes Paket der empfangenen Antwort.
Memcache-Servergruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt Memcache Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
Memcache Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann Memcache-Fehler aufgetreten sind und wie viele Memcache-Antworten die
Server gesendet haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Server zu dem Zeitpunkt waren, als
sie die Fehler gemeldet haben.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie im Abschnitt Memcache-Metriken für Gruppen.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn Sie als Memcache-Server agieren Fehler Die Anzahl der Fehler, die das Gerät hat wird gesendet, wenn es als Memcache-Server fungiert - Transaktionen insgesamt
- Dieses Diagramm zeigt, wie viele Memcache-Antwortserver in der Gruppe gesendet haben und wie
viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn Sie als Memcache-Server agieren Fehler Die Anzahl der Fehler, die das Gerät hat wird gesendet, wenn es als Memcache-Server fungiert
Memcache-Details für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (Memcache-Server)
- Dieses Diagramm zeigt, welche Memcache-Server in der Gruppe am aktivsten waren, indem die Gesamtzahl der Memcache-Antworten, die die Gruppe vom Server gesendet hat, aufgeschlüsselt wird.
- Die besten Methoden
- Dieses Diagramm zeigt, welche Memcache-Methoden auf Servern in der Gruppe am häufigsten aufgerufen wurden, indem die Gesamtzahl der Anfragen, die die Gruppe erhalten hat, nach Methode aufgeteilt wird.
- Oberster Statuscode
- Dieses Diagramm zeigt, welche Memcache-Statuscodes die Gruppen am häufigsten zurückgegeben haben, indem die Gesamtzahl der von der Gruppe gesendeten Antworten nach Statuscode aufgeschlüsselt wird.
Memcache-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden Clients möglicherweise mehr Anfragen, als die Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät empfangen, wenn er als Memcache-Server fungiert Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn Sie als Memcache-Server agieren Treffer Die Anzahl der übereinstimmenden Artikel und dass Gerät, das als Antwort auf GET-Anfragen gesendet wird, wenn es als Memcache fungiert Server. Fehlschläge Die Anzahl der angeforderten, aber nicht gesendeten Artikel als Reaktion auf Get-Befehle, wenn das Gerät als Memcache-Server fungiert. Fehlschüsse werden gezählt, auch wenn der Server den Client nicht explizit über den Fehlschlag informiert hat (für Beispiel, wenn das Abrufen eine stille Anfrage war). Keine Antworten Die Anzahl der gesendeten Anfragen, für die ein Eine Antwort wurde nicht unbedingt erwartet, und es wurde keine empfangen, als das Gerät fungiert als Memcache-Server - Zeit des Zugriffs
- Wenn sich eine Client-Gruppe langsam verhält, können Sie anhand der Zugriffszeit herausfinden, ob das
Problem bei den Servern liegt. Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche
Zeit, die Server für die Bearbeitung von Anfragen von den Clients benötigten. Hohe Zugriffszeiten deuten darauf hin, dass
die Clients langsame Server kontaktieren.
Metrisch Beschreibung Zugriffszeit des Memcache-Servers Wenn das Gerät als Memcache-Server, die Zeit zwischen der Entdeckung des letzten Paket von durch das ExtraHop-System die empfangene Anfrage und das erste Paket der gesendeten Antwort.
Modbus
Das ExtraHop-System sammelt Metriken über die Modbus-Aktivität. Modbus ist ein serielles Kommunikationsprotokoll, das in industriellen Automatisierungsumgebungen Standard ist.
| Hinweis: | Das ExtraHop-System enthält keine integrierten Metrikseiten für Modbus. Sie können Modbus-Metriken jedoch anzeigen, indem Sie sie zu einer benutzerdefinierten Seite hinzufügen oder Dashboard. |
MongoDB
Das ExtraHop-System sammelt Metriken über MongoDB Aktivität. MongoDB ist eine Open-Source-Dokumentendatenbank, die Leistung, Verfügbarkeit und Skalierbarkeit bietet.
MongoDB-Anwendungsseite
Auf dieser Seite werden Metrikdiagramme von angezeigt MongoDB Verkehr, der mit einem Anwendungscontainer in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
MongoDB Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann MongoDB-Fehler und -Antworten mit der
Anwendung verknüpft waren. Anhand dieser Informationen können Sie feststellen, wie aktiv die Anwendung zum
Zeitpunkt des Auftretens der Fehler war.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der MongoDB-Antworten. Fehler Die Anzahl der MongoDB-Antworten Fehler. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der MongoDB-Antworten, die mit
der Anwendung verknüpft waren, und wie viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der MongoDB-Antworten. Fehler Die Anzahl der MongoDB-Antworten Fehler. - Leistung (95. Perzentil)
-
Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken.
Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer vollständigen
Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange Clients gebraucht haben, um Anfragen an
das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange die Server für die Bearbeitung von Anfragen gebraucht haben;
und die Antwortübertragungszeit zeigt, wie lange die Server gebraucht haben, um Antworten an
das Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Transferzeit anfragen Die Zeit zwischen dem ExtraHop-System Erkennen des ersten Paket und des letzten Paket von MongoDB-Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit des Servers Die Zeit zwischen dem ExtraHop-System Erkennung des letzten Paket von MongoDB-Anfragen und des ersten Paket ihrer entsprechende Antworten. Übertragungszeit der Antwort Die Zeit zwischen dem ExtraHop-System Erkennen des ersten Paket und des letzten Paket von MongoDB-Antworten. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Zeitpunkt, an dem ein MongoDB-Client oder Server hat ein Paket gesendet, das eine sofortige Bestätigung erfordert, und wann die Bestätigung erfolgte erhalten. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn eine Anwendung langsam reagiert, können Sie anhand
von Leistungsübersichtsmetriken herausfinden, ob das Netzwerk oder die Server das
Problem verursachen. Diese Metriken zeigen das 95. Perzentil der Zeit, die Server für die Bearbeitung von
Anfragen von Clients benötigten, im Vergleich zum 95. Perzentil der Zeit, die Pakete aus diesen Anfragen
(und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten. Hohe
Serververarbeitungszeiten deuten darauf hin, dass Clients langsame Server kontaktieren. Hohe
TCP-Roundtrip-Zeiten deuten darauf hin, dass Clients über langsame Netzwerke kommunizieren.
Metrisch Beschreibung Verarbeitungszeit des Servers Die Zeit zwischen dem ExtraHop-System Erkennung des letzten Paket von MongoDB-Anfragen und des ersten Paket ihrer entsprechende Antworten. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Zeitpunkt, an dem ein MongoDB-Client oder Server hat ein Paket gesendet, das eine sofortige Bestätigung erfordert, und wann die Bestätigung erfolgte erhalten.
MongoDB Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche MongoDB-Methoden mit der Anwendung verknüpft waren, indem die Gesamtzahl der MongoDB-Anfragen nach Methoden aufgeschlüsselt wird.
- Die häufigsten Fehlertypen
- Dieses Diagramm zeigt, welche MongoDB-Fehler am häufigsten mit der Anwendung in Verbindung gebracht wurden, indem die Anzahl der Antworten nach Fehlern aufgeschlüsselt wird.
- Die besten Datenbanken
- Dieses Diagramm zeigt, auf welche Datenbanken die Anwendung am häufigsten zugegriffen hat, indem die Gesamtzahl der Anfragen, die die Anwendung per Datenbank gesendet hat, aufgeschlüsselt wird.
MongoDB-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des MongoDB-Servers Die Zeit zwischen dem ExtraHop-System Erkennung des letzten Paket von MongoDB-Anfragen und des ersten Paket ihrer entsprechende Antworten. - Verarbeitungszeit des Servers
-
Diese Tabelle zeigt die durchschnittliche Bearbeitungszeit für den Anwendung.
Metrisch Beschreibung Verarbeitungszeit des MongoDB-Servers Die Zeit zwischen dem ExtraHop-System Erkennung des letzten Paket von MongoDB-Anfragen und des ersten Paket ihrer entsprechende Antworten. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Zeitpunkt, an dem ein MongoDB-Client oder Server hat ein Paket gesendet, das eine sofortige Bestätigung erfordert, und wann die Bestätigung erfolgte erhalten. - Zeit für Hin- und Rückfahrt
-
Diese Tabelle zeigt
die durchschnittliche Hin- und Rückflugzeit für die Anwendung.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Zeitpunkt, an dem ein MongoDB-Client oder Server hat ein Paket gesendet, das eine sofortige Bestätigung erfordert, und wann die Bestätigung erfolgte erhalten.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass ein Problem mit einem Server oder einem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
-
Dieses Diagramm zeigt die Anzahl der Nullfenster, die einer Anwendung
zugeordnet waren. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der Pakete
angeben, die über einen bestimmten Zeitraum an sie gesendet werden können.
Wenn an ein Gerät mehr Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein
Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig einzustellen, bis das Gerät den Vorgang
aufholt. Wenn Sie eine große Anzahl von Nullfenstern sehen, ist ein Server oder Client möglicherweise
nicht schnell genug, um die empfangene Datenmenge zu unterstützen.
Metrisch Definition Zero Windows anfordern Die Anzahl der gesendeten Null-Window-Anzeigen von MongoDB-Kunden. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl eingehender Zero-Windows weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Antwort Null Windows Die Anzahl der gesendeten Null-Window-Anzeigen von Servern beim Empfang von MongoDB-Anfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von ausgehenden Zero-Windows weist darauf hin, dass ein Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Gesamtzahl der Host-Stände
- Dieses Diagramm zeigt die durchschnittliche Anzahl von Zero-Window-Werbeanzeigen, die von Geräten gesendet wurden.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen
Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu
viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät
eine Anfrage oder Antwort sendet und innerhalb einer bestimmten
Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen
nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise
zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der verursachten Timeouts bei der erneuten Übertragung durch Überlastung, als Clients MongoDB-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Timeouts bei der erneuten Übertragung durch Überlastung, als Server MongoDB-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
- Gesamtzahl der Netzwerkausfälle
-
Dieses Diagramm zeigt die durchschnittliche Anzahl von Timeouts bei der
erneuten Übertragung, die durch Überlastung beim Senden von Anfragen durch Clients und Server verursacht wurden.
Metrisch Definition RTOs Ein Die Anzahl der verursachten Timeouts bei der erneuten Übertragung durch Überlastung, als Clients MongoDB-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Timeouts bei der erneuten Übertragung durch Überlastung, als Server MongoDB-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Metrische Gesamtwerte für MongoDB
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr Anfragen, als Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um herauszufinden, ob das Problem mit dem Netzwerk oder einem Server zusammenhängt, überprüfen Sie RTOs und Zero Windows in Netzwerk-Daten Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der MongoDB-Anfragen und -Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der MongoDB-Anfragen. Antworten Die Anzahl der MongoDB-Antworten. Fehler Die Anzahl der MongoDB-Antworten Fehler. - MongoDB-Netzwerkmetriken
-
Metrisch Beschreibung Zero Windows anfordern Die Anzahl der gesendeten Null-Window-Anzeigen von MongoDB-Kunden. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Antwort Null Windows Die Anzahl der gesendeten Null-Window-Anzeigen von Servern beim Empfang von MongoDB-Anfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. RTOs anfragen Die Anzahl der verursachten Timeouts bei der erneuten Übertragung durch Überlastung, als Clients MongoDB-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Antwort-RTOs Die Anzahl der verursachten Timeouts bei der erneuten Übertragung durch Überlastung, als Server MongoDB-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. L2-Byte anfordern Die Anzahl der L2-Bytes, die mit verknüpft sind MongoDB-Anfragen Antwort L2 Byte Die Anzahl der L2-Bytes, die mit verknüpft sind MongoDB-Antworten Goodput Bytes anfordern Die Anzahl der Goodput-Bytes, die mit verknüpft sind MongoDB-Anfragen. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Antwort Goodput Bytes Die Anzahl der Goodput-Bytes, die mit verknüpft sind MongoDB-Antworten. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Pakete anfordern Die Anzahl der mit MongoDB verknüpften Pakete Anfragen. Antwortpakete Die Anzahl der mit MongoDB verknüpften Pakete Antworten.
MongoDB-Clientseite
Auf dieser Seite werden Metrikdiagramme von angezeigt MongoDB Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
MongoDB Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann MongoDB-Fehler aufgetreten sind und wie viele Antworten der
MongoDB-Client erhalten hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Client zu dem Zeitpunkt war, als
er die Fehler empfing.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie sich Details zu jedem Fehler anzeigen lassen, einschließlich des Fehlercodes. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von Anfragen zu Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Hinweis: Um zu sehen, welche Fehlercodes der Client erhalten hat, klicken Sie Fehler und wähle Fehler aus der Speisekarte. Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als MongoDB-Client agieren Fehler Die Anzahl der Fehler, die das Gerät hat empfangen, als ich als MongoDB-Client - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der MongoDB-Antworten, die der Client erhalten hat, und wie
viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als MongoDB-Client agieren Fehler Die Anzahl der Fehler, die das Gerät hat empfangen, als ich als MongoDB-Client - Leistungsübersicht (95. Perzentil)
-
Dieses Diagramm zeigt das
95. Perzentil der Timing-Metriken. Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer
vollständigen Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange der Client gebraucht hat, um
Anfragen an das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange Server gebraucht haben, um
die Anfragen zu verarbeiten; und die Antwortübertragungszeit zeigt, wie lange Server gebraucht haben, um
Antworten an das Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Übertragungszeit der Mongo-Client-Anfrage Wenn das Gerät als MongoDB fungiert client, die Zeit zwischen der Entdeckung des ersten und des letzten Paket durch das ExtraHop-System Paket gesendeter Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit des MongoDB-Clientservers Wenn das Gerät als MongoDB fungiert client, die Zeit zwischen der Entdeckung des letzten Pakets des gesendeten Pakets durch das ExtraHop-System Anfrage und das erste Paket der empfangenen Antwort. Übertragungszeit der MongoDB-Client-Antwort Wenn das Gerät als MongoDB fungiert client, die Zeit zwischen der Entdeckung des ersten und des letzten Paket durch das ExtraHop-System Paket der empfangenen Antworten. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines MongoDB-Clients Paket, für das eine sofortige Bestätigung erforderlich war und wann der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn ein Client langsam reagiert, können Sie
anhand von Leistungsübersichtsmetriken herausfinden, ob das Netzwerk oder die Server das Problem verursachen.
Diese Metriken zeigen das 95. Perzentil der Zeit, die Server für die Bearbeitung von
Anfragen vom Client benötigten, im Vergleich zur 95. Perzentilzeit, die Pakete aus diesen
Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten.
Hohe Serververarbeitungszeiten deuten darauf hin, dass der Client langsame Server kontaktiert. Hohe
TCP-Roundtrip-Zeiten deuten darauf hin, dass der Client über langsame
Netzwerke kommuniziert.
Metrisch Beschreibung Verarbeitungszeit des MongoDB-Clientservers Wenn das Gerät als MongoDB fungiert client, die Zeit zwischen der Entdeckung des letzten Pakets des gesendeten Pakets durch das ExtraHop-System Anfrage und das erste Paket der empfangenen Antwort. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines MongoDB-Clients Paket, für das eine sofortige Bestätigung erforderlich war und wann der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
MongoDB Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche MongoDB-Methoden der Client am häufigsten aufgerufen hat, indem die Gesamtzahl der Anfragen, die der Client nach Methode gesendet hat, aufgeschlüsselt wird.
- Die besten Datenbanken
- Dieses Diagramm zeigt, auf welche Datenbanken der Client am häufigsten zugegriffen hat, indem die Gesamtzahl der vom Client gesendeten Anfragen pro Datenbank aufgeschlüsselt wird.
- Die häufigsten Fehler
- Dieses Diagramm zeigt, welche MongoDB-Fehler der Client am häufigsten erhalten hat, indem die Anzahl der irrtümlich an den Client zurückgegebenen Antworten aufgeteilt wird.
MongoDB-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Aufschlüsselung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des MongoDB-Clientservers Wenn das Gerät als MongoDB fungiert client, die Zeit zwischen der Entdeckung des letzten Pakets des gesendeten Pakets durch das ExtraHop-System Anfrage und das erste Paket der empfangenen Antwort. - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Bearbeitungszeit für den Client.
Metrisch Beschreibung Verarbeitungszeit des MongoDB-Clientservers Wenn das Gerät als MongoDB fungiert client, die Zeit zwischen der Entdeckung des letzten Pakets des gesendeten Pakets durch das ExtraHop-System Anfrage und das erste Paket der empfangenen Antwort. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines MongoDB-Clients Paket, für das eine sofortige Bestätigung erforderlich war und wann der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Hin- und Rückflugzeit für den Client.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines MongoDB-Clients Paket, für das eine sofortige Bestätigung erforderlich war und wann der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Metrische Gesamtwerte für MongoDB
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Anfragen und Antworten
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, sendet der Client möglicherweise mehr
Anfragen, als die Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen
, ob das Problem beim Netzwerk oder beim Server liegt, überprüfen Sie RTOs und Zero Windows in der
Netzwerk-Daten
Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der MongoDB-Anfragen und -Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät gesendet hat, als fungiert als MongoDB-Client Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als MongoDB-Client agieren Abgebrochene Anfragen Die Anzahl der Anfragen, die diese MongoDB Der Client begann zu senden, sendete aber nicht vollständig, da die Verbindung abrupt geschlossen. Abgebrochene Antworten Die Anzahl der Anfragen, die diese MongoDB Der Client begann zu senden, sendete aber nicht vollständig, da die Verbindung abrupt geschlossen. Fehler Die Anzahl der Fehler, die das Gerät hat empfangen, als ich als MongoDB-Client - Anfragen- und Antwortgrößen
- Dieses Diagramm zeigt die durchschnittliche Größe der Anfragen und Antworten.
Metrisch Beschreibung Größe der Anfrage Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät gesendet hat, als es als MongoDB-Client fungiert Größe der Antwort Die Verteilung der Größen (in Byte) von Antworten, die das Gerät erhalten hat, als es als MongoDB-Client agiert
MongoDB-Serverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt MongoDB Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
MongoDB Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann MongoDB-Fehler aufgetreten sind und wie viele MongoDB-Antworten der
Server gesendet hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Server zu dem Zeitpunkt war, als er die Fehler
zurückgab.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie sich Details zu jedem Fehler anzeigen lassen, einschließlich des Fehlercodes. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von Anfragen zu Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Hinweis: Um zu sehen, welche Fehlercodes der Client erhalten hat, klicken Sie Fehler und wähle Fehler aus der Speisekarte. Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn er als MongoDB-Server fungiert Fehler Die Anzahl der Fehler, die das Gerät gesendet hat wenn er als MongoDB-Server fungiert - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der MongoDB-Antworten, die der Server gesendet hat, und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn er als MongoDB-Server fungiert Fehler Die Anzahl der Fehler, die das Gerät gesendet hat wenn er als MongoDB-Server fungiert - Leistungsübersicht (95. Perzentil)
-
Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken
. Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer vollständigen
Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange Clients gebraucht haben, um Anfragen an
das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange der Server gebraucht hat, um Anfragen zu verarbeiten;
und die Antwortübertragungszeit zeigt, wie lange der Server gebraucht hat, um Antworten an das
Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Übertragungszeit der Mongo-Serveranfrage Wenn das Gerät als MongoDB fungiert Server, die Zeit zwischen der Entdeckung des ersten und des letzten Paket durch das ExtraHop-System Paket eingegangener Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit des MongoDB-Servers Wenn das Gerät als MongoDB fungiert Server, die Zeit zwischen der Entdeckung des letzten Paket durch das ExtraHop-System empfangene Anfrage und erstes Paket der gesendeten Antwort. Übertragungszeit der Antwort des MongoDB-Servers Wenn das Gerät als MongoDB fungiert Server, die Zeit zwischen der Entdeckung des ersten und des letzten Paket durch das ExtraHop-System Paket gesendeter Antworten. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines MongoDB-Servers Paket, das eine sofortige Bestätigung erforderte und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn ein Server langsam reagiert, können Sie
anhand von Leistungsübersichtsmetriken herausfinden, ob das
Problem vom Netzwerk oder vom Server verursacht wird. Die Leistungsübersichtsmetriken zeigen das 95. Perzentil der Zeit, die der
Server für die Verarbeitung von Anfragen von Clients benötigte, im Vergleich zur 95. Perzentilzeit, die
Pakete aus diesen Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten.
Hohe Serververarbeitungszeiten deuten darauf hin, dass der Server langsam ist.
Hohe RTTs weisen darauf hin, dass der Server über langsame Netzwerke kommuniziert.
Metrisch Beschreibung Verarbeitungszeit des MongoDB-Servers Wenn das Gerät als MongoDB fungiert Server, die Zeit zwischen der Entdeckung des letzten Paket durch das ExtraHop-System empfangene Anfrage und erstes Paket der gesendeten Antwort. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines MongoDB-Servers Paket, das eine sofortige Bestätigung erforderte und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
MongoDB Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche MongoDB-Methoden auf dem Server am häufigsten aufgerufen wurden, indem die Gesamtzahl der Anfragen, die der Server nach Methode erhalten hat, aufgeschlüsselt wird.
- Die besten Datenbanken
- Dieses Diagramm zeigt, auf welche Datenbanken auf dem Server am häufigsten zugegriffen wurde, indem die Gesamtzahl der vom Server gesendeten Antworten pro Datenbank aufgeschlüsselt wird.
- Die häufigsten Fehler
- Dieses Diagramm zeigt, welche MongoDB-Fehler der Server am häufigsten zurückgegeben hat, indem die Anzahl der Antworten, die der Server fehlerhaft zurückgegeben hat, aufgeschlüsselt wird.
MongoDB-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Aufschlüsselung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des MongoDB-Servers Wenn das Gerät als MongoDB fungiert Server, die Zeit zwischen der Entdeckung des letzten Paket durch das ExtraHop-System empfangene Anfrage und erstes Paket der gesendeten Antwort. - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Verarbeitungszeit für den Server.
Metrisch Beschreibung Verarbeitungszeit des MongoDB-Servers Wenn das Gerät als MongoDB fungiert Server, die Zeit zwischen der Entdeckung des letzten Paket durch das ExtraHop-System empfangene Anfrage und erstes Paket der gesendeten Antwort. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines MongoDB-Servers Paket, das eine sofortige Bestätigung erforderte und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Roundtrip-Zeit für den Server.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines MongoDB-Servers Paket, das eine sofortige Bestätigung erforderte und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Metrische Gesamtwerte für MongoDB
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Anfragen und Antworten
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr
Anfragen, als der Server verarbeiten kann, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen
, ob das Problem beim Netzwerk oder beim Server liegt, überprüfen Sie RTOs und Zero Windows in der
Netzwerk-Daten
Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der MongoDB-Anfragen und -Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät erhalten hat wenn er als MongoDB-Server fungiert Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn er als MongoDB-Server fungiert Abgebrochene Anfragen Die Anzahl der Anfragen, die diese MongoDB stellt Der Server begann zu empfangen, empfing aber nicht vollständig, da die Verbindung abrupt geschlossen. Abgebrochene Antworten Die Anzahl der Anfragen, die diese MongoDB stellt Der Server begann zu empfangen, empfing aber nicht vollständig, da die Verbindung abrupt geschlossen. Fehler Die Anzahl der Fehler, die das Gerät gesendet hat wenn er als MongoDB-Server fungiert - Anfragen- und Antwortgrößen
- Dieses Diagramm zeigt die durchschnittliche Größe der Anfragen und Antworten.
Metrisch Beschreibung Größe der Anfrage Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät empfangen hat, als es als MongoDB-Server fungiert Größe der Antwort Die Verteilung der Größen (in Byte) von Antworten, die das Gerät gesendet hat, als es als MongoDB-Server fungiert
MongoDB-Clientgruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt MongoDB Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
MongoDB Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann MongoDB-Fehler aufgetreten sind und wie viele Antworten die
MongoDB-Clients erhalten haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Kunden zu dem
Zeitpunkt waren, als sie die Fehler erhielten.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie sich Details zu jedem Fehler anzeigen lassen, einschließlich des Fehlercodes. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von MongoDB-Anfragen zu MongoDB-Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie in der Tabelle MongoDB-Metriken für Gruppen.
Hinweis: Um zu sehen, welche Fehlercodes der Client erhalten hat, klicken Sie Fehler und wähle Fehler aus der Speisekarte. Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als MongoDB-Client agieren Fehler Die Anzahl der Fehler, die das Gerät hat empfangen, als ich als MongoDB-Client - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele MongoDB-Antworten die Clients erhalten haben und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als MongoDB-Client agieren Fehler Die Anzahl der Fehler, die das Gerät hat empfangen, als ich als MongoDB-Client
MongoDB-Details für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (MongoDB-Clients)
- Dieses Diagramm zeigt, welche MongoDB-Clients in der Gruppe am aktivsten waren, indem es die Gesamtzahl der MongoDB-Anfragen aufschlüsselt, die die Gruppe vom Client gesendet hat.
- Die besten Methoden
- Dieses Diagramm zeigt, welche MongoDB-Methoden die Gruppe am häufigsten aufgerufen hat, indem die Gesamtzahl der Anfragen, die die Gruppe nach Methode gesendet hat, aufgeschlüsselt wird.
- Die häufigsten Fehler
- Dieses Diagramm zeigt, welche MongoDB-Fehler die Gruppe am häufigsten erhalten hat, indem die Anzahl der Antworten, die fehlerhaft an die Gruppe zurückgegeben wurden, aufgeschlüsselt wird.
MongoDB-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden die Clients möglicherweise mehr Anfragen, als Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät gesendet hat, als fungiert als MongoDB-Client Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als MongoDB-Client agieren Abgebrochene Anfragen Die Anzahl der Anfragen, die diese MongoDB Der Client begann zu senden, sendete aber nicht vollständig, da die Verbindung abrupt geschlossen. Abgebrochene Antworten Die Anzahl der Anfragen, die diese MongoDB Der Client begann zu senden, sendete aber nicht vollständig, da die Verbindung abrupt geschlossen. Fehler Die Anzahl der Fehler, die das Gerät hat empfangen, als ich als MongoDB-Client - Verarbeitungszeit des Servers
-
Wenn sich eine Client-Gruppe langsam verhält, können Sie anhand der Serververarbeitungszeit herausfinden,
ob das Problem bei den Servern liegt. Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche
Zeit, die Server für die Bearbeitung von Anfragen von den Clients benötigten. Hohe
Serververarbeitungszeiten deuten darauf hin, dass die Clients langsame Server kontaktieren.
Metrisch Beschreibung Verarbeitungszeit des MongoDB-Clientservers Wenn das Gerät als MongoDB fungiert client, die Zeit zwischen der Entdeckung des letzten Pakets des gesendeten Pakets durch das ExtraHop-System Anfrage und das erste Paket der empfangenen Antwort.
MongoDB-Servergruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt MongoDB Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
MongoDB Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wann MongoDB-Fehler aufgetreten sind und wie viele MongoDB-Antworten die
Server gesendet haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Server zu dem Zeitpunkt waren, als
sie die Fehler gemeldet haben.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie sich Details zu jedem Fehler anzeigen lassen, einschließlich des Fehlercodes. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von MongoDB-Anfragen zu MongoDB-Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie in der Tabelle MongoDB-Metriken für Gruppen.
Hinweis: Um zu sehen, welche Fehlercodes der Client erhalten hat, klicken Sie Fehler und wähle Fehler aus der Speisekarte. Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn er als MongoDB-Server fungiert Fehler Die Anzahl der Fehler, die das Gerät gesendet hat wenn er als MongoDB-Server fungiert - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele MongoDB-Antwortserver in der Gruppe gesendet haben und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn er als MongoDB-Server fungiert Fehler Die Anzahl der Fehler, die das Gerät gesendet hat wenn er als MongoDB-Server fungiert
MongoDB-Details für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (MongoDB-Server)
- Dieses Diagramm zeigt, welche MongoDB-Server in der Gruppe am aktivsten waren, indem die Gesamtzahl der MongoDB-Antworten, die die Gruppe vom Server gesendet hat, aufgeschlüsselt wird.
- Die besten Methoden
- Dieses Diagramm zeigt, welche MongoDB-Methoden auf Servern in der Gruppe am häufigsten aufgerufen wurden, indem die Gesamtzahl der Anfragen, die die Gruppe erhalten hat, nach Methode aufgeteilt wird.
- Die häufigsten Fehler
- Dieses Diagramm zeigt, welche MongoDB-Fehler die Gruppen am häufigsten zurückgegeben haben, indem die Gesamtzahl der Antworten, die die Gruppe irrtümlich gesendet hat, aufgeschlüsselt wird.
MongoDB-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- MongoDB-Metriken für Gruppen
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden Clients möglicherweise mehr Anfragen, als die Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät erhalten hat wenn er als MongoDB-Server fungiert Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn er als MongoDB-Server fungiert Fehler Die Anzahl der Fehler, die das Gerät gesendet hat wenn er als MongoDB-Server fungiert Abgebrochene Anfragen Die Anzahl der Anfragen, die diese MongoDB stellt Der Server begann zu empfangen, empfing aber nicht vollständig, da die Verbindung abrupt geschlossen. Abgebrochene Antworten Die Anzahl der Anfragen, die diese MongoDB stellt Der Server begann zu empfangen, empfing aber nicht vollständig, da die Verbindung abrupt geschlossen. - Verarbeitungszeit des Servers
-
Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche Zeit, die die Server für die
Bearbeitung von Anfragen von Clients benötigten. Hohe Serververarbeitungszeiten deuten darauf hin, dass die Server in einer
Gruppe langsam sind.
Metrisch Beschreibung Verarbeitungszeit des MongoDB-Servers Wenn das Gerät als MongoDB fungiert Server, die Zeit zwischen der Entdeckung des letzten Paket durch das ExtraHop-System empfangene Anfrage und erstes Paket der gesendeten Antwort.
MSMQ
Das ExtraHop-System sammelt Metriken zu Microsoft Message Queuing (MSMQ) Aktivität. MSMQ ist ein Protokoll, das es Anwendungen ermöglicht, Nachrichten und Objekte aneinander zu senden.
| Hinweis: | Das ExtraHop-System enthält keine integrierten Metrikseiten für MSMQ. Sie können jedoch MSMQ-Metriken anzeigen, indem Sie sie zu einer benutzerdefinierten Seite hinzufügen oder Dashboard. |
MSRPC
Das ExtraHop-System sammelt Messwerte zur MRPC (MSRPC) -Aktivität. Das MSRPC-Protokoll ermöglicht es einem Programm, Dienste von einem Computer in einem anderen Netzwerk anzufordern, ohne die Details dieses bestimmten Netzwerk verstehen zu müssen.
Überlegungen zur Sicherheit
- MS-RPC ermöglicht Verwaltungsprogramme wie PsExec, um Befehle an entfernte Geräte zu senden. Angreifer können diese Dienstprogramme nutzen, um entfernte Geräte zu kompromittieren und sich seitlich über ein Netzwerk zu bewegen.
- MS-RPC-Befehle können von Angreifern genutzt werden, um Informationen von Domänencontrollern (DCs) zu stehlen. DC-Synchronisierung und DCShadow sind Beispiele für diese Angriffe, die zu einer Privilegstufenerhöhung und Kerberos führen können goldenes Ticket Angriffe.
- Angriffstools wie Mimikatz, senden Sie MS-RPC-Anfragen an DCs und andere Geräte.
- Verschlüsselter MS-RPC-Verkehr ist ein zunehmend verbreiteter Vektor für bösartige Aktivitäten. Sie können das ExtraHop-System so konfigurieren, Domain-Traffic entschlüsseln um verdächtiges Verhalten und potenzielle Angriffe zu identifizieren.
MSRPC-Clientseite
Auf dieser Seite werden Metrikdiagramme von angezeigt MSRPC Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur MSRPC-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
MSRPC Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Antworten
- Dieses Diagramm zeigt Ihnen, wann der Client MSRPC-Antworten erhalten hat und welche dieser
Antworten die maximale PDU-Körpergröße überschritten haben.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die dieser MSRPC erhalten hat Client. Fragmente der Antwort Die Anzahl der eingegangenen Antworten MSRPC-Client, der die maximale PDU-Körpergröße überschritten hat - Gesamtzahl der Antworten
- Dieses Diagramm zeigt Ihnen, wie viele MSRPC-Antworten der Client erhalten hat und wie viele
dieser Antworten die maximale PDU-Körpergröße überschritten haben.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die dieser MSRPC erhalten hat Client. Fragmente der Antwort Die Anzahl der eingegangenen Antworten MSRPC-Client, der die maximale PDU-Körpergröße überschritten hat - Verwaiste Anrufe
- Dieses Diagramm zeigt Ihnen, wann der Client laufende Anfragen abgebrochen hat.
Metrisch Beschreibung Verwaiste Anrufe Die Häufigkeit, mit der eine Anfrage abgebrochen wurde Fortschritt, wenn das Gerät als MSRPC-Client fungiert - Gesamtzahl der verwaisten Anrufe
- Dieses Diagramm zeigt Ihnen, wie viele Anfragen der Client während der Bearbeitung abgebrochen hat.
Metrisch Beschreibung Verwaiste Anrufe Die Häufigkeit, mit der eine Anfrage abgebrochen wurde Fortschritt, wenn das Gerät als MSRPC-Client fungiert - Stornierte Operationen
- Dieses Diagramm zeigt Ihnen, wann der Client an MSRPC-Abbruchvorgängen teilgenommen hat.
Metrisch Beschreibung Stornierte Operationen Die Anzahl der Abbruchvorgänge, die dieser MSRPC ausgeführt hat Client hat teilgenommen. - Gesamtzahl der stornierten Operationen
- Dieses Diagramm zeigt Ihnen, an wie vielen MSRPC-Abbruchvorgängen der Client teilgenommen hat
.
Metrisch Beschreibung Stornierte Operationen Die Anzahl der Abbruchvorgänge, die dieser MSRPC ausgeführt hat Client hat teilgenommen.
MSRPC-Verkehr
Die folgenden Diagramme sind in dieser Region verfügbar:
- Goodput-Bitrate
- Dieses Diagramm zeigt die Rate, mit der MSRPC-Goodput-Bits im Laufe der Zeit
vom Client empfangen und gesendet wurden.
Metrisch Beschreibung Gut eingegangene Byte Die Anzahl der Goodput-Bytes, die von diesem empfangen wurden MSRPC-Client. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Goodput Byte raus Die Anzahl der Goodput-Bytes, die von diesem MSRPC gesendet wurden Client. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. - Goodput-Bytes insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele MSRPC-Goodput-Bytes vom Client empfangen und gesendet wurden.
Metrisch Beschreibung Gut eingegangene Byte Die Anzahl der Goodput-Bytes, die von diesem empfangen wurden MSRPC-Client. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Goodput Byte raus Die Anzahl der Goodput-Bytes, die von diesem MSRPC gesendet wurden Client. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. - Paket-Rate
- Dieses Diagramm zeigt die Rate, mit der MSRPC-Pakete vom Client im Laufe
der Zeit empfangen und gesendet wurden.
Metrisch Beschreibung Eingehende Pakete Die Anzahl der Pakete, die von diesem MSRPC empfangen wurden Client. Ausgehende Pakete Die Anzahl der von diesem MSRPC gesendeten Pakete Client. - Pakete insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele MSRPC-Pakete vom Client empfangen und gesendet wurden.
Metrisch Beschreibung Eingehende Pakete Die Anzahl der Pakete, die von diesem MSRPC empfangen wurden Client. Ausgehende Pakete Die Anzahl der von diesem MSRPC gesendeten Pakete Client.
Metrische MSRPC-Gesamtsummen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Antworten und Probleme insgesamt
- Zeigt die Gesamtzahl der Antworten und Probleme an.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die dieser MSRPC erhalten hat Client. Fragmente der Antwort Die Anzahl der eingegangenen Antworten MSRPC-Client, der die maximale PDU-Körpergröße überschritten hat Verwaiste Anrufe Die Häufigkeit, mit der eine Anfrage abgebrochen wurde Fortschritt, wenn das Gerät als MSRPC-Client fungiert Stornierte Operationen Die Anzahl der Abbruchvorgänge, die dieser MSRPC ausgeführt hat Client hat teilgenommen. Fehlgeschlagene Endpoint Mapper-Bindungen Wenn das Gerät als MSRPC fungiert client, wie oft der MSRPC-Server den aktuellen nicht finden konnte MSRPC-Anwendung. Zu den Ursachen können Probleme wie die Serveranwendung gehören konnte nicht gestartet oder initialisiert werden Abgelehnte Bindungen Die Anzahl der RPC-Bindungen (Remote Procedure Call) die vom Server abgelehnt wurden, wenn das Gerät als MSRPC-Client fungiert. Abgelehnte Bindungen treten auf, wenn ein Server Bindungsaktualisierungen von einem Peer sendet und empfängt Server außer Betrieb. Fehler-PDUs Die Anzahl der von diesem MSRPC gesendeten Fehler-PDUs Client. - Länge des PDU-Fragments
- In diesem Diagramm werden die Längen der PDU-Fragmente in einem Boxplot dargestellt.
Metrisch Beschreibung Länge des PDU-Fragments Die Verteilung der Fragmentlängen (in Byte), die ausgetauscht werden, wenn das Gerät als MSRPC-Client fungiert
MSRPC-Serverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt MSRPC Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur MSRPC-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
MSRPC Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Antworten
- Dieses Diagramm zeigt, wann der Server MSRPC-Antworten gesendet hat und wann der Server
Antworten erhalten hat, die die maximale PDU-Körpergröße überschritten haben.
Metrisch Beschreibung Antworten Die Anzahl der von diesem MSRPC gesendeten Antworten Server. Fragmente der Antwort Die Anzahl der eingegangenen Antworten MSRPC-Server, der die maximale PDU-Körpergröße überschritten hat - Gesamtzahl der Antworten
- Dieses Diagramm zeigt Ihnen, wie viele MSRPC-Antworten der Server gesendet hat und wie viele
Antwortfragmente der Server empfangen hat.
Metrisch Beschreibung Antworten Die Anzahl der von diesem MSRPC gesendeten Antworten Server. Fragmente der Antwort Die Anzahl der eingegangenen Antworten MSRPC-Server, der die maximale PDU-Körpergröße überschritten hat - Verwaiste Anrufe
- Dieses Diagramm zeigt Ihnen, wann Clients laufende Anfragen auf dem
MSRPC-Server abgebrochen haben.
Metrisch Beschreibung Verwaiste Anrufe Die Häufigkeit, mit der ein Client einen abgebrochen hat Anfrage wird ausgeführt, wenn das Gerät als MSRPC-Server fungiert - Gesamtzahl der verwaisten Anrufe
- Dieses Diagramm zeigt Ihnen, wie viele Anfragen Clients während der Bearbeitung auf dem
MSRPC-Server abgebrochen haben.
Metrisch Beschreibung Verwaiste Anrufe Die Häufigkeit, mit der ein Client einen abgebrochen hat Anfrage wird ausgeführt, wenn das Gerät als MSRPC-Server fungiert - Stornierte Operationen
- Dieses Diagramm zeigt Ihnen, wann der Server an MSRPC-Abbruchvorgängen teilgenommen hat.
Metrisch Beschreibung Stornierte Operationen Die Anzahl der Abbruchvorgänge, die dieser MSRPC ausgeführt hat Server hat teilgenommen. - Gesamtzahl der stornierten Operationen
- Dieses Diagramm zeigt Ihnen, an wie vielen MSRPC-Abbruchvorgängen der Server teilgenommen hat
.
Metrisch Beschreibung Stornierte Operationen Die Anzahl der Abbruchvorgänge, die dieser MSRPC ausgeführt hat Server hat teilgenommen.
MSRPC-Verkehr
Die folgenden Diagramme sind in dieser Region verfügbar:
- Goodput-Bitrate
- Dieses Diagramm zeigt die Rate, mit der MSRPC-Goodput-Bits im Laufe
der Zeit vom Server empfangen und gesendet wurden.
Metrisch Beschreibung Gut eingegangene Byte Die Anzahl der Goodput-Bytes, die von diesem empfangen wurden MSRPC-Server. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Goodput Byte raus Die Anzahl der Goodput-Bytes, die von diesem gesendet wurden MSRPC-Server. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. - Goodput-Bytes insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele MSRPC-Goodput-Bytes vom Server empfangen und gesendet wurden.
Metrisch Beschreibung Gut eingegangene Byte Die Anzahl der Goodput-Bytes, die von diesem empfangen wurden MSRPC-Server. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Goodput Byte raus Die Anzahl der Goodput-Bytes, die von diesem gesendet wurden MSRPC-Server. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. - Paket-Rate
- Dieses Diagramm zeigt die Rate, mit der MSRPC-Pakete im Laufe der Zeit vom
Server empfangen und gesendet wurden.
Metrisch Beschreibung Eingehende Pakete Die Anzahl der Pakete, die von diesem MSRPC empfangen wurden Server. Ausgehende Pakete Die Anzahl der Pakete, die von diesem MSRPC gesendet wurden Server. - Pakete insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele MSRPC-Pakete vom Server empfangen und gesendet wurden.
Metrisch Beschreibung Eingehende Pakete Die Anzahl der Pakete, die von diesem MSRPC empfangen wurden Server. Ausgehende Pakete Die Anzahl der Pakete, die von diesem MSRPC gesendet wurden Server.
Metrische MSRPC-Gesamtsummen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Antworten und Probleme
- Zeigt die Gesamtzahl der Antworten und Probleme an.
Metrisch Beschreibung Antworten Die Anzahl der von diesem MSRPC gesendeten Antworten Server. Fragmente der Antwort Die Anzahl der eingegangenen Antworten MSRPC-Server, der die maximale PDU-Körpergröße überschritten hat Verwaiste Anrufe Die Häufigkeit, mit der ein Client einen abgebrochen hat Anfrage wird ausgeführt, wenn das Gerät als MSRPC-Server fungiert Stornierte Operationen Die Anzahl der Abbruchvorgänge, die dieser MSRPC ausgeführt hat Server hat teilgenommen. Fehlgeschlagene Endpoint Mapper-Bindungen Die Häufigkeit, mit der dieser MSRPC Der Server konnte die aktuelle MSRPC-Anwendung nicht finden. Zu den möglichen Ursachen gehören Probleme, z. B. dass die Serveranwendung nicht gestartet werden kann oder initialisieren Abgelehnte Bindungen Die Anzahl der RPC-Bindungen (Remote Procedure Call) die abgelehnt wurden, wenn das Gerät als MSRPC-Server fungiert. Abgelehnte Bindungen treten auf, wenn ein Server Bind-Updates von einem Peer-Server aus sendet und empfängt bestellen. Fehler-PDUs Die Anzahl der fehlerhaften PDUs, die von diesem MSRPC gesendet wurden Server. - Länge des PDU-Fragments
- In diesem Diagramm werden die Längen der PDU-Fragmente in einem Boxplot dargestellt.
Metrisch Beschreibung Länge des PDU-Fragments Die Verteilung der Fragmentlängen (in Byte), die ausgetauscht werden, wenn das Gerät als MSRPC-Server fungiert
MSRPC-Client-Gruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt MSRPC Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur MSRPC-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
MSRPC Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann die Clients MSRPC-Antworten erhalten haben und welche dieser
Antworten die maximale PDU-Körpergröße überschritten haben.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die dieser MSRPC erhalten hat Client. Fragmente der Antwort Die Anzahl der eingegangenen Antworten MSRPC-Client, der die maximale PDU-Körpergröße überschritten hat - Transaktionen insgesamt
- Dieses Diagramm zeigt, wie oft MSRPC-Clients MSRPC-Antworten erhalten haben und welche dieser Antworten die maximale
PDU-Körpergröße überschritten haben.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die dieser MSRPC erhalten hat Client. Fragmente der Antwort Die Anzahl der eingegangenen Antworten MSRPC-Client, der die maximale PDU-Körpergröße überschritten hat
MSRPC-Details für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (MSRPC-Server)
- Die aktivsten MSRPC-Clients in der Gruppe. Das ExtraHop-System berechnet diese Werte, indem es die Gesamtzahl der von der Gruppe gesendeten MSRPC-Anfragen betrachtet und diese Anfragen nach Kunden aufschlüsselt.
MSRPC-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
- Zeigt die Gesamtzahl der Antworten und Probleme an.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die dieser MSRPC erhalten hat Client. Fragmente der Antwort Die Anzahl der eingegangenen Antworten MSRPC-Client, der die maximale PDU-Körpergröße überschritten hat Verwaiste Anrufe Die Häufigkeit, mit der eine Anfrage abgebrochen wurde Fortschritt, wenn das Gerät als MSRPC-Client fungiert Abgebrochene Operationen Die Anzahl der Abbruchvorgänge, die dieser MSRPC ausgeführt hat Client hat teilgenommen. Fehlgeschlagene Endpoint Mapper-Bindungen Wenn das Gerät als MSRPC fungiert client, wie oft der MSRPC-Server den aktuellen nicht finden konnte MSRPC-Anwendung. Zu den Ursachen können Probleme wie die Serveranwendung gehören konnte nicht gestartet oder initialisiert werden Abgelehnte Bindungen Die Anzahl der RPC-Bindungen (Remote Procedure Call) die vom Server abgelehnt wurden, wenn das Gerät als MSRPC-Client fungiert. Abgelehnte Bindungen treten auf, wenn ein Server Bindungsaktualisierungen von einem Peer sendet und empfängt Server außer Betrieb. Fehler-PDUs Die Anzahl der von diesem MSRPC gesendeten Fehler-PDUs Client.
MSRPC-Servergruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt MSRPC Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur MSRPC-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
MSRPC Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann die Server MSRPC-Antworten gesendet haben und wann die Server Antworten
erhalten haben, die die maximale PDU-Körpergröße überschritten haben.
Metrisch Beschreibung Antworten Die Anzahl der von diesem MSRPC gesendeten Antworten Server. Fragmente der Antwort Die Anzahl der eingegangenen Antworten MSRPC-Server, der die maximale PDU-Körpergröße überschritten hat - Transaktionen insgesamt
- Dieses Diagramm zeigt, wie oft MSRPC-Server RPC-Antworten gesendet haben und wann die
Server Antworten erhalten haben, die die maximale PDU-Körpergröße überschritten haben.
Metrisch Beschreibung Antworten Die Anzahl der von diesem MSRPC gesendeten Antworten Server. Fragmente der Antwort Die Anzahl der eingegangenen Antworten MSRPC-Server, der die maximale PDU-Körpergröße überschritten hat
MSRPC-Details für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (MSRPC-Server)
- Die aktivsten MSRPC-Server in der Gruppe. Das ExtraHop-System berechnet diese Werte, indem es die Gesamtzahl der von der Gruppe gesendeten MSRPC-Antworten betrachtet und diese Antworten nach Servern aufschlüsselt.
MSRPC-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
- Zeigt die Gesamtzahl der Antworten und Probleme an.
Metrisch Beschreibung Antworten Die Anzahl der von diesem MSRPC gesendeten Antworten Server. Fragmente der Antwort Die Anzahl der eingegangenen Antworten MSRPC-Server, der die maximale PDU-Körpergröße überschritten hat Verwaiste Anrufe Die Häufigkeit, mit der ein Client einen abgebrochen hat Anfrage wird ausgeführt, wenn das Gerät als MSRPC-Server fungiert Abgebrochene Operationen Die Anzahl der Abbruchvorgänge, die dieser MSRPC ausgeführt hat Server hat teilgenommen. Fehlgeschlagene Endpoint Mapper-Bindungen Die Häufigkeit, mit der dieser MSRPC Der Server konnte die aktuelle MSRPC-Anwendung nicht finden. Zu den möglichen Ursachen gehören Probleme, z. B. dass die Serveranwendung nicht gestartet werden kann oder initialisieren Abgelehnte Bindungen Die Anzahl der RPC-Bindungen (Remote Procedure Call) die abgelehnt wurden, wenn das Gerät als MSRPC-Server fungiert. Abgelehnte Bindungen treten auf, wenn ein Server Bind-Updates von einem Peer-Server aus sendet und empfängt bestellen. Fehler-PDUs Die Anzahl der fehlerhaften PDUs, die von diesem MSRPC gesendet wurden Server.
NBNS
Das ExtraHop-System sammelt Metriken über den NetBIOS Name Service (NBNS) Protokollaktivität. NBNS ist ein Benennungssystem für Netzwerkhosts und Ressourcen.
| Hinweis: | Das ExtraHop-System enthält keine integrierten Metrikseiten für NBNS. Sie können NBNS-Metriken jedoch anzeigen, indem Sie sie zu einer benutzerdefinierten Seite hinzufügen oder Dashboard. |
NetFlow
Das ExtraHop-System sammelt Metriken zur NetFlow-Aktivität.
Flow-Netzwerke
Ein Flussnetz ist ein Netzwerkgerät, z. B. ein Router oder Switch, das Informationen über Datenflüsse sendet, die auf dem Gerät beobachtet wurden. Übersichtsseiten bieten integrierte Diagramme für den IP-Verkehr , der über Remote-Netzwerkgeräte ein- und ausgeht, z. B. NetFlow-Verkehr, für konfigurierte Flow-Netzwerke und Flow-Schnittstellen.
Übersichtsseiten enthalten drei Regionen mit Diagrammen für zusammenfassende Daten der obersten Ebene.
- Überblick
- Zeigen Sie die Gesamtmenge des Netzwerkdurchsatzes (durchschnittliche Bits pro Sekunde) an, der entweder in das Flussnetz oder in das Flow-Interface ein- und ausfließt. Nur für Flow-Schnittstellen können Sie auch die Bandbreitennutzung des Durchsatzes anzeigen, der in die Flussschnittstelle ein- und ausfließt.
- Protokolle
- IP-Flow-Pakete werden in der Regel über UDP- und TCP-Ports über das Flussnetz oder die Flow-Schnittstelle übertragen. Sehen Sie sich die Gesamtmenge des Datenverkehrs für jedes Protokoll und jeden Port, der Daten überträgt, im Balkendiagramm an. Vergleichen Sie im Liniendiagramm die Änderungen des Protokoll- und Portdurchsatzes im Laufe der Zeit. Sie können den Mauszeiger auch über das Protokoll und den Portnamen in der Legende des Liniendiagramm bewegen, um die Protokolldaten im Diagramm zu isolieren.
- Endpunkte
- Zeigen Sie die Datenmenge an, die Geräte (oder Endpunkte) über das
Flussnetz oder die Flow-Schnittstelle senden und empfangen, und zwar auf folgende Weise:
- In Top-Talker-Diagrammen werden einzelne Geräte mit dem höchsten Durchsatz angezeigt.
- Die wichtigsten Absenderdiagramme zeigen den Durchsatz für Geräte, die Daten senden.
- Die wichtigsten Empfängerdiagramme zeigen den Durchsatz für Geräte, die Daten empfangen.
- Konversationsdiagramme zeigen das höchste Durchsatzvolumen pro Fluss zwischen zwei Geräten (Endpunkten).
- Vergleichen Sie die wichtigsten Sprecher, Absender und Konversationen im Balkendiagramm.
- Vergleichen Sie im Liniendiagramm die Veränderungen der Durchsatzaktivität für einzelne Geräte im Laufe der Zeit.
- Zeigen Sie mit der Maus auf eine Geräte-IP-Adresse im Liniendiagramm, um die Durchsatzdaten im Diagramm zu isolieren.
NetFlow-Anwendungsseite
Auf dieser Seite werden Metrikdiagramme von angezeigt NetFlow Datenverkehr im Zusammenhang mit Anwendungscontainern in Ihrem Netzwerk.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
NetFlow-Zusammenfassung
- Durchsatz
- Dieses Diagramm zeigt den NetFlow-Durchsatz im Zeitverlauf, indem es zeigt, wann Bytes
übertragen wurden.
Metrisch Beschreibung NetFlow-Bytes Die Anzahl der L3-Bytes, die dem Fluss zugeordnet sind Technologien. - Zusammenfassung des Durchsatzes
- Dieses Diagramm zeigt die Geschwindigkeit, mit der NetFlow-Bytes übertragen werden.
Metrisch Beschreibung NetFlow-Bytes Die Anzahl der L3-Bytes, die dem Fluss zugeordnet sind Technologien. - Verkehr insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der übertragenen NetFlow-Bytes.
Metrisch Beschreibung NetFlow-Bytes Die Anzahl der L3-Bytes, die dem Fluss zugeordnet sind Technologien.
Protokolle
- Die besten Protokolle
- Dieses Diagramm zeigt, welche NetFlow-Protokolle im Laufe der Zeit am aktivsten waren. Es zeigt die
Übertragungsrate von Bytes, aufgeschlüsselt nach Protokoll.
Metrisch Beschreibung NetFlow-Bytes Die Anzahl der L3-Bytes, die dem Fluss zugeordnet sind Technologien. - Die besten Protokolle
- Dieses Diagramm zeigt, welche NetFlow-Protokolle am aktivsten waren.
Metrisch Beschreibung NetFlow-Bytes Die Anzahl der L3-Bytes, die dem Fluss zugeordnet sind Technologien.
Endpunkte
- Die besten Redner
- Dieses Diagramm zeigt, welche IP-Adressen im Laufe der
Zeit die meisten NetFlow-Daten gesendet und empfangen haben.
Metrisch Beschreibung NetFlow-Bytes Die Anzahl der L3-Bytes, die dem Fluss zugeordnet sind Technologien. - Die besten Redner
- Dieses Diagramm zeigt, welche IP-Adressen die meisten NetFlow-Daten gesendet und empfangen haben.
Metrisch Beschreibung NetFlow-Bytes Die Anzahl der L3-Bytes, die dem Fluss zugeordnet sind Technologien. - Die besten Absender
- Dieses Diagramm zeigt, welche IP-Adressen im Laufe der Zeit die meisten NetFlow-Daten gesendet haben.
Metrisch Beschreibung NetFlow-Bytes Die Anzahl der L3-Bytes, die dem Fluss zugeordnet sind Technologien. - Die besten Absender
- Dieses Diagramm zeigt, welche IP-Adressen die meisten NetFlow-Daten gesendet haben.
Metrisch Beschreibung NetFlow-Bytes Die Anzahl der L3-Bytes, die dem Fluss zugeordnet sind Technologien. - Die besten Empfänger
- Dieses Diagramm zeigt, welche IP-Adressen im Laufe der Zeit die meisten NetFlow-Daten erhalten haben.
Metrisch Beschreibung NetFlow-Bytes Die Anzahl der L3-Bytes, die dem Fluss zugeordnet sind Technologien. - Die besten Empfänger
- Dieses Diagramm zeigt, welche IP-Adressen die meisten NetFlow-Daten erhalten haben.
Metrisch Beschreibung NetFlow-Bytes Die Anzahl der L3-Bytes, die dem Fluss zugeordnet sind Technologien. - Die besten Konversationen
- Dieses Diagramm zeigt, welche IP-Adresspaare im Laufe der
Zeit die meisten NetFlow-Daten ausgetauscht haben.
Metrisch Beschreibung NetFlow-Bytes Die Anzahl der L3-Bytes, die dem Fluss zugeordnet sind Technologien. - Die besten Konversationen
- Dieses Diagramm zeigt, welche IP-Adresspaare die meisten NetFlow-Daten ausgetauscht haben.
Metrisch Beschreibung NetFlow-Bytes Die Anzahl der L3-Bytes, die dem Fluss zugeordnet sind Technologien.
NetFlow-Metriksummen
- Verkehr insgesamt
-
Metrisch Beschreibung NetFlow-Bytes Die Anzahl der L3-Bytes, die dem Fluss zugeordnet sind Technologien. NetFlow-Pakete Die Anzahl der Pakete, die mit Fluss verknüpft sind Technologien. NetFlow-Aufzeichnungen Die Anzahl der Datensätze, die mit Fluss verknüpft sind Technologien.
NFS
Das ExtraHop-System sammelt Metriken über das NFS (NFS) Aktivität. NFS ist ein verteiltes Dateisystemprotokoll, das Client-Zugriff auf Dateien in einem Netzwerk Attached Storage (NAS) -Repository ermöglicht, typischerweise in einer UNIX-Umgebung. Das ExtraHop-System unterstützt NFSv2, NFSv3 und NFSv4.
Überlegungen zur Sicherheit
- Die NFS-Authentifizierung kann anfällig sein für Brute-Force, bei der es sich um eine Methode zum Erraten von Anmeldedaten handelt, indem zahlreiche Authentifizierungsanfragen mit unterschiedlichen Kombinationen aus Benutzername und Passwort eingereicht werden.
- NFS kann anfällig sein fürRansomware Malware, die Tausende von Lese- und Schreibvorgängen über NFS durchführt, um Dateien zu verschlüsseln, die auf Dateiservern im Netzwerk gespeichert sind.
NFS-Client-Seite
Auf dieser Seite werden Metrikdiagramme von angezeigt NFS Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur NFS-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
NFS Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann NFS-Fehler aufgetreten sind und wie viele Antworten der NFS-Client
erhalten hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Client zum Zeitpunkt des
Eingangs der Fehler war.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie sich Details zu jedem Fehler anzeigen lassen, einschließlich des Fehlercodes. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von Anfragen zu Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Hinweis: Um zu sehen, welche Fehlercodes der Client erhalten hat, klicken Sie Fehler und wähle Fehler aus der Speisekarte. Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als NFS-Client agieren Fehler Wenn das Gerät als NFS-Client fungiert, die Anzahl der Methodenaufrufe, die ein anderes Ergebnis als 'OK' erhalten - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der NFS-Antworten, die der Client erhalten hat, und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als NFS-Client agieren Fehler Wenn das Gerät als NFS-Client fungiert, die Anzahl der Methodenaufrufe, die ein anderes Ergebnis als 'OK' erhalten - Lese- und Schreiboperationen
- Dieses Diagramm zeigt Ihnen, wann der NFS-Client Lese- und Schreiboperationen ausgeführt hat.
Metrisch Beschreibung Liest Die Anzahl der NFS-Leseanfragen, die der Gerät, das gesendet wird, wenn es als NFS-Client fungiert Schreibt Die Anzahl der NFS-Schreibanforderungen, die der Gerät, das gesendet wird, wenn es als NFS-Client fungiert - Operationen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele Lese- und Schreiboperationen der NFS-Client
ausgeführt hat.
Metrisch Beschreibung Liest Die Anzahl der NFS-Leseanfragen, die der Gerät, das gesendet wird, wenn es als NFS-Client fungiert Schreibt Die Anzahl der NFS-Schreibanforderungen, die der Gerät, das gesendet wird, wenn es als NFS-Client fungiert - Leistungsübersicht (95. Perzentil)
-
Dieses Diagramm zeigt das
95. Perzentil der Timing-Metriken. Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer
vollständigen Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange der Client gebraucht hat, um
Anfragen an das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange Server gebraucht haben, um
die Anfragen zu verarbeiten; und die Antwortübertragungszeit zeigt, wie lange Server gebraucht haben, um
Antworten an das Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Übertragungszeit für NFS-Client-Anfragen Wenn das Gerät als NFS-Client fungiert, die Zeit zwischen der Erkennung des ersten Pakets und des letzten Pakets durch das ExtraHop-System von gesendete Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Prozesszeit des NFS-Client-Servers Wenn das Gerät als NFS-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort. Übertragungszeit der NFS-Client-Antwort Wenn das Gerät als NFS-Client fungiert, die Zeit zwischen der Erkennung des ersten Pakets und des letzten Pakets durch das ExtraHop-System von erhaltene Antworten. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen NFS-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn ein Client langsam reagiert, können Sie
anhand von Leistungsübersichtsmetriken herausfinden, ob das Netzwerk oder die Server das Problem verursachen.
Diese Metriken zeigen das 95. Perzentil der Zeit, die Server für die Bearbeitung von
Anfragen vom Client benötigten, im Vergleich zur 95. Perzentilzeit, die Pakete aus diesen
Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten.
Hohe Serververarbeitungszeiten deuten darauf hin, dass der Client langsame Server kontaktiert. Hohe
TCP-Roundtrip-Zeiten deuten darauf hin, dass der Client über langsame
Netzwerke kommuniziert.
Metrisch Beschreibung Verarbeitungszeit des NFS-Clientservers Wenn das Gerät als NFS-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen NFS-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
NFS-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche NFS-Methoden der Client am häufigsten aufgerufen hat, indem es die Gesamtzahl der Anfragen aufschlüsselt, die der Client nach Methode gesendet hat.
- Die wichtigsten Statuscodes
- Dieses Diagramm zeigt, welche NFS-Statuscodes der Client am häufigsten erhalten hat, indem die Anzahl der an den Client zurückgegebenen Antworten nach Statuscode aufgeteilt wird.
- Die häufigsten Authentifizierungsfehler
- Dieses Diagramm zeigt, welche NFS-Authentifizierungsfehler der Client am häufigsten erhalten hat, indem die Anzahl der irrtümlich an den Client zurückgegebenen Antworten aufgeschlüsselt wird.
NFS-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serverzugriffszeit
- In diesem Diagramm werden die Serverzugriffszeiten in einem Histogramm dargestellt.
Metrisch Beschreibung NFS-Client-Zugriffszeit Wenn das Gerät als NFS-Client fungiert, Die Zugriffszeit berechnet die Latenz eines READ- oder WRITE-Befehls ohne Pipeline pro Datei. Das ExtraHop-System erkennt, wann das letzte Paket der Anfrage vom NFS gesendet wird Client und wann das erste Paket der Antwort vom NFS-Client empfangen wird - Serverzugriffszeit
- Dieses Diagramm zeigt die durchschnittliche Zugriffszeit für den Client.
Metrisch Beschreibung NFS-Client-Zugriffszeit Wenn das Gerät als NFS-Client fungiert, Die Zugriffszeit berechnet die Latenz eines READ- oder WRITE-Befehls ohne Pipeline pro Datei. Das ExtraHop-System erkennt, wann das letzte Paket der Anfrage vom NFS gesendet wird Client und wann das erste Paket der Antwort vom NFS-Client empfangen wird - Verteilung der Serververarbeitungszeit
- In diesem Diagramm werden die Serverzugriffszeiten in einem Histogramm dargestellt.
Metrisch Beschreibung Verarbeitungszeit des NFS-Clientservers Wenn das Gerät als NFS-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort. - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Bearbeitungszeit für den Client.
Metrisch Beschreibung Verarbeitungszeit des NFS-Clientservers Wenn das Gerät als NFS-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen NFS-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Hin- und Rückflugzeit für den Client.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen NFS-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Metrische NFS-Gesamtwerte
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Anfragen und Antworten
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, sendet der Client möglicherweise mehr
Anfragen, als die Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen
, ob das Problem beim Netzwerk oder beim Server liegt, überprüfen Sie RTOs und Zero Windows in der
Netzwerk-Daten
Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der NFS-Anfragen und -Antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der NFS-Anfragen, die das Gerät gesendet hat wenn Sie als NFS-Client agieren Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als NFS-Client agieren Abgebrochene Anfragen Die Anzahl der unvollständigen Anfragen, die dieses NFS Client-Gerät gesendet, weil die Verbindung abrupt geschlossen Liest Die Anzahl der NFS-Leseanfragen, die der Gerät, das gesendet wird, wenn es als NFS-Client fungiert Schreibt Die Anzahl der NFS-Schreibanforderungen, die der Gerät, das gesendet wird, wenn es als NFS-Client fungiert Erneute Übertragungen Die Anzahl der NFS-Anfragen, für die Der Zeitgeber für die erneute Übertragung ist abgelaufen und die Anfrage wurde erneut versucht, während das Gerät aktiv ist als NFS-Client Fehler Wenn das Gerät als NFS-Client fungiert, die Anzahl der Methodenaufrufe, die ein anderes Ergebnis als 'OK' erhalten - Anfragen- und Antwortgrößen
- Dieses Diagramm zeigt die durchschnittliche Größe der Anfragen und Antworten.
Metrisch Beschreibung Größe der Anfrage Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät gesendet hat, als es als NFS-Client agiert Größe der Antwort Die Verteilung der Größen (in Byte) von Antworten, die das Gerät erhalten hat, als es als NFS-Client agiert
NFS-Serverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt NFS Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur NFS-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
NFS Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann NFS-Fehler aufgetreten sind und wie viele NFS-Antworten der Server
gesendet hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Server zu dem Zeitpunkt war, als er die Fehler
zurückgab.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie sich Details zu jedem Fehler anzeigen lassen, einschließlich des Fehlercodes. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von Anfragen zu Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Hinweis: Um zu sehen, welche Fehlercodes der Client erhalten hat, klicken Sie auf Fehler und wähle Fehler aus der Speisekarte. Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als NFS-Server Fehler Wenn das Gerät als NFS-Server fungiert, die Anzahl der Methodenaufrufe, die ein anderes Ergebnis als 'OK' erhalten - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der NFS-Antworten, die der Server gesendet hat, und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als NFS-Server Fehler Wenn das Gerät als NFS-Server fungiert, die Anzahl der Methodenaufrufe, die ein anderes Ergebnis als 'OK' erhalten - Lese- und Schreiboperationen
- Dieses Diagramm zeigt Ihnen, wann die Lese- und Schreiboperationen auf dem
NFS-Server ausgeführt wurden.
Metrisch Beschreibung Liest Die Anzahl der NFS-Leseanfragen, die Gerät, das empfangen wurde, wenn es als NFS-Server fungiert Schreibt Die Anzahl der NFS-Schreibanforderungen, die der Gerät, das empfangen wurde, wenn es als NFS-Server fungiert - Zusammenfassung der Operationen
- Dieses Diagramm zeigt Ihnen, wie viele Lese- und Schreiboperationen der NFS-Client
ausgeführt hat.
Metrisch Beschreibung Liest Die Anzahl der NFS-Leseanfragen, die Gerät, das empfangen wurde, wenn es als NFS-Server fungiert Schreibt Die Anzahl der NFS-Schreibanforderungen, die der Gerät, das empfangen wurde, wenn es als NFS-Server fungiert - Leistungsübersicht (95. Perzentil)
-
Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken
. Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer vollständigen
Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange Clients gebraucht haben, um Anfragen an
das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange der Server gebraucht hat, um Anfragen zu verarbeiten;
und die Antwortübertragungszeit zeigt, wie lange der Server gebraucht hat, um Antworten an das
Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Übertragungszeit für NFS-Serveranfragen Wenn das Gerät als NFS-Server fungiert, die Zeit zwischen der Erkennung des ersten Pakets und des letzten Pakets durch das ExtraHop-System von eingegangene Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Prozesszeit des NFS-Serverservers Wenn das Gerät als NFS-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort. Übertragungszeit der NFS-Serverantwort Wenn das Gerät als NFS-Server fungiert, die Zeit zwischen der Erkennung des ersten Pakets und des letzten Pakets durch das ExtraHop-System von gesendete Antworten. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen NFS-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Leistung (95. Perzentil)
-
Wenn ein Server langsam reagiert, können Sie
anhand von Leistungsübersichtsmetriken herausfinden, ob das
Problem vom Netzwerk oder vom Server verursacht wird. Die Leistungsübersichtsmetriken zeigen das 95. Perzentil der Zeit, die der
Server für die Verarbeitung von Anfragen von Clients benötigte, im Vergleich zur 95. Perzentilzeit, die
Pakete aus diesen Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten.
Hohe Serververarbeitungszeiten deuten darauf hin, dass der Server langsam ist.
Hohe RTTs weisen darauf hin, dass der Server über langsame Netzwerke kommuniziert.
Metrisch Beschreibung Verarbeitungszeit des NFS-Servers Wenn das Gerät als NFS-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen NFS-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
NFS-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche NFS-Methoden auf dem Server am häufigsten aufgerufen wurden, indem die Gesamtzahl der Anfragen, die der Server erhalten hat, nach Methode aufgeteilt wird.
- Die wichtigsten Statuscodes
- Dieses Diagramm zeigt, welche NFS-Statuscodes der Server am häufigsten zurückgegeben hat, indem die Gesamtzahl der vom Server gesendeten Antworten nach Statuscode aufgeschlüsselt wird.
- Die häufigsten Authentifizierungsfehler
- Dieses Diagramm zeigt, welche NFS-Authentifizierungsfehler der Server am häufigsten zurückgegeben hat, indem die Gesamtzahl der Antworten, die der Server aufgrund eines Authentifizierungsfehlers gesendet hat, aufgeschlüsselt wird.
NFS-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serverzugriffszeit
- In diesem Diagramm werden die Serverzugriffszeiten in einem Histogramm dargestellt.
Metrisch Beschreibung Zugriffszeit des NFS-Servers Wenn das Gerät als NFS-Server fungiert, Die Zugriffszeit berechnet die Latenz eines READ- oder WRITE-Befehls ohne Pipeline pro Datei. Das ExtraHop-System erkennt, wann das letzte Paket der Anfrage von NFS-Server und wann das erste Paket der Antwort vom NFS-Server gesendet wird - Serverzugriffszeit
- Dieses Diagramm zeigt die durchschnittliche Zugriffszeit für den Server.
Metrisch Beschreibung Zugriffszeit des NFS-Servers Wenn das Gerät als NFS-Server fungiert, Die Zugriffszeit berechnet die Latenz eines READ- oder WRITE-Befehls ohne Pipeline pro Datei. Das ExtraHop-System erkennt, wann das letzte Paket der Anfrage von NFS-Server und wann das erste Paket der Antwort vom NFS-Server gesendet wird - Verteilung der Serververarbeitungszeit
- In diesem Diagramm werden die Serverzugriffszeiten in einem Histogramm dargestellt.
Metrisch Beschreibung Verarbeitungszeit des NFS-Servers Wenn das Gerät als NFS-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort. - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Verarbeitungszeit für den Server.
Metrisch Beschreibung Verarbeitungszeit des NFS-Servers Wenn das Gerät als NFS-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen NFS-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Roundtrip-Zeit für den Server.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen NFS-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Metrische NFS-Gesamtwerte
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr
Anfragen, als der Server verarbeiten kann, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen
, ob das Problem beim Netzwerk oder beim Server liegt, überprüfen Sie RTOs und Zero Windows in der
Netzwerk-Daten
Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der NFS-Anfragen und -Antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der NFS-Anfragen, die das Gerät empfangen, wenn er als NFS-Server fungiert Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als NFS-Server Abgebrochene Anfragen Die Anzahl der unvollständigen Anfragen, die dieses NFS Der Server wurde empfangen, weil die Verbindung abrupt geschlossen Liest Die Anzahl der NFS-Leseanfragen, die Gerät, das empfangen wurde, wenn es als NFS-Server fungiert Schreibt Die Anzahl der NFS-Schreibanforderungen, die der Gerät, das empfangen wurde, wenn es als NFS-Server fungiert Erneute Übertragungen Die Anzahl der NFS-Anfragen, für die Der Zeitgeber für die erneute Übertragung ist abgelaufen und die Anfrage wurde erneut versucht, während das Gerät aktiv ist als NFS-Server - Anfragen- und Antwortgrößen
- Dieses Diagramm zeigt die durchschnittliche Größe der Anfragen und Antworten.
Metrisch Beschreibung Größe der Anfrage Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät empfangen hat, als es als NFS-Server fungiert Größe der Antwort Die Verteilung der Größen (in Byte) von Antworten, die das Gerät gesendet hat, als es als NFS-Server fungierte
NFS-Client-Gruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt NFS Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur NFS-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
NFS Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wann NFS-Fehler aufgetreten sind und wie viele Antworten die NFS-Clients
erhalten haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Kunden zu dem Zeitpunkt waren, als sie die Fehler
erhielten.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie sich Details zu jedem Fehler anzeigen lassen, einschließlich des Fehlercodes. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von Anfragen zu Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie in der Tabelle NFS-Metriken für Gruppen.
Hinweis: Um zu sehen, welche Fehlercodes der Client erhalten hat, klicken Sie auf Fehler und wähle Fehler aus der Speisekarte. Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als NFS-Client agieren Fehler Wenn das Gerät als NFS-Client fungiert, die Anzahl der Methodenaufrufe, die ein anderes Ergebnis als 'OK' erhalten - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele NFS-Antworten die Clients erhalten haben und wie viele dieser
Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als NFS-Client agieren Fehler Wenn das Gerät als NFS-Client fungiert, die Anzahl der Methodenaufrufe, die ein anderes Ergebnis als 'OK' erhalten
NFS-Details für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (NFS-Kunden)
- Dieses Diagramm zeigt, welche NFS-Clients in der Gruppe am aktivsten waren, indem es die Gesamtzahl der NFS-Anfragen aufschlüsselt, die die Gruppe vom Client gesendet hat.
- Die besten Methoden
- Dieses Diagramm zeigt, welche NFS-Methoden die Gruppe am häufigsten aufgerufen hat, indem die Gesamtzahl der Anfragen, die die Gruppe nach Methode gesendet hat, aufgeschlüsselt wird.
- Die wichtigsten Statuscodes
- Dieses Diagramm zeigt, welche NFS-Statuscodes die Gruppe am meisten erhalten hat, indem die Anzahl der an die Gruppe zurückgegebenen Antworten nach Statuscode aufgeschlüsselt wird.
NFS-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden die Clients möglicherweise mehr Anfragen, als Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der NFS-Anfragen, die das Gerät gesendet hat wenn Sie als NFS-Client agieren Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als NFS-Client agieren Abgebrochene Anfragen Die Anzahl der unvollständigen Anfragen, die dieses NFS Client-Gerät gesendet, weil die Verbindung abrupt geschlossen Liest Die Anzahl der NFS-Leseanfragen, die der Gerät, das gesendet wird, wenn es als NFS-Client fungiert Schreibt Die Anzahl der NFS-Schreibanforderungen, die der Gerät, das gesendet wird, wenn es als NFS-Client fungiert Erneute Übertragungen Die Anzahl der NFS-Anfragen, für die Der Zeitgeber für die erneute Übertragung ist abgelaufen und die Anfrage wurde erneut versucht, während das Gerät aktiv ist als NFS-Client Fehler Wenn das Gerät als NFS-Client fungiert, die Anzahl der Methodenaufrufe, die ein anderes Ergebnis als 'OK' erhalten - Zeit des Zugriffs
- Wenn sich eine Client-Gruppe langsam verhält, können Sie anhand der Zugriffszeit herausfinden, ob das
Problem bei den Servern liegt. Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche
Zeit, die Server für die Bearbeitung von Anfragen von den Clients benötigten. Hohe Zugriffszeiten deuten darauf hin, dass
die Clients langsame Server kontaktieren.
Metrisch Beschreibung NFS-Client-Zugriffszeit Wenn das Gerät als NFS-Client fungiert, Die Zugriffszeit berechnet die Latenz eines READ- oder WRITE-Befehls ohne Pipeline pro Datei. Das ExtraHop-System erkennt, wann das letzte Paket der Anfrage vom NFS gesendet wird Client und wann das erste Paket der Antwort vom NFS-Client empfangen wird
NFS-Servergruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt NFS Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur NFS-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
NFS Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wann NFS-Fehler aufgetreten sind und wie viele NFS-Antworten die Server
gesendet haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Server zu dem Zeitpunkt waren, als sie
die Fehler gemeldet haben.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie sich Details zu jedem Fehler anzeigen lassen, einschließlich des Fehlercodes. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von NFS-Anfragen zu NFS-Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie in der Tabelle NFS-Metriken für Gruppen.
Hinweis: Um zu sehen, welche Fehlercodes der Client erhalten hat, klicken Sie auf Fehler und wähle Fehler aus der Speisekarte. Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als NFS-Server Fehler Wenn das Gerät als NFS-Server fungiert, die Anzahl der Methodenaufrufe, die ein anderes Ergebnis als 'OK' erhalten - Transaktionen insgesamt
- Dieses Diagramm zeigt, wie viele NFS-Antwortserver in der Gruppe gesendet haben und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als NFS-Server Fehler Wenn das Gerät als NFS-Server fungiert, die Anzahl der Methodenaufrufe, die ein anderes Ergebnis als 'OK' erhalten
NFS-Details für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (NFS-Server)
- Dieses Diagramm zeigt, welche NFS-Server in der Gruppe am aktivsten waren, indem es die Gesamtzahl der NFS-Antworten aufschlüsselt, die die Gruppe vom Server gesendet hat.
- Die besten Methoden
- Dieses Diagramm zeigt, welche NFS-Methoden auf Servern in der Gruppe am häufigsten aufgerufen wurden, indem die Gesamtzahl der Anfragen, die die Gruppe erhalten hat, nach Methode aufgeteilt wird.
- Wichtigster Statuscode
- Dieses Diagramm zeigt, welche NFS-Statuscodes die Gruppen am häufigsten zurückgegeben haben, indem die Gesamtzahl der von der Gruppe gesendeten Antworten nach Statuscode aufgeschlüsselt wird.
NFS-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden Clients möglicherweise mehr Anfragen, als die Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der NFS-Anfragen, die das Gerät empfangen, wenn er als NFS-Server fungiert Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als NFS-Server Abgebrochene Anfragen Die Anzahl der unvollständigen Anfragen, die dieses NFS Der Server wurde empfangen, weil die Verbindung abrupt geschlossen Liest Die Anzahl der NFS-Leseanfragen, die Gerät, das empfangen wurde, wenn es als NFS-Server fungiert Schreibt Die Anzahl der NFS-Schreibanforderungen, die der Gerät, das empfangen wurde, wenn es als NFS-Server fungiert Weiterübertragungen Die Anzahl der NFS-Anfragen, für die Der Zeitgeber für die erneute Übertragung ist abgelaufen und die Anfrage wurde erneut versucht, während das Gerät aktiv ist als NFS-Server Antworten Wenn das Gerät als NFS-Server fungiert, die Anzahl der Methodenaufrufe, die ein anderes Ergebnis als 'OK' erhalten - Zeit des Zugriffs
- Wenn sich eine Servergruppe langsam verhält, können Sie anhand des Diagramms „Zugriffszeit" herausfinden
, ob das Problem bei den Servern liegt. Das Diagramm „Zugriffszeit" zeigt die durchschnittliche
Zeit, die die Server für die Bearbeitung von Anfragen von Clients benötigten. Hohe Serverzugriffszeiten
deuten darauf hin, dass die Server langsam sind.
Metrisch Beschreibung Zugriffszeit des NFS-Servers Wenn das Gerät als NFS-Server fungiert, Die Zugriffszeit berechnet die Latenz eines READ- oder WRITE-Befehls ohne Pipeline pro Datei. Das ExtraHop-System erkennt, wann das letzte Paket der Anfrage von NFS-Server und wann das erste Paket der Antwort vom NFS-Server gesendet wird
POP3
Das ExtraHop-System sammelt Metriken zu Post Office Protocol Version 3 (POP3) Aktivität. POP3 ist ein Standardprotokoll auf Anwendungsebene, das E-Mail-Nachrichten zwischen einem Server und einer Client-Anwendung über eine TCP-Verbindung überträgt.
| Hinweis: | Das ExtraHop-System enthält keine integrierten Metrikseiten für POP3. Sie können jedoch POP3-Metriken auf einer benutzerdefinierten Seite hinzufügen und anzeigen oder Dashboard. |
POP3-Anwendungsseite
Auf dieser Seite werden Metrikdiagramme von angezeigt POP3 Verkehr, der mit einem Anwendungscontainer in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
POP3 Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann POP3-Fehler und -Antworten mit der
Anwendung verknüpft waren. Anhand dieser Informationen können Sie feststellen, wie aktiv die Anwendung zum
Zeitpunkt des Auftretens der Fehler war.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der POP3-Antworten. Fehler Die Anzahl der POP3-Antworten Fehler. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der POP3-Antworten, die mit der
Anwendung verknüpft waren, und wie viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der POP3-Antworten. Fehler Die Anzahl der POP3-Antworten Fehler. - Leistung (95. Perzentil)
-
Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken.
Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer vollständigen
Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange Clients gebraucht haben, um Anfragen an
das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange die Server für die Bearbeitung von Anfragen gebraucht haben;
und die Antwortübertragungszeit zeigt, wie lange die Server gebraucht haben, um Antworten an
das Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Transferzeit anfragen Die Zeit zwischen der Erkennung durch das ExtraHop-System das erste Paket und das letzte Paket von POP3-Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit des Servers Die Zeit zwischen der Erkennung durch das ExtraHop-System das letzte Paket von POP3-Anfragen und das erste Paket der entsprechenden Antworten. Übertragungszeit der Antwort Die Zeit zwischen der Erkennung durch das ExtraHop-System das erste Paket und das letzte Paket von POP3-Antworten. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines POP3-Clients oder Server ein Paket, das sofort bestätigt werden muss und wann die Bestätigung erfolgte erhalten. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn eine Anwendung langsam reagiert, können Sie anhand
von Leistungsübersichtsmetriken herausfinden, ob das Netzwerk oder die Server das
Problem verursachen. Diese Metriken zeigen das 95. Perzentil der Zeit, die Server für die Bearbeitung von
Anfragen von Clients benötigten, im Vergleich zum 95. Perzentil der Zeit, die Pakete aus diesen Anfragen
(und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten. Hohe
Serververarbeitungszeiten deuten darauf hin, dass Clients langsame Server kontaktieren. Hohe
TCP-Roundtrip-Zeiten deuten darauf hin, dass Clients über langsame Netzwerke kommunizieren.
Metrisch Beschreibung Verarbeitungszeit des Servers Die Zeit zwischen der Erkennung durch das ExtraHop-System das letzte Paket von POP3-Anfragen und das erste Paket der entsprechenden Antworten. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines POP3-Clients oder Server ein Paket, das sofort bestätigt werden muss und wann die Bestätigung erfolgte erhalten.
POP3-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche POP3-Methoden mit der Anwendung verknüpft waren, indem die Gesamtzahl der POP3-Anfragen nach Methoden aufgeschlüsselt wird.
- Die häufigsten Fehler
- Dieses Diagramm zeigt, welche POP3-Fehler am häufigsten mit der Anwendung in Verbindung gebracht wurden, indem die Anzahl der Antworten nach Fehlern aufgeschlüsselt wird.
POP3-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des POP3-Servers Die Zeit zwischen der Erkennung durch das ExtraHop-System das letzte Paket von POP3-Anfragen und das erste Paket der entsprechenden Antworten. - Verarbeitungszeit des Servers
-
Diese Tabelle zeigt die durchschnittliche Bearbeitungszeit für den Anwendung.
Metrisch Beschreibung Verarbeitungszeit des POP3-Servers Die Zeit zwischen der Erkennung durch das ExtraHop-System das letzte Paket von POP3-Anfragen und das erste Paket der entsprechenden Antworten. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines POP3-Clients oder Server ein Paket, das sofort bestätigt werden muss und wann die Bestätigung erfolgte erhalten. - Zeit für Hin- und Rückfahrt
-
Diese Tabelle zeigt
die durchschnittliche Hin- und Rückflugzeit für die Anwendung.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines POP3-Clients oder Server ein Paket, das sofort bestätigt werden muss und wann die Bestätigung erfolgte erhalten.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass ein Problem mit einem Server oder einem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
-
Dieses Diagramm zeigt die Anzahl der Nullfenster, die einer Anwendung
zugeordnet waren. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der Pakete
angeben, die über einen bestimmten Zeitraum an sie gesendet werden können.
Wenn an ein Gerät mehr Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein
Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig einzustellen, bis das Gerät den Vorgang
aufholt. Wenn Sie eine große Anzahl von Nullfenstern sehen, ist ein Server oder Client möglicherweise
nicht schnell genug, um die empfangene Datenmenge zu unterstützen.
Metrisch Definition Zero Windows anfordern Die Anzahl der gesendeten Null-Window-Anzeigen von POP3-Clients. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl eingehender Zero-Windows weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Antwort Null Windows Die Anzahl der gesendeten Null-Window-Anzeigen von Servern beim Empfang von POP3-Anfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von ausgehenden Zero-Windows weist darauf hin, dass ein Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Gesamtzahl der Host-Stände
- Dieses Diagramm zeigt die durchschnittliche Anzahl von Zero-Window-Werbeanzeigen, die von Geräten gesendet wurden.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen
Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu
viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät
eine Anfrage oder Antwort sendet und innerhalb einer bestimmten
Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen
nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise
zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, als Clients POP3-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server POP3-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
- Gesamtzahl der Netzwerkausfälle
-
Dieses Diagramm zeigt die durchschnittliche Anzahl von Timeouts bei der
erneuten Übertragung, die durch Überlastung beim Senden von Anfragen durch Clients und Server verursacht wurden.
Metrisch Definition RTOs Ein Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, als Clients POP3-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server POP3-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Metrische POP3-Gesamtwerte
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr Anfragen, als Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um herauszufinden, ob das Problem mit dem Netzwerk oder einem Server zusammenhängt, überprüfen Sie RTOs und Zero Windows in der Netzwerk-Daten Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der POP3-Anfragen und -Antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der POP3-Anfragen. Antworten Die Anzahl der POP3-Antworten. Fehler Die Anzahl der POP3-Antworten Fehler. Verschlüsselte Sitzungen Die Anzahl der verschlüsselten POP3 Sitzungen. - POP3-Netzwerkmetriken
-
Metrisch Beschreibung Zero Windows anfordern Die Anzahl der gesendeten Null-Window-Anzeigen von POP3-Clients. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Antwort Null Windows Die Anzahl der gesendeten Null-Window-Anzeigen von Servern beim Empfang von POP3-Anfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. RTOs anfragen Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, als Clients POP3-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Antwort-RTOs Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server POP3-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. L2-Byte anfordern Die Anzahl der L2-Bytes, die mit verknüpft sind POP3-Anfragen Antwort L2 Byte Die Anzahl der L2-Bytes, die mit verknüpft sind POP3-Antworten Goodput Bytes anfordern Die Anzahl der Goodput-Bytes, die mit verknüpft sind POP3-Anfragen. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Antwort Goodput Bytes Die Anzahl der Goodput-Bytes, die mit verknüpft sind POP3-Antworten. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Pakete anfordern Die Anzahl der mit POP3 verknüpften Pakete Anfragen. Antwortpakete Die Anzahl der mit POP3 verknüpften Pakete Antworten.
POP3-Clientseite
Auf dieser Seite werden Metrikdiagramme von angezeigt POP3 Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
POP3 Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann POP3-Fehler aufgetreten sind und wie viele Antworten der POP3-Client
erhalten hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Client zum Zeitpunkt des
Eingangs der Fehler war.
Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von Anfragen zu Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als POP3-Client agieren Sessions Die Anzahl der Sitzungen, die das Gerät hat daran teilgenommen, als er als POP3-Client fungierte - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der POP3-Antworten, die der Client erhalten hat, und wie
viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als POP3-Client agieren Fehler Wenn das Gerät als POP3 fungiert client, die Anzahl der empfangenen Befehlsantworten, die einen Antwortcode haben >= 400. - Sessions
- Dieses Diagramm zeigt Ihnen, wann der Client an POP3-Sitzungen teilgenommen hat.
Metrisch Beschreibung Sessions Die Anzahl der Sitzungen, die das Gerät hat daran teilgenommen, als er als POP3-Client fungierte Verschlüsselte Sitzungen Die Anzahl der verschlüsselten Sitzungen an denen das Gerät beteiligt war, als es als POP3-Client fungierte - Gesamtzahl der Sitzungen
- In diesem Diagramm wird die Gesamtzahl der POP3-Sitzungen angezeigt, an denen der Client teilgenommen hat,
und wie viele dieser Sitzungen verschlüsselt waren.
Metrisch Beschreibung Sessions Die Anzahl der Sitzungen, die das Gerät hat daran teilgenommen, als er als POP3-Client fungierte Verschlüsselte Sitzungen Die Anzahl der verschlüsselten Sitzungen an denen das Gerät beteiligt war, als es als POP3-Client fungierte - Leistungsübersicht (95. Perzentil)
-
Dieses Diagramm zeigt das
95. Perzentil der Timing-Metriken. Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer
vollständigen Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange der Client gebraucht hat, um
Anfragen an das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange Server gebraucht haben, um
die Anfragen zu verarbeiten; und die Antwortübertragungszeit zeigt, wie lange Server gebraucht haben, um
Antworten an das Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Übertragungszeit für POP3-Client-Anfragen Wenn das Gerät als POP3-Client fungiert, die Zeit zwischen der Erkennung des ersten Pakets und des letzten Pakets durch das ExtraHop-System von gesendete Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit des POP3-Clientservers Wenn das Gerät als POP3-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort. Übertragungszeit der POP3-Client-Antwort Wenn das Gerät als POP3-Client fungiert, die Zeit zwischen der Erkennung des ersten Pakets und des letzten Pakets durch das ExtraHop-System von erhaltene Antworten. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen POP3-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Leistung (95. Perzentil)
-
Wenn ein Client langsam reagiert, können Sie
anhand von Leistungsübersichtsmetriken herausfinden, ob das Netzwerk oder die Server das Problem verursachen.
Diese Metriken zeigen das 95. Perzentil der Zeit, die Server für die Bearbeitung von
Anfragen vom Client benötigten, im Vergleich zur 95. Perzentilzeit, die Pakete aus diesen
Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten.
Hohe Serververarbeitungszeiten deuten darauf hin, dass der Client langsame Server kontaktiert. Hohe
TCP-Roundtrip-Zeiten deuten darauf hin, dass der Client über langsame
Netzwerke kommuniziert.
Metrisch Beschreibung Verarbeitungszeit des POP3-Clientservers Wenn das Gerät als POP3-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen POP3-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
POP3-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche POP3-Methoden der Client am häufigsten aufgerufen hat, indem die Gesamtzahl der Anfragen, die der Client nach Methode gesendet hat, aufgeschlüsselt wird.
- Die häufigsten Fehler
- Dieses Diagramm zeigt, welche POP3-Fehler der Client am häufigsten erhalten hat, indem die Anzahl der irrtümlich an den Client zurückgegebenen Antworten aufgeschlüsselt wird.
POP3-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des POP3-Clientservers Wenn das Gerät als POP3-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort. - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Bearbeitungszeit für den Client.
Metrisch Beschreibung Verarbeitungszeit des POP3-Clientservers Wenn das Gerät als POP3-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen POP3-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Hin- und Rückflugzeit für den Client.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen POP3-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Metrische POP3-Gesamtwerte
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, sendet der Client möglicherweise mehr
Anfragen, als die Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen
, ob das Problem beim Netzwerk oder beim Server liegt, überprüfen Sie RTOs und Zero Windows in der
Netzwerk-Daten
Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der POP3-Anfragen und -Antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät gesendet hat, als agiert als POP3-Client Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als POP3-Client agieren Abgebrochene Anfragen Die Anzahl der Anfragen, die dieses POP3 Der Client begann zu senden, sendete aber nicht vollständig, da die Verbindung abrupt geschlossen. Abgebrochene Antworten Die Anzahl der Antworten, die dieses POP3 Der Client begann zu empfangen, erhielt aber nicht den vollständigen Empfang, da die Verbindung abrupt geschlossen. Verschlüsselte Sitzungen Die Anzahl der verschlüsselten Sitzungen an denen das Gerät beteiligt war, als es als POP3-Client fungierte Fehler Wenn das Gerät als POP3 fungiert client, die Anzahl der empfangenen Befehlsantworten, die einen Antwortcode haben >= 400. - Anfragen- und Antwortgrößen
- Dieses Diagramm zeigt die durchschnittliche Größe der Anfragen und Antworten.
Metrisch Beschreibung Größe der Anfrage Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät gesendet hat, als es als POP3-Client agiert Größe der Antwort Die Verteilung der Größen (in Byte) von Antworten, die das Gerät erhalten hat, als es als POP3-Client agiert
POP3-Serverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt POP3 Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
POP3 Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann POP3-Fehler aufgetreten sind und wie viele POP3-Antworten der Server
gesendet hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Server zu dem Zeitpunkt war, als er die Fehler
zurückgab.
Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von Anfragen zu Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als POP3-Server Sessions Die Anzahl der Sitzungen, die das Gerät hat daran teilgenommen, als er als POP3-Server fungierte - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der POP3-Antworten, die der Server gesendet hat, und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als POP3-Server Sessions Die Anzahl der Sitzungen, die das Gerät hat daran teilgenommen, als er als POP3-Server fungierte Fehler Wenn das Gerät als POP3 fungiert Server, die Anzahl der gesendeten Befehlsantworten, die einen Antwortcode haben >= 400. - Sessions
- Dieses Diagramm zeigt Ihnen, wann der Server an POP3-Sitzungen teilgenommen hat.
Metrisch Beschreibung Sessions Die Anzahl der Sitzungen, die das Gerät hat daran teilgenommen, als er als POP3-Server fungierte Verschlüsselte Sitzungen Die Anzahl der verschlüsselten Sitzungen an denen das Gerät beteiligt war, als es als POP3-Server fungierte - Gesamtzahl der Sitzungen
- In diesem Diagramm wird die Gesamtzahl der POP3-Sitzungen angezeigt, an denen der Server teilgenommen hat,
und wie viele dieser Sitzungen verschlüsselt wurden.
Metrisch Beschreibung Sessions Die Anzahl der Sitzungen, die das Gerät hat daran teilgenommen, als er als POP3-Server fungierte Verschlüsselte Sitzungen Die Anzahl der verschlüsselten Sitzungen an denen das Gerät beteiligt war, als es als POP3-Server fungierte - Leistungsübersicht (95. Perzentil)
-
Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken
. Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer vollständigen
Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange Clients gebraucht haben, um Anfragen an
das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange der Server gebraucht hat, um Anfragen zu verarbeiten;
und die Antwortübertragungszeit zeigt, wie lange der Server gebraucht hat, um Antworten an das
Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Übertragungszeit für POP3-Serveranfragen Wenn das Gerät als POP3-Server fungiert, die Zeit zwischen der Erkennung des ersten Pakets und des letzten Pakets durch das ExtraHop-System von eingegangene Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit des POP3-Serverservers Wenn das Gerät als POP3-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort. Übertragungszeit der POP3-Serverantwort Wenn das Gerät als POP3-Server fungiert, die Zeit zwischen der Erkennung des ersten Pakets und des letzten Pakets durch das ExtraHop-System von gesendete Antworten. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen POP3-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn ein Server langsam reagiert, können Sie
anhand von Leistungsübersichtsmetriken herausfinden, ob das
Problem vom Netzwerk oder vom Server verursacht wird. Die Leistungsübersichtsmetriken zeigen das 95. Perzentil der Zeit, die der
Server für die Verarbeitung von Anfragen von Clients benötigte, im Vergleich zur 95. Perzentilzeit, die
Pakete aus diesen Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten.
Hohe Serververarbeitungszeiten deuten darauf hin, dass der Server langsam ist.
Hohe RTTs weisen darauf hin, dass der Server über langsame Netzwerke kommuniziert.
Metrisch Beschreibung Verarbeitungszeit des POP3-Serverservers Wenn das Gerät als POP3-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen POP3-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
POP3-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche POP3-Methoden auf dem Server am häufigsten aufgerufen wurden, indem die Gesamtzahl der Anfragen, die der Server nach Methode erhalten hat, aufgeschlüsselt wird.
- Die häufigsten Fehler
- Dieses Diagramm zeigt, welche POP3-Fehler der Server am häufigsten zurückgegeben hat, indem die Gesamtzahl der Antworten, die der Server versehentlich gesendet hat, aufgeschlüsselt wird.
POP3-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des POP3-Serverservers Wenn das Gerät als POP3-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort. - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Verarbeitungszeit für den Server.
Metrisch Beschreibung Verarbeitungszeit des POP3-Serverservers Wenn das Gerät als POP3-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen POP3-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Roundtrip-Zeit für den Server.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen POP3-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Metrische POP3-Gesamtwerte
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Anfragen und Antworten
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr
Anfragen, als der Server verarbeiten kann, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen
, ob das Problem am Netzwerk oder am Server liegt, überprüfen Sie RTOs und Zero Windows in der
Netzwerk-Daten
Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der POP3-Anfragen und -Antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät erhalten hat wenn Sie als POP3-Server agieren Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als POP3-Server Abgebrochene Anfragen Die Anzahl der Anfragen, die dieses POP3 Der Server begann zu empfangen, empfing aber nicht vollständig, da die Verbindung abrupt geschlossen. Abgebrochene Antworten Die Anzahl der Antworten, die dieses POP3 Der Server begann zu senden, sendete aber nicht vollständig, da die Verbindung abrupt geschlossen. Verschlüsselte Sitzungen Die Anzahl der verschlüsselten Sitzungen an denen das Gerät beteiligt war, als es als POP3-Server fungierte Fehler Wenn das Gerät als POP3 fungiert Server, die Anzahl der gesendeten Befehlsantworten, die einen Antwortcode haben >= 400. - Anfragen- und Antwortgrößen
- Dieses Diagramm zeigt die durchschnittliche Größe der Anfragen und Antworten.
Metrisch Beschreibung Größe der Anfrage Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät empfangen hat, als es als POP3-Server fungiert Größe der Antwort Die Verteilung der Größen (in Byte) von Antworten, die das Gerät empfangen hat, als es als POP3-Server fungierte
POP3-Client-Gruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt POP3 Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
POP3 Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann POP3-Fehler aufgetreten sind und wie viele Antworten die POP3-Clients
erhalten haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Kunden zu dem Zeitpunkt waren, als sie die Fehler
erhielten.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie im Abschnitt POP3-Metriken für Gruppen.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als POP3-Client agieren Fehler Wenn das Gerät als POP3 fungiert client, die Anzahl der empfangenen Befehlsantworten, die einen Antwortcode haben >= 400. - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele POP3-Antworten die Clients erhalten haben und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als POP3-Client agieren Fehler Wenn das Gerät als POP3 fungiert client, die Anzahl der empfangenen Befehlsantworten, die einen Antwortcode haben >= 400.
POP3-Details für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (POP3-Clients)
- Dieses Diagramm zeigt, welche POP3-Clients in der Gruppe am aktivsten waren, indem die Gesamtzahl der POP3-Anfragen, die die Gruppe vom Client gesendet hat, aufgeschlüsselt wird.
- Die besten Methoden
- Dieses Diagramm zeigt, welche POP3-Methoden die Gruppe am häufigsten aufgerufen hat, indem die Gesamtzahl der von der Gruppe gesendeten Anfragen nach Methode aufgeschlüsselt wird.
- Die häufigsten Fehler
- Dieses Diagramm zeigt, welche POP3-Fehler die Gruppe am häufigsten erhalten hat, indem die Anzahl der Antworten aufgeschlüsselt wird, die fehlerhaft an die Gruppe zurückgegeben wurden.
POP3-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden die Clients möglicherweise mehr Anfragen, als Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät gesendet hat, als agiert als POP3-Client Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als POP3-Client agieren Abgebrochene Anfragen Die Anzahl der Anfragen, die dieses POP3 Der Client begann zu senden, sendete aber nicht vollständig, da die Verbindung abrupt geschlossen. Abgebrochene Antworten Die Anzahl der Antworten, die dieses POP3 Der Client begann zu empfangen, erhielt aber nicht den vollständigen Empfang, da die Verbindung abrupt geschlossen. Verschlüsselte Sitzungen Die Anzahl der verschlüsselten Sitzungen an denen das Gerät beteiligt war, als es als POP3-Client fungierte Fehler Wenn das Gerät als POP3 fungiert client, die Anzahl der empfangenen Befehlsantworten, die einen Antwortcode haben >= 400. - Verarbeitungszeit des Servers
-
Wenn sich eine Client-Gruppe langsam verhält, können Sie anhand der Serververarbeitungszeit herausfinden,
ob das Problem bei den Servern liegt. Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche
Zeit, die Server für die Bearbeitung von Anfragen von den Clients benötigten. Hohe
Serververarbeitungszeiten deuten darauf hin, dass die Clients langsame Server kontaktieren.
Metrisch Beschreibung Verarbeitungszeit des POP3-Clientservers Wenn das Gerät als POP3-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort.
POP3-Servergruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt POP3 Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
POP3 Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann POP3-Fehler aufgetreten sind und wie viele POP3-Antworten die Server
gesendet haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Server zu dem Zeitpunkt waren, als sie
die Fehler gemeldet haben.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie im Abschnitt POP3-Metriken für Gruppen.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als POP3-Server Fehler Wenn das Gerät als POP3 fungiert Server, die Anzahl der gesendeten Befehlsantworten, die einen Antwortcode haben >= 400. - Transaktionen insgesamt
- Dieses Diagramm zeigt, wie viele POP3-Antwortserver in der Gruppe gesendet haben und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als POP3-Server Fehler Wenn das Gerät als POP3 fungiert Server, die Anzahl der gesendeten Befehlsantworten, die einen Antwortcode haben >= 400.
POP3-Details für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (POP3-Server)
- Dieses Diagramm zeigt, welche POP3-Server in der Gruppe am aktivsten waren, indem die Gesamtzahl der POP3-Antworten, die die Gruppe vom Server gesendet hat, aufgeschlüsselt wird.
- Die besten Methoden
- Dieses Diagramm zeigt, welche POP3-Methoden auf Servern in der Gruppe am häufigsten aufgerufen wurden, indem die Gesamtzahl der Anfragen, die die Gruppe erhalten hat, nach Methode aufgeteilt wird.
- Die häufigsten Fehler
- Dieses Diagramm zeigt, welche POP3-Fehler die Gruppen am häufigsten gemeldet haben, indem die Gesamtzahl der Antworten, die die Gruppe irrtümlich gesendet hat, aufgeschlüsselt wird.
POP3-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Anfragen und Antworten
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden Clients möglicherweise mehr Anfragen, als die Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät erhalten hat wenn Sie als POP3-Server agieren Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als POP3-Server Abgebrochene Anfragen Die Anzahl der Anfragen, die dieses POP3 Der Server begann zu empfangen, empfing aber nicht vollständig, da die Verbindung abrupt geschlossen. Abgebrochene Antworten Die Anzahl der Antworten, die dieses POP3 Der Server begann zu senden, sendete aber nicht vollständig, da die Verbindung abrupt geschlossen. Verschlüsselte Sitzungen Die Anzahl der verschlüsselten Sitzungen an denen das Gerät beteiligt war, als es als POP3-Server fungierte Fehler Wenn das Gerät als POP3 fungiert Server, die Anzahl der gesendeten Befehlsantworten, die einen Antwortcode haben >= 400. - Verarbeitungszeit des Servers
-
Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche Zeit, die die Server für die
Bearbeitung von Anfragen von Clients benötigten. Hohe Serververarbeitungszeiten deuten darauf hin, dass die Server in einer
Gruppe langsam sind.
Metrisch Beschreibung Verarbeitungszeit des POP3-Serverservers Wenn das Gerät als POP3-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort.
RDP
Das ExtraHop-System sammelt Metriken über das Remote Desktop Protocol (RDP) Aktivität. RDP ist ein proprietäres Microsoft-Protokoll für die Kommunikation zwischen einem Remote Desktop Session Host-Server und einem Client, auf dem die Remote Desktop Connections-Software ausgeführt wird. RDP ist in TCP gekapselt und verschlüsselt.
Überlegungen zur Sicherheit
- RDP RDP-Authentifizierung kann anfällig sein für Brute-Force, bei der es sich um eine Methode zum Erraten von Anmeldedaten handelt, indem zahlreiche Authentifizierungsanfragen mit unterschiedlichen Kombinationen aus Benutzername und Passwort eingereicht werden.
- RDP sollte sein Behinderte sofern dies nicht erforderlich ist, um unbefugten Zugriff auf interne Geräte zu verhindern.
- Veraltete Versionen von RDP haben bekannte Sicherheitslücken wie Blauer Keep.
- RDP ist ein Fernwartung Protokoll, das ein Angreifer nutzen kann, um mit entfernten Geräten zu interagieren und sich seitlich im Netzwerk zu bewegen.
RDP-Anwendungsseite
Auf dieser Seite werden Metrikdiagramme von angezeigt RDP Verkehr, der mit einem Anwendungscontainer in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur RDP-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
RDP Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Sessions
- Dieses Diagramm zeigt Ihnen, wann RDP-Clientverbindungen geöffnet wurden, wann verschlüsselte
Verbindungen geöffnet wurden und wann Fehler mit der Anwendung verknüpft waren. Anhand dieser
Informationen können Sie feststellen, wie aktiv die Anwendung zum Zeitpunkt des Auftretens der
Fehler war.
Metrisch Beschreibung Client wird geöffnet Die Anzahl der RDP-Sitzungen, die geöffnet wurden von Kunden. Verschlüsselte Öffnungen Die Anzahl der verschlüsselten RDP-Sitzungen, die geöffnet. Fehler Die Anzahl der Fehler, die RDP-Sitzungen verhindert haben ab dem Öffnen. - Gesamtzahl der Sitzungen
- Dieses Diagramm zeigt die Gesamtzahl der RDP-Clientverbindungen, verschlüsselten
Verbindungen und Fehler, die mit der Anwendung verknüpft waren.
Metrisch Beschreibung Client wird geöffnet Die Anzahl der RDP-Sitzungen, die geöffnet wurden von Kunden. Verschlüsselte Öffnungen Die Anzahl der verschlüsselten RDP-Sitzungen, die geöffnet. Fehler Die Anzahl der Fehler, die RDP-Sitzungen verhindert haben ab dem Öffnen. - Zeit für Hin- und Rückfahrt
- Dieses Diagramm zeigt die Perzentile der Round Trip Time (RTT) von RDP-Sitzungen. Die RTT-Metrik
misst, wie lange es gedauert hat, bis Pakete vom
Client oder Server sofort bestätigt wurden. Daher ist RTT ein guter Indikator für die
Leistung Ihres Netzwerk.
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Round Trip Time (RTT) ist ein Maß für die Gesamtzahl Netzwerklatenz. Das ExtraHop-System berechnet RTT, indem es die benötigte Zeit misst senden Sie ein RDP-Paket und erhalten Sie eine sofortige Bestätigung ( - Zeit für Hin- und Rückfahrt
- Dieses Diagramm zeigt das 95. Perzentil für die RDP-Roundtrip-Zeit.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Round Trip Time (RTT) ist ein Maß für die Gesamtzahl Netzwerklatenz. Das ExtraHop-System berechnet RTT, indem es die benötigte Zeit misst senden Sie ein RDP-Paket und erhalten Sie eine sofortige Bestätigung (
RDP Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die häufigsten Fehler
- Dieses Diagramm zeigt, welche RDP-Fehler am häufigsten mit der Anwendung in Verbindung gebracht wurden, indem die Anzahl der Antworten nach Fehlern
aufgeschlüsselt wird.
Metrisch Beschreibung Fehler Die Anzahl der Fehler, die RDP-Sitzungen verhindert haben ab dem Öffnen.
RDP-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Round Trip Time (RTT) ist ein Maß für die Gesamtzahl Netzwerklatenz. Das ExtraHop-System berechnet RTT, indem es die benötigte Zeit misst senden Sie ein RDP-Paket und erhalten Sie eine sofortige Bestätigung ( - Zeit für Hin- und Rückfahrt
-
Diese Tabelle zeigt
die durchschnittliche Hin- und Rückflugzeit für die Anwendung.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Round Trip Time (RTT) ist ein Maß für die Gesamtzahl Netzwerklatenz. Das ExtraHop-System berechnet RTT, indem es die benötigte Zeit misst senden Sie ein RDP-Paket und erhalten Sie eine sofortige Bestätigung (
RDP Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass ein Problem mit einem Server oder einem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
-
Dieses Diagramm zeigt die Anzahl der Nullfenster, die einer Anwendung
zugeordnet waren. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der Pakete
angeben, die über einen bestimmten Zeitraum an sie gesendet werden können.
Wenn an ein Gerät mehr Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein
Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig einzustellen, bis das Gerät den Vorgang
aufholt. Wenn Sie eine große Anzahl von Nullfenstern sehen, ist ein Server oder Client möglicherweise
nicht schnell genug, um die empfangene Datenmenge zu unterstützen.
Metrisch Definition Kunde Zero Windows Die Anzahl der Zero Windows-Werbung gesendet von RDP-Clients. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl eingehender Zero-Windows weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Server Zero Windows Die Anzahl der Zero Windows-Werbung gesendet von RDP-Servern. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von ausgehenden Zero-Windows weist darauf hin, dass ein Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Gesamtzahl der Host-Stände
-
Dieses Diagramm zeigt die durchschnittliche Anzahl von
Zero-Window-Werbeanzeigen, die von Geräten gesendet wurden.
Metrisch Definition Kunde Zero Windows Die Anzahl der Zero Windows-Werbung gesendet von RDP-Clients. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl eingehender Zero-Windows weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Server Zero Windows Die Anzahl der Zero Windows-Werbung gesendet von RDP-Servern. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von ausgehenden Zero-Windows weist darauf hin, dass ein Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen
Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu
viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät
eine Anfrage oder Antwort sendet und innerhalb einer bestimmten
Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen
nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise
zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs für Kunden Die Anzahl der Timeouts für die erneute Übertragung (RTOs) verursacht durch Netzwerküberlastung, als Clients RDP-Daten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Server-RTOs Die Anzahl der Timeouts für die erneute Übertragung (RTOs) verursacht durch Netzwerküberlastung, als Server RDP-Daten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
- Gesamtzahl der Netzwerkausfälle
-
Dieses Diagramm zeigt die durchschnittliche Anzahl von Timeouts bei der
erneuten Übertragung, die durch Überlastung beim Senden von Anfragen durch Clients und Server verursacht wurden.
Metrisch Definition RTOs für Kunden Die Anzahl der Timeouts für die erneute Übertragung (RTOs) verursacht durch Netzwerküberlastung, als Clients RDP-Daten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Server-RTOs Die Anzahl der Timeouts für die erneute Übertragung (RTOs) verursacht durch Netzwerküberlastung, als Server RDP-Daten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RDP Metrische Summen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Sitzungen
- Dieses Diagramm zeigt die Gesamtzahl der RDP-Clientverbindungen, verschlüsselten
Verbindungen und Fehler, die mit der Anwendung verknüpft waren.
Metrisch Beschreibung Client wird geöffnet Die Anzahl der RDP-Sitzungen, die geöffnet wurden von Kunden. Verschlüsselte Öffnungen Die Anzahl der verschlüsselten RDP-Sitzungen, die geöffnet. Fehler Die Anzahl der Fehler, die RDP-Sitzungen verhindert haben ab dem Öffnen. - RDP-Netzwerkmetriken
-
Metrisch Beschreibung Kunde Zero Windows Die Anzahl der Zero Windows-Werbung gesendet von RDP-Clients. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Server Zero Windows Die Anzahl der Zero Windows-Werbung gesendet von RDP-Servern. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. RTOs für Kunden Die Anzahl der Timeouts für die erneute Übertragung (RTOs) verursacht durch Netzwerküberlastung, als Clients RDP-Daten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Server-RTOs Die Anzahl der Timeouts für die erneute Übertragung (RTOs) verursacht durch Netzwerküberlastung, als Server RDP-Daten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. L2-Byte für den Client Die Anzahl der von RDP gesendeten L2-Bytes Kunden innerhalb dieser Anwendung. L2-Byte des Servers Die Anzahl der von RDP gesendeten L2-Bytes Server innerhalb dieser Anwendung. Kunde Goodput Bytes Die Anzahl der von RDP gesendeten Goodput-Bytes Kunden innerhalb dieser Anwendung. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Goodput-Bytes für Server Die Anzahl der von RDP gesendeten Goodput-Bytes Server innerhalb dieser Anwendung. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Client-Pakete Die Anzahl der von RDP-Clients gesendeten Pakete innerhalb dieser Anwendung. Server-Pakete Die Anzahl der von RDP-Servern gesendeten Pakete innerhalb dieser Anwendung. Kunde Nagle Delays Die Anzahl der RDP-Verbindungsverzögerungen für Kunden aufgrund schlechter Interaktionen zwischen dem Nagle-Algorithmus und verzögerten Bestätigungen (ACKs Server-Nagle-Verzögerungen Die Anzahl der RDP-Verbindungsverzögerungen für Server aufgrund schlechter Interaktionen zwischen dem Nagle-Algorithmus und verzögerten Bestätigungen (ACKs
RDP-Client-Seite
Auf dieser Seite werden Metrikdiagramme von angezeigt RDP Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur RDP-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
RDP Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Sessions
- Dieses Diagramm zeigt Ihnen, wann der RDP-Client Sitzungen geöffnet oder daran teilgenommen hat, einschließlich
verschlüsselter Sitzungen, und wann Fehler aufgetreten sind. Anhand dieser Informationen können Sie feststellen, wie
aktiv der Client zum Zeitpunkt des Auftretens der Fehler war.
Metrisch Beschreibung Sessions Die Anzahl der derzeit aktiven Sitzungen mit diesem RDP-Client verknüpft Öffnet Die Häufigkeit, mit der dieser RDP-Client versucht hat eine Sitzung öffnen. Verschlüsselte Öffnungen Die Häufigkeit, mit der dieser RDP-Client hat versucht, eine verschlüsselte Sitzung zu öffnen. Fehler Die Anzahl der Fehler, die dieses RDP verhindert haben Client vom Öffnen einer Sitzung. - Gesamtzahl der Sitzungen
- Dieses Diagramm zeigt Ihnen die Gesamtzahl der Sitzungen, die der RDP-Client geöffnet
hat oder an denen er teilgenommen hat, die Anzahl der verschlüsselten Sitzungen und die Anzahl der
aufgetretenen Fehler.
Metrisch Beschreibung Sessions Die Anzahl der derzeit aktiven Sitzungen mit diesem RDP-Client verknüpft Öffnet Die Häufigkeit, mit der dieser RDP-Client versucht hat eine Sitzung öffnen. Verschlüsselte Öffnungen Die Häufigkeit, mit der dieser RDP-Client hat versucht, eine verschlüsselte Sitzung zu öffnen. Fehler Die Anzahl der Fehler, die dieses RDP verhindert haben Client vom Öffnen einer Sitzung. - Zeit für Hin- und Rückfahrt
- Dieses Diagramm zeigt die Perzentile der Round Trip Time (RTT). Die RTT-Metrik misst, wie
lange es gedauert hat, bis Pakete eine sofortige Bestätigung vom RDP-Client Client.
Daher ist RTT ein guter Indikator für die Leistung Ihres Netzwerk.
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen RDP-Client das erforderte eine sofortige Bestätigung und wann der Client Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
- Dieses Diagramm zeigt das 95. Perzentil für die RDP-Roundtrip-Zeit.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen RDP-Client das erforderte eine sofortige Bestätigung und wann der Client Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
RDP-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die häufigsten Fehler
- Dieses Diagramm zeigt, welche RDP-Fehler der Client am häufigsten erhalten hat, indem die Anzahl der Antworten, die per Fehlermeldung an den Client zurückgegeben wurden, aufgeschlüsselt wird.
RDP-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen RDP-Client das erforderte eine sofortige Bestätigung und wann der Client Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Hin- und Rückflugzeit für den Client.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen RDP-Client das erforderte eine sofortige Bestätigung und wann der Client Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Gesamtwerte der RDP-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Sitzungen
- Dieses Diagramm zeigt Ihnen die Gesamtzahl der Sitzungen, die der RDP-Client geöffnet
hat oder an denen er teilgenommen hat, die Anzahl der verschlüsselten Sitzungen und die Anzahl der
aufgetretenen Fehler.
Metrisch Beschreibung Sessions Die Anzahl der derzeit aktiven Sitzungen mit diesem RDP-Client verknüpft Öffnet Die Häufigkeit, mit der dieser RDP-Client versucht hat eine Sitzung öffnen. Verschlüsselte Öffnungen Die Häufigkeit, mit der dieser RDP-Client hat versucht, eine verschlüsselte Sitzung zu öffnen. Fehler Die Anzahl der Fehler, die dieses RDP verhindert haben Client vom Öffnen einer Sitzung.
RDP-Serverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt RDP Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur RDP-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
Die folgenden Diagramme sind in dieser Region verfügbar:
RDP Zusammenfassung
- Sessions
- Dieses Diagramm zeigt Ihnen, wann der RDP-Server Sitzungen geöffnet oder daran teilgenommen hat, einschließlich
verschlüsselter Sitzungen, und wann Fehler aufgetreten sind. Anhand dieser Informationen können Sie feststellen, wie
aktiv der RDP-Server zum Zeitpunkt des Auftretens der Fehler war.
Metrisch Beschreibung Sessions Die Anzahl der derzeit aktiven Sitzungen mit diesem RDP-Server verknüpft Öffnet Die Häufigkeit, mit der ein RDP-Client versucht hat öffne eine Sitzung auf diesem Server. Verschlüsselte Öffnungen Die Häufigkeit, mit der ein RDP-Client versucht hat um eine verschlüsselte Sitzung auf diesem Server zu öffnen. Fehler Die Anzahl der Fehler, die ein RDP verhindert haben Client vom Öffnen einer Sitzung auf diesem Server. - Gesamtzahl der Sitzungen
- Dieses Diagramm zeigt Ihnen die Gesamtzahl der Sitzungen, die der RDP-Server geöffnet
hat oder an denen er teilgenommen hat, die Anzahl der verschlüsselten Sitzungen und die Anzahl der
aufgetretenen Fehler.
Metrisch Beschreibung Sessions Die Anzahl der derzeit aktiven Sitzungen mit diesem RDP-Server verknüpft Öffnet Die Häufigkeit, mit der ein RDP-Client versucht hat öffne eine Sitzung auf diesem Server. Verschlüsselte Öffnungen Die Häufigkeit, mit der ein RDP-Client versucht hat um eine verschlüsselte Sitzung auf diesem Server zu öffnen. Fehler Die Anzahl der Fehler, die ein RDP verhindert haben Client vom Öffnen einer Sitzung auf diesem Server. - Zeit für Hin- und Rückfahrt
- Dieses Diagramm zeigt die Perzentile der Round Trip Time (RTT). Die RTT-Metrik misst, wie
lange es gedauert hat, bis Pakete eine sofortige Bestätigung vom RDP-Server Server.
Daher ist RTT ein guter Indikator für die Leistung Ihres Netzwerk.
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen RDP-Server das erforderte eine sofortige Bestätigung und wann der Server Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
- Dieses Diagramm zeigt das 95. Perzentil für die RDP-Roundtrip-Zeit.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen RDP-Server das erforderte eine sofortige Bestätigung und wann der Server Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
RDP-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die häufigsten Fehler
- Dieses Diagramm zeigt, welche RDP-Fehler der Server am häufigsten zurückgegeben hat, indem die Gesamtzahl der Antworten, die der Server per Fehlermeldung gesendet hat, aufgeschlüsselt wird.
RDP-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen RDP-Server das erforderte eine sofortige Bestätigung und wann der Server Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Roundtrip-Zeit für den Server.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen RDP-Server das erforderte eine sofortige Bestätigung und wann der Server Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Gesamtwerte der RDP-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Sitzungen
- Dieses Diagramm zeigt Ihnen die Gesamtzahl der Sitzungen, die der RDP-Server geöffnet
hat oder an denen er teilgenommen hat, die Anzahl der verschlüsselten Sitzungen und die Anzahl der
aufgetretenen Fehler.
Metrisch Beschreibung Sessions Die Anzahl der derzeit aktiven Sitzungen mit diesem RDP-Server verknüpft Öffnet Die Häufigkeit, mit der ein RDP-Client versucht hat öffne eine Sitzung auf diesem Server. Verschlüsselte Öffnungen Die Häufigkeit, mit der ein RDP-Client versucht hat um eine verschlüsselte Sitzung auf diesem Server zu öffnen. Fehler Die Anzahl der Fehler, die ein RDP verhindert haben Client vom Öffnen einer Sitzung auf diesem Server.
RDP-Clientgruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt RDP Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur RDP-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
RDP Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Sessions
- Dieses Diagramm zeigt Ihnen, wann RDP-Clients Sitzungen geöffnet oder daran teilgenommen haben und wann
Fehler aufgetreten sind. Anhand dieser Informationen können Sie feststellen, wie aktiv RDP-Clients zum
Zeitpunkt des Auftretens der Fehler waren.
Metrisch Beschreibung Sessions Die Anzahl der derzeit aktiven Sitzungen mit diesem RDP-Client verknüpft Öffnet Die Häufigkeit, mit der dieser RDP-Client versucht hat eine Sitzung öffnen. Verschlüsselte Öffnungen Die Häufigkeit, mit der dieser RDP-Client hat versucht, eine verschlüsselte Sitzung zu öffnen. Fehler Die Anzahl der Fehler, die dieses RDP verhindert haben Client vom Öffnen einer Sitzung. - Gesamtzahl der Sitzungen
- Dieses Diagramm zeigt Ihnen die Gesamtzahl der Sitzungen, die von
RDP-Clients geöffnet wurden oder an denen sie teilgenommen haben, und wie viele Fehler aufgetreten sind.
Metrisch Beschreibung Sessions Die Anzahl der derzeit aktiven Sitzungen mit diesem RDP-Client verknüpft Öffnet Die Häufigkeit, mit der dieser RDP-Client versucht hat eine Sitzung öffnen. Verschlüsselte Öffnungen Die Häufigkeit, mit der dieser RDP-Client hat versucht, eine verschlüsselte Sitzung zu öffnen. Fehler Die Anzahl der Fehler, die dieses RDP verhindert haben Client vom Öffnen einer Sitzung.
RDP-Details für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (RDP-Clients)
- Dieses Diagramm zeigt, welche RDP-Clients in der Gruppe am aktivsten waren, indem die Gesamtzahl der RDP-Sitzungen nach Client aufgeschlüsselt wurde.
RDP-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Sitzungen
- Dieses Diagramm zeigt Ihnen die Gesamtzahl der Sitzungen, die von
RDP-Clients geöffnet wurden oder an denen sie teilgenommen haben, die Anzahl der verschlüsselten Sitzungen und die Anzahl der aufgetretenen Fehler.
Metrisch Beschreibung Sessions Die Anzahl der derzeit aktiven Sitzungen mit diesem RDP-Client verknüpft Öffnet Die Häufigkeit, mit der dieser RDP-Client versucht hat eine Sitzung öffnen. Verschlüsselte Öffnungen Die Häufigkeit, mit der dieser RDP-Client hat versucht, eine verschlüsselte Sitzung zu öffnen. Fehler Die Anzahl der Fehler, die dieses RDP verhindert haben Client vom Öffnen einer Sitzung.
RDP-Servergruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt RDP Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur RDP-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
RDP Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Sessions
- Dieses Diagramm zeigt Ihnen, wann RDP-Server Sitzungen geöffnet haben oder an Sitzungen teilgenommen haben und wann
Fehler aufgetreten sind. Anhand dieser Informationen können Sie feststellen, wie aktiv RDP-Server zum
Zeitpunkt des Auftretens der Fehler waren.
Metrisch Beschreibung Sessions Die Anzahl der derzeit aktiven Sitzungen mit diesem RDP-Server verknüpft Öffnet Die Häufigkeit, mit der ein RDP-Client versucht hat öffne eine Sitzung auf diesem Server. Verschlüsselte Öffnungen Die Häufigkeit, mit der ein RDP-Client versucht hat um eine verschlüsselte Sitzung auf diesem Server zu öffnen. Fehler Die Anzahl der Fehler, die ein RDP verhindert haben Client vom Öffnen einer Sitzung auf diesem Server. - Gesamtzahl der Sitzungen
- Dieses Diagramm zeigt Ihnen die Gesamtzahl der Sitzungen, die von
RDP-Servern geöffnet wurden oder an denen teilgenommen haben, und wie viele Fehler aufgetreten sind.
Metrisch Beschreibung Sessions Die Anzahl der derzeit aktiven Sitzungen mit diesem RDP-Server verknüpft Öffnet Die Häufigkeit, mit der ein RDP-Client versucht hat öffne eine Sitzung auf diesem Server. Verschlüsselte Öffnungen Die Häufigkeit, mit der ein RDP-Client versucht hat um eine verschlüsselte Sitzung auf diesem Server zu öffnen. Fehler Die Anzahl der Fehler, die ein RDP verhindert haben Client vom Öffnen einer Sitzung auf diesem Server.
RDP-Details für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top Gruppenmitglieder (RDP-Server)
- Dieses Diagramm zeigt, welche RDP-Server in der Gruppe am aktivsten waren, indem die Gesamtzahl der RDP-Sitzungen nach Server aufgeteilt wurde.
RDP-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Sitzungen
- Dieses Diagramm zeigt Ihnen die Gesamtzahl der Sitzungen, die von
RDP-Servern geöffnet wurden oder an denen sie teilgenommen haben, die Anzahl der verschlüsselten Sitzungen und die Anzahl der aufgetretenen Fehler.
Metrisch Beschreibung Sessions Die Anzahl der derzeit aktiven Sitzungen mit diesem RDP-Server verknüpft Öffnet Die Häufigkeit, mit der ein RDP-Client versucht hat öffne eine Sitzung auf diesem Server. Verschlüsselte Öffnungen Die Häufigkeit, mit der ein RDP-Client versucht hat um eine verschlüsselte Sitzung auf diesem Server zu öffnen. Fehler Die Anzahl der Fehler, die ein RDP verhindert haben Client vom Öffnen einer Sitzung auf diesem Server.
Redis
Das ExtraHop-System sammelt Metriken über Redis Aktivität. Redis ist ein Open-Source-Datenstrukturserver. Redis-Clients kommunizieren mit Redis-Servern über das Redis Serialization Protocol (RESP).
| Hinweis: | Das ExtraHop-System enthält keine integrierten Redis-Metrikseiten für Anwendungen. Sie können jedoch Redis-Anwendungsmetriken auf einer benutzerdefinierten Seite hinzufügen und anzeigen oder Dashboard. |
Redis-Client-Seite
Auf dieser Seite werden Metrikdiagramme von angezeigt Redis Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
Redis Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann Redis-Fehler aufgetreten sind und wie viele Antworten der
Redis-Client erhalten hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Client zum Zeitpunkt des
Eingangs der Fehler war.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als Redis-Client agieren Fehler Die Anzahl der Redis-Fehler, die aufgrund eines unbekannter Befehl oder eine Operation wurde mit den falschen Daten ausgeführt typ. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der Redis-Antworten, die der Client erhalten hat, und wie
viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als Redis-Client agieren Fehler Die Anzahl der Redis-Fehler, die aufgrund eines unbekannter Befehl oder eine Operation wurde mit den falschen Daten ausgeführt typ. - Leistungsübersicht (95. Perzentil)
-
Dieses Diagramm zeigt das
95. Perzentil der Timing-Metriken. Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer
vollständigen Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange der Client gebraucht hat, um
Anfragen an das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange Server gebraucht haben, um
die Anfragen zu verarbeiten; und die Antwortübertragungszeit zeigt, wie lange Server gebraucht haben, um
Antworten an das Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Transferzeit anfragen Wenn das Gerät als Redis-Client fungiert, die Zeit zwischen der Erkennung des ersten Pakets und des letzten Paket gesendeter Anfragen durch das ExtraHop-System. Hohe Werte können auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Dauer der Bearbeitung Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als Redis-Client agieren Übertragungszeit der Antwort Wenn das Gerät als Redis-Client fungiert, die Zeit zwischen dem Erkennen des ersten Pakets und dem letzten Paket mit empfangenen Antworten durch das ExtraHop-System. Hohe Werte können auf eine starke Reaktion oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Redis-Clients an Paket, für das eine sofortige Bestätigung erforderlich war und wann der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn ein Client langsam reagiert, können Sie
anhand von Leistungsübersichtsmetriken herausfinden, ob das Netzwerk oder die Server das Problem verursachen.
Diese Metriken zeigen das 95. Perzentil der Zeit, die Server für die Bearbeitung von
Anfragen vom Client benötigten, im Vergleich zur 95. Perzentilzeit, die Pakete aus diesen
Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten.
Hohe Serververarbeitungszeiten deuten darauf hin, dass der Client langsame Server kontaktiert. Hohe
TCP-Roundtrip-Zeiten deuten darauf hin, dass der Client über langsame
Netzwerke kommuniziert.
Metrisch Beschreibung Bearbeitungszeit Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als Redis-Client agieren Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Redis-Clients an Paket, für das eine sofortige Bestätigung erforderlich war und wann der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Redis Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche Redis-Methoden der Client am häufigsten aufgerufen hat, indem es die Gesamtzahl der Anfragen aufschlüsselt, die der Client nach Methode gesendet hat.
- Die häufigsten Fehler
- Dieses Diagramm zeigt, welche Redis-Fehler der Client am häufigsten erhalten hat, indem die Anzahl der irrtümlich an den Client zurückgegebenen Antworten aufgeschlüsselt wird.
Redis-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des Redis-Servers Die Zeit zwischen dem letzten Byte der Anfrage und dem ersten Byte der Antwort. - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Bearbeitungszeit für den Client.
Metrisch Beschreibung Verarbeitungszeit des Redis-Servers Die Zeit zwischen dem letzten Byte der Anfrage und dem ersten Byte der Antwort. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Redis-Clients an Paket, für das eine sofortige Bestätigung erforderlich war und wann der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Hin- und Rückflugzeit für den Client.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Redis-Clients an Paket, für das eine sofortige Bestätigung erforderlich war und wann der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Metrische Gesamtwerte von Redis
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, sendet der Client möglicherweise mehr
Anfragen, als die Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen
, ob das Problem beim Netzwerk oder beim Server liegt, überprüfen Sie RTOs und Zero Windows in der
Netzwerk-Daten
Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Redis-Anfragen und -Antworten exakt gleich sein wird, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät gesendet hat, als fungiert als Redis-Client Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als Redis-Client agieren Abgebrochene Anfragen Die Anzahl der Anfragen, die nicht vollständig waren übertragen, weil das Zeitlimit für die Verbindung abgelaufen ist oder die Verbindung mit einem TCP geschlossen wurde Reset (RST) oder FIN Abgebrochene Antworten Die Anzahl der Antworten, die nicht vollständig waren übertragen, weil das Zeitlimit für die Verbindung abgelaufen ist oder die Verbindung mit einem TCP geschlossen wurde Reset (RST) oder FIN Fehler Die Anzahl der Redis-Fehler, die aufgrund eines unbekannter Befehl oder eine Operation wurde mit den falschen Daten ausgeführt typ. - Anfragen- und Antwortgrößen
- Dieses Diagramm zeigt die durchschnittliche Größe der Anfragen und Antworten.
Metrisch Beschreibung Größe der Anfrage Die Größenverteilung (in Byte) der Anfragen, die das Gerät als Redis-Client gesendet hat . Größe der Antwort Die Größenverteilung (in Byte) der Antworten, die das Gerät als Redis-Client gesendet hat .
Redis-Serverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt Redis Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
Redis Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann Redis-Fehler aufgetreten sind und wie viele Redis-Antworten der
Server gesendet hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Server zu dem Zeitpunkt war, als er die Fehler
zurückgab.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn Sie als Redis-Server agieren Fehler Die Anzahl der Fehler, die das Gerät als Redis-Server erhalten hat. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der Redis-Antworten, die der Server gesendet hat, und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn Sie als Redis-Server agieren Fehler Die Anzahl der Fehler, die das Gerät als Redis-Server erhalten hat. - Leistungsübersicht (95. Perzentil)
-
Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken
. Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer vollständigen
Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange Clients gebraucht haben, um Anfragen an
das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange der Server gebraucht hat, um Anfragen zu verarbeiten;
und die Antwortübertragungszeit zeigt, wie lange der Server gebraucht hat, um Antworten an das
Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Transferzeit anfragen Wenn das Gerät als Redis-Server fungiert, die Zeit zwischen der Erkennung des ersten Pakets und des letzten Paket empfangener Anfragen durch das ExtraHop-System. Hohe Werte können auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Bearbeitungszeit Die Anzahl der Antworten, die das Gerät gesendet hat wenn Sie als Redis-Server agieren Übertragungszeit der Antwort Wenn das Gerät als Redis-Server fungiert, die Zeit zwischen dem Erkennen des ersten Pakets und dem letzten Paket gesendeter Antworten durch das ExtraHop-System. Hohe Werte können auf eine starke Reaktion oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Redis-Servers an Paket, das eine sofortige Bestätigung erforderte und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn ein Server langsam reagiert, können Sie
anhand von Leistungsübersichtsmetriken herausfinden, ob das
Problem vom Netzwerk oder vom Server verursacht wird. Die Leistungsübersichtsmetriken zeigen das 95. Perzentil der Zeit, die der
Server für die Verarbeitung von Anfragen von Clients benötigte, im Vergleich zur 95. Perzentilzeit, die
Pakete aus diesen Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten.
Hohe Serververarbeitungszeiten deuten darauf hin, dass der Server langsam ist.
Hohe RTTs weisen darauf hin, dass der Server über langsame Netzwerke kommuniziert.
Metrisch Beschreibung Dauer der Bearbeitung Die Anzahl der Antworten, die das Gerät gesendet hat wenn Sie als Redis-Server agieren Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Redis-Servers an Paket, das eine sofortige Bestätigung erforderte und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Redis Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche Redis-Methoden auf dem Server am häufigsten aufgerufen wurden, indem die Gesamtzahl der Anfragen, die der Server erhalten hat, nach Methode aufgeteilt wird.
- Die häufigsten Fehlertypen
- Dieses Diagramm zeigt, welche Redis-Fehler der Server am häufigsten zurückgegeben hat, indem die Gesamtzahl der Antworten, die der Server versehentlich gesendet hat, aufgeschlüsselt wird.
Redis-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des Redis-Servers Die Zeit zwischen dem letzten Byte der Anfrage und dem ersten Byte der Antwort. - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Verarbeitungszeit für den Server.
Metrisch Beschreibung Verarbeitungszeit des Redis-Servers Die Zeit zwischen dem letzten Byte der Anfrage und dem ersten Byte der Antwort. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Redis-Servers an Paket, das eine sofortige Bestätigung erforderte und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Roundtrip-Zeit für den Server.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Redis-Servers an Paket, das eine sofortige Bestätigung erforderte und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Metrische Gesamtwerte von Redis
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr
Anfragen, als der Server verarbeiten kann, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen
, ob das Problem beim Netzwerk oder beim Server liegt, überprüfen Sie RTOs und Zero Windows in der
Netzwerk-Daten
Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Redis-Anfragen und -Antworten exakt gleich sein wird, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät erhalten hat wenn Sie als Redis-Server agieren Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn Sie als Redis-Server agieren Abgebrochene Anfragen Die Anzahl der Anfragen, die nicht vollständig waren übertragen, weil das Zeitlimit für die Verbindung abgelaufen ist oder die Verbindung mit einem TCP geschlossen wurde Reset (RST) oder FIN Abgebrochene Antworten Die Anzahl der Antworten, die nicht vollständig waren übertragen, weil das Zeitlimit für die Verbindung abgelaufen ist oder die Verbindung mit einem TCP geschlossen wurde Reset (RST) oder FIN Fehler Die Anzahl der Redis-Fehler, die aufgrund eines unbekannter Befehl oder eine Operation wurde mit den falschen Daten ausgeführt typ. - Anfragen- und Antwortgrößen
- Dieses Diagramm zeigt die durchschnittliche Größe der Anfragen und Antworten.
Metrisch Beschreibung Größe der Anfrage Die Verteilung der Größen (in Byte) der Anfragen, die das Gerät gesendet hat, als es als Redis-Server fungiert. Größe der Antwort Die Verteilung der Größen (in Byte) der Antworten, die das Gerät gesendet hat, als es als Redis-Server fungiert.
Redis-Client-Gruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt Redis Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
Redis Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann Redis-Fehler aufgetreten sind und wie viele Antworten die
Redis-Clients erhalten haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Kunden zu dem
Zeitpunkt waren, als sie die Fehler erhielten.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie im Abschnitt Redis-Metriken für Gruppen.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als Redis-Client agieren Fehler Die Anzahl der Fehler, die das Gerät als Redis-Client erhalten hat. - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele Redis-Antworten die Kunden erhalten haben und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als Redis-Client agieren Fehler Die Anzahl der Fehler, die das Gerät als Redis-Client erhalten hat.
Redis-Details für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (Redis-Kunden)
- Dieses Diagramm zeigt, welche Redis-Clients in der Gruppe am aktivsten waren, indem es die Gesamtzahl der Redis-Anfragen aufschlüsselt, die die Gruppe vom Client gesendet hat.
- Die besten Methoden
- Dieses Diagramm zeigt, welche Redis-Methoden die Gruppe am häufigsten aufgerufen hat, indem die Gesamtzahl der Anfragen, die die Gruppe gesendet hat, nach Methode aufgeteilt wird.
- Die häufigsten Fehler
- Dieses Diagramm zeigt, welche Redis-Fehler die Gruppe am häufigsten erhalten hat, indem die Anzahl der Antworten, die irrtümlich an die Gruppe zurückgegeben wurden, aufgeschlüsselt wird.
Redis-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Anfragen und Antworten
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden die Clients möglicherweise mehr Anfragen, als Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät gesendet hat, als fungiert als Redis-Client Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als Redis-Client agieren Abgebrochene Anfragen Die Anzahl der Anfragen, die nicht vollständig waren übertragen, weil das Zeitlimit für die Verbindung abgelaufen ist oder die Verbindung mit einem TCP geschlossen wurde Reset (RST) oder FIN Abgebrochene Antworten Die Anzahl der Antworten, die nicht vollständig waren übertragen, weil das Zeitlimit für die Verbindung abgelaufen ist oder die Verbindung mit einem TCP geschlossen wurde Reset (RST) oder FIN Antwortfehler Die Anzahl der Redis-Fehler, die aufgrund eines unbekannter Befehl oder eine Operation wurde mit den falschen Daten ausgeführt typ. - Verarbeitungszeit des Servers
-
Wenn sich eine Client-Gruppe langsam verhält, können Sie anhand der Serververarbeitungszeit herausfinden,
ob das Problem bei den Servern liegt. Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche
Zeit, die Server für die Bearbeitung von Anfragen von den Clients benötigten. Hohe
Serververarbeitungszeiten deuten darauf hin, dass die Clients langsame Server kontaktieren.
Metrisch Beschreibung Verarbeitungszeit des Servers Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als Redis-Client agieren
Redis-Servergruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt Redis Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
Redis Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann Redis-Fehler aufgetreten sind und wie viele Redis-Antworten die
Server gesendet haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Server zu dem Zeitpunkt waren, als
sie die Fehler gemeldet haben.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie im Abschnitt Redis-Metriken für Gruppen.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn Sie als Redis-Server agieren Fehler Die Anzahl der Fehler, die das Gerät als Redis-Server erhalten hat. - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele Redis-Antwortserver in der Gruppe gesendet haben und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn Sie als Redis-Server agieren Fehler Die Anzahl der Fehler, die das Gerät als Redis-Server erhalten hat.
Redis-Details für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (Redis-Server)
- Dieses Diagramm zeigt, welche Redis-Server in der Gruppe am aktivsten waren, indem die Gesamtzahl der von der Gruppe gesendeten Redis-Antworten pro Server aufgeschlüsselt wird.
- Die besten Methoden
- Dieses Diagramm zeigt, welche Redis-Methoden auf Servern in der Gruppe am häufigsten aufgerufen wurden, indem die Gesamtzahl der Anfragen, die die Gruppe erhalten hat, nach Methode aufgeteilt wird.
- Die häufigsten Fehler
- Dieses Diagramm zeigt, welche Redis-Fehler die Gruppen am häufigsten zurückgegeben haben, indem die Gesamtzahl der Antworten, die die Gruppe irrtümlich gesendet hat, aufgeschlüsselt wird.
Redis-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden Clients möglicherweise mehr Anfragen, als die Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät erhalten hat wenn Sie als Redis-Server agieren Antworten Die Anzahl der Antworten, die das Gerät gesendet hat wenn Sie als Redis-Server agieren Abgebrochene Anfragen Die Anzahl der Anfragen, die nicht vollständig waren übertragen, weil das Zeitlimit für die Verbindung abgelaufen ist oder die Verbindung mit einem TCP geschlossen wurde Reset (RST) oder FIN Abgebrochene Antworten Die Anzahl der Antworten, die nicht vollständig waren übertragen, weil das Zeitlimit für die Verbindung abgelaufen ist oder die Verbindung mit einem TCP geschlossen wurde Reset (RST) oder FIN Antwortfehler Die Anzahl der Redis-Fehler, die aufgrund eines unbekannter Befehl oder eine Operation wurde mit den falschen Daten ausgeführt typ. - Verarbeitungszeit des Servers
-
Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche Zeit, die die Server für die
Bearbeitung von Anfragen von Clients benötigten. Hohe Serververarbeitungszeiten deuten darauf hin, dass die Server in einer
Gruppe langsam sind.
Metrisch Beschreibung Verarbeitungszeit des Servers Die Anzahl der Antworten, die das Gerät gesendet hat wenn Sie als Redis-Server agieren
RFB
Das ExtraHop-System sammelt Messwerte zur Remote Framebuffer (RFB) -Aktivität. RFB ist ein Protokoll für den Fernzugriff auf eine grafische Benutzeroberfläche, mit der ein Client ein System auf einem anderen Computer anzeigen und steuern kann.
RFB-Kundenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt RFB Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
RFB-Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Sessions
- In diesem Diagramm wird angezeigt, wann RFB-Sitzungen auf dem Client aufgetreten sind, einschließlich Sitzungen mit
unbekannter Autorisierung und Sitzungen mit Fehlern.
Metrisch Beschreibung RFB-Clientsitzungen Die Anzahl der erfolgreichen Sitzungen Authentifizierung, an der dieser RFB-Client teilgenommen hat RFB-Client wird geöffnet Die Häufigkeit, mit der dieser RFB-Client versucht hat, eine Sitzung öffnen. RFB Client Unbekannte Authentifizierung Die Anzahl der Sitzungen mit einem unbekannten Autorisierungsstatus, die von diesem RFB-Client geöffnet wurden. Das ExtraHop-System hat es getan erkannte den Autorisierungstyp nicht, als die Sitzung geöffnet wurde. RFB-Client-Fehler Die Anzahl der Fehler, die diesen RFB verhindert haben Client daran, eine Sitzung mit erfolgreicher Authentifizierung zu öffnen. - Gesamtzahl der Sitzungen
- In diesem Diagramm wird die Gesamtzahl der RFB-Sitzungen auf dem Client angezeigt, einschließlich Sitzungen
mit unbekannter Autorisierung und Sitzungen mit Fehlern.
Metrisch Beschreibung RFB-Clientsitzungen Die Anzahl der erfolgreichen Sitzungen Authentifizierung, an der dieser RFB-Client teilgenommen hat RFB-Client wird geöffnet Die Häufigkeit, mit der dieser RFB-Client versucht hat, eine Sitzung öffnen. RFB Client Unbekannte Authentifizierung Die Anzahl der Sitzungen mit einem unbekannten Autorisierungsstatus, die von diesem RFB-Client geöffnet wurden. Das ExtraHop-System hat es getan erkannte den Autorisierungstyp nicht, als die Sitzung geöffnet wurde. RFB-Client-Fehler Die Anzahl der Fehler, die diesen RFB verhindert haben Client daran, eine Sitzung mit erfolgreicher Authentifizierung zu öffnen.
RFB Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die häufigsten Fehler
- In diesem Diagramm werden die häufigsten RFB-Fehlermeldungen angezeigt, die auf dem Client aufgetreten sind.
Metrisch Beschreibung RFB-Client-Fehler Die Anzahl der Fehler, die diesen RFB verhindert haben Client daran, eine Sitzung mit erfolgreicher Authentifizierung zu öffnen.
Dauer der RFB-Sitzung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Sitzungsdauer
- Dieses Diagramm zeigt, wie lange eine RFB-Sitzung auf dem Client geöffnet war. Sie können die Dauer nach Perzentil- oder Minimal- und Maximalwerten
filtern.
Metrisch Beschreibung Dauer der RFB-Client-Sitzung Die Zeit zwischen wann dieser RFB-Client hat eine Sitzung mit erfolgreicher Authentifizierung geöffnet und geschlossen. - Dauer der Sitzung
- In diesem Diagramm wird die durchschnittliche Dauer von RFB-Sitzungen auf dem Client angezeigt.
Metrisch Beschreibung Dauer der RFB-Client-Sitzung Die Zeit zwischen wann dieser RFB-Client hat eine Sitzung mit erfolgreicher Authentifizierung geöffnet und geschlossen.
Metrische RFB-Gesamtwerte
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Sitzungen
- In diesem Diagramm wird die Gesamtzahl der RFB-Sitzungen auf dem Client angezeigt, einschließlich Sitzungen
mit unbekannter Autorisierung und Sitzungen mit Fehlern.
Metrisch Beschreibung RFB-Clientsitzungen Die Anzahl der erfolgreichen Sitzungen Authentifizierung, an der dieser RFB-Client teilgenommen hat RFB-Client wird geöffnet Die Häufigkeit, mit der dieser RFB-Client versucht hat, eine Sitzung öffnen. RFB Client Unbekannte Authentifizierung Die Anzahl der Sitzungen mit einem unbekannten Autorisierungsstatus, die von diesem RFB-Client geöffnet wurden. Das ExtraHop-System hat es getan erkannte den Autorisierungstyp nicht, als die Sitzung geöffnet wurde. RFB-Client-Fehler Die Anzahl der Fehler, die diesen RFB verhindert haben Client daran, eine Sitzung mit erfolgreicher Authentifizierung zu öffnen.
RFB-Serverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt RFB Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
RFB-Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Sessions
- In diesem Diagramm wird angezeigt, wann RFB-Sitzungen auf dem Server aufgetreten sind, einschließlich Sitzungen mit
unbekannter Autorisierung und Sitzungen mit Fehlern.
Metrisch Beschreibung RFB-Serversitzungen Die Anzahl der erfolgreichen Sitzungen Authentifizierung, an der dieser RFB-Server teilgenommen hat RFB Server wird geöffnet Gibt an, wie oft dieser RFB-Server versucht hat eine Sitzung öffnen. RFB Server Unbekannte Authentifizierung Die Anzahl der Sitzungen mit einem unbekannten Autorisierungsstatus, die von diesem RFB-Server geöffnet wurden. Das ExtraHop-System hat es getan Ich habe den Autorisierungstyp nicht erkannt, als die Sitzung geöffnet wurde. RFB-Serverfehler Die Anzahl der Fehler, die diesen RFB verhindert haben Server vor dem Öffnen einer Sitzung mit erfolgreicher Authentifizierung. - Gesamtzahl der Sitzungen
- In diesem Diagramm wird die Gesamtzahl der RFB-Sitzungen auf dem Server angezeigt, einschließlich Sitzungen
mit unbekannter Autorisierung und Sitzungen mit Fehlern.
Metrisch Beschreibung RFB-Serversitzungen Die Anzahl der erfolgreichen Sitzungen Authentifizierung, an der dieser RFB-Server teilgenommen hat RFB Server wird geöffnet Gibt an, wie oft dieser RFB-Server versucht hat eine Sitzung öffnen. RFB Server Unbekannte Authentifizierung Die Anzahl der Sitzungen mit einem unbekannten Autorisierungsstatus, die von diesem RFB-Server geöffnet wurden. Das ExtraHop-System hat es getan Ich habe den Autorisierungstyp nicht erkannt, als die Sitzung geöffnet wurde. RFB-Serverfehler Die Anzahl der Fehler, die diesen RFB verhindert haben Server vor dem Öffnen einer Sitzung mit erfolgreicher Authentifizierung.
RFB Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die häufigsten Fehler
- Dieses Diagramm zeigt die häufigsten RFB-Fehlermeldungen, die auf dem Server aufgetreten sind.
Metrisch Beschreibung RFB-Serverfehler Die Anzahl der Fehler, die diesen RFB verhindert haben Server vor dem Öffnen einer Sitzung mit erfolgreicher Authentifizierung.
Dauer der RFB-Sitzung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Sitzungsdauer
- Dieses Diagramm zeigt, wie lange eine RFB-Sitzung auf dem Server geöffnet war. Sie können die Dauer nach Perzentil- oder Minimal- und Maximalwerten
filtern.
Metrisch Beschreibung Dauer der RFB-Serversitzung Die Zeit zwischen wann dieser RFB-Server hat eine Sitzung mit erfolgreicher Authentifizierung geöffnet und geschlossen. - Dauer der Sitzung
- Dieses Diagramm zeigt die durchschnittliche Dauer von RFB-Sitzungen auf dem Server.
Metrisch Beschreibung Dauer der RFB-Serversitzung Die Zeit zwischen wann dieser RFB-Server hat eine Sitzung mit erfolgreicher Authentifizierung geöffnet und geschlossen.
Metrische RFB-Gesamtwerte
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Sitzungen
- In diesem Diagramm wird die Gesamtzahl der RFB-Sitzungen auf dem Server angezeigt, einschließlich Sitzungen
mit unbekannter Autorisierung und Sitzungen mit Fehlern.
Metrisch Beschreibung RFB-Serversitzungen Die Anzahl der erfolgreichen Sitzungen Authentifizierung, an der dieser RFB-Server teilgenommen hat RFB Server wird geöffnet Gibt an, wie oft dieser RFB-Server versucht hat eine Sitzung öffnen. RFB Server Unbekannte Authentifizierung Die Anzahl der Sitzungen mit einem unbekannten Autorisierungsstatus, die von diesem RFB-Server geöffnet wurden. Das ExtraHop-System hat es getan Ich habe den Autorisierungstyp nicht erkannt, als die Sitzung geöffnet wurde. RFB-Serverfehler Die Anzahl der Fehler, die diesen RFB verhindert haben Server vor dem Öffnen einer Sitzung mit erfolgreicher Authentifizierung.
RFB-Clientgruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt RFB Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
RFB-Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Sessions
- In diesem Diagramm wird angezeigt, wann RFB-Sitzungen auf Clients in der Gruppe aufgetreten sind, einschließlich
Sitzungen mit unbekannter Autorisierung und Sitzungen mit Fehlern.
Metrisch Beschreibung RFB-Clientsitzungen Die Anzahl der erfolgreichen Sitzungen Authentifizierung, an der dieser RFB-Client teilgenommen hat RFB-Client wird geöffnet Die Häufigkeit, mit der dieser RFB-Client versucht hat, eine Sitzung öffnen. RFB Client Unbekannte Authentifizierung Die Anzahl der Sitzungen mit einem unbekannten Autorisierungsstatus, die von diesem RFB-Client geöffnet wurden. Das ExtraHop-System hat es getan erkannte den Autorisierungstyp nicht, als die Sitzung geöffnet wurde. RFB-Client-Fehler Die Anzahl der Fehler, die diesen RFB verhindert haben Client daran, eine Sitzung mit erfolgreicher Authentifizierung zu öffnen. - Gesamtzahl der Sitzungen
- Dieses Diagramm zeigt die Gesamtzahl der RFB-Sitzungen auf Clients in der Gruppe,
einschließlich Sitzungen mit unbekannter Autorisierung und Sitzungen mit Fehlern.
Metrisch Beschreibung RFB-Clientsitzungen Die Anzahl der erfolgreichen Sitzungen Authentifizierung, an der dieser RFB-Client teilgenommen hat RFB-Client wird geöffnet Die Häufigkeit, mit der dieser RFB-Client versucht hat, eine Sitzung öffnen. RFB Client Unbekannte Authentifizierung Die Anzahl der Sitzungen mit einem unbekannten Autorisierungsstatus, die von diesem RFB-Client geöffnet wurden. Das ExtraHop-System hat es getan erkannte den Autorisierungstyp nicht, als die Sitzung geöffnet wurde. RFB-Client-Fehler Die Anzahl der Fehler, die diesen RFB verhindert haben Client daran, eine Sitzung mit erfolgreicher Authentifizierung zu öffnen.
RFB-Details für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (RFB-Kunden)
- In diesem Diagramm werden die Clients in der Gruppe angezeigt, die die meisten
RFB-Sitzungen abgeschlossen haben.
Metrisch Beschreibung RFB-Clientsitzungen Die Anzahl der erfolgreichen Sitzungen Authentifizierung, an der dieser RFB-Client teilgenommen hat
RFB-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Sitzungen
- Dieses Diagramm zeigt die Gesamtzahl der RFB-Sitzungen auf Clients in der Gruppe,
einschließlich Sitzungen mit unbekannter Autorisierung und Sitzungen mit Fehlern.
Metrisch Beschreibung RFB-Clientsitzungen Die Anzahl der erfolgreichen Sitzungen Authentifizierung, an der dieser RFB-Client teilgenommen hat RFB-Client wird geöffnet Die Häufigkeit, mit der dieser RFB-Client versucht hat, eine Sitzung öffnen. RFB Client Unbekannte Authentifizierung Die Anzahl der Sitzungen mit einem unbekannten Autorisierungsstatus, die von diesem RFB-Client geöffnet wurden. Das ExtraHop-System hat es getan erkannte den Autorisierungstyp nicht, als die Sitzung geöffnet wurde. RFB-Client-Fehler Die Anzahl der Fehler, die diesen RFB verhindert haben Client daran, eine Sitzung mit erfolgreicher Authentifizierung zu öffnen.
RFB-Servergruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt RFB Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
RFB-Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Sessions
- In diesem Diagramm wird angezeigt, wann RFB-Sitzungen auf Servern in der Gruppe stattfanden, einschließlich
Sitzungen mit unbekannter Autorisierung und Sitzungen mit Fehlern.
Metrisch Beschreibung RFB-Serversitzungen Die Anzahl der erfolgreichen Sitzungen Authentifizierung, an der dieser RFB-Server teilgenommen hat RFB Server wird geöffnet Gibt an, wie oft dieser RFB-Server versucht hat eine Sitzung öffnen. RFB Server Unbekannte Authentifizierung Die Anzahl der Sitzungen mit einem unbekannten Autorisierungsstatus, die von diesem RFB-Server geöffnet wurden. Das ExtraHop-System hat es getan Ich habe den Autorisierungstyp nicht erkannt, als die Sitzung geöffnet wurde. RFB-Serverfehler Die Anzahl der Fehler, die diesen RFB verhindert haben Server vor dem Öffnen einer Sitzung mit erfolgreicher Authentifizierung. - Gesamtzahl der Sitzungen
- Dieses Diagramm zeigt die Gesamtzahl der RFB-Sitzungen auf Servern in der Gruppe,
einschließlich Sitzungen mit unbekannter Autorisierung und Sitzungen mit Fehlern.
Metrisch Beschreibung RFB-Serversitzungen Die Anzahl der erfolgreichen Sitzungen Authentifizierung, an der dieser RFB-Server teilgenommen hat RFB Server wird geöffnet Gibt an, wie oft dieser RFB-Server versucht hat eine Sitzung öffnen. RFB Server Unbekannte Authentifizierung Die Anzahl der Sitzungen mit einem unbekannten Autorisierungsstatus, die von diesem RFB-Server geöffnet wurden. Das ExtraHop-System hat es getan Ich habe den Autorisierungstyp nicht erkannt, als die Sitzung geöffnet wurde. RFB-Serverfehler Die Anzahl der Fehler, die diesen RFB verhindert haben Server vor dem Öffnen einer Sitzung mit erfolgreicher Authentifizierung.
RFB-Details für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (RFB-Kunden)
- In diesem Diagramm werden die Server in der Gruppe angezeigt, die die meisten
RFB-Sitzungen abgeschlossen haben.
Metrisch Beschreibung RFB-Serversitzungen Die Anzahl der erfolgreichen Sitzungen Authentifizierung, an der dieser RFB-Server teilgenommen hat
RFB-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Sitzungen
- Dieses Diagramm zeigt die Gesamtzahl der RFB-Sitzungen auf Servern in der Gruppe,
einschließlich Sitzungen mit unbekannter Autorisierung und Sitzungen mit Fehlern.
Metrisch Beschreibung RFB-Serversitzungen Die Anzahl der erfolgreichen Sitzungen Authentifizierung, an der dieser RFB-Server teilgenommen hat RFB Server wird geöffnet Gibt an, wie oft dieser RFB-Server versucht hat eine Sitzung öffnen. RFB Server Unbekannte Authentifizierung Die Anzahl der Sitzungen mit einem unbekannten Autorisierungsstatus, die von diesem RFB-Server geöffnet wurden. Das ExtraHop-System hat es getan Ich habe den Autorisierungstyp nicht erkannt, als die Sitzung geöffnet wurde. RFB-Serverfehler Die Anzahl der Fehler, die diesen RFB verhindert haben Server vor dem Öffnen einer Sitzung mit erfolgreicher Authentifizierung.
RTCP
Das ExtraHop-System sammelt Metriken über das Real-Time Transport Control Protocol (RTCP) Aktivität. RTCP ist ein Protokoll, das Statistiken für Streaming-Audio- und Videodaten überwacht, die über das RTP-Protokoll übertragen werden.
RTCP-Anwendungsseite
Auf dieser Seite werden Metrikdiagramme von angezeigt RTCP Verkehr, der mit einem Anwendungscontainer in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
RTCP Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Absendernachrichten
-
Metrisch Beschreibung Nachrichten des Absenders Die Anzahl der Pakete, die vom Absender vom Beginn der Übertragung bis zu dem Zeitpunkt, an dem dieser Absender ein Paket meldet wurde generiert. Absender Drops Die Anzahl der Pakete, die verloren gegangen sind von der Absender seit Beginn des Empfangs. - Gesamtzahl der Empfängernachrichten
-
Metrisch Beschreibung Empfängernachrichten Die Anzahl der Pakete, die vom Empfänger vom Beginn der Übertragung bis zu dem Zeitpunkt, an dem dieser Empfänger meldet Paket wurde generiert. Empfänger fällt aus Die Anzahl der Pakete, die verloren gegangen sind seit Beginn des Empfangs. - Nachrichten des Absenders
-
Metrisch Beschreibung Nachrichten des Absenders Die Anzahl der Pakete, die vom Absender vom Beginn der Übertragung bis zu dem Zeitpunkt, an dem dieser Absender ein Paket meldet wurde generiert. Absender Drops Die Anzahl der Pakete, die verloren gegangen sind von der Absender seit Beginn des Empfangs. - Empfängernachrichten
-
Metrisch Beschreibung Empfängernachrichten Die Anzahl der Pakete, die vom Empfänger vom Beginn der Übertragung bis zu dem Zeitpunkt, an dem dieser Empfänger meldet Paket wurde generiert. Empfänger fällt aus Die Anzahl der Pakete, die verloren gegangen sind seit Beginn des Empfangs.
RTCP-Jitter
Die folgenden Diagramme sind in dieser Region verfügbar:
- Absender-Jitter
-
Metrisch Beschreibung Absender: Jitter melden Eine Schätzung der statistischen Varianz der Zwischenankunftszeit der RTP-Pakete, gemessen in Zeitstempeleinheiten und ausgedrückt als eine Ganzzahl ohne Vorzeichen - Empfänger-Jitter
-
Metrisch Beschreibung Empfängerbericht Jitter Eine Schätzung der statistischen Varianz der Zwischenankunftszeit der RTCP-Pakete, gemessen in Zeitstempeleinheiten und ausgedrückt als eine Ganzzahl ohne Vorzeichen
RTCP-Nachrichtentypen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Arten von Nachrichten
-
Metrisch Beschreibung Nachrichten nach Typ Die Anzahl der RTCP-Einträge, aufgeschlüsselt nach Nachrichtentyp.
Gesamtwerte der RTCP-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Nachrichten insgesamt
-
Metrisch Beschreibung Absender-Meldungen Die Anzahl der Pakete, die vom Absender vom Beginn der Übertragung bis zu dem Zeitpunkt, an dem dieser Absender ein Paket meldet wurde generiert. Absenderbericht gelöscht Die Anzahl der Pakete, die verloren gegangen sind von der Absender seit Beginn des Empfangs. Empfänger-Berichtsnachrichten Die Anzahl der Pakete, die vom Empfänger vom Beginn der Übertragung bis zu dem Zeitpunkt, an dem dieser Empfänger meldet Paket wurde generiert. Empfängerbericht wird gelöscht Die Anzahl der Pakete, die verloren gegangen sind seit Beginn des Empfangs. - RTCP-Netzwerkmetriken
-
Metrisch Beschreibung Byte Die Anzahl der Goodput-Bytes, die RTCP zugeordnet sind Übertragungen L2-Byte Die Anzahl der L2-Bytes, die RTCP zugeordnet sind Übertragungen Pakete Die Anzahl der mit RTCP verknüpften Pakete Übertragungen
RTCP-Geräteseite
Auf dieser Seite werden Metrikdiagramme von angezeigt RTCP Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
RTCP Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Zusammenfassung In
- In diesem Diagramm wird die Gesamtzahl der eingehenden Sender- und Empfängernachrichten angezeigt.
Metrisch Beschreibung Nachrichten des Absenders Die Anzahl der eingehenden Pakete, die übertragen wurden von der Absender vom Beginn der Übertragung bis zum Zeitpunkt der Meldung durch diesen Absender Paket wurde generiert. Absender Drops Die Anzahl der eingehenden Pakete, die seit Beginn des Empfangs vom Absender verloren gegangen. Empfängernachrichten Die Anzahl der eingehenden Pakete, die übertragen wurden von der Empfänger vom Beginn der Übertragung bis zu dem Zeitpunkt, an dem dieser Empfänger meldet Paket wurde generiert. Empfänger fällt aus Die Anzahl der eingehenden Pakete, die seit Beginn des Empfangs vom Empfänger verloren gegangen. - Zusammenfassung raus
- In diesem Diagramm wird die Gesamtzahl der ausgehenden Sender- und Empfängernachrichten angezeigt.
Metrisch Beschreibung Nachrichten des Absenders Die Anzahl der übertragenen ausgehenden Pakete durch den Absender vom Beginn der Übertragung bis zu dem Zeitpunkt, an dem dieser Absender die Meldung übermittelt Paket wurde generiert. Absender Drops Die Anzahl der ausgehenden Pakete, die seit Beginn des Empfangs vom Absender verloren gegangen. Empfängernachrichten Die Anzahl der übertragenen ausgehenden Pakete vom Empfänger vom Beginn der Übertragung bis zum Zeitpunkt dieses Empfängers Berichtspaket wurde generiert. Empfänger fällt aus Die Anzahl der ausgehenden Pakete, die seit Beginn des Empfangs vom Empfänger verloren gegangen. - Eingehende Nachrichten
- Dieses Diagramm zeigt Ihnen, wann eingehende Sender- und Empfängernachrichten
übertragen wurden.
Metrisch Beschreibung Nachrichten des Absenders Die Anzahl der eingehenden Pakete, die übertragen wurden von der Absender vom Beginn der Übertragung bis zum Zeitpunkt der Meldung durch diesen Absender Paket wurde generiert. Absender Drops Die Anzahl der eingehenden Pakete, die seit Beginn des Empfangs vom Absender verloren gegangen. Empfängernachrichten Die Anzahl der eingehenden Pakete, die übertragen wurden von der Empfänger vom Beginn der Übertragung bis zu dem Zeitpunkt, an dem dieser Empfänger meldet Paket wurde generiert. Empfänger fällt aus Die Anzahl der eingehenden Pakete, die seit Beginn des Empfangs vom Empfänger verloren gegangen. - Ausgehende Nachrichten
- Dieses Diagramm zeigt Ihnen, wann ausgehende Sender- und Empfängernachrichten
übertragen wurden.
Metrisch Beschreibung Nachrichten des Absenders Die Anzahl der übertragenen ausgehenden Pakete durch den Absender vom Beginn der Übertragung bis zu dem Zeitpunkt, an dem dieser Absender die Meldung übermittelt Paket wurde generiert. Absender Drops Die Anzahl der ausgehenden Pakete, die seit Beginn des Empfangs vom Absender verloren gegangen. Empfängernachrichten Die Anzahl der übertragenen ausgehenden Pakete vom Empfänger vom Beginn der Übertragung bis zum Zeitpunkt dieses Empfängers Berichtspaket wurde generiert. Empfänger fällt aus Die Anzahl der ausgehenden Pakete, die seit Beginn des Empfangs vom Empfänger verloren gegangen.
RTCP-Jitter
Die folgenden Diagramme sind in dieser Region verfügbar:
- Jitter rein
- Zeigt Schätzungen der statistischen Varianz der Interankunftszeit der eingehenden Pakete an.
Metrisch Beschreibung Absender: Jitter In melden Eine Schätzung der statistischen Varianz von die Zwischenankunftszeit der eingehenden Pakete, gemessen in Zeitstempeleinheiten und ausgedrückt als Ganzzahl ohne Vorzeichen Empfänger meldet Jitter In Eine Schätzung der statistischen Varianz von die Zwischenankunftszeit der eingehenden Pakete, gemessen in Zeitstempeleinheiten und ausgedrückt als Ganzzahl ohne Vorzeichen - Jitter raus
- Zeigt Schätzungen der statistischen Varianz der Interankunftszeit der ausgehenden Pakete an.
Metrisch Beschreibung Absender Jitter Out melden Eine Schätzung der statistischen Varianz der Zwischenankunftszeit der ausgehenden Pakete, gemessen in Zeitstempeleinheiten und ausgedrückt als Ganzzahl ohne Vorzeichen Empfänger meldet Jitter Out Eine Schätzung der statistischen Varianz der Zwischenankunftszeit der ausgehenden Pakete, gemessen in Zeitstempeleinheiten und ausgedrückt als Ganzzahl ohne Vorzeichen
Arten von Nachrichten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Nachrichtentypen in
- Die am häufigsten vom Gerät empfangenen Nachrichtentypen. Das ExtraHop-System berechnet diese
Werte, indem es die Gesamtzahl der vom Client empfangenen RTCP-Nachrichten betrachtet und diese
Nachrichten nach Typ aufteilt.
Metrisch Beschreibung Nachrichtentypen in Die Anzahl der RTCP-Einträge, aufgeschlüsselt nach Nachrichtentyp. - Nachrichtentypen aus
- Die am häufigsten vom Gerät gesendeten Nachrichtentypen. Das ExtraHop-System berechnet diese Werte, indem es die Gesamtzahl der vom Client gesendeten RTCP-Nachrichten betrachtet und diese Nachrichten nach Typ aufteilt.
RTCP-Gerätegruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt RTCP Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
RTCP-Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Zusammenfassung In
- Zeigt die Gesamtzahl der eingehenden Sender- und Empfängernachrichten für die
Gruppe an.
Metrisch Beschreibung Nachrichten des Absenders Die Anzahl der eingehenden Pakete, die übertragen wurden von der Absender vom Beginn der Übertragung bis zum Zeitpunkt der Meldung durch diesen Absender Paket wurde generiert. Absender Drops Die Anzahl der eingehenden Pakete, die seit Beginn des Empfangs vom Absender verloren gegangen. Empfängernachrichten Die Anzahl der eingehenden Pakete, die übertragen wurden von der Empfänger vom Beginn der Übertragung bis zu dem Zeitpunkt, an dem dieser Empfänger meldet Paket wurde generiert. Empfänger fällt aus Die Anzahl der eingehenden Pakete, die seit Beginn des Empfangs vom Empfänger verloren gegangen. - Zusammenfassung Raus
- Zeigt die Gesamtzahl der ausgehenden Sender- und Empfängernachrichten für die Gruppe an.
Metrisch Beschreibung Nachrichten des Absenders Die Anzahl der übertragenen ausgehenden Pakete durch den Absender vom Beginn der Übertragung bis zu dem Zeitpunkt, an dem dieser Absender die Meldung übermittelt Paket wurde generiert. Absender Drops Die Anzahl der ausgehenden Pakete, die seit Beginn des Empfangs vom Absender verloren gegangen. Empfängernachrichten Die Anzahl der übertragenen ausgehenden Pakete vom Empfänger vom Beginn der Übertragung bis zum Zeitpunkt dieses Empfängers Berichtspaket wurde generiert. Empfänger fällt aus Die Anzahl der ausgehenden Pakete, die seit Beginn des Empfangs vom Empfänger verloren gegangen.
RTP
Das ExtraHop-System sammelt Metriken über das Real-Time Transport Protocol (RTP) Aktivität. RTP ist ein Protokoll, das das standardisierte Paketformat für die Echtzeitübertragung von Streaming-Audio und Video definiert.
RTP-Anwendungsseite
Auf dieser Seite werden Metrikdiagramme von angezeigt RTP Verkehr, der mit einem Anwendungscontainer in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
RTP-Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Nachrichten
-
Metrisch Beschreibung Nachrichten Die Anzahl der mit RTP verknüpften Nachrichten Übertragungen Duplikate Die Anzahl der doppelten Nachrichten, die mit RTP verknüpft sind Übertragungen Außer Betrieb Anzahl der Pakete, die RTP-Übertragungen zugeordnet sind wo die Sequenznummer nicht mit der Sequenznummer übereinstimmte, die das ExtraHop-System hatte erwartet. Die Neuordnung könnte am Entstehungsort eingeführt worden sein oder ein Vermittler. Dies kann zu einer verminderten Anrufqualität führen. Tropfen Die Anzahl der mit RTP verknüpften Pakete Übertragungen, die während des Transports verloren gingen - Nachrichten insgesamt
-
Metrisch Beschreibung Nachrichten Die Anzahl der mit RTP verknüpften Nachrichten Übertragungen - Mittlerer Meinungswert (MOS)
-
Metrisch Beschreibung Mittlerer Meinungswert (MOS) Der durchschnittliche Meinungswert, der für Pakete berechnet wurde verbunden mit RTP-Übertragungen. Das MOS ist eine Schätzung der RTP-Stream-Leistung und der VoIP-Anrufqualität. Die MOS-Werte liegen zwischen 1 und 5, wobei 5 die höchste wahrgenommene Gesprächsqualität darstellt. Das ExtraHop-System berechnet den MOS auf der Grundlage von Delay, Loss, Discard, Jitter und Codec. Der MOS wird nur für die folgenden Codecs berechnet: ITU-T G.711 PCMU Audio, ITU-T G.711 PCMA Audio, ITU-T G.729 Audio und GSM 6.10 Audio.
RTP-Jitter
Die folgenden Diagramme sind in dieser Region verfügbar:
- Zittern
-
Metrisch Beschreibung Zittern Eine Schätzung der statistischen Varianz der Die Zwischenankunftszeit von RTP-Paketen, gemessen in Zeitstempeleinheiten und ausgedrückt als Ganzzahl ohne Vorzeichen
RTP-Codecs
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Codecs
- Dieses Diagramm zeigt die Anzahl der von der Anwendung gesendeten und empfangenen Nachrichten, aufgeteilt nach Codec.
- Codecs mit den meisten Drops
- Dieses Diagramm zeigt die Anzahl der Pakete im Zusammenhang mit RTP-Übertragungen, die während der Übertragung verloren gegangen sind, aufgeschlüsselt nach Codec.
- Codecs mit dem meisten Jitter
- Dieses Diagramm zeigt die Codecs mit der größten statistischen Varianz der Interarrival-Zeit von RTP-Paketen.
Gesamtwerte der RTP-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Nachrichten insgesamt
-
Metrisch Beschreibung Nachrichten Die Anzahl der mit RTP verknüpften Nachrichten Übertragungen Duplikate Die Anzahl der doppelten Nachrichten, die mit RTP verknüpft sind Übertragungen Außer Betrieb Anzahl der Pakete, die RTP-Übertragungen zugeordnet sind wo die Sequenznummer nicht mit der Sequenznummer übereinstimmte, die das ExtraHop-System hatte erwartet. Die Neuordnung könnte am Entstehungsort eingeführt worden sein oder ein Vermittler. Dies kann zu einer verminderten Anrufqualität führen. Tropfen Die Anzahl der mit RTP verknüpften Pakete Übertragungen, die während des Transports verloren gingen - RTP-Netzwerkmetriken
-
Metrisch Beschreibung L2-Byte Die Anzahl der mit RTP verknüpften L2-Bytes Übertragungen Gute Ausgangs-Bytes Die Anzahl der Goodput-Bytes, die RTP zugeordnet sind Übertragungen Pakete Die Anzahl der mit RTP verknüpften Pakete Übertragungen
RTP-Geräteseite
Auf dieser Seite werden Metrikdiagramme von angezeigt RTP Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
Region
Die folgenden Diagramme sind in dieser Region verfügbar:
- Zusammenfassung In
-
Metrisch Beschreibung Mittlerer Meinungsscore Der für Pakete berechnete mittlere Meinungswert (MOS) vom RTP-Gerät empfangen. Das MOS ist eine Schätzung der RTP-Stream-Leistung und der VoIP-Anrufqualität. Die MOS-Werte liegen zwischen 1 und 5, wobei 5 die höchste wahrgenommene Gesprächsqualität darstellt. Das ExtraHop-System berechnet den MOS auf der Grundlage von Delay, Loss, Discard, Jitter und Codec. Der MOS wird nur für die folgenden Codecs berechnet: ITU-T G.711 PCMU Audio, ITU-T G.711 PCMA Audio, ITU-T G.729 Audio und GSM 6.10 Audio. Nachrichten Die Anzahl der vom RTP empfangenen Nachrichten Gerät. - Zusammenfassung Raus
-
Metrisch Beschreibung Mittlerer Meinungsscore Der für Pakete berechnete mittlere Meinungswert (MOS) gesendet vom RTP-Gerät. Das MOS ist eine Schätzung der RTP-Stream-Leistung und der VoIP-Anrufqualität. Die MOS-Werte liegen zwischen 1 und 5, wobei 5 die höchste wahrgenommene Gesprächsqualität darstellt. Das ExtraHop-System berechnet den MOS auf der Grundlage von Delay, Loss, Discard, Jitter und Codec. Der MOS wird nur für die folgenden Codecs berechnet: ITU-T G.711 PCMU Audio, ITU-T G.711 PCMA Audio, ITU-T G.729 Audio und GSM 6.10 Audio. Nachrichten Die Anzahl der vom RTP gesendeten Nachrichten Gerät.
- MOS-Eingang
-
Metrisch Beschreibung Mittlerer Meinungsscore Der für Pakete berechnete mittlere Meinungswert (MOS) vom RTP-Gerät empfangen. Das MOS ist eine Schätzung der RTP-Stream-Leistung und der VoIP-Anrufqualität. Die MOS-Werte liegen zwischen 1 und 5, wobei 5 die höchste wahrgenommene Gesprächsqualität darstellt. Das ExtraHop-System berechnet den MOS auf der Grundlage von Delay, Loss, Discard, Jitter und Codec. Der MOS wird nur für die folgenden Codecs berechnet: ITU-T G.711 PCMU Audio, ITU-T G.711 PCMA Audio, ITU-T G.729 Audio und GSM 6.10 Audio. - MOS-Ausgang
-
Metrisch Beschreibung Mittlerer Meinungsscore Der für Pakete berechnete mittlere Meinungswert (MOS) gesendet vom RTP-Gerät. Das MOS ist eine Schätzung der RTP-Stream-Leistung und der VoIP-Anrufqualität. Die MOS-Werte liegen zwischen 1 und 5, wobei 5 die höchste wahrgenommene Gesprächsqualität darstellt. Das ExtraHop-System berechnet den MOS auf der Grundlage von Delay, Loss, Discard, Jitter und Codec. Der MOS wird nur für die folgenden Codecs berechnet: ITU-T G.711 PCMU Audio, ITU-T G.711 PCMA Audio, ITU-T G.729 Audio und GSM 6.10 Audio. - Eingehende Nachrichten
-
Metrisch Beschreibung Nachrichten Die Anzahl der vom RTP empfangenen Nachrichten Gerät. Duplikate Die Anzahl der doppelten Nachrichten, die vom RTP-Gerät Außer Betrieb Anzahl der Pakete, die von dem Gerät empfangen wurden, auf dem das RTP Die Sequenznummer stimmte nicht mit der Sequenznummer überein, die das ExtraHop-System hatte erwartend. Die Neuordnung wurde möglicherweise am Gerät selbst oder durch einen Zwischengerät. Dies kann zu einer verminderten Anrufqualität führen. Tropfen Die Anzahl der Pakete, die vor der Übertragung verloren gegangen sind Empfang durch das RTP-Gerät - Ausgehende Nachrichten
-
Metrisch Beschreibung Nachrichten Die Anzahl der vom RTP gesendeten Nachrichten Gerät. Duplikate Die Anzahl der doppelten Nachrichten, die vom RTP gesendet wurden Gerät. Außer Betrieb Anzahl der Pakete, die von dem Gerät gesendet wurden, auf dem Die RTP-Sequenznummer stimmte nicht mit der Sequenznummer des ExtraHop-Systems überein erwartend. Die Neuordnung wurde möglicherweise am Gerät selbst oder durch einen Zwischengerät. Dies kann zu einer verminderten Anrufqualität führen. Tropfen Die Anzahl der vom RTP-Gerät gesendeten Pakete, die gingen auf dem Transit verloren.
Zittern
Die folgenden Diagramme sind in dieser Region verfügbar:
- Jitter rein
-
Metrisch Beschreibung Absender: Jitter In melden Eine Schätzung der statistischen Varianz von die Zwischenankunftszeit der eingehenden Pakete, gemessen in Zeitstempeleinheiten und ausgedrückt als Ganzzahl ohne Vorzeichen Empfänger meldet Jitter In Eine Schätzung der statistischen Varianz von die Zwischenankunftszeit der eingehenden Pakete, gemessen in Zeitstempeleinheiten und ausgedrückt als Ganzzahl ohne Vorzeichen - Jitter raus
-
Metrisch Beschreibung Absender Jitter Out melden Eine Schätzung der statistischen Varianz der Zwischenankunftszeit der ausgehenden Pakete, gemessen in Zeitstempeleinheiten und ausgedrückt als Ganzzahl ohne Vorzeichen Empfänger meldet Jitter Out Eine Schätzung der statistischen Varianz der Zwischenankunftszeit der ausgehenden Pakete, gemessen in Zeitstempeleinheiten und ausgedrückt als Ganzzahl ohne Vorzeichen
RTP-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- RTP-Eingang
-
Metrisch Beschreibung Nachrichten Die Anzahl der vom RTP empfangenen Nachrichten Gerät. Duplikate Die Anzahl der doppelten Nachrichten, die vom RTP-Gerät Außer Betrieb Anzahl der Pakete, die von dem Gerät empfangen wurden, auf dem das RTP Die Sequenznummer stimmte nicht mit der Sequenznummer überein, die das ExtraHop-System hatte erwartend. Die Neuordnung wurde möglicherweise am Gerät selbst oder durch einen Zwischengerät. Dies kann zu einer verminderten Anrufqualität führen. Tropfen Die Anzahl der Pakete, die vor der Übertragung verloren gegangen sind Empfang durch das RTP-Gerät - RTP-Ausgang
-
Metrisch Beschreibung Nachrichten Die Anzahl der vom RTP gesendeten Nachrichten Gerät. Duplikate Die Anzahl der doppelten Nachrichten, die vom RTP gesendet wurden Gerät. Außer Betrieb Anzahl der Pakete, die von dem Gerät gesendet wurden, auf dem Die RTP-Sequenznummer stimmte nicht mit der Sequenznummer des ExtraHop-Systems überein erwartend. Die Neuordnung wurde möglicherweise am Gerät selbst oder durch einen Zwischengerät. Dies kann zu einer verminderten Anrufqualität führen. Tropfen Die Anzahl der vom RTP-Gerät gesendeten Pakete, die gingen auf dem Transit verloren.
Codecs
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Codecs in
-
Dieses Diagramm zeigt die Anzahl der vom RTP-Gerät empfangenen Nachrichten, aufgeteilt nach Codecs.
- Die besten Codecs im Umlauf
-
Dieses Diagramm zeigt die Anzahl der vom RTP-Gerät gesendeten Nachrichten, aufgeteilt nach Codecs.
Seite „RTP-Gerätegruppen"
Auf dieser Seite werden Metrikdiagramme von angezeigt RTP Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
RTP-Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Zusammenfassung In
-
Metrisch Beschreibung Mittlerer Meinungsscore Der für Pakete berechnete mittlere Meinungswert (MOS) vom RTP-Gerät empfangen. Das MOS ist eine Schätzung der RTP-Stream-Leistung und der VoIP-Anrufqualität. Die MOS-Werte liegen zwischen 1 und 5, wobei 5 die höchste wahrgenommene Gesprächsqualität darstellt. Das ExtraHop-System berechnet den MOS auf der Grundlage von Delay, Loss, Discard, Jitter und Codec. Der MOS wird nur für die folgenden Codecs berechnet: ITU-T G.711 PCMU Audio, ITU-T G.711 PCMA Audio, ITU-T G.729 Audio und GSM 6.10 Audio. Nachrichten Die Anzahl der vom RTP empfangenen Nachrichten Gerät. - Zusammenfassung Raus
-
Metrisch Beschreibung Mittlerer Meinungsscore Der für Pakete berechnete mittlere Meinungswert (MOS) gesendet vom RTP-Gerät. Das MOS ist eine Schätzung der RTP-Stream-Leistung und der VoIP-Anrufqualität. Die MOS-Werte liegen zwischen 1 und 5, wobei 5 die höchste wahrgenommene Gesprächsqualität darstellt. Das ExtraHop-System berechnet den MOS auf der Grundlage von Delay, Loss, Discard, Jitter und Codec. Der MOS wird nur für die folgenden Codecs berechnet: ITU-T G.711 PCMU Audio, ITU-T G.711 PCMA Audio, ITU-T G.729 Audio und GSM 6.10 Audio. Nachrichten Die Anzahl der vom RTP gesendeten Nachrichten Gerät. - RTP-Eingang
-
Metrisch Beschreibung Nachrichten Die Anzahl der vom RTP empfangenen Nachrichten Gerät. Duplikate Die Anzahl der doppelten Nachrichten, die vom RTP-Gerät Außer Betrieb Anzahl der Pakete, die von dem Gerät empfangen wurden, auf dem das RTP Die Sequenznummer stimmte nicht mit der Sequenznummer überein, die das ExtraHop-System hatte erwartend. Die Neuordnung wurde möglicherweise am Gerät selbst oder durch einen Zwischengerät. Dies kann zu einer verminderten Anrufqualität führen. Tropfen Die Anzahl der Pakete, die vor der Übertragung verloren gegangen sind Empfang durch das RTP-Gerät - RTP-Ausgang
-
Metrisch Beschreibung Nachrichten Die Anzahl der vom RTP gesendeten Nachrichten Gerät. Duplikate Die Anzahl der doppelten Nachrichten, die vom RTP gesendet wurden Gerät. Außer Betrieb Anzahl der Pakete, die von dem Gerät gesendet wurden, auf dem Die RTP-Sequenznummer stimmte nicht mit der Sequenznummer des ExtraHop-Systems überein erwartend. Die Neuordnung wurde möglicherweise am Gerät selbst oder durch einen Zwischengerät. Dies kann zu einer verminderten Anrufqualität führen. Tropfen Die Anzahl der vom RTP-Gerät gesendeten Pakete, die gingen auf dem Transit verloren.
SCCP
Das ExtraHop-System sammelt Messwerte zur Aktivität des Skinny Client Control Protocol (SCCP). SCCP ist ein IP-basiertes Protokoll für die Sitzungssignalisierung mit Cisco Unified Communications Manager, das häufig in VoIP-Umgebungen (Voice over Internet Protocol) eingesetzt wird.
SCCP-Anwendungsseite
Auf dieser Seite werden Metrikdiagramme von angezeigt SCCP Verkehr, der mit einem Anwendungscontainer in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
SCCP-Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anrufe und Nachrichten
- In diesem Diagramm wird angezeigt, wann die Gesamtzahl der mit
der Anwendung verknüpften SCCP-Aufrufe und -Nachrichten stattgefunden hat.
Metrisch Beschreibung SCCP-Aufrufe Die Anzahl der SCCP-Aufrufe dafür Anwendung. SCCP-Nachrichten Die Anzahl der Nachrichten, die SCCP-Aufrufen zugeordnet sind für diese Anwendung. SCCP-Nachrichten, die viele Nachrichtentypen enthalten können, sind zwischen Anrufmanagern und Telefonen ausgetauscht. - Gesamtzahl der Anrufe und Nachrichten
- In diesem Diagramm wird die Gesamtzahl der SCCP-Aufrufe und -Nachrichten angezeigt, die mit der
Anwendung verknüpft sind.
Metrisch Beschreibung SCCP-Aufrufe Die Anzahl der SCCP-Aufrufe dafür Anwendung. SCCP-Nachrichten Die Anzahl der Nachrichten, die SCCP-Aufrufen zugeordnet sind für diese Anwendung. SCCP-Nachrichten, die viele Nachrichtentypen enthalten können, sind zwischen Anrufmanagern und Telefonen ausgetauscht. - Dauer des Anrufs
- Dieses Diagramm zeigt die Länge der mit der Anwendung verknüpften SCCP-Aufrufe, aufgeteilt nach
Perzentilen.
Metrisch Beschreibung Dauer des SCCP-Anrufs Die Länge der damit verbundenen Anrufe SCCP-Anwendung. Diese Metrik wird von den SCCP-Geräten innerhalb dieses Systems berechnet und gemeldet Anwendung. - Dauer des Anrufs
- Dieses Diagramm zeigt das 95. Perzentil der SCCP-Anruflängen.
Metrisch Beschreibung Dauer des SCCP-Anrufs Die Länge der damit verbundenen Anrufe SCCP-Anwendung. Diese Metrik wird von den SCCP-Geräten innerhalb dieses Systems berechnet und gemeldet Anwendung. - Zeit für Hin- und Rückfahrt
- In diesem Diagramm wird die Dauer der mit der Anwendung verknüpften Hin- und Rückflugzeit,
aufgeteilt nach Perzentilen, angezeigt.
Metrisch Beschreibung SCCP-Rundreisezeit Round Trip Time (RTT) ist ein Maß für die Gesamtzahl Netzwerklatenz. Das ExtraHop-System berechnet RTT, indem es die benötigte Zeit misst. um eine SCCP-Nachricht zu senden und eine sofortige Bestätigung (ACK) zu erhalten - Zeit für Hin- und Rückfahrt
- In diesem Diagramm wird das 95. Perzentil der mit der Anwendung verknüpften Hin- und Rückflugzeit angezeigt.
Metrisch Beschreibung SCCP-Rundreisezeit Round Trip Time (RTT) ist ein Maß für die Gesamtzahl Netzwerklatenz. Das ExtraHop-System berechnet RTT, indem es die benötigte Zeit misst. um eine SCCP-Nachricht zu senden und eine sofortige Bestätigung (ACK) zu erhalten
SCCP-Nachrichten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Typ der häufigsten Nachrichten
- In diesem Diagramm werden die SCCP-Nachrichtentypen angezeigt, die am häufigsten mit der
Anwendung in Verbindung gebracht wurden.
Metrisch Beschreibung SCCP-Nachrichten Die Anzahl der Nachrichten, die SCCP-Aufrufen zugeordnet sind für diese Anwendung. SCCP-Nachrichten, die viele Nachrichtentypen enthalten können, sind zwischen Anrufmanagern und Telefonen ausgetauscht. - Die besten Absender
- In diesem Diagramm werden die IP-Adressen angezeigt, die der Anwendung zugeordnet sind, die die
meisten SCCP-Nachrichten gesendet hat.
Metrisch Beschreibung SCCP-Nachrichten Die Anzahl der Nachrichten, die SCCP-Aufrufen zugeordnet sind für diese Anwendung. SCCP-Nachrichten, die viele Nachrichtentypen enthalten können, sind zwischen Anrufmanagern und Telefonen ausgetauscht. - Die besten Empfänger
- In diesem Diagramm werden die IP-Adressen angezeigt, die der Anwendung zugeordnet sind, die die
meisten SCCP-Nachrichten empfangen hat.
Metrisch Beschreibung SCCP-Nachrichten Die Anzahl der Nachrichten, die SCCP-Aufrufen zugeordnet sind für diese Anwendung. SCCP-Nachrichten, die viele Nachrichtentypen enthalten können, sind zwischen Anrufmanagern und Telefonen ausgetauscht.
SCCP-Netzwerkdaten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Stände veranstalten
-
Dieses Diagramm zeigt die Anzahl der Nullfenster, die einer Anwendung
zugeordnet waren. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der Pakete
angeben, die über einen bestimmten Zeitraum an sie gesendet werden können.
Wenn an ein Gerät mehr Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein
Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig einzustellen, bis das Gerät den Vorgang
aufholt. Wenn Sie eine große Anzahl von Nullfenstern sehen, ist ein Server oder Client möglicherweise
nicht schnell genug, um die empfangene Datenmenge zu unterstützen.
Metrisch Beschreibung SCCP Null Windows Die Anzahl der Zero Windows for SCCP-Aufrufe mit dieser Anwendung verknüpft. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. - Gesamtzahl der Host-Stände
-
Dieses Diagramm zeigt die durchschnittliche Anzahl von
Zero-Window-Werbeanzeigen, die von Geräten gesendet wurden.
Metrisch Beschreibung SCCP Null Windows Die Anzahl der Zero Windows for SCCP-Aufrufe mit dieser Anwendung verknüpft. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. - Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen
Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu
viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät
eine Anfrage oder Antwort sendet und innerhalb einer bestimmten
Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen
nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise
zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition SCCP RTO Die Anzahl der Retransmission-Timeouts (RTOs) für SCCP-Aufrufe, die dieser Anwendung zugeordnet sind. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. - Gesamtzahl der Netzwerkausfälle
-
Dieses Diagramm zeigt die durchschnittliche Anzahl von Timeouts bei der
erneuten Übertragung, die durch Überlastung beim Senden von Anfragen durch Clients und Server verursacht wurden.
Metrisch Definition SCCP RTO Die Anzahl der Retransmission-Timeouts (RTOs) für SCCP-Aufrufe, die dieser Anwendung zugeordnet sind. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen.
SCCP-Metriksummen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Anrufe und Nachrichten
- In diesem Diagramm werden die Gesamtzahl der mit der
Anwendung verknüpften SCCP-Aufrufe und -Nachrichten sowie die Dauer der Verzögerung beim Empfang von Paketen angezeigt.
Metrisch Beschreibung SCCP-Aufrufe Die Anzahl der SCCP-Aufrufe dafür Anwendung. SCCP-Nachrichten Die Anzahl der Nachrichten, die SCCP-Aufrufen zugeordnet sind für diese Anwendung. SCCP-Nachrichten, die viele Nachrichtentypen enthalten können, sind zwischen Anrufmanagern und Telefonen ausgetauscht. SCCP hat Jitter gemeldet Die Länge der Verzögerung beim Empfang von Anrufpaketen für diese SCCP-Anwendung aufgrund von Jitter. (Jitter ist ein Maß für die Variation in der Netzwerklatenz im Laufe der Zeit.) Diese Metrik wird von SCCP berechnet und gemeldet Geräte innerhalb dieser Anwendung. - SCCP-Netzwerkmetriken
- In diesem Diagramm werden die Gesamtwerte der Netzwerkmetriken angezeigt, die mit der Anwendung verknüpft sind.
Metrisch Beschreibung SCCP Null Windows Die Anzahl der Zero Windows for SCCP-Aufrufe mit dieser Anwendung verknüpft. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. SCCP RTO Die Anzahl der Retransmission-Timeouts (RTOs) für SCCP-Aufrufe, die dieser Anwendung zugeordnet sind. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. SCCP-Bytes Die Anzahl der Goodput-Bytes, die SCCP zugeordnet sind fordert diese Anwendung. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. SCCP L2-Byte Die Anzahl der mit SCCP verknüpften L2-Bytes fordert diese Anwendung. SCCP-Pakete Die Anzahl der mit SCCP verknüpften Pakete fordert diese Anwendung. SCCP hat Pakete als verloren gemeldet Die Anzahl der Pakete, die während eines Anrufs verloren gegangen sind die mit dieser SCCP-Anwendung verknüpft sind. Diese Metrik wird berechnet und von SCCP-Geräten in dieser Anwendung gemeldet
SCCP-Geräteseite
Auf dieser Seite werden Metrikdiagramme von angezeigt SCCP Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
SCCP-Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Zusammenfassung In
- In diesem Diagramm wird die Gesamtzahl der eingehenden SCCP-Anrufe und -Nachrichten angezeigt,
die vom Gerät empfangen wurden.
Metrisch Beschreibung SCCP-Geräteanrufe Die Anzahl der eingehenden Anrufe, die von diesem SCCP empfangen wurden Gerät. Eingehende SCCP-Gerätemeldungen Die Anzahl der von diesem SCCP empfangenen Nachrichten Gerät. SCCP-Nachrichten, die viele Nachrichtentypen enthalten können, werden ausgetauscht zwischen Rufen Sie Manager und Telefone an. - Zusammenfassung raus
- In diesem Diagramm wird die Gesamtzahl der ausgehenden SCCP-Anrufe und -Nachrichten angezeigt, die vom
Gerät gesendet wurden.
Metrisch Beschreibung SCCP-Geräteanrufe Die Anzahl der ausgehenden Anrufe, die von diesem SCCP gesendet wurden Gerät. Ausgehende SCCP-Gerätemeldungen Die Anzahl der von diesem SCCP-Gerät gesendeten Nachrichten. SCCP-Nachrichten, die viele Nachrichtentypen enthalten können, werden zwischen Anrufen ausgetauscht Manager und Telefone. - Anrufe und Nachrichten in
- In diesem Diagramm wird angezeigt, wann die Gesamtzahl der eingehenden SCCP-Anrufe und -Nachrichten vom Gerät
empfangen wurde.
Metrisch Beschreibung SCCP-Geräteanrufe Die Anzahl der eingehenden Anrufe, die von diesem SCCP empfangen wurden Gerät. Eingehende SCCP-Gerätemeldungen Die Anzahl der von diesem SCCP empfangenen Nachrichten Gerät. SCCP-Nachrichten, die viele Nachrichtentypen enthalten können, werden ausgetauscht zwischen Rufen Sie Manager und Telefone an. - Ausgehende Anrufe und Nachrichten
- In diesem Diagramm wird angezeigt, wann die Gesamtzahl der ausgehenden SCCP-Anrufe und -Nachrichten vom Gerät
gesendet wurde.
Metrisch Beschreibung SCCP-Geräteanrufe Die Anzahl der ausgehenden Anrufe, die von diesem SCCP gesendet wurden Gerät. Ausgehende SCCP-Gerätemeldungen Die Anzahl der von diesem SCCP-Gerät gesendeten Nachrichten. SCCP-Nachrichten, die viele Nachrichtentypen enthalten können, werden zwischen Anrufen ausgetauscht Manager und Telefone.
Dauer des SCCP-Anrufs
Die folgenden Diagramme sind in dieser Region verfügbar:
- Dauer des Anrufs
- In diesem Diagramm wird die Länge der SCCP-Aufrufe nach Perzentilen aufgeteilt.
Metrisch Beschreibung Dauer des SCCP-Geräteanrufs Die Länge des Anrufs für dieses SCCP Gerät. - Dauer des Anrufs
- Dieses Diagramm zeigt das 95. Perzentil der SCCP-Anruflängen.
Metrisch Beschreibung Dauer des SCCP-Geräteanrufs Die Länge des Anrufs für dieses SCCP Gerät.
SCCP-Nachrichtentypen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Nachrichten in
- Dieses Diagramm zeigt, welche SCCP-Nachrichtentypen am häufigsten vom
Gerät empfangen wurden.
Metrisch Beschreibung Eingehende SCCP-Gerätemeldungen Die Anzahl der von diesem SCCP empfangenen Nachrichten Gerät. SCCP-Nachrichten, die viele Nachrichtentypen enthalten können, werden ausgetauscht zwischen Rufen Sie Manager und Telefone an. - Am häufigsten ausgegebene Nachrichten
- Dieses Diagramm zeigt, welche SCCP-Nachrichtentypen am häufigsten vom Gerät gesendet wurden.
Metrisch Beschreibung Ausgehende SCCP-Gerätemeldungen Die Anzahl der von diesem SCCP-Gerät gesendeten Nachrichten. SCCP-Nachrichten, die viele Nachrichtentypen enthalten können, werden zwischen Anrufen ausgetauscht Manager und Telefone.
Gesamtwerte der SCCP-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- SCCP-rein
- In diesem Diagramm werden die Gesamtzahl der vom Gerät
empfangenen SCCP-Aufrufe, -Nachrichten, -Bytes und -Pakete sowie die Dauer der Verzögerung beim Empfang von Paketen angezeigt.
Metrisch Beschreibung SCCP-Geräteanrufe Die Anzahl der eingehenden Anrufe, die von diesem SCCP empfangen wurden Gerät. Eingehende SCCP-Gerätemeldungen Die Anzahl der von diesem SCCP empfangenen Nachrichten Gerät. SCCP-Nachrichten, die viele Nachrichtentypen enthalten können, werden ausgetauscht zwischen Rufen Sie Manager und Telefone an. SCCP-Gerät hat Jitter gemeldet Die Länge der Verzögerung beim Senden oder Empfangen von Paketen für dieses SCCP-Gerät aufgrund von Jitter. (Jitter ist ein Maß für die Variation von Netzwerklatenz während des Zeitintervalls.) Diese Metrik wird berechnet und gemeldet von das Gerät. SCCP-Gerät hat eingegangene Bytes gemeldet Die Anzahl der Goodput-Call-Bytes, die empfangen wurden von dieses SCCP-Gerät, wie vom Gerät berechnet und gemeldet. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Eingehende Pakete vom SCCP-Gerät gemeldet Die Anzahl der von diesem empfangenen Anrufpakete SCCP-Gerät, wie vom Gerät berechnet und gemeldet - SCCP-Ausgang
- In diesem Diagramm werden die Gesamtzahl der
vom Gerät gesendeten SCCP-Aufrufe, -Nachrichten, -Bytes und -Pakete sowie die Dauer der Verzögerung beim Senden von Paketen angezeigt.
Metrisch Beschreibung SCCP-Geräteanrufe Die Anzahl der ausgehenden Anrufe, die von diesem SCCP gesendet wurden Gerät. Ausgehende SCCP-Gerätemeldungen Die Anzahl der von diesem SCCP-Gerät gesendeten Nachrichten. SCCP-Nachrichten, die viele Nachrichtentypen enthalten können, werden zwischen Anrufen ausgetauscht Manager und Telefone. SCCP-Gerät hat Jitter gemeldet Die Länge der Verzögerung beim Senden oder Empfangen von Paketen für dieses SCCP-Gerät aufgrund von Jitter. (Jitter ist ein Maß für die Variation von Netzwerklatenz während des Zeitintervalls.) Diese Metrik wird berechnet und gemeldet von das Gerät. SCCP-Gerät hat ausgehende Byte gemeldet Die Anzahl der Goodput-Call-Bytes, die von diesem gesendet wurden SCCP-Gerät, wie vom Gerät berechnet und gemeldet. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. SCCP-Gerät hat ausgehende Pakete gemeldet Die Anzahl der von diesem SCCP gesendeten Anrufpakete Gerät, wie vom Gerät berechnet und gemeldet.
SCCP-Gerätegruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt SCCP Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
SCCP-Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Zusammenfassung In
- In diesem Diagramm wird die Gesamtzahl der eingehenden SCCP-Anrufe und -Nachrichten angezeigt,
die von den Geräten in der Gruppe empfangen wurden.
Metrisch Beschreibung SCCP-Geräteanrufe Die Anzahl der eingehenden Anrufe, die von diesem SCCP empfangen wurden Gerät. Eingehende SCCP-Gerätemeldungen Die Anzahl der von diesem SCCP empfangenen Nachrichten Gerät. SCCP-Nachrichten, die viele Nachrichtentypen enthalten können, werden ausgetauscht zwischen Rufen Sie Manager und Telefone an. - Zusammenfassung raus
- In diesem Diagramm wird die Gesamtzahl der ausgehenden SCCP-Anrufe und -Nachrichten angezeigt, die von den
Geräten in der Gruppe gesendet wurden.
Metrisch Beschreibung SCCP-Geräteanrufe Die Anzahl der ausgehenden Anrufe, die von diesem SCCP gesendet wurden Gerät. Ausgehende SCCP-Gerätemeldungen Die Anzahl der von diesem SCCP-Gerät gesendeten Nachrichten. SCCP-Nachrichten, die viele Nachrichtentypen enthalten können, werden zwischen Anrufen ausgetauscht Manager und Telefone. - SCCP-Eins
- Dieses Diagramm zeigt die Gesamtzahl der SCCP-Aufrufe, -Nachrichten, -Bytes und -Pakete, die von Geräten in der Gruppe
empfangen wurden, sowie die Dauer der Verzögerung beim Empfang von Paketen.
Metrisch Beschreibung SCCP-Geräteanrufe Die Anzahl der eingehenden Anrufe, die von diesem SCCP empfangen wurden Gerät. Eingehende SCCP-Gerätemeldungen Die Anzahl der von diesem SCCP empfangenen Nachrichten Gerät. SCCP-Nachrichten, die viele Nachrichtentypen enthalten können, werden ausgetauscht zwischen Rufen Sie Manager und Telefone an. SCCP-Gerät hat Jitter gemeldet Die Länge der Verzögerung beim Senden oder Empfangen von Paketen für dieses SCCP-Gerät aufgrund von Jitter. (Jitter ist ein Maß für die Variation von Netzwerklatenz während des Zeitintervalls.) Diese Metrik wird berechnet und gemeldet von das Gerät. SCCP-Gerät hat eingegangene Bytes gemeldet Die Anzahl der Goodput-Call-Bytes, die empfangen wurden von dieses SCCP-Gerät, wie vom Gerät berechnet und gemeldet. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Eingehende Pakete vom SCCP-Gerät gemeldet Die Anzahl der von diesem empfangenen Anrufpakete SCCP-Gerät, wie vom Gerät berechnet und gemeldet - SCCP-Ausgang
- Dieses Diagramm zeigt die Gesamtzahl der SCCP-Aufrufe, -Nachrichten, -Bytes und -Pakete, die
von Geräten in der Gruppe gesendet wurden, sowie die Dauer der Verzögerung beim Senden von Paketen.
Metrisch Beschreibung SCCP-Geräteanrufe Die Anzahl der ausgehenden Anrufe, die von diesem SCCP gesendet wurden Gerät. Ausgehende SCCP-Gerätemeldungen Die Anzahl der von diesem SCCP-Gerät gesendeten Nachrichten. SCCP-Nachrichten, die viele Nachrichtentypen enthalten können, werden zwischen Anrufen ausgetauscht Manager und Telefone. SCCP-Gerät hat Jitter gemeldet Die Länge der Verzögerung beim Senden oder Empfangen von Paketen für dieses SCCP-Gerät aufgrund von Jitter. (Jitter ist ein Maß für die Variation von Netzwerklatenz während des Zeitintervalls.) Diese Metrik wird berechnet und gemeldet von das Gerät. SCCP-Gerät hat ausgehende Byte gemeldet Die Anzahl der Goodput-Call-Bytes, die von diesem gesendet wurden SCCP-Gerät, wie vom Gerät berechnet und gemeldet. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. SCCP-Gerät hat ausgehende Pakete gemeldet Die Anzahl der von diesem SCCP gesendeten Anrufpakete Gerät, wie vom Gerät berechnet und gemeldet.
SCCP-Geräte in der Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Geräte in
- In diesem Diagramm werden die Geräte in der Gruppe angezeigt, die die meisten SCCP-Anrufe erhalten haben.
Metrisch Beschreibung SCCP-Geräteanrufe Die Anzahl der eingehenden Anrufe, die von diesem SCCP empfangen wurden Gerät. - Top-Geräte im Umlauf
- In diesem Diagramm werden die Geräte in der Gruppe angezeigt, die die meisten SCCP-Anrufe gesendet haben.
Metrisch Beschreibung SCCP-Geräteanrufe Die Anzahl der ausgehenden Anrufe, die von diesem SCCP gesendet wurden Gerät.
SIP
Das ExtraHop-System sammelt Metriken über das Session Initiation Protocol (SIP) Aktivität. SIP ist ein Signalprotokoll, das Kommunikationssitzungen wie Sprachanrufe für IP-basierte Telefonieanwendungen steuert.
SIP-Anwendungsseite
SIP Zusammenfassung
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann SIP-Fehler und -Antworten mit der
Anwendung verknüpft waren. Anhand dieser Informationen können Sie feststellen, wie aktiv die Anwendung zum
Zeitpunkt des Auftretens der Fehler war.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der SIP-Antworten. Fehler Die Anzahl der SIP-Antwortfehler. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der SIP-Antworten, die mit der
Anwendung verknüpft waren, und wie viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der SIP-Antworten. Fehler Die Anzahl der SIP-Antwortfehler. - Leistung (95. Perzentil)
-
Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken.
Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer vollständigen
Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange Clients gebraucht haben, um Anfragen an
das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange die Server für die Bearbeitung von Anfragen gebraucht haben;
und die Antwortübertragungszeit zeigt, wie lange die Server gebraucht haben, um Antworten an
das Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Transferzeit anfragen Die Zeit zwischen der Erkennung durch das ExtraHop-System das erste Paket und das letzte Paket von SIP-Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Bearbeitungszeit Die Zeit zwischen der Erkennung des letztes Paket von SIP-Anfragen und das erste Paket der entsprechenden Antworten. Übertragungszeit der Antwort Die Zeit zwischen der Erkennung durch das ExtraHop-System das erste Paket und das letzte Paket von SIP-Antworten. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden einer Nachricht durch einen SIP-Client oder Server Paket, das sofort bestätigt werden muss und wann die Bestätigung erfolgte erhalten. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn eine Anwendung langsam reagiert, können Sie anhand
von Leistungsübersichtsmetriken herausfinden, ob das Netzwerk oder die Server das
Problem verursachen. Diese Metriken zeigen das 95. Perzentil der Zeit, die Server für die Bearbeitung von
Anfragen von Clients benötigten, im Vergleich zum 95. Perzentil der Zeit, die Pakete aus diesen Anfragen
(und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten. Hohe
Serververarbeitungszeiten deuten darauf hin, dass Clients langsame Server kontaktieren. Hohe
TCP-Roundtrip-Zeiten deuten darauf hin, dass Clients über langsame Netzwerke kommunizieren.
Metrisch Beschreibung Bearbeitungszeit Die Zeit zwischen der Erkennung des letztes Paket von SIP-Anfragen und das erste Paket der entsprechenden Antworten. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden einer Nachricht durch einen SIP-Client oder Server Paket, das sofort bestätigt werden muss und wann die Bestätigung erfolgte erhalten.
SIP-Angaben
- Die besten Methoden
- Dieses Diagramm zeigt, welche SIP-Methoden mit der Anwendung verknüpft waren, indem die Gesamtzahl der SIP-Anfragen nach Methoden aufgeschlüsselt wird.
- Die wichtigsten Statuscodes
- Dieses Diagramm zeigt, welche SIP-Statuscodes der Server am häufigsten zurückgegeben hat, indem die Gesamtzahl der Antworten, die die Anwendung gesendet hat, nach Statuscode aufgeteilt wird.
- Die besten URIs
- Dieses Diagramm zeigt, auf welche URIs die Anwendung am häufigsten zugegriffen hat, indem die Gesamtzahl der Antworten, die die Anwendung per URI erhalten hat, aufgeschlüsselt wird.
SIP-Leistung
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Bearbeitungszeit Die Zeit zwischen der Erkennung des letztes Paket von SIP-Anfragen und das erste Paket der entsprechenden Antworten. - Verarbeitungszeit des Servers
-
Diese Tabelle zeigt die durchschnittliche Bearbeitungszeit für den Anwendung.
Metrisch Beschreibung Bearbeitungszeit Die Zeit zwischen der Erkennung des letztes Paket von SIP-Anfragen und das erste Paket der entsprechenden Antworten. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden einer Nachricht durch einen SIP-Client oder Server Paket, das sofort bestätigt werden muss und wann die Bestätigung erfolgte erhalten. - Zeit für Hin- und Rückfahrt
-
Diese Tabelle zeigt
die durchschnittliche Hin- und Rückflugzeit für die Anwendung.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden einer Nachricht durch einen SIP-Client oder Server Paket, das sofort bestätigt werden muss und wann die Bestätigung erfolgte erhalten.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass ein Problem mit einem Server oder einem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
-
Dieses Diagramm zeigt die Anzahl der Nullfenster, die einer Anwendung
zugeordnet waren. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der Pakete
angeben, die über einen bestimmten Zeitraum an sie gesendet werden können.
Wenn an ein Gerät mehr Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein
Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig einzustellen, bis das Gerät den Vorgang
aufholt. Wenn Sie eine große Anzahl von Nullfenstern sehen, ist ein Server oder Client möglicherweise
nicht schnell genug, um die empfangene Datenmenge zu unterstützen.
Metrisch Definition Zero Windows anfordern Die Anzahl der gesendeten Null-Window-Anzeigen von POP3-Clients. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl eingehender Zero-Windows weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Antwort Null Windows Die Anzahl der gesendeten Null-Window-Anzeigen von Servern beim Empfang von POP3-Anfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von ausgehenden Zero-Windows weist darauf hin, dass ein Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Gesamtzahl der Host-Stände
- Dieses Diagramm zeigt die durchschnittliche Anzahl von Zero-Window-Werbeanzeigen, die von Geräten gesendet wurden.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen
Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu
viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät
eine Anfrage oder Antwort sendet und innerhalb einer bestimmten
Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen
nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise
zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, als Clients POP3-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server POP3-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
- Gesamtzahl der Netzwerkausfälle
-
Dieses Diagramm zeigt die durchschnittliche Anzahl von Timeouts bei der
erneuten Übertragung, die durch Überlastung beim Senden von Anfragen durch Clients und Server verursacht wurden.
Metrisch Definition RTOs Ein Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, als Clients POP3-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server POP3-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Gesamtwerte der SIP-Metriken
- Gesamtzahl der Anfragen und Antworten
-
Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr Anfragen, als Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um herauszufinden, ob das Problem mit dem Netzwerk oder einem Server zusammenhängt, überprüfen Sie RTOs und Zero Windows in der Netzwerk-Daten Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der SIP-Anfragen und -Antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der SIP-Anfragen. Antworten Die Anzahl der SIP-Antworten. Fehler Die Anzahl der SIP-Antwortfehler. - SIP-Netzwerkmetriken
-
Metrisch Beschreibung L2-Byte anfordern Die Anzahl der mit SIP verknüpften L2-Bytes Anfragen. Antwort L2 Byte Die Anzahl der mit SIP verknüpften L2-Bytes Antworten. Goodput Bytes anfordern Die Anzahl der zugehörigen Goodput-Bytes mit SIP-Anfragen. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Antwort Goodput Bytes Die Anzahl der zugehörigen Goodput-Bytes mit SIP-Antworten. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Pakete anfordern Die Anzahl der Pakete, die SIP zugeordnet sind Anfragen. Antwortpakete Die Anzahl der Pakete, die SIP zugeordnet sind Antworten.
Wo soll ich als Nächstes suchen?
Analysieren Sie eine Metrik: Sie können weitere Informationen zu einer Metrik abrufen, indem Sie auf den Metrikwert oder -namen klicken und eine Option aus dem Menü Drilldown by auswählen. Wenn Sie sich beispielsweise die Gesamtzahl der Fehler ansehen, klicken Sie auf die Zahl und wählen Sie Server um zu sehen, welche Server die Fehler zurückgegeben haben.
Den Metric Explorer durchsuchen: Integrierte Protokollseiten enthalten die am häufigsten referenzierten Metriken für ein Protokoll, aber Sie können zusätzliche Metriken im Metric Explorer sehen. Klicken Sie auf einer Protokollseite auf einen beliebigen Diagrammtitel und wählen Sie Diagramm erstellen aus.... Wenn der Metric Explorer geöffnet wird, klicken Sie auf Metrik hinzufügen im linken Bereich, um eine Drop-down-Liste mit umfassenden Messwerten für das Gerät anzuzeigen. Wenn Sie eine interessante Metrik finden, klicken Sie Zum Dashboard hinzufügen um die Metrik zu einem neuen oder vorhandenen Dashboard hinzuzufügen.
Erstellen Sie eine benutzerdefinierte Metrik: Wenn Sie eine Metrik anzeigen möchten, die nicht im Metric Explorer enthalten ist, können Sie über einen Auslöser eine benutzerdefinierte Metrik erstellen. Weitere Informationen finden Sie in den folgenden Ressourcen:
SIP-Client-Seite
Auf dieser Seite werden Metrikdiagramme von angezeigt SIP Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
SIP Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann SIP-Fehler aufgetreten sind und wie viele Antworten der SIP-Client
erhalten hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Client zum Zeitpunkt des
Eingangs der Fehler war.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als SIP-Client. Antwortfehler Die Anzahl der eingegangenen Antworten mit einem SIP-Statuscode >= 500 - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der SIP-Antworten, die der Client erhalten hat, und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als SIP-Client. Antwortfehler Die Anzahl der eingegangenen Antworten mit einem SIP-Statuscode >= 500 - Verarbeitungszeit des Servers
- Dieses Diagramm zeigt die Verarbeitungszeiten von SIP-Servern, aufgeteilt nach Perzentilen.
Die Serververarbeitungszeit gibt an, wie lange Server gebraucht haben, um Anfragen vom Client zu verarbeiten. Die
Serververarbeitungszeit wird berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das letzte Paket einer
Anfrage und das erste Paket einer Antwort vom ExtraHop-System erkannt wird.
Metrisch Beschreibung Verarbeitungszeit des SIP-Client-Servers Wenn das Gerät als SMPP-Client fungiert (ESME), die Zeit zwischen der Erkennung des letzten Pakets des gesendeten Pakets durch das ExtraHop-System Anfrage und das erste Paket der empfangenen Antwort. - Serververarbeitungszeit (95.)
- Zeigt das 95. Perzentil für die Serververarbeitungszeit an.
Metrisch Beschreibung Verarbeitungszeit des SIP-Clients Wenn das Gerät als SMPP-Client fungiert (ESME), die Zeit zwischen der Erkennung des letzten Pakets des gesendeten Pakets durch das ExtraHop-System Anfrage und das erste Paket der empfangenen Antwort. Das Diagramm mit der Zusammenfassung der Serververarbeitungszeit konzentriert sich auf das 95. Perzentil, um den höchsten Wert für einen bestimmten Zeitraum anzuzeigen und gleichzeitig Ausreißer zu filtern. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Die folgende Tabelle zeigt, wie die Anzeige des 95. Werts anstelle des tatsächlichen Maximums zu einer genaueren Ansicht der Daten führen kann:
SIP-Angaben
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche SIP-Methoden der Client am häufigsten aufgerufen hat, indem die Gesamtzahl der vom Client gesendeten Anfragen nach Methode aufgeschlüsselt wird.
- Die wichtigsten Statuscodes
- Dieses Diagramm zeigt, welche SIP-Statuscodes der Client am häufigsten erhalten hat, indem die Anzahl der an den Client zurückgegebenen Antworten nach Statuscode aufgeteilt wird.
- Die besten URIs
- Dieses Diagramm zeigt, auf welche URIs der Client am häufigsten zugegriffen hat, indem die Gesamtzahl der Antworten, die der Client per URI erhalten hat, aufgeschlüsselt wird.
SIP-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des SIP-Client-Servers Wenn das Gerät als SIP-Client fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort. - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Bearbeitungszeit für den Client.
Metrisch Beschreibung Verarbeitungszeit des SIP-Client-Servers Wenn das Gerät als SIP-Client fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort.
Gesamtwerte der SIP-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, sendet der Client möglicherweise mehr
Anfragen, als die Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der SIP-Anfragen und -Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät gesendet hat, als fungiert als SIP-Client. Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als SIP-Client. Antwortfehler Die Anzahl der eingegangenen Antworten mit einem SIP-Statuscode >= 500 - Größe der Anfrage und Antwort
- Dieses Diagramm zeigt die durchschnittliche Größe der Anfragen und Antworten.
Metrisch Beschreibung Größe der Anfrage Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät gesendet hat, als es als SIP-Client agiert. Die Größenangaben beinhalten SIP-Nutzlast, aber keine Header Größe der Antwort Die Verteilung der Größen (in Byte) von Antworten, die das Gerät gesendet hat, als es als SIP-Client agiert hat. Maße der Größe schließt SIP-Nutzdaten ein, aber keine Header
SIP-Serverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt SIP Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
SIP Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann SIP-Fehler aufgetreten sind und wie viele SIP-Antworten der Server
gesendet hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Server zu dem Zeitpunkt war, als er die Fehler
zurückgab.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als SIP-Server. Antwortfehler Die Anzahl der gesendeten Antworten, die ein SIP haben Statuscode >= 500 - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der SIP-Antworten, die der Server gesendet hat, und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als SIP-Server. Antwortfehler Die Anzahl der gesendeten Antworten, die ein SIP haben Statuscode >= 500 - Verarbeitungszeiten des Servers
- Dieses Diagramm zeigt die Verarbeitungszeiten von SIP-Servern, aufgeteilt nach Perzentilen. Die
Serververarbeitungszeit gibt an, wie lange der Server gebraucht hat, um Anfragen von Clients zu verarbeiten. Die
Serververarbeitungszeit wird berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das letzte Paket einer
Anfrage und das erste Paket einer Antwort vom ExtraHop-System erkannt wird.
Metrisch Beschreibung Verarbeitungszeit des SIP-Servers Wenn das Gerät als SMPP-Server fungiert (SMSC), die Zeit zwischen der Entdeckung des letzten Paket durch das ExtraHop-System empfangene Anfrage und erstes Paket der gesendeten Antwort. - Serververarbeitungszeit (95.)
- Zeigt das 95. Perzentil für die Serververarbeitungszeit an.
Metrisch Beschreibung Verarbeitungszeit des SIP-Servers Wenn das Gerät als SMPP-Server fungiert (SMSC), die Zeit zwischen der Entdeckung des letzten Paket durch das ExtraHop-System empfangene Anfrage und erstes Paket der gesendeten Antwort. Das Diagramm mit der Zusammenfassung der Serververarbeitungszeit konzentriert sich auf das 95. Perzentil, um den höchsten Wert für einen bestimmten Zeitraum anzuzeigen und gleichzeitig Ausreißer zu filtern. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Die folgende Tabelle zeigt, wie die Anzeige des 95. Werts anstelle des wahren Maximums zu einer genaueren Ansicht der Daten führen kann:
SIP-Angaben
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche SIP-Methoden auf dem Server am häufigsten aufgerufen wurden, indem die Gesamtzahl der Anfragen, die der Server erhalten hat, nach Methode aufgeteilt wird.
- Die wichtigsten Statuscodes
- Dieses Diagramm zeigt, welche SIP-Statuscodes der Server am häufigsten zurückgegeben hat, indem die Gesamtzahl der vom Server gesendeten Antworten nach Statuscode aufgeschlüsselt wird.
- Die besten URIs
- Dieses Diagramm zeigt, auf welche URIs auf dem Server am häufigsten zugegriffen wurde, indem die Gesamtzahl der Antworten, die der Server per URI gesendet hat, aufgeschlüsselt wird.
SIP-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des SIP-Servers Wenn das Gerät als SMPP-Server fungiert (SMSC), die Zeit zwischen der Entdeckung des letzten Paket durch das ExtraHop-System empfangene Anfrage und erstes Paket der gesendeten Antwort. - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Verarbeitungszeit für den Server.
Metrisch Beschreibung Verarbeitungszeit des SIP-Servers Wenn das Gerät als SMPP-Server fungiert (SMSC), die Zeit zwischen der Entdeckung des letzten Paket durch das ExtraHop-System empfangene Anfrage und erstes Paket der gesendeten Antwort.
Gesamtwerte der SIP-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Anfragen und Antworten
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr
Anfragen, als der Server verarbeiten kann, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der SIP-Anfragen und -Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät gesendet hat, als fungiert als SIP-Server. Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als SIP-Server. Antwortfehler Die Anzahl der gesendeten Antworten, die ein SIP haben Statuscode >= 500 - Größe der Anfrage und Antwort
- Dieses Diagramm zeigt die durchschnittliche Größe der Anfragen und Antworten.
Metrisch Beschreibung Größe der Anfrage Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät gesendet hat, als es als SIP-Server fungiert. Die Größenangaben beinhalten SIP-Nutzlast, aber keine Header Größe der Antwort Die Verteilung der Größen (in Byte) von Antworten, die das Gerät gesendet hat, als es als SIP-Server fungiert. Maße der Größe schließt SIP-Nutzdaten ein, aber keine Header
SIP-Client-Gruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt SIP Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
SIP Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann SIP-Fehler aufgetreten sind und wie viele Antworten die SIP-Clients
erhalten haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Kunden zu dem Zeitpunkt waren, als sie die Fehler
erhielten.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie im Abschnitt SIP-Metriken für Gruppen.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als SIP-Client. Antwortfehler Die Anzahl der eingegangenen Antworten mit einem SIP-Statuscode >= 500 - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele SIP-Antworten die Clients erhalten haben und wie viele dieser
Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als SIP-Client. Antwortfehler Die Anzahl der eingegangenen Antworten mit einem SIP-Statuscode >= 500
SIP-Details für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (SIP-Clients)
- Dieses Diagramm zeigt, welche SIP-Clients in der Gruppe am aktivsten waren, indem es die Gesamtzahl der SIP-Anfragen aufschlüsselt, die die Gruppe vom Client gesendet hat.
- Die besten Methoden
- Dieses Diagramm zeigt, welche SIP-Methoden die Gruppe am häufigsten aufgerufen hat, indem die Gesamtzahl der von der Gruppe gesendeten Anfragen nach Methode aufgeschlüsselt wird.
- Die wichtigsten Statuscodes
- Dieses Diagramm zeigt, welche SIP-Statuscodes die Gruppe am häufigsten erhalten hat, indem die Anzahl der an die Gruppe zurückgegebenen Antworten nach Statuscode aufgeschlüsselt wird.
SIP-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden die Clients möglicherweise mehr Anfragen, als Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät gesendet hat, als fungiert als SIP-Client. Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als SIP-Client. Fehler Die Anzahl der eingegangenen Antworten mit einem SIP-Statuscode >= 500 - Verarbeitungszeit des Servers
-
Wenn sich eine Client-Gruppe langsam verhält, können Sie anhand der Serververarbeitungszeit herausfinden,
ob das Problem bei den Servern liegt. Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche
Zeit, die Server für die Bearbeitung von Anfragen von den Clients benötigten. Hohe
Serververarbeitungszeiten deuten darauf hin, dass die Clients langsame Server kontaktieren.
Metrisch Beschreibung Verarbeitungszeit des SIP-Client-Servers Wenn das Gerät als SMPP-Client fungiert (ESME), die Zeit zwischen der Erkennung des letzten Pakets des gesendeten Pakets durch das ExtraHop-System Anfrage und das erste Paket der empfangenen Antwort.
SIP-Servergruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt SIP Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
SIP Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann SIP-Fehler aufgetreten sind und wie viele SIP-Antworten die Server
gesendet haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Server zu dem Zeitpunkt waren, als sie
die Fehler gemeldet haben.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie im Abschnitt SIP-Metriken für Gruppen.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als SIP-Server. Antwortfehler Die Anzahl der gesendeten Antworten, die ein SIP haben Statuscode >= 500 - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele SIP-Antwortserver in der Gruppe gesendet haben und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als SIP-Server. Antwortfehler Die Anzahl der gesendeten Antworten, die ein SIP haben Statuscode >= 500
SIP-Details für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (SIP-Server)
- Dieses Diagramm zeigt, welche SIP-Server in der Gruppe am aktivsten waren, indem die Gesamtzahl der SIP-Antworten, die die Gruppe vom Server gesendet hat, aufgeschlüsselt wird.
- Die besten Methoden
- Dieses Diagramm zeigt, welche SIP-Methoden auf Servern in der Gruppe am häufigsten aufgerufen wurden, indem die Gesamtzahl der Anfragen, die die Gruppe erhalten hat, nach Methode aufgeschlüsselt wird.
- Oberster Statuscode
- Dieses Diagramm zeigt, welche SIP-Statuscodes die Gruppen am häufigsten zurückgegeben haben, indem die Gesamtzahl der von der Gruppe gesendeten Antworten nach Statuscode aufgeschlüsselt wird.
SIP-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden Clients möglicherweise mehr Anfragen, als die Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät gesendet hat, als fungiert als SIP-Server. Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als SIP-Server. Antwortfehler Die Anzahl der gesendeten Antworten, die ein SIP haben Statuscode >= 500 - Verarbeitungszeit des Servers
-
Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche Zeit, die die Server für die
Bearbeitung von Anfragen von Clients benötigten. Hohe Serververarbeitungszeiten deuten darauf hin, dass die Server in einer
Gruppe langsam sind.
Metrisch Beschreibung Verarbeitungszeit des SIP-Servers Wenn das Gerät als SMPP-Server fungiert (SMSC), die Zeit zwischen der Entdeckung des letzten Paket durch das ExtraHop-System empfangene Anfrage und erstes Paket der gesendeten Antwort.
SMPP
Das ExtraHop-System sammelt Metriken über Short Message Peer-to-Peer (SMPP) Aktivität. SMPP ist ein Protokoll auf Anwendungsebene, das SMS-Daten ( Short Message Service) zwischen External Short Messaging Entities (ESME) und Short Message Service Centers (SMSC) überträgt.
SMPP-Clientseite
Auf dieser Seite werden Metrikdiagramme von angezeigt SMPP Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
SMPP Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann SMPP-Fehler aufgetreten sind und wie viele Antworten der SMPP-Client erhalten hat.
Anhand dieser Informationen können Sie feststellen, wie aktiv der Client zum Zeitpunkt des
Eingangs der Fehler war.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie sich Details zu jedem Fehler anzeigen lassen. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von Anfragen zu Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Hinweis: Um jeden Fehler anzuzeigen, der an den Client zurückgegeben wurde, klicken Sie auf Fehler und wählen Sie dann Fehler aus der Speisekarte. Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als SMPP-Client (ESME) agieren Fehler Die Anzahl der Fehler, die das Gerät hat empfangen, wenn ich als SMPP-Client - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der SMPP-Antworten, die der Client erhalten hat, und wie
viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als SMPP-Client (ESME) agieren Fehler Die Anzahl der Fehler, die das Gerät hat empfangen, wenn ich als SMPP-Client - Leistungsübersicht (95. Perzentil)
-
Dieses Diagramm zeigt das
95. Perzentil der Timing-Metriken. Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer
vollständigen Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange der Client gebraucht hat, um
Anfragen an das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange Server gebraucht haben, um
die Anfragen zu verarbeiten; und die Antwortübertragungszeit zeigt, wie lange Server gebraucht haben, um
Antworten an das Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Übertragungszeit der SMPP-Client-Anfrage Wenn das Gerät als SMPP-Client fungiert (ESME), die Zeit zwischen der Erkennung des ersten und des letzten Paket durch das ExtraHop-System Paket gesendeter Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit des SMPP-Client-Servers Wenn das Gerät als SMPP-Client fungiert (ESME), die Zeit zwischen der Erkennung des letzten Pakets des gesendeten Pakets durch das ExtraHop-System Anfrage und das erste Paket der empfangenen Antwort. Übertragungszeit der SMPP-Client-Antwort Wenn das Gerät als SMPP-Client fungiert (ESME), die Zeit zwischen der Erkennung des ersten und des letzten Paket durch das ExtraHop-System Paket der empfangenen Antworten. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. TCP-Hin- und Rückflugzeit Die Zeit zwischen dem Senden eines Paket durch einen SMPP-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn ein Client langsam reagiert, können Sie
anhand von Leistungsübersichtsmetriken herausfinden, ob das Netzwerk oder die Server das Problem verursachen.
Diese Metriken zeigen das 95. Perzentil der Zeit, die Server für die Bearbeitung von
Anfragen vom Client benötigten, im Vergleich zur 95. Perzentilzeit, die Pakete aus diesen
Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten.
Hohe Serververarbeitungszeiten deuten darauf hin, dass der Client langsame Server kontaktiert. Hohe
TCP-Roundtrip-Zeiten deuten darauf hin, dass der Client über langsame
Netzwerke kommuniziert.
Metrisch Beschreibung Verarbeitungszeit des SMPP-Client-Servers Wenn das Gerät als SMPP-Client fungiert (ESME), die Zeit zwischen der Erkennung des letzten Pakets des gesendeten Pakets durch das ExtraHop-System Anfrage und das erste Paket der empfangenen Antwort. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen SMPP-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
SMPP-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die wichtigsten Statuscodes
- Dieses Diagramm zeigt, welche SMPP-Statuscodes der Client am häufigsten erhalten hat, indem die Anzahl der an den Client zurückgegebenen Antworten nach Statuscode aufgeschlüsselt wird.
- Die wichtigsten Befehle
- Dieses Diagramm zeigt, welche Befehle der Client am häufigsten ausgeführt hat, indem die Gesamtzahl der Antworten, die der Client per Befehl erhalten hat, aufgeschlüsselt wird.
SMPP-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des SMPP-Client-Servers Wenn das Gerät als SMPP-Client fungiert (ESME), die Zeit zwischen der Erkennung des letzten Pakets des gesendeten Pakets durch das ExtraHop-System Anfrage und das erste Paket der empfangenen Antwort. - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Bearbeitungszeit für den Client.
Metrisch Beschreibung Verarbeitungszeit des SMPP-Client-Servers Wenn das Gerät als SMPP-Client fungiert (ESME), die Zeit zwischen der Erkennung des letzten Pakets des gesendeten Pakets durch das ExtraHop-System Anfrage und das erste Paket der empfangenen Antwort.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
SMPP-Metriksummen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, sendet der Client möglicherweise mehr
Anfragen, als die Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen
, ob das Problem beim Netzwerk oder beim Server liegt, überprüfen Sie RTOs und Zero Windows in der
Netzwerk-Daten
Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der SMPP-Anfragen und -Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät gesendet hat, als agiert als SMPP-Client (ESME Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als SMPP-Client (ESME) agieren Fehler Die Anzahl der Fehler, die das Gerät hat empfangen, wenn ich als SMPP-Client - Größe der Anfrage und Antwort
- Dieses Diagramm zeigt die durchschnittliche Größe der Anfragen und Antworten.
Metrisch Beschreibung Größe der Anfrage Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät gesendet hat, als es als SMPP-Client (ESME) agiert Größe der Antwort Die Verteilung der Größen (in Byte) von Antworten, die das Gerät erhalten hat, als SMPP-Client (ESME).
SMPP-Serverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt SMPP Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
SMPP Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann SMPP-Fehler aufgetreten sind und wie viele SMPP-Antworten der Server gesendet hat.
Anhand dieser Informationen können Sie feststellen, wie aktiv der Server zu dem Zeitpunkt war, als er die Fehler
zurückgab.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie sich Details zu jedem Fehler anzeigen lassen. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von Anfragen zu Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Hinweis: Um jeden Fehler anzuzeigen, der vom Server zurückgegeben wurde, klicken Sie auf Fehler und wählen Sie dann Fehler aus der Speisekarte. Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als SMPP-Server (SMSC Fehler Die Anzahl der Fehler, die das Gerät gesendet hat wenn er als SMPP-Server (SMSC) fungiert - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der SMPP-Antworten, die der Server gesendet hat, und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als SMPP-Server (SMSC Fehler Die Anzahl der Fehler, die das Gerät gesendet hat wenn er als SMPP-Server (SMSC) fungiert - Leistungsübersicht (95. Perzentil)
-
Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken
. Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer vollständigen
Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange Clients gebraucht haben, um Anfragen an
das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange der Server gebraucht hat, um Anfragen zu verarbeiten;
und die Antwortübertragungszeit zeigt, wie lange der Server gebraucht hat, um Antworten an das
Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Übertragungszeit der SMPP-Serveranforderung Wenn das Gerät als SMPP-Server fungiert (SMSC), die Zeit zwischen der Erkennung des ersten und des letzten Paket durch das ExtraHop-System Paket eingegangener Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit des SMPP-Servers Wenn das Gerät als SMPP-Server fungiert (SMSC), die Zeit zwischen der Entdeckung des letzten Paket durch das ExtraHop-System empfangene Anfrage und erstes Paket der gesendeten Antwort. Übertragungszeit der SMPP-Serverantwort Wenn das Gerät als SMPP-Server fungiert (SMSC), die Zeit zwischen der Erkennung des ersten und des letzten Paket durch das ExtraHop-System Paket gesendeter Antworten. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. TCP-Hin- und Rückflugzeit Die Zeit zwischen dem Senden eines Paket durch einen SMPP-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn ein Server langsam reagiert, können Sie
anhand von Leistungsübersichtsmetriken herausfinden, ob das
Problem vom Netzwerk oder vom Server verursacht wird. Die Leistungsübersichtsmetriken zeigen das 95. Perzentil der Zeit, die der
Server für die Verarbeitung von Anfragen von Clients benötigte, im Vergleich zur 95. Perzentilzeit, die
Pakete aus diesen Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten.
Hohe Serververarbeitungszeiten deuten darauf hin, dass der Server langsam ist.
Hohe RTTs weisen darauf hin, dass der Server über langsame Netzwerke kommuniziert.
Metrisch Beschreibung Verarbeitungszeit des SMPP-Servers Wenn das Gerät als SMPP-Server fungiert (SMSC), die Zeit zwischen der Entdeckung des letzten Paket durch das ExtraHop-System empfangene Anfrage und erstes Paket der gesendeten Antwort. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen SMPP-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
SMPP-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die wichtigsten Statuscodes
- Dieses Diagramm zeigt, welche SMPP-Statuscodes der Server am häufigsten zurückgegeben hat, indem die Gesamtzahl der vom Server gesendeten Antworten nach Statuscode aufgeschlüsselt wird.
- Die wichtigsten Befehle
- Dieses Diagramm zeigt, welche Befehle auf dem Server ausgeführt wurden, indem die Gesamtzahl der Antworten, die der Server per Befehl gesendet hat, aufgeschlüsselt wird.
SMPP-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des SMPP-Servers Wenn das Gerät als SMPP-Server fungiert (SMSC), die Zeit zwischen der Entdeckung des letzten Paket durch das ExtraHop-System empfangene Anfrage und erstes Paket der gesendeten Antwort. - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Verarbeitungszeit für den Server.
Metrisch Beschreibung Verarbeitungszeit des SMPP-Servers Wenn das Gerät als SMPP-Server fungiert (SMSC), die Zeit zwischen der Entdeckung des letzten Paket durch das ExtraHop-System empfangene Anfrage und erstes Paket der gesendeten Antwort.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
SMPP-Metriksummen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr
Anfragen, als der Server verarbeiten kann, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen
, ob das Problem beim Netzwerk oder beim Server liegt, überprüfen Sie RTOs und Zero Windows in der
Netzwerk-Daten
Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der SMPP-Anfragen und -Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät erhalten hat wenn er als SMPP-Server (SMSC) fungiert Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als SMPP-Server (SMSC Fehler Die Anzahl der Fehler, die das Gerät gesendet hat wenn er als SMPP-Server (SMSC) fungiert - Größe der Anfrage und Antwort
- Dieses Diagramm zeigt die durchschnittliche Größe der Anfragen und Antworten.
Metrisch Beschreibung Größe der Anfrage Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät empfangen hat, als es als SMPP-Server (SMSC) fungiert Größe der Antwort Die Verteilung der Größen (in Byte) von Antworten, die das Gerät gesendet hat, als es als SMPP-Server (SMSC) fungierte
SMPP-Clientgruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt SMPP Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
SMPP Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann SMPP-Fehler aufgetreten sind und wie viele Antworten die SMPP-Clients erhalten haben.
Anhand dieser Informationen können Sie feststellen, wie aktiv die Kunden zu dem Zeitpunkt waren, als sie die Fehler
erhielten.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie sich Details zu jedem Fehler anzeigen lassen. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von SMPP-Anfragen zu SMPP-Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie in der Tabelle SMPP-Metriken für Gruppen.
Hinweis: Um jeden Fehler anzuzeigen , der an den Client zurückgegeben wurde, klicken Sie auf Fehler und wählen Sie dann Fehler aus der Speisekarte. Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als SMPP-Client (ESME) agieren Fehler Die Anzahl der Fehler, die das Gerät hat empfangen, wenn ich als SMPP-Client - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele SMPP-Antworten die Kunden erhalten haben und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als SMPP-Client (ESME) agieren Fehler Die Anzahl der Fehler, die das Gerät hat empfangen, wenn ich als SMPP-Client
SMPP-Details für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (SMPP-Kunden)
- Dieses Diagramm zeigt, welche SMPP-Clients in der Gruppe am aktivsten waren, indem es die Gesamtzahl der SMPP-Anfragen aufschlüsselt, die die Gruppe vom Client gesendet hat.
- Die wichtigsten Statuscodes
- Dieses Diagramm zeigt, welche SMPP-Statuscodes die Gruppe am häufigsten erhalten hat, indem die Anzahl der an die Gruppe zurückgegebenen Antworten nach Statuscode aufgeschlüsselt wird.
- Die wichtigsten Befehle
- Dieses Diagramm zeigt, welche Befehle die Gruppe am häufigsten ausgeführt hat, indem die Gesamtzahl der Antworten, die die Gruppe per Befehl erhalten hat, aufgeschlüsselt wird.
SMPP-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden die Clients möglicherweise mehr Anfragen, als Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät gesendet hat, als agiert als SMPP-Client (ESME Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als SMPP-Client (ESME) agieren Fehler Die Anzahl der Fehler, die das Gerät hat empfangen, wenn ich als SMPP-Client - Verarbeitungszeit des Servers
-
Wenn sich eine Client-Gruppe langsam verhält, können Sie anhand der Serververarbeitungszeit herausfinden,
ob das Problem bei den Servern liegt. Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche
Zeit, die Server für die Bearbeitung von Anfragen von den Clients benötigten. Hohe
Serververarbeitungszeiten deuten darauf hin, dass die Clients langsame Server kontaktieren.
Metrisch Beschreibung Verarbeitungszeit des SMPP-Client-Servers Wenn das Gerät als SMPP-Client fungiert (ESME), die Zeit zwischen der Erkennung des letzten Pakets des gesendeten Pakets durch das ExtraHop-System Anfrage und das erste Paket der empfangenen Antwort.
SMPP-Servergruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt SMPP Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
SMPP Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wann SMPP-Fehler aufgetreten sind und wie viele SMPP-Antworten die Server gesendet haben.
Anhand dieser Informationen können Sie feststellen, wie aktiv die Server zu dem Zeitpunkt waren, als sie
die Fehler gemeldet haben.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie sich Details zu jedem Fehler anzeigen lassen. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von SMPP-Anfragen zu SMPP-Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie in der Tabelle SMPP-Metriken für Gruppen.
Hinweis: Um jeden Fehler anzuzeigen , der vom Server zurückgegeben wurde, klicken Sie auf Fehler und wählen Sie dann Fehler aus der Speisekarte. Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als SMPP-Server (SMSC Fehler Die Anzahl der Fehler, die das Gerät gesendet hat wenn er als SMPP-Server (SMSC) fungiert - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele SMPP-Antwortserver in der Gruppe gesendet haben und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als SMPP-Server (SMSC Fehler Die Anzahl der Fehler, die das Gerät gesendet hat wenn er als SMPP-Server (SMSC) fungiert
SMPP-Details für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (SMPP-Server)
- Dieses Diagramm zeigt, welche SMPP-Server in der Gruppe am aktivsten waren, indem die Gesamtzahl der SMPP-Antworten, die die Gruppe vom Server gesendet hat, aufgeschlüsselt wird.
- Oberster Statuscode
- Dieses Diagramm zeigt, welche SMPP-Statuscodes die Gruppen am häufigsten zurückgegeben haben, indem die Gesamtzahl der von der Gruppe gesendeten Antworten nach Statuscode aufgeschlüsselt wird.
- Die wichtigsten Befehle
- Dieses Diagramm zeigt, welche Befehle auf Servern in der Gruppe ausgeführt wurden, indem die Gesamtzahl der Antworten, die die Gruppe per Befehl gesendet hat, aufgeschlüsselt wird.
SMPP-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden Clients möglicherweise mehr Anfragen, als die Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät erhalten hat wenn er als SMPP-Server (SMSC) fungiert Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als SMPP-Server (SMSC Fehler Die Anzahl der Fehler, die das Gerät gesendet hat wenn er als SMPP-Server (SMSC) fungiert - Verarbeitungszeit des Servers
-
Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche Zeit, die die Server für die
Bearbeitung von Anfragen von Clients benötigten. Hohe Serververarbeitungszeiten deuten darauf hin, dass die Server in einer
Gruppe langsam sind.
Metrisch Beschreibung Verarbeitungszeit des SMPP-Servers Wenn das Gerät als SMPP-Server fungiert (SMSC), die Zeit zwischen der Entdeckung des letzten Paket durch das ExtraHop-System empfangene Anfrage und erstes Paket der gesendeten Antwort.
SMTP
Das ExtraHop-System sammelt Metriken zum Simple Mail Transfer Protocol (SMTP) Aktivität. SMTP ist ein Standardprotokoll, das E-Mail-Nachrichten zwischen Servern, E-Mail-Übertragungsagenten und Client-Anwendungen sendet, empfängt und weiterleitet.
Erfahren Sie mehr, indem Sie an der SMTP Quick Peek-Schulung teilnehmen.
SMTP-Anwendungsseite
Auf dieser Seite werden Metrikdiagramme von angezeigt SMTP Verkehr, der mit einem Anwendungscontainer in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
SMTP Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann SMTP-Fehler und -Antworten mit der
Anwendung verknüpft waren. Anhand dieser Informationen können Sie feststellen, wie aktiv die Anwendung zum
Zeitpunkt des Auftretens der Fehler war.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der SMTP-Antworten. Fehler Die Anzahl der SMTP-Antworten Fehler. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der SMTP-Antworten, die mit der
Anwendung verknüpft waren, und wie viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der SMTP-Antworten. Fehler Die Anzahl der SMTP-Antworten Fehler. - Leistung (95. Perzentil)
-
Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken.
Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer vollständigen
Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange Clients gebraucht haben, um Anfragen an
das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange die Server für die Bearbeitung von Anfragen gebraucht haben;
und die Antwortübertragungszeit zeigt, wie lange die Server gebraucht haben, um Antworten an
das Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Transferzeit anfragen Die Zeit zwischen der Erkennung durch das ExtraHop-System das erste Paket und das letzte Paket von SMTP-Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit des Servers Die Zeit zwischen der Erkennung durch das ExtraHop-System das letzte Paket von SMTP-Anfragen und das erste Paket der entsprechenden Anfragen Antworten. Übertragungszeit der Antwort Die Zeit zwischen der Erkennung durch das ExtraHop-System das erste Paket und das letzte Paket von SMTP-Antworten. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines SMTP-Clients oder Server ein Paket, das sofort bestätigt werden muss und wann die Bestätigung erfolgte erhalten. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn eine Anwendung langsam reagiert, können Sie anhand
von Leistungsübersichtsmetriken herausfinden, ob das Netzwerk oder die Server das
Problem verursachen. Diese Metriken zeigen das 95. Perzentil der Zeit, die Server für die Bearbeitung von
Anfragen von Clients benötigten, im Vergleich zum 95. Perzentil der Zeit, die Pakete aus diesen Anfragen
(und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten. Hohe
Serververarbeitungszeiten deuten darauf hin, dass Clients langsame Server kontaktieren. Hohe
TCP-Roundtrip-Zeiten deuten darauf hin, dass Clients über langsame Netzwerke kommunizieren.
Metrisch Beschreibung Verarbeitungszeit des Servers Die Zeit zwischen der Erkennung durch das ExtraHop-System das letzte Paket von SMTP-Anfragen und das erste Paket der entsprechenden Anfragen Antworten. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines SMTP-Clients oder Server ein Paket, das sofort bestätigt werden muss und wann die Bestätigung erfolgte erhalten.
SMTP-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche SMTP-Methoden mit der Anwendung verknüpft waren, indem die Gesamtzahl der SMTP-Anfragen nach Methoden aufgeschlüsselt wird.
- Die wichtigsten Statuscodes
- Dieses Diagramm zeigt, welche SMTP-Statuscodes der Server am häufigsten zurückgegeben hat, indem die Gesamtzahl der Antworten, die die Anwendung gesendet hat, nach Statuscode aufgeteilt wird.
- Die häufigsten Fehler
- Dieses Diagramm zeigt, welche SMTP-Fehler am häufigsten mit der Anwendung in Verbindung gebracht wurden, indem die Anzahl der Antworten nach Fehlern aufgeschlüsselt wird.
SMTP-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des SMTP-Servers Die Zeit zwischen der Erkennung durch das ExtraHop-System das letzte Paket von SMTP-Anfragen und das erste Paket der entsprechenden Anfragen Antworten. - Verarbeitungszeit des Servers
-
Diese Tabelle zeigt die durchschnittliche Bearbeitungszeit für den Anwendung.
Metrisch Beschreibung Verarbeitungszeit des SMTP-Servers Die Zeit zwischen der Erkennung durch das ExtraHop-System das letzte Paket von SMTP-Anfragen und das erste Paket der entsprechenden Anfragen Antworten. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines SMTP-Clients oder Server ein Paket, das sofort bestätigt werden muss und wann die Bestätigung erfolgte erhalten. - Zeit für Hin- und Rückfahrt
-
Diese Tabelle zeigt
die durchschnittliche Hin- und Rückflugzeit für die Anwendung.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines SMTP-Clients oder Server ein Paket, das sofort bestätigt werden muss und wann die Bestätigung erfolgte erhalten.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass ein Problem mit einem Server oder einem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
-
Dieses Diagramm zeigt die Anzahl der Nullfenster, die einer Anwendung
zugeordnet waren. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der Pakete
angeben, die über einen bestimmten Zeitraum an sie gesendet werden können.
Wenn an ein Gerät mehr Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein
Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig einzustellen, bis das Gerät den Vorgang
aufholt. Wenn Sie eine große Anzahl von Nullfenstern sehen, ist ein Server oder Client möglicherweise
nicht schnell genug, um die empfangene Datenmenge zu unterstützen.
Metrisch Definition Zero Windows anfordern Die Anzahl der gesendeten Null-Window-Anzeigen von SMTP-Clients. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl eingehender Zero-Windows weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Antwort Null Windows Die Anzahl der gesendeten Null-Window-Anzeigen von Servern beim Empfang von SMTP-Anfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von ausgehenden Zero-Windows weist darauf hin, dass ein Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Gesamtzahl der Host-Stände
- Dieses Diagramm zeigt die durchschnittliche Anzahl von Zero-Window-Werbeanzeigen, die von Geräten gesendet wurden.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen
Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu
viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät
eine Anfrage oder Antwort sendet und innerhalb einer bestimmten
Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen
nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise
zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Clients SMTP-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server SMTP-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
- Gesamtzahl der Netzwerkausfälle
-
Dieses Diagramm zeigt die durchschnittliche Anzahl von Timeouts bei der
erneuten Übertragung, die durch Überlastung beim Senden von Anfragen durch Clients und Server verursacht wurden.
Metrisch Definition RTOs Ein Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Clients SMTP-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server SMTP-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Gesamtwerte der SMTP-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr Anfragen, als Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um herauszufinden, ob das Problem mit dem Netzwerk oder einem Server zusammenhängt, überprüfen Sie RTOs und Zero Windows in Netzwerk-Daten Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der SMTP-Anfragen und -Antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der SMTP-Anfragen. Antworten Die Anzahl der SMTP-Antworten. Antwortfehler Die Anzahl der SMTP-Antworten Fehler. Sessions Die Anzahl der SMTP-Sitzungen. Verschlüsselte Sitzungen Die Anzahl der verschlüsselten SMTP Sitzungen. - SMTP-Netzwerkmetriken
-
Metrisch Beschreibung Zero Windows anfordern Die Anzahl der gesendeten Null-Window-Anzeigen von SMTP-Clients. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Antwort Null Windows Die Anzahl der gesendeten Null-Window-Anzeigen von Servern beim Empfang von SMTP-Anfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. RTOs anfragen Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Clients SMTP-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Antwort-RTOs Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server SMTP-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. L2-Byte anfordern Die Anzahl der L2-Bytes, die mit verknüpft sind SMTP-Anfragen Antwort L2 Byte Die Anzahl der L2-Bytes, die mit verknüpft sind SMTP-Antworten Goodput Bytes anfordern Die Anzahl der Goodput-Bytes, die mit verknüpft sind SMTP-Anfragen. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Antwort Goodput Bytes Die Anzahl der Goodput-Bytes, die mit verknüpft sind SMTP-Antworten. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Pakete anfordern Die Anzahl der mit SMTP verknüpften Pakete Anfragen. Antwortpakete Die Anzahl der mit SMTP verknüpften Pakete Antworten.
SMTP-Client-Seite
Auf dieser Seite werden Metrikdiagramme von angezeigt SMTP Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
SMTP Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann SMTP-Fehler aufgetreten sind und wie viele Antworten der SMTP-Client
erhalten hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Client zum Zeitpunkt des
Eingangs der Fehler war.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie sich Details zu jedem Fehler anzeigen lassen. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von Anfragen zu Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Hinweis: Um jeden Fehler anzuzeigen, der an den Client zurückgegeben wurde, klicken Sie auf Antworten und wählen Sie dann Fehler aus der Speisekarte. Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als SMTP-Client agieren Fehler Wenn das Gerät als SMTP fungiert client, die Anzahl der empfangenen Befehlsantworten, die einen Antwortcode haben >= 400. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der SMTP-Antworten, die der Client erhalten hat, und wie
viele dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als SMTP-Client agieren Sessions Die Anzahl der Sitzungen, die das Gerät hat daran teilgenommen, als er als SMTP-Client fungierte Fehler Wenn das Gerät als SMTP fungiert client, die Anzahl der empfangenen Befehlsantworten, die einen Antwortcode haben >= 400. - Leistungsübersicht (95. Perzentil)
-
Dieses Diagramm zeigt das
95. Perzentil der Timing-Metriken. Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer
vollständigen Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange der Client gebraucht hat, um
Anfragen an das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange Server gebraucht haben, um
die Anfragen zu verarbeiten; und die Antwortübertragungszeit zeigt, wie lange Server gebraucht haben, um
Antworten an das Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Übertragungszeit der SMTP-Clientanfrage Wenn das Gerät als SMTP-Client fungiert, die Zeit zwischen der Erkennung des ersten Pakets und des letzten Pakets durch das ExtraHop-System von gesendete Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit des SMTP-Client-Servers Wenn das Gerät als SMTP-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort. Übertragungszeit der SMTP-Client-Antwort Wenn das Gerät als SMTP-Client fungiert, die Zeit zwischen der Erkennung des ersten Pakets und des letzten Pakets durch das ExtraHop-System von erhaltene Antworten. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen SMTP-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn ein Client langsam reagiert, können Sie
anhand von Leistungsübersichtsmetriken herausfinden, ob das Netzwerk oder die Server das Problem verursachen.
Diese Metriken zeigen das 95. Perzentil der Zeit, die Server für die Bearbeitung von
Anfragen vom Client benötigten, im Vergleich zur 95. Perzentilzeit, die Pakete aus diesen
Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten.
Hohe Serververarbeitungszeiten deuten darauf hin, dass der Client langsame Server kontaktiert. Hohe
TCP-Roundtrip-Zeiten deuten darauf hin, dass der Client über langsame
Netzwerke kommuniziert.
Metrisch Beschreibung Verarbeitungszeit des SMTP-Clientservers Wenn das Gerät als SMTP-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen SMTP-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
SMTP-Einzelheiten
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche SMTP-Methoden der Client am häufigsten aufgerufen hat, indem die Gesamtzahl der Anfragen, die der Client nach Methode gesendet hat, aufgeschlüsselt wird.
- Die häufigsten Fehler
- Dieses Diagramm zeigt, welche SMTP-Fehler der Client am häufigsten erhalten hat, indem die Anzahl der irrtümlich an den Client zurückgegebenen Antworten aufgeschlüsselt wird.
SMTP-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des SMTP-Clientservers Wenn das Gerät als SMTP-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort. - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Bearbeitungszeit für den Client.
Metrisch Beschreibung Verarbeitungszeit des SMTP-Clientservers Wenn das Gerät als SMTP-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen SMTP-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Hin- und Rückflugzeit für den Client.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen SMTP-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Gesamtwerte der SMTP-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, sendet der Client möglicherweise mehr
Anfragen, als die Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen
, ob das Problem am Netzwerk oder am Server liegt, überprüfen Sie RTOs und Zero Windows in der
Netzwerk-Daten
Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der SMTP-Anfragen und -Antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät gesendet hat, als fungiert als SMTP-Client Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als SMTP-Client agieren Abgebrochene Anfragen Die Anzahl der Anfragen, die dieses SMTP Der Client begann zu senden, sendete aber nicht vollständig, da die Verbindung abrupt hergestellt wurde geschlossen. Abgebrochene Antworten Die Anzahl der Anfragen, die dieses SMTP Der Client begann zu senden, sendete aber nicht vollständig, da die Verbindung abrupt hergestellt wurde geschlossen. Sessions Die Anzahl der Sitzungen, die das Gerät hat daran teilgenommen, als er als SMTP-Client fungierte Verschlüsselte Sitzungen Die Anzahl der verschlüsselten Sitzungen an denen das Gerät beteiligt war, als es als SMTP-Client fungierte Fehler Wenn das Gerät als SMTP fungiert client, die Anzahl der empfangenen Befehlsantworten, die einen Antwortcode haben >= 400. - Größe der Anfrage und Antwort
- Dieses Diagramm zeigt die durchschnittliche Größe der Anfragen und Antworten.
Metrisch Beschreibung Größe der Anfrage Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät gesendet hat, als es als SMTP-Client agiert Größe der Antwort Die Verteilung der Größen (in Byte) von Antworten, die das Gerät erhalten hat, als es als SMTP-Client agiert
SMTP-Serverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt SMTP Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
SMTP Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann SMTP-Fehler aufgetreten sind und wie viele SMTP-Antworten der Server
gesendet hat. Anhand dieser Informationen können Sie feststellen, wie aktiv der Server zu dem Zeitpunkt war, als er die Fehler
zurückgab.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie sich Details zu jedem Fehler anzeigen lassen. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von Anfragen zu Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Hinweis: Um jeden Fehler anzuzeigen, der an den Server zurückgegeben wurde, klicken Sie auf Antworten und wählen Sie dann Fehler aus der Speisekarte. Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als SMTP-Server Fehler Wenn das Gerät als SMTP fungiert Server, die Anzahl der gesendeten Befehlsantworten, die einen Antwortcode haben >= 400. - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der SMTP-Antworten, die der Server gesendet hat, und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als SMTP-Server Sessions Die Anzahl der Sitzungen, die das Gerät hat daran teilgenommen, als er als SMTP-Server fungierte Fehler Wenn das Gerät als SMTP fungiert Server, die Anzahl der gesendeten Befehlsantworten, die einen Antwortcode haben >= 400. - Leistungsübersicht (95. Perzentil)
-
Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken
. Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer vollständigen
Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange Clients gebraucht haben, um Anfragen an
das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange der Server gebraucht hat, um Anfragen zu verarbeiten;
und die Antwortübertragungszeit zeigt, wie lange der Server gebraucht hat, um Antworten an das
Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Übertragungszeit der SMTP-Serveranforderung Wenn das Gerät als SMTP-Server fungiert, die Zeit zwischen der Erkennung des ersten Pakets und des letzten Pakets durch das ExtraHop-System von eingegangene Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit des SMTP-Servers Wenn das Gerät als SMTP-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort. Übertragungszeit der SMTP-Serverantwort Wenn das Gerät als SMTP-Server fungiert, die Zeit zwischen der Erkennung des ersten Pakets und des letzten Pakets durch das ExtraHop-System von gesendete Antworten. Eine hohe Zahl kann auf eine große Antwort oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen SMTP-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn ein Server langsam reagiert, können Sie
anhand von Leistungsübersichtsmetriken herausfinden, ob das
Problem vom Netzwerk oder vom Server verursacht wird. Die Leistungsübersichtsmetriken zeigen das 95. Perzentil der Zeit, die der
Server für die Verarbeitung von Anfragen von Clients benötigte, im Vergleich zur 95. Perzentilzeit, die
Pakete aus diesen Anfragen (und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten.
Hohe Serververarbeitungszeiten deuten darauf hin, dass der Server langsam ist.
Hohe RTTs weisen darauf hin, dass der Server über langsame Netzwerke kommuniziert.
Metrisch Beschreibung Verarbeitungszeit des SMTP-Servers Wenn das Gerät als SMTP-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen SMTP-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Einzelheiten der Transaktion
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Methoden
- Dieses Diagramm zeigt, welche SMTP-Methoden auf dem Server am häufigsten aufgerufen wurden, indem die Gesamtzahl der Anfragen, die der Server erhalten hat, nach Methode aufgeteilt wird.
- Die häufigsten Fehler
- Dieses Diagramm zeigt, welche SMTP-Fehler der Server am häufigsten zurückgegeben hat, indem die Gesamtzahl der Antworten, die der Server versehentlich gesendet hat, aufgeschlüsselt wird.
SMTP-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des SMTP-Servers Wenn das Gerät als SMTP-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort. - Verarbeitungszeit des Servers
-
Dieses
Diagramm zeigt die durchschnittliche Verarbeitungszeit für den Server.
Metrisch Beschreibung Verarbeitungszeit des SMTP-Servers Wenn das Gerät als SMTP-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort. - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen SMTP-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Roundtrip-Zeit für den Server.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen SMTP-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Gesamtwerte der SMTP-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Anfragen und Antworten
- Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und
Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr
Anfragen, als der Server verarbeiten kann, oder das Netzwerk ist möglicherweise zu langsam. Um festzustellen
, ob das Problem am Netzwerk oder am Server liegt, überprüfen Sie RTOs und Zero Windows in der
Netzwerk-Daten
Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der SMTP-Anfragen und -Antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät erhalten hat wenn Sie als SMTP-Server agieren Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als SMTP-Server Fehler Wenn das Gerät als SMTP fungiert Server, die Anzahl der gesendeten Befehlsantworten, die einen Antwortcode haben >= 400. Abgebrochene Anfragen Die Anzahl der Anfragen, die dieses SMTP Der Server begann zu empfangen, empfing aber nicht vollständig, da die Verbindung abrupt geschlossen. Abgebrochene Antworten Die Anzahl der Anfragen, die dieses SMTP Der Server begann zu empfangen, empfing aber nicht vollständig, da die Verbindung abrupt geschlossen. Verschlüsselte Sitzungen Die Anzahl der verschlüsselten Sitzungen an denen das Gerät beteiligt war, als es als SMTP-Server fungierte - Größe der Anfrage und Antwort
-
Metrisch Beschreibung Größe der Anfrage Die Verteilung der Größen (in Byte) von Anfragen, die das Gerät empfangen hat, als es als SMTP-Server fungiert Größe der Antwort Die Verteilung der Größen (in Byte) von Antworten, die das Gerät erhalten hat, als es als SMTP-Server fungierte
SMTP-Clientgruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt SMTP Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
SMTP Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wann SMTP-Fehler aufgetreten sind und wie viele Antworten die SMTP-Clients
erhalten haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Kunden zu dem Zeitpunkt waren, als sie die Fehler
erhielten.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie sich Details zu jedem Fehler anzeigen lassen. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von SMTP-Anfragen zu SMTP-Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie in der Tabelle SMTP-Metriken für Gruppen.
Hinweis: Um jeden Fehler anzuzeigen, der an die Clients zurückgegeben wurde, klicken Sie auf Antworten und wählen Sie dann Fehler aus der Speisekarte. Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als SMTP-Client agieren Fehler Wenn das Gerät als SMTP fungiert client, die Anzahl der empfangenen Befehlsantworten, die einen Antwortcode haben >= 400. - Transaktionen insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele SMTP-Antworten die Clients erhalten haben und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als SMTP-Client agieren Fehler Wenn das Gerät als SMTP fungiert client, die Anzahl der empfangenen Befehlsantworten, die einen Antwortcode haben >= 400.
SMTP-Details für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (SMTP-Clients)
- Dieses Diagramm zeigt, welche SMTP-Clients in der Gruppe am aktivsten waren, indem es die Gesamtzahl der SMTP-Anfragen aufschlüsselt, die die Gruppe vom Client gesendet hat.
- Die besten Methoden
- Dieses Diagramm zeigt, welche SMTP-Methoden die Gruppe am häufigsten aufgerufen hat, indem die Gesamtzahl der von der Gruppe gesendeten Anfragen nach Methode aufgeschlüsselt wird.
- Die häufigsten Fehler
- Dieses Diagramm zeigt, welche SMTP-Fehler die Gruppe am häufigsten erhalten hat, indem die Anzahl der Antworten, die fälschlicherweise an die Gruppe zurückgegeben wurden, aufgeteilt wird.
SMPP-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Anfragen und Antworten
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden die Clients möglicherweise mehr Anfragen, als Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät gesendet hat, als fungiert als SMTP-Client Antworten Die Anzahl der Antworten, die das Gerät erhalten hat wenn Sie als SMTP-Client agieren Abgebrochene Anfragen Die Anzahl der Anfragen, die dieses SMTP Der Client begann zu senden, sendete aber nicht vollständig, da die Verbindung abrupt hergestellt wurde geschlossen. Abgebrochene Antworten Die Anzahl der Anfragen, die dieses SMTP Der Client begann zu senden, sendete aber nicht vollständig, da die Verbindung abrupt hergestellt wurde geschlossen. Sessions Die Anzahl der Sitzungen, die das Gerät hat daran teilgenommen, als er als SMTP-Client fungierte Verschlüsselte Sitzungen Die Anzahl der verschlüsselten Sitzungen an denen das Gerät beteiligt war, als es als SMTP-Client fungierte Fehler Wenn das Gerät als SMTP fungiert client, die Anzahl der empfangenen Befehlsantworten, die einen Antwortcode haben >= 400. - Verarbeitungszeit des Servers
-
Wenn sich eine Client-Gruppe langsam verhält, können Sie anhand der Serververarbeitungszeit herausfinden,
ob das Problem bei den Servern liegt. Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche
Zeit, die Server für die Bearbeitung von Anfragen von den Clients benötigten. Hohe
Serververarbeitungszeiten deuten darauf hin, dass die Clients langsame Server kontaktieren.
Metrisch Beschreibung Verarbeitungszeit des SMTP-Client-Servers Wenn das Gerät als SMTP-Client fungiert, die Zeit zwischen der Entdeckung des letzten Paket der gesendeten Anfrage durch das ExtraHop-System und das erste Paket der empfangenen Antwort.
SMTP-Servergruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt SMTP Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
SMTP Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann SMTP-Fehler aufgetreten sind und wie viele SMTP-Antworten die Server
gesendet haben. Anhand dieser Informationen können Sie feststellen, wie aktiv die Server zu dem Zeitpunkt waren, als sie
die Fehler gemeldet haben.
Wenn Sie eine große Anzahl von Fehlern sehen, können Sie sich Details zu jedem Fehler anzeigen lassen. Wenn die Anzahl der Fehler jedoch gering ist, ist das Problem möglicherweise komplexer, und Sie sollten das Verhältnis von SMTP-Anfragen zu SMTP-Antworten untersuchen. In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie in der Tabelle SMTP-Metriken für Gruppen.
Hinweis: Um jeden Fehler anzuzeigen , der an den Server zurückgegeben wurde, klicken Sie auf Antworten und wählen Sie dann Fehler aus der Speisekarte. Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als SMTP-Server Fehler Wenn das Gerät als SMTP fungiert Server, die Anzahl der gesendeten Befehlsantworten, die einen Antwortcode haben >= 400. - Transaktionen insgesamt
- Dieses Diagramm zeigt, wie viele SMTP-Antwortserver in der Gruppe gesendet haben und wie viele
dieser Antworten Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als SMTP-Server Fehler Wenn das Gerät als SMTP fungiert Server, die Anzahl der gesendeten Befehlsantworten, die einen Antwortcode haben >= 400.
SMTP-Details für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (SMTP-Server)
- Dieses Diagramm zeigt, welche SMTP-Server in der Gruppe am aktivsten waren, indem es die Gesamtzahl der SMTP-Antworten aufschlüsselt, die die Gruppe vom Server gesendet hat.
- Die besten Methoden
- Dieses Diagramm zeigt, welche SMTP-Methoden auf Servern in der Gruppe am häufigsten aufgerufen wurden, indem die Gesamtzahl der Anfragen, die die Gruppe erhalten hat, nach Methode aufgeteilt wird.
- Die häufigsten Fehler
- Dieses Diagramm zeigt, welche SMTP-Fehler die Gruppen am häufigsten gemeldet haben, indem die Gesamtzahl der Antworten, die die Gruppe irrtümlich gesendet hat, aufgeschlüsselt wird.
SMPP-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen
und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten
gibt, senden Clients möglicherweise mehr Anfragen, als die Server verarbeiten
können, oder das Netzwerk ist möglicherweise zu langsam.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der Anfragen und Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Anfragen Die Anzahl der Anfragen, die das Gerät erhalten hat wenn Sie als SMTP-Server agieren Antworten Die Anzahl der Antworten, die das Gerät gesendet hat, als fungiert als SMTP-Server Fehler Wenn das Gerät als SMTP fungiert Server, die Anzahl der gesendeten Befehlsantworten, die einen Antwortcode haben >= 400. Abgebrochene Anfragen Die Anzahl der Anfragen, die dieses SMTP Der Server begann zu empfangen, empfing aber nicht vollständig, da die Verbindung abrupt geschlossen. Abgebrochene Antworten Die Anzahl der Anfragen, die dieses SMTP Der Server begann zu empfangen, empfing aber nicht vollständig, da die Verbindung abrupt geschlossen. Verschlüsselte Sitzungen Die Anzahl der verschlüsselten Sitzungen an denen das Gerät beteiligt war, als es als SMTP-Server fungierte - Verarbeitungszeit des Servers
-
Das Diagramm Serververarbeitungszeit zeigt die durchschnittliche Zeit, die die Server für die
Bearbeitung von Anfragen von Clients benötigten. Hohe Serververarbeitungszeiten deuten darauf hin, dass die Server in einer
Gruppe langsam sind.
Metrisch Beschreibung Verarbeitungszeit des SMTP-Servers Wenn das Gerät als SMTP-Server fungiert, die Zeit zwischen der Erkennung des letzten Pakets des empfangenen Pakets durch das ExtraHop-System Anfrage und erstes Paket der gesendeten Antwort.
SSH
Das ExtraHop-System sammelt Messwerte zur Secure Shell (SSH) -Aktivität. SSH ist ein Protokoll, das Informationen sicher über ein Netzwerk überträgt.
Überlegungen zur Sicherheit
- Die SSH-Authentifizierung kann anfällig sein für Brute-Force, bei der es sich um eine Methode zum Erraten von Anmeldedaten handelt, indem zahlreiche Authentifizierungsanfragen mit unterschiedlichen Kombinationen aus Benutzername und Passwort eingereicht werden.
- Malware kann sich tarnen Command-and-Control-Beaconing (C&C) zwischen einem kompromittierten Gerät und einem von einem Angreifer kontrollierten Server als legitimer SSH-Verkehr.
- SSH ist ein Fernwartung Protokoll, das ein Angreifer nutzen kann, um mit entfernten Geräten zu interagieren und sich seitlich im Netzwerk zu bewegen.
- SSH Anmeldedaten können gestohlen werden oder SSH-Sitzungen können missbraucht werden, um Remote-Geräte zu gefährden.
SSH-Anwendungsseite
Auf dieser Seite werden Metrikdiagramme von angezeigt SSH Verkehr, der mit einem Anwendungscontainer in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur SSH-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
SSH Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Zusammenfassung der Sitzung
- Diese Tabelle zeigt Ihnen, wann die Anwendung an SSH-Sitzungen teilgenommen hat.
Metrisch Beschreibung SSH-Sitzungen Die Anzahl der damit verbundenen SSH-Sitzungen Anwendung. Nach erfolgreichem SSH-Handshake wird eine Sitzung eingerichtet abgeschlossen. - Gesamtzahl der Sitzungen
- Diese Tabelle zeigt Ihnen, an wie vielen SSH-Sitzungen die Anwendung teilgenommen hat.
Metrisch Beschreibung SSH-Sitzungen Die Anzahl der damit verbundenen SSH-Sitzungen Anwendung. Nach erfolgreichem SSH-Handshake wird eine Sitzung eingerichtet abgeschlossen.
Einzelheiten zum SSH-Algorithmus
Die folgenden Diagramme sind in dieser Region verfügbar:
- Wichtige Austauschalgorithmen
- Dieses Diagramm zeigt, mit welchen Schlüsselaustauschalgorithmen die Anwendung am häufigsten SSH-Schlüssel erstellt hat, indem die Anzahl der SSH-Sitzungen, an denen die Anwendung teilgenommen hat, nach Schlüsselaustauschalgorithmen aufgeteilt wird.
SSH-Serverdetails
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verschlüsselungsalgorithmen
- Dieses Diagramm zeigt, welche Verschlüsselungsalgorithmus-Server in der Anwendung Daten am meisten verschlüsselt haben, indem die Anzahl der SSH-Sitzungen, an denen die Server teilgenommen haben, nach Verschlüsselungsalgorithmus wird.
- Komprimierungsalgorithmen
- Dieses Diagramm zeigt, mit welchen Komprimierungsalgorithmen Server in der Anwendung Daten am meisten komprimiert haben, indem die Anzahl der SSH-Sitzungen, an denen die Server teilgenommen haben , anhand des Komprimierungsalgorithmus aufgeschlüsselt wird.
- Die besten Implementierungen
- Dieses Diagramm zeigt, welche SSH-Implementierungen von den Servern in der Anwendung am häufigsten verwendet wurden, indem die Anzahl der SSH-Sitzungen, an denen die Server teilgenommen haben, nach Implementierung aufgeschlüsselt wurde.
- MAC-Algorithmen
- Dieses Diagramm zeigt, welche MAC-Algorithmus-Server in der Anwendung die Datenintegrität am meisten verifiziert haben, indem die Gesamtzahl der SSH-Sitzungen, an denen die Server durch MAC-Algorithmen teilgenommen haben, aufgeschlüsselt wird.
SSH-Client-Details
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verschlüsselungsalgorithmen
- Dieses Diagramm zeigt, mit welchen Verschlüsselungsalgorithmen Clients in der Anwendung Daten am meisten verschlüsselt haben, indem die Anzahl der SSH-Sitzungen, an denen die Clients teilgenommen haben, nach Verschlüsselungsalgorithmus wird.
- Komprimierungsalgorithmen
- Dieses Diagramm zeigt, welche Komprimierungsalgorithmen Clients in der Anwendung Daten am meisten komprimierten, indem die Anzahl der SSH-Sitzungen, an denen die Clients teilgenommen haben , anhand des Komprimierungsalgorithmus aufgeschlüsselt wurde.
- Die besten Implementierungen
- Dieses Diagramm zeigt, welche SSH-Implementierungen von den Clients in der Anwendung am häufigsten verwendet wurden, indem die Anzahl der SSH-Sitzungen, an denen die Clients teilgenommen haben, nach Implementierung aufgeschlüsselt wird.
- MAC-Algorithmen
- Dieses Diagramm zeigt, welche MAC-Algorithmus-Clients in der Anwendung die Datenintegrität am meisten verifiziert haben, indem die Gesamtzahl der SSH-Sitzungen, an denen die Clients durch MAC-Algorithmen teilgenommen haben, aufgeschlüsselt wird.
SSH-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines SSH-Clients oder Server Paket, das sofort bestätigt werden muss und wann die Bestätigung erfolgte erhalten. - Zeit für Hin- und Rückfahrt
-
Diese Tabelle zeigt
die durchschnittliche Hin- und Rückflugzeit für die Anwendung.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines SSH-Clients oder Server Paket, das sofort bestätigt werden muss und wann die Bestätigung erfolgte erhalten.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass ein Problem mit einem Server oder einem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
-
Dieses Diagramm zeigt die Anzahl der Nullfenster, die einer Anwendung
zugeordnet waren. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der Pakete
angeben, die über einen bestimmten Zeitraum an sie gesendet werden können.
Wenn an ein Gerät mehr Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein
Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig einzustellen, bis das Gerät den Vorgang
aufholt. Wenn Sie eine große Anzahl von Nullfenstern sehen, ist ein Server oder Client möglicherweise
nicht schnell genug, um die empfangene Datenmenge zu unterstützen.
Metrisch Definition Zero Windows anfordern Die Anzahl der gesendeten Null-Window-Anzeigen von SSH-Clients. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl eingehender Zero-Windows weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Antwort Null Windows Die Anzahl der gesendeten Null-Window-Anzeigen von Servern beim Empfang von SSH-Anfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von ausgehenden Zero-Windows weist darauf hin, dass ein Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Gesamtzahl der Host-Stände
- Dieses Diagramm zeigt die durchschnittliche Anzahl von Zero-Window-Werbeanzeigen, die von Geräten gesendet wurden.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen
Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu
viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät
eine Anfrage oder Antwort sendet und innerhalb einer bestimmten
Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen
nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise
zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Clients SSH-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server SSH-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
- Gesamtzahl der Netzwerkausfälle
-
Dieses Diagramm zeigt die durchschnittliche Anzahl von Timeouts bei der
erneuten Übertragung, die durch Überlastung beim Senden von Anfragen durch Clients und Server verursacht wurden.
Metrisch Definition RTOs Ein Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Clients SSH-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server SSH-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Gesamtwerte der SSH-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Anfragen und Antworten insgesamt
-
Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr Anfragen, als Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um herauszufinden, ob das Problem mit dem Netzwerk oder einem Server zusammenhängt, überprüfen Sie RTOs und Zero Windows in der Netzwerk-Daten Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der SSH-Anfragen und -Antworten exakt gleich ist, selbst in einer gesunden Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Sessions Die Anzahl der damit verbundenen SSH-Sitzungen Anwendung. Nach erfolgreichem SSH-Handshake wird eine Sitzung eingerichtet abgeschlossen. Durchschnittliche Sitzungsdauer Die Zeit zwischen Öffnen und Schließen die Sitzung. - SSH-Netzwerkmetriken
-
Metrisch Beschreibung Zero Windows anfordern Die Anzahl der gesendeten Null-Window-Anzeigen von SSH-Clients. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Antwort Null Windows Die Anzahl der gesendeten Null-Window-Anzeigen von Servern beim Empfang von SSH-Anfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. RTOs anfragen Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Clients SSH-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Antwort-RTOs Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server SSH-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. L2-Byte anfordern Die Anzahl der L2-Bytes, die SSH zugeordnet sind Anfragen. Antwort L2 Byte Die Anzahl der L2-Bytes, die SSH zugeordnet sind Antworten. Goodput Bytes anfordern Die Anzahl der Goodput-Bytes, die mit verknüpft sind SSH-Anfragen. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Antwort Goodput Bytes Die Anzahl der Goodput-Bytes, die mit verknüpft sind SSH-Antworten. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Pakete anfordern Die Anzahl der mit SSH verknüpften Pakete Anfragen. Antwortpakete Die Anzahl der mit SSH verknüpften Pakete Antworten.
SSH-Client-Seite
Auf dieser Seite werden Metrikdiagramme von angezeigt SSH Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur SSH-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
SSH Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Sessions
- Dieses Diagramm zeigt Ihnen, wann der Client an SSH-Sitzungen teilgenommen hat.
Metrisch Beschreibung SSH-Sitzungen Die Häufigkeit, mit der ein SSH-Handshake Handschlag wird wurde erfolgreich abgeschlossen, wenn das Gerät als SSH-Client fungiert. - Gesamtzahl der Sitzungen
- Dieses Diagramm zeigt Ihnen, an wie vielen SSH-Sitzungen der Client teilgenommen hat.
Metrisch Beschreibung SSH-Sitzungen Die Häufigkeit, mit der ein SSH-Handshake Handschlag wird wurde erfolgreich abgeschlossen, wenn das Gerät als SSH-Client fungiert.
Einzelheiten zum SSH-Algorithmus
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Verschlüsselungsalgorithmen
- Dieses Diagramm zeigt, mit welchen Verschlüsselungsalgorithmen der Client Daten am meisten verschlüsselt hat, indem die Anzahl der SSH-Sitzungen, an denen der Client teilgenommen hat, nach Verschlüsselungsalgorithmen aufgeteilt wird.
- Die besten Komprimierungsalgorithmen
- Dieses Diagramm zeigt, mit welchen Komprimierungsalgorithmen der Client Daten am meisten komprimiert hat, indem die Anzahl der SSH-Sitzungen, an denen der Client teilgenommen hat, anhand des Komprimierungsalgorithmus aufgeschlüsselt wird.
- Die wichtigsten Exchange-Algorithmen
- Dieses Diagramm zeigt, mit welchen Schlüsselaustauschalgorithmen der Client am häufigsten SSH-Schlüssel erstellt hat, indem die Anzahl der SSH-Sitzungen, an denen der Client teilgenommen hat, nach Schlüsselaustauschalgorithmen aufgeteilt wird.
- Die besten MAC-Algorithmen
- Dieses Diagramm zeigt, mit welchen MAC-Algorithmen der Client die Datenintegrität am meisten verifiziert hat, indem die Gesamtzahl der SSH-Sitzungen, an denen der Client durch MAC-Algorithmen teilgenommen hat, aufgeschlüsselt wird.
SSH-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen SSH-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Hin- und Rückflugzeit für den Client.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen SSH-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
SSH-Serverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt SSH Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur SSH-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
SSH Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Sessions
- Dieses Diagramm zeigt Ihnen, wann der Server an SSH-Sitzungen teilgenommen hat.
Metrisch Beschreibung SSH-Sitzungen Die Häufigkeit, mit der ein SSH-Handshake Handschlag wird wurde erfolgreich abgeschlossen, wenn das Gerät als SSH-Server fungiert. - Gesamtzahl der Sitzungen
- Dieses Diagramm zeigt Ihnen, an wie vielen SSH-Sitzungen der Server teilgenommen hat.
Metrisch Beschreibung SSH-Sitzungen Die Häufigkeit, mit der ein SSH-Handshake Handschlag wird wurde erfolgreich abgeschlossen, wenn das Gerät als SSH-Server fungiert.
Einzelheiten zum Algorithmus
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Verschlüsselungsalgorithmen
- Dieses Diagramm zeigt, mit welchen Verschlüsselungsalgorithmen der Server Daten am meisten verschlüsselt hat, indem die Anzahl der SSH-Sitzungen, an denen der Server teilgenommen hat, anhand des Verschlüsselungsalgorithmus aufgeschlüsselt wird.
- Die besten Komprimierungsalgorithmen
- Dieses Diagramm zeigt, mit welchen Komprimierungsalgorithmen der Server Daten am meisten komprimiert hat, indem die Anzahl der SSH-Sitzungen, an denen der Server teilgenommen hat, anhand des Komprimierungsalgorithmus aufgeschlüsselt wird.
- Die wichtigsten Exchange-Algorithmen
- Dieses Diagramm zeigt, mit welchen Schlüsselaustauschalgorithmen der Server SSH-Schlüssel am häufigsten erstellt hat, indem die Anzahl der SSH-Sitzungen, an denen der Server teilgenommen hat, nach Schlüsselaustauschalgorithmen aufgeteilt wird.
- Die besten MAC-Algorithmen
- Dieses Diagramm zeigt, mit welchen MAC-Algorithmen der Server die Datenintegrität am meisten verifiziert hat, indem die Gesamtzahl der SSH-Sitzungen, an denen der Server durch MAC-Algorithmen teilgenommen hat, aufgeschlüsselt wird.
SSH-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen SSH-Server das erforderte eine sofortige Bestätigung und wann der Server die erhielt Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Hin- und Rückflugzeit für den Client.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen SSH-Server das erforderte eine sofortige Bestätigung und wann der Server die erhielt Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
SSH-Client-Gruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt SSH Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur SSH-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
SSH Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Sessions
- Dieses Diagramm zeigt Ihnen, wann die Clients in der Gruppe an SSH-Sitzungen teilgenommen haben.
Metrisch Beschreibung SSH-Sitzungen Die Häufigkeit, mit der ein SSH-Handshake Handschlag wird wurde erfolgreich abgeschlossen, wenn das Gerät als SSH-Client fungiert. - Gesamtzahl der Sitzungen
- Dieses Diagramm zeigt Ihnen, an wie vielen SSH-Sitzungen die Kunden in der Gruppe teilgenommen haben
.
Metrisch Beschreibung SSH-Sitzungen Die Häufigkeit, mit der ein SSH-Handshake Handschlag wird wurde erfolgreich abgeschlossen, wenn das Gerät als SSH-Client fungiert.
Details zum SSH-Algorithmus für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (SSH-Clients)
- Dieses Diagramm zeigt, welche SSH-Clients in der Gruppe am aktivsten waren, indem es die Gesamtzahl der SSH-Anfragen aufschlüsselt, die die Gruppe vom Client gesendet hat.
- Chiffrieralgorithmen
- Dieses Diagramm zeigt, mit welchen Verschlüsselungsalgorithmen die Gruppe die Daten am meisten verschlüsselt hat, indem die Anzahl der SSH-Sitzungen, an denen die Gruppe teilgenommen hat, anhand des Verschlüsselungsalgorithmus aufgeschlüsselt wird.
- Wichtige Austauschalgorithmen
- Dieses Diagramm zeigt, mit welchen Schlüsselaustauschalgorithmen die Gruppe am häufigsten SSH-Schlüssel erstellt hat, indem die Anzahl der SSH-Sitzungen, an denen die Gruppe teilgenommen hat, nach Schlüsselaustauschalgorithmen aufgeschlüsselt wird.
- MAC-Algorithmen
- Dieses Diagramm zeigt, mit welchen MAC-Algorithmen die Gruppe die Datenintegrität am meisten verifiziert hat, indem die Gesamtzahl der SSH-Sitzungen, an denen die Gruppe mit MAC-Algorithmen teilgenommen hat, aufgeschlüsselt wird.
SSH-Servergruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt SSH Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur SSH-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
SSH-Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Sessions
- Dieses Diagramm zeigt Ihnen, wann die Server in der Gruppe an SSH-Sitzungen teilgenommen haben.
Metrisch Beschreibung SSH-Sitzungen Die Häufigkeit, mit der ein SSH-Handshake Handschlag wird wurde erfolgreich abgeschlossen, wenn das Gerät als SSH-Server fungiert. - Gesamtzahl der Sitzungen
- Dieses Diagramm zeigt Ihnen, an wie vielen SSH-Sitzungen die Server in der Gruppe teilgenommen haben
.
Metrisch Beschreibung SSH-Sitzungen Die Häufigkeit, mit der ein SSH-Handshake Handschlag wird wurde erfolgreich abgeschlossen, wenn das Gerät als SSH-Server fungiert.
Details zum SSH-Algorithmus für die Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (SSH-Server)
- Dieses Diagramm zeigt, welche SSH-Server in der Gruppe am aktivsten waren, indem die Gesamtzahl der SSH-Antworten, die die Gruppe vom Server gesendet hat, aufgeschlüsselt wird.
- Chiffrieralgorithmen
- Dieses Diagramm zeigt, mit welchen Verschlüsselungsalgorithmen die Gruppe die Daten am meisten verschlüsselt hat, indem die Anzahl der SSH-Sitzungen, an denen die Gruppe teilgenommen hat, anhand des Verschlüsselungsalgorithmus aufgeschlüsselt wird.
- Wichtige Austauschalgorithmen
- Dieses Diagramm zeigt, mit welchen Schlüsselaustauschalgorithmen die Gruppe am häufigsten SSH-Schlüssel erstellt hat, indem die Anzahl der SSH-Sitzungen, an denen die Gruppe teilgenommen hat, nach Schlüsselaustauschalgorithmen aufgeschlüsselt wird.
- MAC-Algorithmen
- Dieses Diagramm zeigt, mit welchen MAC-Algorithmen die Gruppe die Datenintegrität am meisten verifiziert hat, indem die Gesamtzahl der SSH-Sitzungen, an denen die Gruppe mit MAC-Algorithmen teilgenommen hat, aufgeschlüsselt wird.
SSL
Das ExtraHop-System sammelt Messwerte zur Secure Sockets Layer (SSL) -Aktivität. SSL ist ein Standardprotokoll zur Sicherung der Kommunikation über das Internet. Um eine verschlüsselte Verbindung zwischen einem Webbrowser und einem Server herzustellen, muss der Server über ein SSL-Zertifikat verfügen.
| Hinweis: | SSL-Metriken können Informationen über SSL-Verkehr enthalten, der über HTTP-CONNECT getunnelt wird. |
Erfahren Sie mehr, indem Sie an der SSL Quick Peek-Schulung teilnehmen.
Überlegungen zur Sicherheit
- SSL 3.0, TLS 1.0 und TLS 1.1 wurden als veraltet eingestuft, da diese Versionen von SSL/TLS nur Schwache Verschlüsselung Verschlüsselungsalgorithmen unterstützen und anfällig für Angriffe wie POODLE und BEAST sind.
- Abgelaufene oder selbstsignierte SSL-/TLS-Zertifikate können Machine-in-the-Middle-Angriffe (MITM) ermöglichen.
- Verschlüsselter SSL/TLS-Verkehr ist ein zunehmend verbreiteter Vektor für bösartige Aktivität. Sie können das ExtraHop-System so konfigurieren SSL-/TLS-Verkehr entschlüsseln um Erkennungen zu ermöglichen, mit denen verdächtiges Verhalten und potenzielle Angriffe identifiziert werden können.
SSL-Anwendungsseite
Auf dieser Seite werden Metrikdiagramme von angezeigt SSL Verkehr, der mit einem Anwendungscontainer in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur SSL-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
SSL Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Sessions
- Dieses Diagramm zeigt Ihnen, wann die Anwendung an SSL-Sitzungen teilgenommen hat.
Metrisch Beschreibung Verbundene Sitzungen Die Anzahl der eingerichteten sicheren Verbindungen aufgrund eines abgeschlossenen SSL-Handshakes mit dieser Anwendung verknüpft Entschlüsselte Sitzungen Die Anzahl der verschlüsselten SSL-Sitzungen verbunden mit dieser Anwendung, für die das ExtraHop-System die notwendigen Informationen zum Entschlüsseln der Sitzung Wiederaufgenommene Sitzungen Die Häufigkeit, mit der eine SSL-Sitzung wieder aufgenommen wurde über eine neue Verbindung mit der ursprünglichen Sitzungs-ID oder dem ursprünglichen Ticket. Abgebrochene Sitzungen Die Anzahl der versuchten SSL-Sitzungen, die dies getan haben nicht über den SSL-Handshake Handschlag fortfahren. Nach dem wurden keine Daten zwischen Geräten ausgetauscht Handschlag. Wenn die Anzahl der abgebrochenen Sitzungen hoch ist, schauen Sie sich die SSL-Benachrichtigungen nach Typ an Metrik zur Bestimmung, welche Fehler aufgetreten sind, z. B. Probleme mit dem Zertifikat. Schwache Chiffren Die Anzahl der damit verbundenen Sitzungen Anwendung, die mit einer Schwache Verschlüsselung Suite ausgehandelt wurden. Das ExtraHop-System erkennt automatisch Schwache Verschlüsselung Suites. CBC, DES, 3DES, RC4, null, anonym und Export Cipher Suites gelten als schwach, da sie eine Verschlüsselung enthalten Algorithmus, von dem bekannt ist, dass er anfällig ist. Daten, die mit einer Schwache Verschlüsselung Suite verschlüsselt wurden, sind potenziell unsicher Hier ist ein Beispiel für eine Schwache Verschlüsselung Verschlüsselungssuite: TLS_ECDH_Anon_with_RC4_128_SHA
Die folgenden Verschlüsselungssuite Suite-Algorithmen werden als schwach angesehen:Chiffrierblockverkettung (CBC): Dieser Algorithmus weist mehrere bekannte Sicherheitslücken auf, darunter solche im Zusammenhang mit den Angriffen Lucky Thirteen (CVE-2013-0169), POODLE (CVE-2014-3566) und BEAST (CVE-2011-3389).
Datenverschlüsselungsstandard (DES): Dieser Algorithmus wird als unsicher angesehen, da der 56-Bit-Schlüssel zu klein ist.
Dreifacher Datenverschlüsselungsalgorithmus (3DES): Dieser Algorithmus hat eine bekannte Schwachstelle (CVE-2016-2183).
Rivest Chiffre 4 (RC4): Dieser Algorithmus wird aufgrund von Verzerrungen im RC4-Keystream, die ausgenutzt werden können, als unsicher angesehen.
null: Dieser Wert gibt an, dass kein Verschlüsselungsalgorithmus auf die Daten angewendet wird.
bald: Dieser Wert gibt an, dass keine Authentifizierung auf die Daten angewendet wird.
Export: Dieser Algorithmus wurde bewusst so konzipiert, dass er schwach ist, um frühere Exportgesetze der Vereinigten Staaten zu erfüllen.
- Gesamtzahl der Sitzungen
- Dieses Diagramm zeigt Ihnen, an wie vielen SSL-Sitzungen die Anwendung teilgenommen hat.
Metrisch Beschreibung Verbundene Sitzungen Die Anzahl der eingerichteten sicheren Verbindungen aufgrund eines abgeschlossenen SSL-Handshakes mit dieser Anwendung verknüpft Entschlüsselte Sitzungen Die Anzahl der verschlüsselten SSL-Sitzungen verbunden mit dieser Anwendung, für die das ExtraHop-System die notwendigen Informationen zum Entschlüsseln der Sitzung Wiederaufgenommene Sitzungen Die Häufigkeit, mit der eine SSL-Sitzung wieder aufgenommen wurde über eine neue Verbindung mit der ursprünglichen Sitzungs-ID oder dem ursprünglichen Ticket. Abgebrochene Sitzungen Die Anzahl der versuchten SSL-Sitzungen, die dies getan haben nicht über den SSL-Handshake Handschlag fortfahren. Nach dem wurden keine Daten zwischen Geräten ausgetauscht Handschlag. Wenn die Anzahl der abgebrochenen Sitzungen hoch ist, schauen Sie sich die SSL-Benachrichtigungen nach Typ an Metrik zur Bestimmung, welche Fehler aufgetreten sind, z. B. Probleme mit dem Zertifikat. Schwache Chiffren Die Anzahl der damit verbundenen Sitzungen Anwendung, die mit einer Schwache Verschlüsselung Suite ausgehandelt wurden. Das ExtraHop-System erkennt automatisch Schwache Verschlüsselung Suites. CBC, DES, 3DES, RC4, null, anonym und Export Cipher Suites gelten als schwach, da sie eine Verschlüsselung enthalten Algorithmus, von dem bekannt ist, dass er anfällig ist. Daten, die mit einer Schwache Verschlüsselung Suite verschlüsselt wurden, sind potenziell unsicher Hier ist ein Beispiel für eine Schwache Verschlüsselung Verschlüsselungssuite: TLS_ECDH_Anon_with_RC4_128_SHA
Die folgenden Verschlüsselungssuite Suite-Algorithmen werden als schwach angesehen:Chiffrierblockverkettung (CBC): Dieser Algorithmus weist mehrere bekannte Sicherheitslücken auf, darunter solche im Zusammenhang mit den Angriffen Lucky Thirteen (CVE-2013-0169), POODLE (CVE-2014-3566) und BEAST (CVE-2011-3389).
Datenverschlüsselungsstandard (DES): Dieser Algorithmus wird als unsicher angesehen, da der 56-Bit-Schlüssel zu klein ist.
Dreifacher Datenverschlüsselungsalgorithmus (3DES): Dieser Algorithmus hat eine bekannte Schwachstelle (CVE-2016-2183).
Rivest Chiffre 4 (RC4): Dieser Algorithmus wird aufgrund von Verzerrungen im RC4-Keystream, die ausgenutzt werden können, als unsicher angesehen.
null: Dieser Wert gibt an, dass kein Verschlüsselungsalgorithmus auf die Daten angewendet wird.
bald: Dieser Wert gibt an, dass keine Authentifizierung auf die Daten angewendet wird.
Export: Dieser Algorithmus wurde bewusst so konzipiert, dass er schwach ist, um frühere Exportgesetze der Vereinigten Staaten zu erfüllen.
SSL-Sitzungsdetails
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Versionen
- Dieses Diagramm zeigt, über welche Versionen des SSL-Protokolls die Anwendung am häufigsten kommuniziert hat, indem
die Gesamtzahl der SSL-Sitzungen, an denen die Anwendung
teilgenommen hat, nach Protokollversion aufgeschlüsselt wird.
Metrisch Beschreibung SSL-Sitzungen nach Version Die Häufigkeit, mit der eine Sitzung verknüpft ist Diese Anwendung enthielt eine bestimmte SSL-Version. - Die wichtigsten Benachrichtigungen
- Dieses Diagramm zeigt, welche SSL-Warnungstypen die Anwendung am häufigsten gesendet oder empfangen hat, indem die Anzahl der Benachrichtigungen nach Typ
aufgeschlüsselt wird.
Metrisch Beschreibung SSL-Alerts nach Typ Die Anzahl der SSL-Benachrichtigungen, die während des SSL-Handshake oder entschlüsselte Sitzung, aufgeschlüsselt nach Typ. Jeder Warnungstyp bietet Informationen über die aufgetretene Warnung oder den schwerwiegenden Fehler. Abhängig von Wenn ein schwerwiegender Fehler auftritt, kann die Sitzung oder der Handschlag nicht fortgesetzt werden und die Sitzungen endet.
Einzelheiten zum SSL-Zertifikat
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Zertifikate
- Dieses Diagramm zeigt die wichtigsten Zertifikate, die an die Anwendung gesendet wurden, indem die
Gesamtzahl der verbundenen SSL-Sitzungen nach Zertifikat aufgeschlüsselt wird.
Metrisch Beschreibung Mit SSL verbundene Sitzungen Die Anzahl der eingerichteten sicheren Verbindungen aufgrund eines abgeschlossenen SSL-Handshakes mit dieser Anwendung verknüpft - Top-Domains (SNI)
- Dieses Diagramm zeigt, mit welchen Domänen der SSL-Client während der
SSL/TLS-Handshake-Aushandlung eine Verbindung herstellen wollte.
Metrisch Beschreibung Mit SSL verbundene Sitzungen von SNI Die Anzahl der etablierten sicheren Verbindungen aufgrund eines abgeschlossenen SSL-Handshakes, aufgelistet nach dem Hostnamen, den der Client möchte eine Verbindung herstellen mit. Der Client sendet den Hostnamen während des SSL/TLS-Handshakes Verhandlung als Teil der Server Name Indication (SNI) TLS-Erweiterung - Die besten Cipher Suites
- Dieses Diagramm zeigt, welche Chiffre für die am häufigsten verschlüsselten Daten der Anwendung geeignet ist, indem
die Anzahl der SSL-Sitzungen, an denen die Anwendung teilgenommen hat, nach Verschlüsselungssuite aufgeteilt wird.
Metrisch Beschreibung SSL-Sitzungen von Cipher Suite Die Häufigkeit, mit der eine bestimmte SSL-Verschlüsselungssammlung ausgehandelt.
SSL-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Zeit für Hin- und Rückfahrt
- Dieses Diagramm zeigt die Perzentile der Round Trip Time (RTT). Die RTT-Metrik misst, wie
lange es gedauert hat, bis Pakete vom Client oder Server sofort bestätigt wurden.
Daher ist RTT ein guter Indikator für die Leistung Ihres Netzwerk.
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines SSL-Clients oder Server Paket, das sofort bestätigt werden muss und wann die Bestätigung erfolgte erhalten. - Zeit für Hin- und Rückfahrt
- Diese Grafik zeigt den Median für RTT.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines SSL-Clients oder Server Paket, das sofort bestätigt werden muss und wann die Bestätigung erfolgte erhalten.
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass ein Problem mit einem Server oder einem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
-
Dieses Diagramm zeigt die Anzahl der Nullfenster, die einer Anwendung
zugeordnet waren. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der Pakete
angeben, die über einen bestimmten Zeitraum an sie gesendet werden können.
Wenn an ein Gerät mehr Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein
Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig einzustellen, bis das Gerät den Vorgang
aufholt. Wenn Sie eine große Anzahl von Nullfenstern sehen, ist ein Server oder Client möglicherweise
nicht schnell genug, um die empfangene Datenmenge zu unterstützen.
Metrisch Definition Zero Windows anfordern Die Anzahl der gesendeten Null-Window-Anzeigen von SSL-Clients. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl eingehender Zero-Windows weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Antwort Null Windows Die Anzahl der gesendeten Null-Window-Anzeigen von Servern beim Empfang von SSL-Anfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von ausgehenden Zero-Windows weist darauf hin, dass ein Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Gesamtzahl der Host-Stände
- Dieses Diagramm zeigt die durchschnittliche Anzahl von Zero-Window-Werbeanzeigen, die von Geräten gesendet wurden.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen
Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu
viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät
eine Anfrage oder Antwort sendet und innerhalb einer bestimmten
Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen
nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise
zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Clients SSL-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server SSL-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
- Gesamtzahl der Netzwerkausfälle
-
Dieses Diagramm zeigt die durchschnittliche Anzahl von Timeouts bei der
erneuten Übertragung, die durch Überlastung beim Senden von Anfragen durch Clients und Server verursacht wurden.
Metrisch Definition RTOs Ein Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Clients SSL-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server SSL-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Gesamtwerte der SSL-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Sessions
-
Metrisch Beschreibung Verbundene Sitzungen Die Anzahl der eingerichteten sicheren Verbindungen aufgrund eines abgeschlossenen SSL-Handshakes mit dieser Anwendung verknüpft Entschlüsselte Sitzungen Die Anzahl der verschlüsselten SSL-Sitzungen verbunden mit dieser Anwendung, für die das ExtraHop-System die notwendigen Informationen zum Entschlüsseln der Sitzung Wiederaufgenommene Sitzungen Die Häufigkeit, mit der eine SSL-Sitzung wieder aufgenommen wurde über eine neue Verbindung mit der ursprünglichen Sitzungs-ID oder dem ursprünglichen Ticket. Abgebrochene Sitzungen Die Anzahl der versuchten SSL-Sitzungen, die dies getan haben nicht über den SSL-Handshake Handschlag fortfahren. Nach dem wurden keine Daten zwischen Geräten ausgetauscht Handschlag. Wenn die Anzahl der abgebrochenen Sitzungen hoch ist, schauen Sie sich die SSL-Benachrichtigungen nach Typ an Metrik zur Bestimmung, welche Fehler aufgetreten sind, z. B. Probleme mit dem Zertifikat. Schwache Chiffren Die Anzahl der damit verbundenen Sitzungen Anwendung, die mit einer Schwache Verschlüsselung Suite ausgehandelt wurden. Das ExtraHop-System erkennt automatisch Schwache Verschlüsselung Suites. CBC, DES, 3DES, RC4, null, anonym und Export Cipher Suites gelten als schwach, da sie eine Verschlüsselung enthalten Algorithmus, von dem bekannt ist, dass er anfällig ist. Daten, die mit einer Schwache Verschlüsselung Suite verschlüsselt wurden, sind potenziell unsicher Hier ist ein Beispiel für eine Schwache Verschlüsselung Verschlüsselungssuite: TLS_ECDH_Anon_with_RC4_128_SHA
Die folgenden Verschlüsselungssuite Suite-Algorithmen werden als schwach angesehen:Chiffrierblockverkettung (CBC): Dieser Algorithmus weist mehrere bekannte Sicherheitslücken auf, darunter solche im Zusammenhang mit den Angriffen Lucky Thirteen (CVE-2013-0169), POODLE (CVE-2014-3566) und BEAST (CVE-2011-3389).
Datenverschlüsselungsstandard (DES): Dieser Algorithmus wird als unsicher angesehen, da der 56-Bit-Schlüssel zu klein ist.
Dreifacher Datenverschlüsselungsalgorithmus (3DES): Dieser Algorithmus hat eine bekannte Schwachstelle (CVE-2016-2183).
Rivest Chiffre 4 (RC4): Dieser Algorithmus wird aufgrund von Verzerrungen im RC4-Keystream, die ausgenutzt werden können, als unsicher angesehen.
null: Dieser Wert gibt an, dass kein Verschlüsselungsalgorithmus auf die Daten angewendet wird.
bald: Dieser Wert gibt an, dass keine Authentifizierung auf die Daten angewendet wird.
Export: Dieser Algorithmus wurde bewusst so konzipiert, dass er schwach ist, um frühere Exportgesetze der Vereinigten Staaten zu erfüllen.
Neu ausgehandelte Sitzungen Die Häufigkeit einer SSL-Sitzung der mit diesem Antrag verbundene Antrag wurde neu verhandelt. Erweitertes Master Secret Die Anzahl der SSL-Sitzungen mit ein erweitertes Hauptgeheimnis. SSLv2-kompatible Sitzungen Die Anzahl der SSL-Sitzungen, für die der Ein privater Schlüssel war verfügbar, der ihre Entschlüsselung ermöglichte Selbstsignierte Zertifikate Die Anzahl der SSL-Sitzungen, die mit verknüpft sind diese Anwendung, die selbstsignierte Zertifikate enthielt. Ein selbstsigniertes Zertifikat ist mit einem eigenen privaten Schlüssel signiert. - SSL-Netzwerkmetriken
-
Metrisch Beschreibung Zero Windows anfordern Die Anzahl der gesendeten Null-Window-Anzeigen von SSL-Clients. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Antwort Null Windows Die Anzahl der gesendeten Null-Window-Anzeigen von Servern beim Empfang von SSL-Anfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. RTOs anfragen Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Clients SSL-Anfragen sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Antwort-RTOs Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server SSL-Antworten sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. L2-Byte anfordern Die Anzahl der mit SSL verknüpften L2-Bytes Anfragen. Antwort L2 Byte Die Anzahl der mit SSL verknüpften L2-Bytes Antworten. Goodput Bytes anfordern Die Anzahl der Goodput-Bytes, die mit verknüpft sind SSL-Anfragen. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Antwort Goodput Bytes Die Anzahl der Goodput-Bytes, die mit verknüpft sind SSL-Antworten. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Pakete anfordern Die Anzahl der mit SSL verknüpften Pakete Anfragen. Antwortpakete Die Anzahl der mit SSL verknüpften Pakete Antworten.
SSL-Client-Seite
Auf dieser Seite werden Metrikdiagramme von angezeigt SSL Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur SSL-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
SSL Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Sessions
- Dieses Diagramm zeigt Ihnen, wann der Client an SSL-Sitzungen teilgenommen hat.
Metrisch Beschreibung Verbundene Sitzungen Die Anzahl der eingerichteten sicheren Verbindungen von diesem SSL-Client aufgrund eines abgeschlossenen SSL-Handshakes Entschlüsselte Sitzungen Die Anzahl der verknüpften verschlüsselten Sitzungen mit diesem SSL-Client, für den das ExtraHop-System die notwendigen Informationen hatte entschlüsselt die Sitzung Wiederaufgenommene Sitzungen Die Häufigkeit, mit der eine Sitzung wieder aufgenommen wurde eine neue Verbindung mit diesem SSL-Client durch Wiederverwendung der ursprünglichen Sitzungs-ID oder Fahrkarte. Abgebrochene Sitzungen Die Anzahl der versuchten SSL-Sitzungen, die dies getan haben geht nicht über den SSL-Handshake Handschlag und führt nicht zu einer Verbindung. Es wurden keine Daten ausgetauscht zwischen Geräten. Wenn die Anzahl der abgebrochenen Sitzungen hoch ist, schauen Sie sich die SSL-Benachrichtigungen an nach Type Metrik, um zu ermitteln, welche Fehler aufgetreten sind. Schwache Chiffren Die Anzahl der Sitzungen, die eingerichtet wurden von dieser SSL-Client, der mit einer Schwache Verschlüsselung Verschlüsselungssuite ausgehandelt wurde. Das ExtraHop-System erkennt automatisch Schwache Verschlüsselung Suites. CBC, DES, 3DES, RC4, null, anonym und Export Cipher Suites gelten als schwach, da sie eine Verschlüsselung enthalten Algorithmus, von dem bekannt ist, dass er anfällig ist. Daten, die mit einer Schwache Verschlüsselung Suite verschlüsselt wurden, sind potenziell unsicher Hier ist ein Beispiel für eine Schwache Verschlüsselung Verschlüsselungssuite: TLS_ECDH_Anon_with_RC4_128_SHA
Die folgenden Verschlüsselungssuite Suite-Algorithmen werden als schwach angesehen:Chiffrierblockverkettung (CBC): Dieser Algorithmus weist mehrere bekannte Sicherheitslücken auf, darunter solche im Zusammenhang mit den Angriffen Lucky Thirteen (CVE-2013-0169), POODLE (CVE-2014-3566) und BEAST (CVE-2011-3389).
Datenverschlüsselungsstandard (DES): Dieser Algorithmus wird als unsicher angesehen, da der 56-Bit-Schlüssel zu klein ist.
Dreifacher Datenverschlüsselungsalgorithmus (3DES): Dieser Algorithmus hat eine bekannte Schwachstelle (CVE-2016-2183).
Rivest Chiffre 4 (RC4): Dieser Algorithmus wird aufgrund von Verzerrungen im RC4-Keystream, die ausgenutzt werden können, als unsicher angesehen.
null: Dieser Wert gibt an, dass kein Verschlüsselungsalgorithmus auf die Daten angewendet wird.
bald: Dieser Wert gibt an, dass keine Authentifizierung auf die Daten angewendet wird.
Export: Dieser Algorithmus wurde bewusst so konzipiert, dass er schwach ist, um frühere Exportgesetze der Vereinigten Staaten zu erfüllen.
- Gesamtzahl der Sitzungen
- Dieses Diagramm zeigt Ihnen, an wie vielen SSL-Sitzungen der Client teilgenommen hat.
Metrisch Beschreibung Verbundene Sitzungen Die Anzahl der eingerichteten sicheren Verbindungen von diesem SSL-Client aufgrund eines abgeschlossenen SSL-Handshakes Entschlüsselte Sitzungen Die Anzahl der verknüpften verschlüsselten Sitzungen mit diesem SSL-Client, für den das ExtraHop-System die notwendigen Informationen hatte entschlüsselt die Sitzung Wiederaufgenommene Sitzungen Die Häufigkeit, mit der eine Sitzung wieder aufgenommen wurde eine neue Verbindung mit diesem SSL-Client durch Wiederverwendung der ursprünglichen Sitzungs-ID oder Fahrkarte. Abgebrochene Sitzungen Die Anzahl der versuchten SSL-Sitzungen, die dies getan haben geht nicht über den SSL-Handshake Handschlag und führt nicht zu einer Verbindung. Es wurden keine Daten ausgetauscht zwischen Geräten. Wenn die Anzahl der abgebrochenen Sitzungen hoch ist, schauen Sie sich die SSL-Benachrichtigungen an nach Type Metrik, um zu ermitteln, welche Fehler aufgetreten sind. Schwache Chiffren Die Anzahl der Sitzungen, die eingerichtet wurden von dieser SSL-Client, der mit einer Schwache Verschlüsselung Verschlüsselungssuite ausgehandelt wurde. Das ExtraHop-System erkennt automatisch Schwache Verschlüsselung Suites. CBC, DES, 3DES, RC4, null, anonym und Export Cipher Suites gelten als schwach, da sie eine Verschlüsselung enthalten Algorithmus, von dem bekannt ist, dass er anfällig ist. Daten, die mit einer Schwache Verschlüsselung Suite verschlüsselt wurden, sind potenziell unsicher Hier ist ein Beispiel für eine Schwache Verschlüsselung Verschlüsselungssuite: TLS_ECDH_Anon_with_RC4_128_SHA
Die folgenden Verschlüsselungssuite Suite-Algorithmen werden als schwach angesehen:Chiffrierblockverkettung (CBC): Dieser Algorithmus weist mehrere bekannte Sicherheitslücken auf, darunter solche im Zusammenhang mit den Angriffen Lucky Thirteen (CVE-2013-0169), POODLE (CVE-2014-3566) und BEAST (CVE-2011-3389).
Datenverschlüsselungsstandard (DES): Dieser Algorithmus wird als unsicher angesehen, da der 56-Bit-Schlüssel zu klein ist.
Dreifacher Datenverschlüsselungsalgorithmus (3DES): Dieser Algorithmus hat eine bekannte Schwachstelle (CVE-2016-2183).
Rivest Chiffre 4 (RC4): Dieser Algorithmus wird aufgrund von Verzerrungen im RC4-Keystream, die ausgenutzt werden können, als unsicher angesehen.
null: Dieser Wert gibt an, dass kein Verschlüsselungsalgorithmus auf die Daten angewendet wird.
bald: Dieser Wert gibt an, dass keine Authentifizierung auf die Daten angewendet wird.
Export: Dieser Algorithmus wurde bewusst so konzipiert, dass er schwach ist, um frühere Exportgesetze der Vereinigten Staaten zu erfüllen.
SSL-Sitzungsdetails
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Versionen
- Dieses Diagramm zeigt, wie viele SSL-Sitzungen auf jeder SSL-Version stattfanden, und die Handshake-Zeit im 95.
Perzentil für jede Version.
Metrisch Beschreibung SSL-Clientsitzungen nach Version Die Anzahl der damit verbundenen Sitzungen SSL-Client, aufgeschlüsselt nach verwendeter SSL-Protokollversion. SSL-Handshake-Zeit nach Version Die Zeit, die für die Aushandlung des SSL benötigt wurde Handschlag zum Herstellen einer Verbindung, aufgelistet nach SSL-Version - Handshake-Zeit nach Version
- Dieses Diagramm zeigt die Perzentile der Handshake-Zeiten, sortiert nach SSL-Version.
Metrisch Beschreibung SSL-Handshake-Zeit nach Version Die Zeit, die für die Aushandlung des SSL benötigt wurde Handschlag zum Herstellen einer Verbindung, aufgelistet nach SSL-Version - Die wichtigsten Inhaltstypen
- Dieses Diagramm zeigt, welche Arten von Inhalten der Client am häufigsten ausgetauscht hat, indem
die Gesamtzahl der vom Client ausgetauschten SSL-Datensätze nach Inhaltstyp aufgeschlüsselt wird.
Metrisch Beschreibung Handschlag Eine Nachricht von einem ersten Austausch, bei dem sich ein Client und ein Server auf eine Protokollversion geeinigt haben, kryptografische Algorithmen ausgewählt, sich optional gegenseitig authentifiziert und Verschlüsselungstechniken mit öffentlichen Schlüsseln verwendet haben, um gemeinsame Geheimnisse zu generieren. Daten zur Bewerbung Eine über SSL/TLS gesendete Nachricht, die normalerweise direkt über der Transportschicht gesendet wird (z. B. TCP/IP). Chiffre ändern Eine Meldung, die auf eine Umstellung der Verschlüsselungsstrategien hinweist. Warnmeldungen Eine Meldung, die darauf hinweist, dass bei einer Sitzung der Status geändert wurde oder ein Fehler aufgetreten ist, z. B. ein Handshake-Fehler, eine ungültige Prüfsumme oder ein Zertifikatsproblem. - Die wichtigsten Benachrichtigungen
- Dieses Diagramm zeigt, welche SSL-Warnungstypen der Client am häufigsten gesendet oder empfangen hat, indem
die Anzahl der Alerts nach Typ aufgeteilt wird.
Metrisch Beschreibung SSL-Client-Alerts nach Typ Die Anzahl der von diesem gesendeten oder empfangenen Benachrichtigungen SSL-Client während des SSL-Handshakes oder der entschlüsselten Sitzung, aufgeschlüsselt nach Warnungstyp. Jeder Warnungstyp enthält Informationen über die Warnung oder den Zustand eines schwerwiegenden Fehlers das ist passiert. Je nachdem, wann ein schwerwiegender Fehler auftritt, die Sitzung oder der Handschlag kann nicht fortgesetzt werden und die Sitzungen enden.
Einzelheiten zum SSL-Zertifikat
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Zertifikate
- Dieses Diagramm zeigt die wichtigsten an den Client gesendeten Zertifikate, aufgeschlüsselt nach der
Gesamtzahl der verbundenen SSL-Sitzungen nach Zertifikat.
Metrisch Beschreibung Mit dem SSL-Client verbundene Sitzungen Die Anzahl der eingerichteten sicheren Verbindungen von diesem SSL-Client aufgrund eines abgeschlossenen SSL-Handshakes - Top-Domains (SNI)
- Dieses Diagramm zeigt, mit welchen Domänen der SSL-Client während der
SSL/TLS-Handshake-Aushandlung eine Verbindung herstellen wollte.
Metrisch Beschreibung Mit dem SSL-Client verbundene Sitzungen von SNI Die Anzahl der SSL-Sitzungen, die mit verknüpft sind dieser Client, aufgelistet nach dem Hostnamen, zu dem der Client eine Verbindung herstellen möchte. Der Client sendet den Hostnamen während der SSL/TLS-Handshake-Aushandlung als Teil des Servers TLS-Erweiterung für Namensangaben (SNI) - Die besten Cipher Suites
- Dieses Diagramm zeigt, welche Chiffre für die am häufigsten verschlüsselten Daten des Clients geeignet ist, indem
die Anzahl der SSL-Sitzungen, an denen der Client teilgenommen hat, nach Verschlüsselungssuite aufgeteilt wird.
Metrisch Beschreibung SSL-Clientsitzungen von Cipher Suite Die Anzahl der mit diesem SSL verknüpften Sitzungen Client, aufgeschlüsselt nach der ausgehandelten Verschlüsselungssuite
SSL-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen SSL-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Hin- und Rückflugzeit für den Client.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen SSL-Client das erforderte eine sofortige Bestätigung und als der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Gesamtwerte der SSL-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Sitzungen
-
Metrisch Beschreibung Verbundene Sitzungen Die Anzahl der eingerichteten sicheren Verbindungen von diesem SSL-Client aufgrund eines abgeschlossenen SSL-Handshakes Entschlüsselte Sitzungen Die Anzahl der verknüpften verschlüsselten Sitzungen mit diesem SSL-Client, für den das ExtraHop-System die notwendigen Informationen hatte entschlüsselt die Sitzung Wiederaufgenommene Sitzungen Die Häufigkeit, mit der eine Sitzung wieder aufgenommen wurde eine neue Verbindung mit diesem SSL-Client durch Wiederverwendung der ursprünglichen Sitzungs-ID oder Fahrkarte. Abgebrochene Sitzungen Die Anzahl der versuchten SSL-Sitzungen, die dies getan haben geht nicht über den SSL-Handshake Handschlag und führt nicht zu einer Verbindung. Es wurden keine Daten ausgetauscht zwischen Geräten. Wenn die Anzahl der abgebrochenen Sitzungen hoch ist, schauen Sie sich die SSL-Benachrichtigungen an nach Type Metrik, um zu ermitteln, welche Fehler aufgetreten sind. Schwache Chiffren Die Anzahl der Sitzungen, die eingerichtet wurden von dieser SSL-Client, der mit einer Schwache Verschlüsselung Verschlüsselungssuite ausgehandelt wurde. Das ExtraHop-System erkennt automatisch Schwache Verschlüsselung Suites. CBC, DES, 3DES, RC4, null, anonym und Export Cipher Suites gelten als schwach, da sie eine Verschlüsselung enthalten Algorithmus, von dem bekannt ist, dass er anfällig ist. Daten, die mit einer Schwache Verschlüsselung Suite verschlüsselt wurden, sind potenziell unsicher Hier ist ein Beispiel für eine Schwache Verschlüsselung Verschlüsselungssuite: TLS_ECDH_Anon_with_RC4_128_SHA
Die folgenden Verschlüsselungssuite Suite-Algorithmen werden als schwach angesehen:Chiffrierblockverkettung (CBC): Dieser Algorithmus weist mehrere bekannte Sicherheitslücken auf, darunter solche im Zusammenhang mit den Angriffen Lucky Thirteen (CVE-2013-0169), POODLE (CVE-2014-3566) und BEAST (CVE-2011-3389).
Datenverschlüsselungsstandard (DES): Dieser Algorithmus wird als unsicher angesehen, da der 56-Bit-Schlüssel zu klein ist.
Dreifacher Datenverschlüsselungsalgorithmus (3DES): Dieser Algorithmus hat eine bekannte Schwachstelle (CVE-2016-2183).
Rivest Chiffre 4 (RC4): Dieser Algorithmus wird aufgrund von Verzerrungen im RC4-Keystream, die ausgenutzt werden können, als unsicher angesehen.
null: Dieser Wert gibt an, dass kein Verschlüsselungsalgorithmus auf die Daten angewendet wird.
bald: Dieser Wert gibt an, dass keine Authentifizierung auf die Daten angewendet wird.
Export: Dieser Algorithmus wurde bewusst so konzipiert, dass er schwach ist, um frühere Exportgesetze der Vereinigten Staaten zu erfüllen.
Neu ausgehandelte Sitzungen Die Häufigkeit, mit der eine SSL-Sitzung stattgefunden hat wurde mit diesem SSL-Client neu verhandelt Sitzungen mit Extended Master Secret Wenn das Gerät als SSL-Client, die Anzahl der Sitzungen, die das erweiterte Mastergeheimnis verwenden. SSLv2-kompatible Sitzungen Wenn das Gerät als SSL fungiert client, wie oft ein SSLv2-kompatibles Hallo Selbstsignierte Zertifikate Die Anzahl der SSL-Sitzungen, die mit verknüpft sind dieser Client, der selbstsignierte Zertifikate enthielt. Ein selbstsigniertes Zertifikat ist signiert mit einem eigenen privaten Schlüssel. - Größe des Datensatzes
-
Metrisch Beschreibung Größe des Datensatzes Die Größenverteilung von SSL-Datensätzen (in Byte) wird ausgetauscht, wenn das Gerät als SSL-Client fungiert.
SSL-Serverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt SSL Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur SSL-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
SSL Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Sessions
- Dieses Diagramm zeigt Ihnen, an wie vielen SSL-Sitzungen der Client teilgenommen hat.
Metrisch Beschreibung Verbundene Sitzungen Die Anzahl der eingerichteten sicheren Verbindungen von diesem SSL-Server aufgrund eines abgeschlossenen SSL-Handshakes Entschlüsselte Sitzungen Die Anzahl der verknüpften verschlüsselten Sitzungen mit diesem SSL-Server, für den das ExtraHop-System die notwendigen Informationen hatte, um entschlüsselt die Sitzung Wiederaufgenommene Sitzungen Die Häufigkeit, mit der eine Sitzung wieder aufgenommen wurde eine neue Verbindung mit diesem SSL-Server durch Wiederverwendung der ursprünglichen Sitzungs-ID oder Fahrkarte. Abgebrochene Sitzungen Die Anzahl der versuchten SSL-Sitzungen, die dies getan haben geht nicht über den SSL-Handshake Handschlag und führt nicht zu einer Verbindung. Es wurden keine Daten ausgetauscht zwischen Geräten. Wenn die Anzahl der abgebrochenen Sitzungen hoch ist, schauen Sie sich die SSL-Benachrichtigungen an nach Type Metrik, um zu ermitteln, welche Fehler aufgetreten sind. Schwache Chiffren Die Anzahl der Sitzungen, die eingerichtet wurden von dieser SSL-Server, der mit einer Schwache Verschlüsselung Suite ausgehandelt wurde. Das ExtraHop-System erkennt automatisch Schwache Verschlüsselung Suites. CBC, DES, 3DES, RC4, null, anonym und Export Cipher Suites gelten als schwach, da sie eine Verschlüsselung enthalten Algorithmus, von dem bekannt ist, dass er anfällig ist. Daten, die mit einer Schwache Verschlüsselung Suite verschlüsselt wurden, sind potenziell unsicher Hier ist ein Beispiel für eine Schwache Verschlüsselung Verschlüsselungssuite: TLS_ECDH_Anon_with_RC4_128_SHA
Die folgenden Verschlüsselungssuite Suite-Algorithmen werden als schwach angesehen:Chiffrierblockverkettung (CBC): Dieser Algorithmus weist mehrere bekannte Sicherheitslücken auf, darunter solche im Zusammenhang mit den Angriffen Lucky Thirteen (CVE-2013-0169), POODLE (CVE-2014-3566) und BEAST (CVE-2011-3389).
Datenverschlüsselungsstandard (DES): Dieser Algorithmus wird als unsicher angesehen, da der 56-Bit-Schlüssel zu klein ist.
Dreifacher Datenverschlüsselungsalgorithmus (3DES): Dieser Algorithmus hat eine bekannte Schwachstelle (CVE-2016-2183).
Rivest Chiffre 4 (RC4): Dieser Algorithmus wird aufgrund von Verzerrungen im RC4-Keystream, die ausgenutzt werden können, als unsicher angesehen.
null: Dieser Wert gibt an, dass kein Verschlüsselungsalgorithmus auf die Daten angewendet wird.
bald: Dieser Wert gibt an, dass keine Authentifizierung auf die Daten angewendet wird.
Export: Dieser Algorithmus wurde bewusst so konzipiert, dass er schwach ist, um frühere Exportgesetze der Vereinigten Staaten zu erfüllen.
- Gesamtzahl der Sitzungen
- Dieses Diagramm zeigt Ihnen, wann der Server an SSL-Sitzungen teilgenommen hat.
Metrisch Beschreibung Verbundene Sitzungen Die Anzahl der eingerichteten sicheren Verbindungen von diesem SSL-Server aufgrund eines abgeschlossenen SSL-Handshakes Entschlüsselte Sitzungen Die Anzahl der verknüpften verschlüsselten Sitzungen mit diesem SSL-Client, für den das ExtraHop-System die notwendigen Informationen hatte entschlüsselt die Sitzung Wiederaufgenommene Sitzungen Die Häufigkeit, mit der eine Sitzung wieder aufgenommen wurde eine neue Verbindung mit diesem SSL-Server durch Wiederverwendung der ursprünglichen Sitzungs-ID oder Fahrkarte. Abgebrochene Sitzungen Die Anzahl der versuchten SSL-Sitzungen, die dies getan haben geht nicht über den SSL-Handshake Handschlag und führt nicht zu einer Verbindung. Es wurden keine Daten ausgetauscht zwischen Geräten. Wenn die Anzahl der abgebrochenen Sitzungen hoch ist, schauen Sie sich die SSL-Benachrichtigungen an nach Type Metrik, um zu ermitteln, welche Fehler aufgetreten sind. Schwache Chiffren Die Anzahl der Sitzungen, die eingerichtet wurden von dieser SSL-Server, der mit einer Schwache Verschlüsselung Suite ausgehandelt wurde. Das ExtraHop-System erkennt automatisch Schwache Verschlüsselung Suites. CBC, DES, 3DES, RC4, null, anonym und Export Cipher Suites gelten als schwach, da sie eine Verschlüsselung enthalten Algorithmus, von dem bekannt ist, dass er anfällig ist. Daten, die mit einer Schwache Verschlüsselung Suite verschlüsselt wurden, sind potenziell unsicher Hier ist ein Beispiel für eine Schwache Verschlüsselung Verschlüsselungssuite: TLS_ECDH_Anon_with_RC4_128_SHA
Die folgenden Verschlüsselungssuite Suite-Algorithmen werden als schwach angesehen:Chiffrierblockverkettung (CBC): Dieser Algorithmus weist mehrere bekannte Sicherheitslücken auf, darunter solche im Zusammenhang mit den Angriffen Lucky Thirteen (CVE-2013-0169), POODLE (CVE-2014-3566) und BEAST (CVE-2011-3389).
Datenverschlüsselungsstandard (DES): Dieser Algorithmus wird als unsicher angesehen, da der 56-Bit-Schlüssel zu klein ist.
Dreifacher Datenverschlüsselungsalgorithmus (3DES): Dieser Algorithmus hat eine bekannte Schwachstelle (CVE-2016-2183).
Rivest Chiffre 4 (RC4): Dieser Algorithmus wird aufgrund von Verzerrungen im RC4-Keystream, die ausgenutzt werden können, als unsicher angesehen.
null: Dieser Wert gibt an, dass kein Verschlüsselungsalgorithmus auf die Daten angewendet wird.
bald: Dieser Wert gibt an, dass keine Authentifizierung auf die Daten angewendet wird.
Export: Dieser Algorithmus wurde bewusst so konzipiert, dass er schwach ist, um frühere Exportgesetze der Vereinigten Staaten zu erfüllen.
SSL-Sitzungsdetails
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Versionen
- Dieses Diagramm zeigt, wie viele SSL-Sitzungen auf jeder SSL-Version stattfanden, und die Handshake-Zeit im 95.
Perzentil für jede Version.
Metrisch Beschreibung SSL-Serversitzungen nach Version Die Anzahl der damit verbundenen Sitzungen SSL-Server, aufgeschlüsselt nach verwendeter SSL-Protokollversion. SSL-Handshake-Zeit nach Version Die Zeit, die für die Aushandlung des SSL benötigt wurde Handschlag zum Herstellen einer Verbindung, aufgelistet nach SSL-Version - Handshake-Zeit nach Version
- Dieses Diagramm zeigt die Perzentile der Handshake-Zeiten, sortiert nach SSL-Version.
Metrisch Beschreibung SSL-Handshake-Zeit nach Version Die Zeit, die für die Aushandlung des SSL benötigt wurde Handschlag zum Herstellen einer Verbindung, aufgelistet nach SSL-Version - Die wichtigsten Inhaltstypen
- Dieses Diagramm zeigt, welche Inhaltstypen der Server am häufigsten ausgetauscht hat, indem
die Gesamtzahl der vom Server ausgetauschten SSL-Datensätze nach Inhaltstyp aufgeschlüsselt wird.
Metrisch Beschreibung Handschlag Eine Nachricht von einem ersten Austausch, bei dem sich ein Client und ein Server auf eine Protokollversion geeinigt haben, kryptografische Algorithmen ausgewählt, sich optional gegenseitig authentifiziert und Verschlüsselungstechniken mit öffentlichen Schlüsseln verwendet haben, um gemeinsame Geheimnisse zu generieren. Daten zur Bewerbung Eine über SSL/TLS gesendete Nachricht, die normalerweise direkt über der Transportschicht gesendet wird (z. B. TCP/IP). Chiffre ändern Eine Meldung, die auf eine Umstellung der Verschlüsselungsstrategien hinweist. Warnmeldungen Eine Meldung, die darauf hinweist, dass bei einer Sitzung der Status geändert wurde oder ein Fehler aufgetreten ist, z. B. ein Handshake-Fehler, eine ungültige Prüfsumme oder ein Zertifikatsproblem. - Die wichtigsten Benachrichtigungen
- Dieses Diagramm zeigt, welche SSL-Warnungstypen der Server am häufigsten gesendet oder empfangen hat, indem die Anzahl der Warnungen nach Typ
aufgeschlüsselt wird.
Metrisch Beschreibung SSL-Client-Alerts nach Typ Die Anzahl der von diesem gesendeten oder empfangenen Benachrichtigungen SSL-Server während des SSL-Handshakes oder der entschlüsselten Sitzung, aufgeschlüsselt nach Warnungstyp. Jeder Warnungstyp enthält Informationen über die Warn- oder schwerwiegenden Fehlerbedingungen. das ist passiert. Je nachdem, wann ein schwerwiegender Fehler auftritt, die Sitzung oder der Handschlag kann nicht fortgesetzt werden und die Sitzungen enden.
Einzelheiten zum SSL-Zertifikat
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Zertifikate
- Dieses Diagramm zeigt die wichtigsten Zertifikate, die der Server gesendet hat, indem die Gesamtzahl
der verbundenen SSL-Sitzungen nach Zertifikat aufgeschlüsselt wird.
Metrisch Beschreibung Mit dem SSL-Server verbundene Sitzungen Die Anzahl der eingerichteten sicheren Verbindungen von diesem SSL-Server aufgrund eines abgeschlossenen SSL-Handshakes - Top-Domains (SNI)
- Dieses Diagramm zeigt, zu welchen Domänen die SSL-Clients während der
SSL/TLS-Handshake-Aushandlung eine Verbindung herstellen wollten.
Metrisch Beschreibung Mit dem SSL-Server verbundene Sitzungen von SNI Die Anzahl der SSL-Sitzungen, die mit verknüpft sind dieser Server, aufgelistet nach dem Hostnamen, zu dem der Client eine Verbindung herstellen möchte. Der Client sendet den Hostnamen während der SSL/TLS-Handshake-Aushandlung als Teil des Servers TLS-Erweiterung für Namensangaben (SNI) - Die besten Cipher Suites
- Dieses Diagramm zeigt, welche Chiffre zu den am meisten verschlüsselten Daten passt, indem
die Anzahl der SSL-Sitzungen, an denen der Server teilgenommen hat, nach Verschlüsselungssuite aufgeteilt wird.
Metrisch Beschreibung SSL-Clientsitzungen von Cipher Suite Die Anzahl der mit diesem SSL verknüpften Sitzungen Server, aufgeschlüsselt nach der ausgehandelten Verschlüsselungssuite
SSL-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen SSL-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
-
Dieses Diagramm zeigt die durchschnittliche
Hin- und Rückflugzeit für den Client.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Paket durch einen SSL-Server das erforderte eine sofortige Bestätigung und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz.
Gesamtwerte der SSL-Metriken
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Sitzungen
-
Metrisch Beschreibung Verbundene Sitzungen Die Anzahl der eingerichteten sicheren Verbindungen von diesem SSL-Server aufgrund eines abgeschlossenen SSL-Handshakes Entschlüsselte Sitzungen Die Anzahl der verknüpften verschlüsselten Sitzungen mit diesem SSL-Server, für den das ExtraHop-System die notwendigen Informationen hatte, um entschlüsselt die Sitzung Wiederaufgenommene Sitzungen Die Häufigkeit, mit der eine Sitzung wieder aufgenommen wurde eine neue Verbindung mit diesem SSL-Server durch Wiederverwendung der ursprünglichen Sitzungs-ID oder Fahrkarte. Abgebrochene Sitzungen Die Anzahl der versuchten SSL-Sitzungen, die dies getan haben geht nicht über den SSL-Handshake Handschlag und führt nicht zu einer Verbindung. Es wurden keine Daten ausgetauscht zwischen Geräten. Wenn die Anzahl der abgebrochenen Sitzungen hoch ist, schauen Sie sich die SSL-Benachrichtigungen an nach Type Metrik, um zu ermitteln, welche Fehler aufgetreten sind. Schwache Chiffren Die Anzahl der Sitzungen, die eingerichtet wurden von dieser SSL-Server, der mit einer Schwache Verschlüsselung Suite ausgehandelt wurde. Das ExtraHop-System erkennt automatisch Schwache Verschlüsselung Suites. CBC, DES, 3DES, RC4, null, anonym und Export Cipher Suites gelten als schwach, da sie eine Verschlüsselung enthalten Algorithmus, von dem bekannt ist, dass er anfällig ist. Daten, die mit einer Schwache Verschlüsselung Suite verschlüsselt wurden, sind potenziell unsicher Hier ist ein Beispiel für eine Schwache Verschlüsselung Verschlüsselungssuite: TLS_ECDH_Anon_with_RC4_128_SHA
Die folgenden Verschlüsselungssuite Suite-Algorithmen werden als schwach angesehen:Chiffrierblockverkettung (CBC): Dieser Algorithmus weist mehrere bekannte Sicherheitslücken auf, darunter solche im Zusammenhang mit den Angriffen Lucky Thirteen (CVE-2013-0169), POODLE (CVE-2014-3566) und BEAST (CVE-2011-3389).
Datenverschlüsselungsstandard (DES): Dieser Algorithmus wird als unsicher angesehen, da der 56-Bit-Schlüssel zu klein ist.
Dreifacher Datenverschlüsselungsalgorithmus (3DES): Dieser Algorithmus hat eine bekannte Schwachstelle (CVE-2016-2183).
Rivest Chiffre 4 (RC4): Dieser Algorithmus wird aufgrund von Verzerrungen im RC4-Keystream, die ausgenutzt werden können, als unsicher angesehen.
null: Dieser Wert gibt an, dass kein Verschlüsselungsalgorithmus auf die Daten angewendet wird.
bald: Dieser Wert gibt an, dass keine Authentifizierung auf die Daten angewendet wird.
Export: Dieser Algorithmus wurde bewusst so konzipiert, dass er schwach ist, um frühere Exportgesetze der Vereinigten Staaten zu erfüllen.
Neu ausgehandelte Sitzungen Die Häufigkeit, mit der eine SSL-Sitzung stattgefunden hat wurde mit diesem SSL-Server neu verhandelt Sitzungen mit Extended Master Secret Wenn das Gerät als SSL-Server, die Anzahl der Sitzungen, die das erweiterte Mastergeheimnis verwenden. SSLv2-kompatible Sitzungen Wenn das Gerät als SSL fungiert Server, wie oft ein SSLv2-kompatibles Hallo vom Client. Selbstsignierte Zertifikate Die Anzahl der SSL-Sitzungen, die mit verknüpft sind dieser Server, der selbstsignierte Zertifikate enthielt. Ein selbstsigniertes Zertifikat ist signiert mit einem eigenen privaten Schlüssel. - Größe des Datensatzes
-
Metrisch Beschreibung Größe des Datensatzes Die Größenverteilung von SSL-Datensätzen (in Byte) wird ausgetauscht, wenn das Gerät als SSL-Server fungiert.
SSL-Client-Gruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt SSL Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur SSL-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
SSL Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Sessions
- Dieses Diagramm zeigt Ihnen, wann die Clients in der Gruppe an SSL-Sitzungen teilgenommen haben.
Metrisch Beschreibung Verbundene Sitzungen Die Anzahl der eingerichteten sicheren Verbindungen von diesem SSL-Client aufgrund eines abgeschlossenen SSL-Handshakes Entschlüsselte Sitzungen Die Anzahl der verknüpften verschlüsselten Sitzungen mit diesem SSL-Client, für den das ExtraHop-System die notwendigen Informationen hatte entschlüsselt die Sitzung Wiederaufgenommene Sitzungen Die Häufigkeit, mit der eine Sitzung wieder aufgenommen wurde eine neue Verbindung mit diesem SSL-Client durch Wiederverwendung der ursprünglichen Sitzungs-ID oder Fahrkarte. Abgebrochene Sitzungen Die Anzahl der versuchten SSL-Sitzungen, die dies getan haben geht nicht über den SSL-Handshake Handschlag und führt nicht zu einer Verbindung. Es wurden keine Daten ausgetauscht zwischen Geräten. Wenn die Anzahl der abgebrochenen Sitzungen hoch ist, schauen Sie sich die SSL-Benachrichtigungen an nach Type Metrik, um zu ermitteln, welche Fehler aufgetreten sind. Schwache Chiffren Die Anzahl der Sitzungen, die eingerichtet wurden von dieser SSL-Client, der mit einer Schwache Verschlüsselung Verschlüsselungssuite ausgehandelt wurde. Das ExtraHop-System erkennt automatisch Schwache Verschlüsselung Suites. CBC, DES, 3DES, RC4, null, anonym und Export Cipher Suites gelten als schwach, da sie eine Verschlüsselung enthalten Algorithmus, von dem bekannt ist, dass er anfällig ist. Daten, die mit einer Schwache Verschlüsselung Suite verschlüsselt wurden, sind potenziell unsicher Hier ist ein Beispiel für eine Schwache Verschlüsselung Verschlüsselungssuite: TLS_ECDH_Anon_with_RC4_128_SHA
Die folgenden Verschlüsselungssuite Suite-Algorithmen werden als schwach angesehen:Chiffrierblockverkettung (CBC): Dieser Algorithmus weist mehrere bekannte Sicherheitslücken auf, darunter solche im Zusammenhang mit den Angriffen Lucky Thirteen (CVE-2013-0169), POODLE (CVE-2014-3566) und BEAST (CVE-2011-3389).
Datenverschlüsselungsstandard (DES): Dieser Algorithmus wird als unsicher angesehen, da der 56-Bit-Schlüssel zu klein ist.
Dreifacher Datenverschlüsselungsalgorithmus (3DES): Dieser Algorithmus hat eine bekannte Schwachstelle (CVE-2016-2183).
Rivest Chiffre 4 (RC4): Dieser Algorithmus wird aufgrund von Verzerrungen im RC4-Keystream, die ausgenutzt werden können, als unsicher angesehen.
null: Dieser Wert gibt an, dass kein Verschlüsselungsalgorithmus auf die Daten angewendet wird.
bald: Dieser Wert gibt an, dass keine Authentifizierung auf die Daten angewendet wird.
Export: Dieser Algorithmus wurde bewusst so konzipiert, dass er schwach ist, um frühere Exportgesetze der Vereinigten Staaten zu erfüllen.
- Gesamtzahl der Sitzungen
- Dieses Diagramm zeigt Ihnen, an wie vielen SSL-Sitzungen die Clients in der Gruppe teilgenommen haben
.
Metrisch Beschreibung Verbundene Sitzungen Die Anzahl der eingerichteten sicheren Verbindungen von diesem SSL-Client aufgrund eines abgeschlossenen SSL-Handshakes Entschlüsselte Sitzungen Die Anzahl der verknüpften verschlüsselten Sitzungen mit diesem SSL-Client, für den das ExtraHop-System die notwendigen Informationen hatte entschlüsselt die Sitzung Wiederaufgenommene Sitzungen Die Häufigkeit, mit der eine Sitzung wieder aufgenommen wurde eine neue Verbindung mit diesem SSL-Client durch Wiederverwendung der ursprünglichen Sitzungs-ID oder Fahrkarte. Abgebrochene Sitzungen Die Anzahl der versuchten SSL-Sitzungen, die dies getan haben geht nicht über den SSL-Handshake Handschlag und führt nicht zu einer Verbindung. Es wurden keine Daten ausgetauscht zwischen Geräten. Wenn die Anzahl der abgebrochenen Sitzungen hoch ist, schauen Sie sich die SSL-Benachrichtigungen an nach Type Metrik, um zu ermitteln, welche Fehler aufgetreten sind. Schwache Chiffren Die Anzahl der Sitzungen, die eingerichtet wurden von dieser SSL-Client, der mit einer Schwache Verschlüsselung Verschlüsselungssuite ausgehandelt wurde. Das ExtraHop-System erkennt automatisch Schwache Verschlüsselung Suites. CBC, DES, 3DES, RC4, null, anonym und Export Cipher Suites gelten als schwach, da sie eine Verschlüsselung enthalten Algorithmus, von dem bekannt ist, dass er anfällig ist. Daten, die mit einer Schwache Verschlüsselung Suite verschlüsselt wurden, sind potenziell unsicher Hier ist ein Beispiel für eine Schwache Verschlüsselung Verschlüsselungssuite: TLS_ECDH_Anon_with_RC4_128_SHA
Die folgenden Verschlüsselungssuite Suite-Algorithmen werden als schwach angesehen:Chiffrierblockverkettung (CBC): Dieser Algorithmus weist mehrere bekannte Sicherheitslücken auf, darunter solche im Zusammenhang mit den Angriffen Lucky Thirteen (CVE-2013-0169), POODLE (CVE-2014-3566) und BEAST (CVE-2011-3389).
Datenverschlüsselungsstandard (DES): Dieser Algorithmus wird als unsicher angesehen, da der 56-Bit-Schlüssel zu klein ist.
Dreifacher Datenverschlüsselungsalgorithmus (3DES): Dieser Algorithmus hat eine bekannte Schwachstelle (CVE-2016-2183).
Rivest Chiffre 4 (RC4): Dieser Algorithmus wird aufgrund von Verzerrungen im RC4-Keystream, die ausgenutzt werden können, als unsicher angesehen.
null: Dieser Wert gibt an, dass kein Verschlüsselungsalgorithmus auf die Daten angewendet wird.
bald: Dieser Wert gibt an, dass keine Authentifizierung auf die Daten angewendet wird.
Export: Dieser Algorithmus wurde bewusst so konzipiert, dass er schwach ist, um frühere Exportgesetze der Vereinigten Staaten zu erfüllen.
SSL-Sitzungsdetails
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (SSL-Clients)
- Dieses Diagramm zeigt, welche SSL-Clients in der Gruppe am aktivsten waren, indem die
Gesamtzahl der verbundenen SSL-Sitzungen, an denen die Gruppe teilgenommen hat, nach Client wurde.
Metrisch Beschreibung Verbundene SSL-Sitzungen Die Anzahl der eingerichteten sicheren Verbindungen von diesem SSL-Client aufgrund eines abgeschlossenen SSL-Handshakes - Die besten Versionen
- Dieses Diagramm zeigt, wie viele SSL-Sitzungen auf jeder SSL-Version stattfanden, und die Handshake-Zeit im 95.
Perzentil für jede Version.
Metrisch Beschreibung SSL-Clientsitzungen nach Version Die Anzahl der damit verbundenen Sitzungen SSL-Client, aufgeschlüsselt nach verwendeter SSL-Protokollversion. SSL-Handshake-Zeit nach Version Die Zeit, die für die Aushandlung des SSL benötigt wurde Handschlag zum Herstellen einer Verbindung, aufgelistet nach SSL-Version - Die wichtigsten Inhaltstypen
- Dieses Diagramm zeigt, welche Inhaltstypen die Gruppe am häufigsten ausgetauscht hat, indem die Gesamtzahl
der von der Gruppe ausgetauschten SSL-Datensätze nach Inhaltstyp aufgeschlüsselt wird.
Metrisch Beschreibung Handschlag Eine Nachricht von einem ersten Austausch, bei dem sich ein Client und ein Server auf eine Protokollversion geeinigt haben, kryptografische Algorithmen ausgewählt, sich optional gegenseitig authentifiziert und Verschlüsselungstechniken mit öffentlichen Schlüsseln verwendet haben, um gemeinsame Geheimnisse zu generieren. Daten zur Bewerbung Eine über SSL/TLS gesendete Nachricht, die normalerweise direkt über der Transportschicht gesendet wird (z. B. TCP/IP). Chiffre ändern Eine Meldung, die auf eine Umstellung der Verschlüsselungsstrategien hinweist. Alerts Eine Meldung, die darauf hinweist, dass bei einer Sitzung der Status geändert wurde oder ein Fehler aufgetreten ist, z. B. ein Handshake-Fehler, eine ungültige Prüfsumme oder ein Zertifikatsproblem. - Die wichtigsten Benachrichtigungen
- Dieses Diagramm zeigt, welche SSL-Warnungstypen die Gruppe am häufigsten gesendet oder empfangen hat, indem die Anzahl der Benachrichtigungen nach Typ
aufgeschlüsselt wird.
Metrisch Beschreibung SSL-Client-Benachrichtigungen nach Typ Die Anzahl der von diesem gesendeten oder empfangenen Benachrichtigungen SSL-Client während des SSL-Handshakes oder der entschlüsselten Sitzung, aufgeschlüsselt nach Warnungstyp. Jeder Warnungstyp enthält Informationen über die Warnung oder den Zustand eines schwerwiegenden Fehlers das ist passiert. Je nachdem, wann ein schwerwiegender Fehler auftritt, die Sitzung oder der Handschlag kann nicht fortgesetzt werden und die Sitzungen enden.
Einzelheiten zum SSL-Zertifikat
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Cipher Suites
- Dieses Diagramm zeigt, welche Chiffre der Gruppe am meisten verschlüsselten Daten entspricht, indem
die Anzahl der SSL-Sitzungen, an denen die Gruppe teilgenommen hat, nach Verschlüsselungssuite aufgeteilt wird.
Metrisch Beschreibung SSL-Clientsitzungen von Cipher Suite Die Anzahl der mit diesem SSL verknüpften Sitzungen Client, aufgeschlüsselt nach der ausgehandelten Verschlüsselungssuite - Die besten Zertifikate
- Dieses Diagramm zeigt die wichtigsten an die Gruppe gesendeten Zertifikate, aufgeschlüsselt nach der
Gesamtzahl der verbundenen SSL-Sitzungen nach Zertifikat.
Metrisch Beschreibung Mit dem SSL-Client verbundene Sitzungen Die Anzahl der eingerichteten sicheren Verbindungen von diesem SSL-Client aufgrund eines abgeschlossenen SSL-Handshakes - Ablauf des Zertifikats
- Dieses Diagramm zeigt die Ablaufdaten der Zertifikate, die an die Gruppe gesendet wurden.
Metrisch Beschreibung Ablauf von SSL-Zertifikaten Das Verfallsdatum des Zertifikate, die diesem SSL-Client während der Sitzung von Peer-Servern präsentiert werden Verhandlungen.
SSL-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Sitzungen
-
Metrisch Beschreibung Verbundene Sitzungen Die Anzahl der eingerichteten sicheren Verbindungen von diesem SSL-Client aufgrund eines abgeschlossenen SSL-Handshakes Entschlüsselte Sitzungen Die Anzahl der verknüpften verschlüsselten Sitzungen mit diesem SSL-Client, für den das ExtraHop-System die notwendigen Informationen hatte entschlüsselt die Sitzung Wiederaufgenommene Sitzungen Die Häufigkeit, mit der eine Sitzung wieder aufgenommen wurde eine neue Verbindung mit diesem SSL-Client durch Wiederverwendung der ursprünglichen Sitzungs-ID oder Fahrkarte. Abgebrochene Sitzungen Die Anzahl der versuchten SSL-Sitzungen, die dies getan haben geht nicht über den SSL-Handshake Handschlag und führt nicht zu einer Verbindung. Es wurden keine Daten ausgetauscht zwischen Geräten. Wenn die Anzahl der abgebrochenen Sitzungen hoch ist, schauen Sie sich die SSL-Benachrichtigungen an nach Type Metrik, um zu ermitteln, welche Fehler aufgetreten sind. Schwache Chiffren Die Anzahl der Sitzungen, die eingerichtet wurden von dieser SSL-Client, der mit einer Schwache Verschlüsselung Verschlüsselungssuite ausgehandelt wurde. Das ExtraHop-System erkennt automatisch Schwache Verschlüsselung Suites. CBC, DES, 3DES, RC4, null, anonym und Export Cipher Suites gelten als schwach, da sie eine Verschlüsselung enthalten Algorithmus, von dem bekannt ist, dass er anfällig ist. Daten, die mit einer Schwache Verschlüsselung Suite verschlüsselt wurden, sind potenziell unsicher Hier ist ein Beispiel für eine Schwache Verschlüsselung Verschlüsselungssuite: TLS_ECDH_Anon_with_RC4_128_SHA
Die folgenden Verschlüsselungssuite Suite-Algorithmen werden als schwach angesehen:Chiffrierblockverkettung (CBC): Dieser Algorithmus weist mehrere bekannte Sicherheitslücken auf, darunter solche im Zusammenhang mit den Angriffen Lucky Thirteen (CVE-2013-0169), POODLE (CVE-2014-3566) und BEAST (CVE-2011-3389).
Datenverschlüsselungsstandard (DES): Dieser Algorithmus wird als unsicher angesehen, da der 56-Bit-Schlüssel zu klein ist.
Dreifacher Datenverschlüsselungsalgorithmus (3DES): Dieser Algorithmus hat eine bekannte Schwachstelle (CVE-2016-2183).
Rivest Chiffre 4 (RC4): Dieser Algorithmus wird aufgrund von Verzerrungen im RC4-Keystream, die ausgenutzt werden können, als unsicher angesehen.
null: Dieser Wert gibt an, dass kein Verschlüsselungsalgorithmus auf die Daten angewendet wird.
bald: Dieser Wert gibt an, dass keine Authentifizierung auf die Daten angewendet wird.
Export: Dieser Algorithmus wurde bewusst so konzipiert, dass er schwach ist, um frühere Exportgesetze der Vereinigten Staaten zu erfüllen.
Neu ausgehandelte Sitzungen Die Häufigkeit, mit der eine SSL-Sitzung stattgefunden hat wurde mit diesem SSL-Client neu verhandelt Sitzungen mit Extended Master Secret Wenn das Gerät als SSL-Client, die Anzahl der Sitzungen, die das erweiterte Mastergeheimnis verwenden. SSLv2-kompatible Sitzungen Wenn das Gerät als SSL fungiert client, wie oft ein SSLv2-kompatibles Hallo Selbstsignierte Zertifikate Die Anzahl der SSL-Sitzungen, die mit verknüpft sind dieser Client, der selbstsignierte Zertifikate enthielt. Ein selbstsigniertes Zertifikat ist signiert mit einem eigenen privaten Schlüssel. - Größe des Datensatzes
-
Metrisch Beschreibung Größe des Datensatzes Die Größenverteilung von SSL-Datensätzen (in Byte) wird ausgetauscht, wenn das Gerät als SSL-Client fungiert.
SSL-Servergruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt SSL Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur SSL-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
SSL Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Sitzungen
- Dieses Diagramm zeigt Ihnen, an wie vielen SSL-Sitzungen die Server in der Gruppe teilgenommen haben
.
Metrisch Beschreibung Verbundene Sitzungen Die Anzahl der eingerichteten sicheren Verbindungen von diesem SSL-Server aufgrund eines abgeschlossenen SSL-Handshakes Entschlüsselte Sitzungen Die Anzahl der verknüpften verschlüsselten Sitzungen mit diesem SSL-Server, für den das ExtraHop-System die notwendigen Informationen hatte, um entschlüsselt die Sitzung Wiederaufgenommene Sitzungen Die Häufigkeit, mit der eine Sitzung wieder aufgenommen wurde eine neue Verbindung mit diesem SSL-Server durch Wiederverwendung der ursprünglichen Sitzungs-ID oder Fahrkarte. Abgebrochene Sitzungen Die Anzahl der versuchten SSL-Sitzungen, die dies getan haben geht nicht über den SSL-Handshake Handschlag und führt nicht zu einer Verbindung. Es wurden keine Daten ausgetauscht zwischen Geräten. Wenn die Anzahl der abgebrochenen Sitzungen hoch ist, schauen Sie sich die SSL-Benachrichtigungen an nach Type Metrik, um zu ermitteln, welche Fehler aufgetreten sind. Schwache Chiffren Die Anzahl der Sitzungen, die eingerichtet wurden von dieser SSL-Server, der mit einer Schwache Verschlüsselung Suite ausgehandelt wurde. Das ExtraHop-System erkennt automatisch Schwache Verschlüsselung Suites. CBC, DES, 3DES, RC4, null, anonym und Export Cipher Suites gelten als schwach, da sie eine Verschlüsselung enthalten Algorithmus, von dem bekannt ist, dass er anfällig ist. Daten, die mit einer Schwache Verschlüsselung Suite verschlüsselt wurden, sind potenziell unsicher Hier ist ein Beispiel für eine Schwache Verschlüsselung Verschlüsselungssuite: TLS_ECDH_Anon_with_RC4_128_SHA
Die folgenden Verschlüsselungssuite Suite-Algorithmen werden als schwach angesehen:Chiffrierblockverkettung (CBC): Dieser Algorithmus weist mehrere bekannte Sicherheitslücken auf, darunter solche im Zusammenhang mit den Angriffen Lucky Thirteen (CVE-2013-0169), POODLE (CVE-2014-3566) und BEAST (CVE-2011-3389).
Datenverschlüsselungsstandard (DES): Dieser Algorithmus wird als unsicher angesehen, da der 56-Bit-Schlüssel zu klein ist.
Dreifacher Datenverschlüsselungsalgorithmus (3DES): Dieser Algorithmus hat eine bekannte Schwachstelle (CVE-2016-2183).
Rivest Chiffre 4 (RC4): Dieser Algorithmus wird aufgrund von Verzerrungen im RC4-Keystream, die ausgenutzt werden können, als unsicher angesehen.
null: Dieser Wert gibt an, dass kein Verschlüsselungsalgorithmus auf die Daten angewendet wird.
bald: Dieser Wert gibt an, dass keine Authentifizierung auf die Daten angewendet wird.
Export: Dieser Algorithmus wurde bewusst so konzipiert, dass er schwach ist, um frühere Exportgesetze der Vereinigten Staaten zu erfüllen.
- Sessions
- Dieses Diagramm zeigt Ihnen, wann Server in der Gruppe an SSL-Sitzungen teilgenommen haben.
Metrisch Beschreibung Verbundene Sitzungen Die Anzahl der eingerichteten sicheren Verbindungen von diesem SSL-Server aufgrund eines abgeschlossenen SSL-Handshakes Entschlüsselte Sitzungen Die Anzahl der verknüpften verschlüsselten Sitzungen mit diesem SSL-Server, für den das ExtraHop-System die notwendigen Informationen hatte, um entschlüsselt die Sitzung Wiederaufgenommene Sitzungen Die Häufigkeit, mit der eine Sitzung wieder aufgenommen wurde eine neue Verbindung mit diesem SSL-Server durch Wiederverwendung der ursprünglichen Sitzungs-ID oder Fahrkarte. Abgebrochene Sitzungen Die Anzahl der versuchten SSL-Sitzungen, die dies getan haben geht nicht über den SSL-Handshake Handschlag und führt nicht zu einer Verbindung. Es wurden keine Daten ausgetauscht zwischen Geräten. Wenn die Anzahl der abgebrochenen Sitzungen hoch ist, schauen Sie sich die SSL-Benachrichtigungen an nach Type Metrik, um zu ermitteln, welche Fehler aufgetreten sind. Schwache Chiffren Die Anzahl der Sitzungen, die eingerichtet wurden von dieser SSL-Server, der mit einer Schwache Verschlüsselung Suite ausgehandelt wurde. Das ExtraHop-System erkennt automatisch Schwache Verschlüsselung Suites. CBC, DES, 3DES, RC4, null, anonym und Export Cipher Suites gelten als schwach, da sie eine Verschlüsselung enthalten Algorithmus, von dem bekannt ist, dass er anfällig ist. Daten, die mit einer Schwache Verschlüsselung Suite verschlüsselt wurden, sind potenziell unsicher Hier ist ein Beispiel für eine Schwache Verschlüsselung Verschlüsselungssuite: TLS_ECDH_Anon_with_RC4_128_SHA
Die folgenden Verschlüsselungssuite Suite-Algorithmen werden als schwach angesehen:Chiffrierblockverkettung (CBC): Dieser Algorithmus weist mehrere bekannte Sicherheitslücken auf, darunter solche im Zusammenhang mit den Angriffen Lucky Thirteen (CVE-2013-0169), POODLE (CVE-2014-3566) und BEAST (CVE-2011-3389).
Datenverschlüsselungsstandard (DES): Dieser Algorithmus wird als unsicher angesehen, da der 56-Bit-Schlüssel zu klein ist.
Dreifacher Datenverschlüsselungsalgorithmus (3DES): Dieser Algorithmus hat eine bekannte Schwachstelle (CVE-2016-2183).
Rivest Chiffre 4 (RC4): Dieser Algorithmus wird aufgrund von Verzerrungen im RC4-Keystream, die ausgenutzt werden können, als unsicher angesehen.
null: Dieser Wert gibt an, dass kein Verschlüsselungsalgorithmus auf die Daten angewendet wird.
bald: Dieser Wert gibt an, dass keine Authentifizierung auf die Daten angewendet wird.
Export: Dieser Algorithmus wurde bewusst so konzipiert, dass er schwach ist, um frühere Exportgesetze der Vereinigten Staaten zu erfüllen.
SSL-Sitzungsdetails für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (SSL-Server)
- Dieses Diagramm zeigt, welche SSL-Server in der Gruppe am aktivsten waren, indem die
Gesamtzahl der verbundenen SSL-Sitzungen, an denen die Gruppe teilgenommen hat, nach Server wurde.
Metrisch Beschreibung Verbundene SSL-Sitzungen Die Anzahl der eingerichteten sicheren Verbindungen von diesem SSL-Client aufgrund eines abgeschlossenen SSL-Handshakes - Die besten Versionen
- Dieses Diagramm zeigt, wie viele SSL-Sitzungen auf jeder SSL-Version stattfanden, und die Handshake-Zeit im 95.
Perzentil für jede Version.
Metrisch Beschreibung SSL-Serversitzungen nach Version Die Anzahl der damit verbundenen Sitzungen SSL-Server, aufgeschlüsselt nach verwendeter SSL-Protokollversion. SSL-Handshake-Zeit nach Version Die Zeit, die für die Aushandlung des SSL benötigt wurde Handschlag zum Herstellen einer Verbindung, aufgelistet nach SSL-Version - Die wichtigsten Inhaltstypen
- Dieses Diagramm zeigt, welche Inhaltstypen die Gruppe am häufigsten ausgetauscht hat, indem die Gesamtzahl
der von der Gruppe ausgetauschten SSL-Datensätze nach Inhaltstyp aufgeschlüsselt wird.
Metrisch Beschreibung Handschlag Eine Nachricht von einem ersten Austausch, bei dem sich ein Client und ein Server auf eine Protokollversion geeinigt haben, kryptografische Algorithmen ausgewählt, sich optional gegenseitig authentifiziert und Verschlüsselungstechniken mit öffentlichen Schlüsseln verwendet haben, um gemeinsame Geheimnisse zu generieren. Daten zur Bewerbung Eine über SSL/TLS gesendete Nachricht, die normalerweise direkt über der Transportschicht gesendet wird (z. B. TCP/IP). Chiffre ändern Eine Meldung, die auf eine Umstellung der Verschlüsselungsstrategien hinweist. Alerts Eine Meldung, die darauf hinweist, dass bei einer Sitzung der Status geändert wurde oder ein Fehler aufgetreten ist, z. B. ein Handshake-Fehler, eine ungültige Prüfsumme oder ein Zertifikatsproblem. - Die wichtigsten Benachrichtigungen
- Dieses Diagramm zeigt, welche SSL-Warnungstypen die Gruppe am häufigsten gesendet oder empfangen hat, indem die Anzahl der Benachrichtigungen nach Typ
aufgeschlüsselt wird.
Metrisch Beschreibung SSL-Client-Benachrichtigungen nach Typ Die Anzahl der von diesem gesendeten oder empfangenen Benachrichtigungen SSL-Server während des SSL-Handshakes oder der entschlüsselten Sitzung, aufgeschlüsselt nach Warnungstyp. Jeder Warnungstyp enthält Informationen über die Warn- oder schwerwiegenden Fehlerbedingungen. das ist passiert. Je nachdem, wann ein schwerwiegender Fehler auftritt, die Sitzung oder der Handschlag kann nicht fortgesetzt werden und die Sitzungen enden.
Einzelheiten zum SSL-Zertifikat
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die besten Cipher Suites
- Dieses Diagramm zeigt, welche Chiffre der Gruppe am meisten verschlüsselten Daten entspricht, indem
die Anzahl der SSL-Sitzungen, an denen die Gruppe teilgenommen hat, nach Verschlüsselungssuite aufgeteilt wird.
Metrisch Beschreibung SSL-Clientsitzungen von Cipher Suite Die Anzahl der mit diesem SSL verknüpften Sitzungen Server, aufgeschlüsselt nach der ausgehandelten Verschlüsselungssuite - Die besten Zertifikate
- Dieses Diagramm zeigt die wichtigsten Zertifikate, die von der Gruppe gesendet wurden, indem die Gesamtzahl
der verbundenen SSL-Sitzungen nach Zertifikat aufgeschlüsselt wird.
Metrisch Beschreibung Mit dem SSL-Server verbundene Sitzungen Die Anzahl der eingerichteten sicheren Verbindungen von diesem SSL-Server aufgrund eines abgeschlossenen SSL-Handshakes - Ablauf des Zertifikats
- Dieses Diagramm zeigt die Ablaufdaten der von der Gruppe gesendeten Zertifikate.
Metrisch Beschreibung Ablauf von SSL-Zertifikaten Das Verfallsdatum des Zertifikate, die von diesem SSL-Server den Clients während der Sitzung präsentiert werden Verhandlungen.
SSL-Metriken für Gruppen
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Sitzungen
-
Metrisch Beschreibung Verbundene Sitzungen Die Anzahl der eingerichteten sicheren Verbindungen von diesem SSL-Server aufgrund eines abgeschlossenen SSL-Handshakes Entschlüsselte Sitzungen Die Anzahl der verknüpften verschlüsselten Sitzungen mit diesem SSL-Server, für den das ExtraHop-System die notwendigen Informationen hatte, um entschlüsselt die Sitzung Wiederaufgenommene Sitzungen Die Häufigkeit, mit der eine Sitzung wieder aufgenommen wurde eine neue Verbindung mit diesem SSL-Server durch Wiederverwendung der ursprünglichen Sitzungs-ID oder Fahrkarte. Abgebrochene Sitzungen Die Anzahl der versuchten SSL-Sitzungen, die dies getan haben geht nicht über den SSL-Handshake Handschlag und führt nicht zu einer Verbindung. Es wurden keine Daten ausgetauscht zwischen Geräten. Wenn die Anzahl der abgebrochenen Sitzungen hoch ist, schauen Sie sich die SSL-Benachrichtigungen an nach Type Metrik, um zu ermitteln, welche Fehler aufgetreten sind. Schwache Chiffren Die Anzahl der Sitzungen, die eingerichtet wurden von dieser SSL-Server, der mit einer Schwache Verschlüsselung Suite ausgehandelt wurde. Das ExtraHop-System erkennt automatisch Schwache Verschlüsselung Suites. CBC, DES, 3DES, RC4, null, anonym und Export Cipher Suites gelten als schwach, da sie eine Verschlüsselung enthalten Algorithmus, von dem bekannt ist, dass er anfällig ist. Daten, die mit einer Schwache Verschlüsselung Suite verschlüsselt wurden, sind potenziell unsicher Hier ist ein Beispiel für eine Schwache Verschlüsselung Verschlüsselungssuite: TLS_ECDH_Anon_with_RC4_128_SHA
Die folgenden Verschlüsselungssuite Suite-Algorithmen werden als schwach angesehen:Chiffrierblockverkettung (CBC): Dieser Algorithmus weist mehrere bekannte Sicherheitslücken auf, darunter solche im Zusammenhang mit den Angriffen Lucky Thirteen (CVE-2013-0169), POODLE (CVE-2014-3566) und BEAST (CVE-2011-3389).
Datenverschlüsselungsstandard (DES): Dieser Algorithmus wird als unsicher angesehen, da der 56-Bit-Schlüssel zu klein ist.
Dreifacher Datenverschlüsselungsalgorithmus (3DES): Dieser Algorithmus hat eine bekannte Schwachstelle (CVE-2016-2183).
Rivest Chiffre 4 (RC4): Dieser Algorithmus wird aufgrund von Verzerrungen im RC4-Keystream, die ausgenutzt werden können, als unsicher angesehen.
null: Dieser Wert gibt an, dass kein Verschlüsselungsalgorithmus auf die Daten angewendet wird.
bald: Dieser Wert gibt an, dass keine Authentifizierung auf die Daten angewendet wird.
Export: Dieser Algorithmus wurde bewusst so konzipiert, dass er schwach ist, um frühere Exportgesetze der Vereinigten Staaten zu erfüllen.
Neu ausgehandelte Sitzungen Die Häufigkeit, mit der eine SSL-Sitzung stattgefunden hat wurde mit diesem SSL-Server neu verhandelt Sitzungen mit Extended Master Secret Wenn das Gerät als SSL-Server, die Anzahl der Sitzungen, die das erweiterte Mastergeheimnis verwenden. SSLv2-kompatible Sitzungen Wenn das Gerät als SSL fungiert Server, wie oft ein SSLv2-kompatibles Hallo vom Client. Selbstsignierte Zertifikate Die Anzahl der SSL-Sitzungen, die mit verknüpft sind dieser Server, der selbstsignierte Zertifikate enthielt. Ein selbstsigniertes Zertifikat ist signiert mit einem eigenen privaten Schlüssel. - Größe des Datensatzes
-
Metrisch Beschreibung Größe des Datensatzes Die Größenverteilung von SSL-Datensätzen (in Byte) wird ausgetauscht, wenn das Gerät als SSL-Server fungiert.
Speicher-NAS
Das ExtraHop-System sammelt Messwerte über Netzwerkspeicher (NAS) Aktivität. NAS ist ein Speicher-Repository auf Dateiebene. Clients können über die Protokolle SMB (Server Message Block) oder NFS (Network File System) auf das Repository zugreifen.
Erfahren Sie mehr, indem Sie an der Storage Quick Peek-Schulung teilnehmen.
NAS-Anwendungsseite
Auf dieser Seite werden Metrikdiagramme von angezeigt Speicher-NAS Datenverkehr im Zusammenhang mit Anwendungscontainern in Ihrem Netzwerk.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
NAS Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Transaktionen
- Dieses Diagramm zeigt Ihnen, wann Warnungen, Fehler und Antworten des NAS mit der
Anwendung verknüpft waren. Anhand dieser Informationen können Sie feststellen, wie aktiv die Anwendung zum
Zeitpunkt des Auftretens der Fehler und Warnungen war.
In einer gesunden Umgebung sollte die Anzahl der Anfragen und Antworten ungefähr gleich sein. Weitere Informationen finden Sie unter Anfragen und Antworten.
Metrisch Beschreibung Antworten Die Anzahl der gesendeten NFS- und SMB/CIFS-Antworten oder von NAS-Geräten (Netzwerk Attached Storage) empfangen. Fehler Die Anzahl der NFS- und SMB/CIFS-Antworten Fehler, die von NAS-Geräten (Netzwerk Attached Storage) gesendet oder empfangen wurden. Fehler können unterschiedlich sein von informativ bis schwerwiegend. Eine große Menge an Fehlern sollte sein untersucht. Warnungen Die Anzahl der gesendeten Antwortwarnungen oder empfangen von NAS-Geräten (Netzwerk Attached Storage). CIFS-Antworten Die Anzahl der gesendeten SMB- /CIFS-Antworten oder empfangen von NAS-Geräten (Netzwerk Attached Storage). NFS-Antworten Die Anzahl der gesendeten oder empfangenen NFS-Antworten von NAS-Geräte (Netzwerk Attached Storage) - Transaktionen insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der NAS-Antworten, die mit der
Anwendung verknüpft waren, und wie viele dieser Antworten Warnungen und Fehler enthielten.
Metrisch Beschreibung Antworten Die Anzahl der gesendeten NFS- und SMB/CIFS-Antworten oder von NAS-Geräten (Netzwerk Attached Storage) empfangen. Fehler Die Anzahl der NFS- und SMB/CIFS-Antworten Fehler, die von NAS-Geräten (Netzwerk Attached Storage) gesendet oder empfangen wurden. Fehler können unterschiedlich sein von informativ bis schwerwiegend. Eine große Menge an Fehlern sollte sein untersucht. Warnungen Die Anzahl der gesendeten Antwortwarnungen oder empfangen von NAS-Geräten (Netzwerk Attached Storage). CIFS-Antworten Die Anzahl der gesendeten SMB- /CIFS-Antworten oder empfangen von NAS-Geräten (Netzwerk Attached Storage). NFS-Antworten Die Anzahl der gesendeten oder empfangenen NFS-Antworten von NAS-Geräte (Netzwerk Attached Storage) - Operationen
- Dieses Diagramm zeigt Ihnen, wann die Anwendung NAS-Lese-, Schreib- und Anforderungsvorgänge für
Dateisysteminformationen ausgeführt hat.
Metrisch Beschreibung Liest Die Anzahl der gesendeten Lesevorgangsanfragen oder von NAS-Geräten (Netzwerk Attached Storage) empfangen. Schreibt Die Anzahl der gesendeten Schreiboperationsanforderungen oder empfangen von NAS-Geräten (Netzwerk Attached Storage). Anfragen nach Dateisysteminformationen Die Anzahl der NFS- und SMB/CIFS-Dateisysteme Metadatenabfragen, die vom Netzwerk Attached Storage (NAS) übertragen werden Geräte. - Operationen insgesamt
- Diese Tabelle zeigt Ihnen, wie viele NAS-Lese- und Schreibvorgänge die Anwendung
ausgeführt hat.
Metrisch Beschreibung Liest Die Anzahl der gesendeten Lesevorgangsanfragen oder von NAS-Geräten (Netzwerk Attached Storage) empfangen. Schreibt Die Anzahl der gesendeten Schreiboperationsanforderungen oder empfangen von NAS-Geräten (Netzwerk Attached Storage). - Zugriffszeit (95. Perzentil)
- Dieses Diagramm zeigt das 95. Perzentil der Zugriffszeiten für die Anwendung im Zeitverlauf.
Hohe Serverzugriffszeiten deuten darauf hin, dass die Anwendung langsame Server kontaktiert.
Metrisch Beschreibung NAS-Zugriffszeit Die Zeit für den Zugriff auf eine Datei auf einem SMB/CIFS oder NFS-Partition. Für SMB/CIFS wird die Zugriffszeit gemessen, indem das erste Mal getaktet wird LESEN oder SCHREIBEN Sie in jedem Fluss. Bei NFS wird die Zugriffszeit anhand des Timings gemessen Befehle ohne Pipeline für jedes READ und - Zugriffszeit (95. Perzentil)
- Dieses Diagramm zeigt das 95. Perzentil der Zugriffszeiten für den ausgewählten Zeitraum.
Metrisch Beschreibung NAS-Zugriffszeit Die Zeit für den Zugriff auf eine Datei auf einem SMB/CIFS oder NFS-Partition. Für SMB/CIFS wird die Zugriffszeit gemessen, indem das erste Mal getaktet wird LESEN oder SCHREIBEN Sie in jedem Fluss. Bei NFS wird die Zugriffszeit anhand des Timings gemessen Befehle ohne Pipeline für jedes READ und - Leistung (95. Perzentil)
-
Dieses Diagramm zeigt das 95. Perzentil der Timing-Metriken.
Die Metriken für Transfer und Bearbeitungszeit zeigen Teile einer vollständigen
Transaktion. Die Anforderungsübertragungszeit gibt an, wie lange Clients gebraucht haben, um Anfragen an
das Netzwerk zu übertragen; die Serververarbeitungszeit zeigt, wie lange die Server für die Bearbeitung von Anfragen gebraucht haben;
und die Antwortübertragungszeit zeigt, wie lange die Server gebraucht haben, um Antworten an
das Netzwerk zu übertragen.
Die Übertragungs- und Verarbeitungszeiten werden berechnet, indem die Zeit zwischen dem Zeitpunkt gemessen wird, zu dem das erste und das letzte Paket mit Anfragen und Antworten vom ExtraHop-System erkannt werden, wie in der folgenden Abbildung dargestellt:
Es kann schwierig sein, anhand der Übertragungs- und Verarbeitungszeiten zu erkennen, ob ein Problem durch ein Netzwerk oder ein Gerät verursacht wird, da diese Kennzahlen allein ein unvollständiges Bild liefern. Daher ist die Metrik Round Trip Time (RTT) auch in dieser Tabelle enthalten. RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die Übertragungszeit der Anfrage kann hoch sein, weil der Client lange gebraucht hat, um die Anfrage zu übertragen (möglicherweise, weil die Anfrage sehr umfangreich war). Die Übertragungszeit kann jedoch auch hoch sein, weil die Übertragung der Anfrage im Netzwerk lange dauerte (möglicherweise aufgrund einer Netzwerküberlastung).
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Transferzeit anfragen Die Zeit zwischen der Erkennung durch das ExtraHop-System das erste Paket und das letzte Paket von Netzwerk Attached Storage (NAS) -Anfragen. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Verarbeitungszeit des Servers Die Zeit zwischen der Erkennung durch das ExtraHop-System das letzte Paket von Netzwerk Attached Storage (NAS) -Anfragen und das erste Paket von ihre entsprechenden Antworten. Übertragungszeit der Antwort Die Zeit zwischen der Erkennung durch das ExtraHop-System das erste Paket und das letzte Paket der Netzwerk Attached Storage (NAS) -Antworten. Eine hohe Zahl kann auf eine große Anfrage oder eine Netzwerkverzögerung hinweisen. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Zeitpunkt, an den ein Netzwerk Attached Storage angeschlossen ist (NAS) Client oder Server hat ein Paket gesendet, das eine sofortige Bestätigung erfordert, und wann Bestätigung wurde erhalten Das Leistungsdiagramm (95. Perzentil) zeigt den höchsten Wert für einen Zeitraum, während Ausreißer gefiltert werden. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Durch die Anzeige des 95. Werts und nicht des wahren Maximums bietet Ihnen das Diagramm eine genauere Ansicht der Daten:
- Aufführung (95.)
-
Wenn eine Anwendung langsam reagiert, können Sie anhand
von Leistungsübersichtsmetriken herausfinden, ob das Netzwerk oder die Server das
Problem verursachen. Diese Metriken zeigen das 95. Perzentil der Zeit, die Server für die Bearbeitung von
Anfragen von Clients benötigten, im Vergleich zum 95. Perzentil der Zeit, die Pakete aus diesen Anfragen
(und ihren jeweiligen Antworten) für die Übertragung über das Netzwerk benötigten. Hohe
Serververarbeitungszeiten deuten darauf hin, dass Clients langsame Server kontaktieren. Hohe
TCP-Roundtrip-Zeiten deuten darauf hin, dass Clients über langsame Netzwerke kommunizieren.
Metrisch Beschreibung Verarbeitungszeit des Servers Die Zeit zwischen der Erkennung durch das ExtraHop-System das letzte Paket von Netzwerk Attached Storage (NAS) -Anfragen und das erste Paket von ihre entsprechenden Antworten. Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Zeitpunkt, an den ein Netzwerk Attached Storage angeschlossen ist (NAS) Client oder Server hat ein Paket gesendet, das eine sofortige Bestätigung erfordert, und wann Bestätigung wurde erhalten
Einzelheiten zum NAS
Die folgenden Diagramme sind in dieser Region verfügbar:
- Die häufigsten Dateien
- Dieses Diagramm zeigt, auf welche Dateien die Anwendung am häufigsten zugegriffen hat, indem die Gesamtzahl der NAS-Antworten, die die Anwendung erhalten hat, nach Dateipfad aufgeschlüsselt wird.
- Die häufigsten Fehler
- Dieses Diagramm zeigt, welche NAS-Fehler am häufigsten mit der Anwendung in Verbindung gebracht wurden, indem die Anzahl der Antworten nach Fehlern aufgeschlüsselt wird.
NAS-Leistung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Verteilung der Serververarbeitungszeit
-
In diesem Diagramm werden die
Serververarbeitungszeiten in einem Histogramm dargestellt, um die häufigsten Verarbeitungszeiten darzustellen.
Metrisch Beschreibung Verarbeitungszeit des NAS-Servers Die Zeit zwischen der Erkennung durch das ExtraHop-System das letzte Paket von Netzwerk Attached Storage (NAS) -Anfragen und das erste Paket von ihre entsprechenden Antworten. - Verarbeitungszeit des Servers
-
Diese Tabelle zeigt die durchschnittliche Bearbeitungszeit für den Anwendung.
Metrisch Beschreibung Verarbeitungszeit des NAS-Servers Die Zeit zwischen der Erkennung durch das ExtraHop-System das letzte Paket von Netzwerk Attached Storage (NAS) -Anfragen und das erste Paket von ihre entsprechenden Antworten. - Verteilung der Zugriffszeit
- In diesem Diagramm werden die Zugriffszeiten in einem Histogramm dargestellt, um die häufigsten
Zugriffszeiten anzuzeigen.
Metrisch Beschreibung NAS-Zugriffszeit Die Zeit für den Zugriff auf eine Datei auf einem SMB/CIFS oder NFS-Partition. Für SMB/CIFS wird die Zugriffszeit gemessen, indem das erste Mal getaktet wird LESEN oder SCHREIBEN Sie in jedem Fluss. Bei NFS wird die Zugriffszeit anhand des Timings gemessen Befehle ohne Pipeline für jedes READ und - Zeit des Zugriffs
- Diese Tabelle zeigt die durchschnittliche Bearbeitungszeit für den Anwendung.
Metrisch Beschreibung NAS-Zugriffszeit Die Zeit für den Zugriff auf eine Datei auf einem SMB/CIFS oder NFS-Partition. Für SMB/CIFS wird die Zugriffszeit gemessen, indem das erste Mal getaktet wird LESEN oder SCHREIBEN Sie in jedem Fluss. Bei NFS wird die Zugriffszeit anhand des Timings gemessen Befehle ohne Pipeline für jedes READ und - Verteilung der Hin- und Rückreisezeit
-
In dieser Tabelle sind die Hin- und Rückflugzeiten in einem Histogramm aufgeführt, um die
häufigsten Hin- und Rückflugzeiten anzuzeigen.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Zeitpunkt, an den ein Netzwerk Attached Storage angeschlossen ist (NAS) Client oder Server hat ein Paket gesendet, das eine sofortige Bestätigung erfordert, und wann Bestätigung wurde erhalten - Zeit für Hin- und Rückfahrt
-
Diese Tabelle zeigt
die durchschnittliche Hin- und Rückflugzeit für die Anwendung.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Zeitpunkt, an den ein Netzwerk Attached Storage angeschlossen ist (NAS) Client oder Server hat ein Paket gesendet, das eine sofortige Bestätigung erfordert, und wann Bestätigung wurde erhalten
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass ein Problem mit einem Server oder einem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
-
Dieses Diagramm zeigt die Anzahl der Nullfenster, die einer Anwendung
zugeordnet waren. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der Pakete
angeben, die über einen bestimmten Zeitraum an sie gesendet werden können.
Wenn an ein Gerät mehr Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein
Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig einzustellen, bis das Gerät den Vorgang
aufholt. Wenn Sie eine große Anzahl von Nullfenstern sehen, ist ein Server oder Client möglicherweise
nicht schnell genug, um die empfangene Datenmenge zu unterstützen.
Metrisch Definition Zero Windows anfordern Die Anzahl der gesendeten Null-Window-Anzeigen von NAS-Clients (Netzwerk Attached Storage). Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl eingehender Zero-Windows weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Antwort Null Windows Die Anzahl der gesendeten Null-Window-Anzeigen von Servern beim Empfang von Netzwerk Attached Storage (NAS) -Anfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von ausgehenden Zero-Windows weist darauf hin, dass ein Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Gesamtzahl der Host-Stände
- Dieses Diagramm zeigt die durchschnittliche Anzahl von Zero-Window-Werbeanzeigen, die von Geräten gesendet wurden.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen
Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu
viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät
eine Anfrage oder Antwort sendet und innerhalb einer bestimmten
Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen
nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise
zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Timeouts für die erneute Übertragung (RTOs) verursacht durch eine Überlastung beim Senden von Netzwerk Attached Storage (NAS) -Clients Anfragen. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server NAS-Antworten (Netzwerk Attached Storage) sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
- Gesamtzahl der Netzwerkausfälle
-
Dieses Diagramm zeigt die durchschnittliche Anzahl von Timeouts bei der
erneuten Übertragung, die durch Überlastung beim Senden von Anfragen durch Clients und Server verursacht wurden.
Metrisch Definition RTOs Ein Die Anzahl der Timeouts für die erneute Übertragung (RTOs) verursacht durch eine Überlastung beim Senden von Netzwerk Attached Storage (NAS) -Clients Anfragen. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server NAS-Antworten (Netzwerk Attached Storage) sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von ausgehenden RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
NAS-Metriken insgesamt
Die folgenden Diagramme sind in dieser Region verfügbar:
- Gesamtzahl der Anfragen und Antworten
-
Anfragen und Antworten stellen die Konversation dar, die zwischen Clients und Servern stattfindet. Wenn es mehr Anfragen als Antworten gibt, senden Clients möglicherweise mehr Anfragen, als Server verarbeiten können, oder das Netzwerk ist möglicherweise zu langsam. Um herauszufinden, ob das Problem mit dem Netzwerk oder einem Server zusammenhängt, überprüfen Sie RTOs und Zero Windows in der Netzwerk-Daten Abschnitt.
Hinweis: Es ist unwahrscheinlich, dass die Gesamtzahl der NAS-Anfragen und -Antworten exakt gleich ist, selbst in einer intakten Umgebung. Möglicherweise sehen Sie sich einen Zeitraum an, in dem eine Antwort auf eine Anfrage erfasst wird, die vor Beginn des Zeitraums gesendet wurde. Im Allgemeinen gilt: Je größer der Unterschied zwischen Antworten und Fehlern ist, desto größer ist die Wahrscheinlichkeit, dass bei diesen Transaktionen ein Problem auftritt. Metrisch Beschreibung Antworten Die Anzahl der gesendeten NFS- und SMB/CIFS-Antworten oder von NAS-Geräten (Netzwerk Attached Storage) empfangen. CIFS-Antworten Die Anzahl der gesendeten SMB- /CIFS-Antworten oder empfangen von NAS-Geräten (Netzwerk Attached Storage). NFS-Antworten Die Anzahl der gesendeten oder empfangenen NFS-Antworten von NAS-Geräte (Netzwerk Attached Storage) Warnungen Die Anzahl der gesendeten Antwortwarnungen oder empfangen von NAS-Geräten (Netzwerk Attached Storage). Fehler Die Anzahl der NFS- und SMB/CIFS-Antworten Fehler, die von NAS-Geräten (Netzwerk Attached Storage) gesendet oder empfangen wurden. Fehler können unterschiedlich sein von informativ bis schwerwiegend. Eine große Menge an Fehlern sollte sein untersucht. Liest Die Anzahl der gesendeten Lesevorgangsanfragen oder von NAS-Geräten (Netzwerk Attached Storage) empfangen. Schreibt Die Anzahl der gesendeten Schreiboperationsanforderungen oder empfangen von NAS-Geräten (Netzwerk Attached Storage). Anfragen nach Dateisysteminformationen Die Anzahl der NFS- und SMB/CIFS-Dateisysteme Metadatenabfragen, die vom Netzwerk Attached Storage (NAS) übertragen werden Geräte. Schleusen Die Anzahl der NFS- und SMB/CIFS-Sperrvorgänge Anfragen, die von NAS-Geräten (Netzwerk Attached Storage) gesendet und empfangen werden. Sperren von Dateien verhindert den unbeabsichtigten Verlust von Daten durch gleichzeitige Schreibvorgänge in dieselbe Datei oder durch Beschädigung der Datei. - NAS-Netzwerkmetriken
-
Metrisch Beschreibung Zero Windows anfordern Die Anzahl der gesendeten Null-Window-Anzeigen von NAS-Clients (Netzwerk Attached Storage). Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Antwort Null Windows Die Anzahl der gesendeten Null-Window-Anzeigen von Servern beim Empfang von Netzwerk Attached Storage (NAS) -Anfragen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. RTOs anfragen Die Anzahl der Timeouts für die erneute Übertragung (RTOs) verursacht durch eine Überlastung beim Senden von Netzwerk Attached Storage (NAS) -Clients Anfragen. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Antwort-RTOs Die Anzahl der Timeouts bei der erneuten Übertragung, verursacht durch Überlastung, wenn Server NAS-Antworten (Netzwerk Attached Storage) sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. L2-Byte anfordern Die Anzahl der L2-Bytes, die mit verknüpft sind Anfragen, die von NAS-Geräten (Netzwerk Attached Storage) gesendet oder empfangen werden. Antwort L2 Byte Die Anzahl der L2-Bytes, die mit verknüpft sind Antworten, die von NAS-Geräten (Netzwerk Attached Storage) gesendet oder empfangen wurden. Goodput Bytes anfordern Die Anzahl der Goodput-Bytes, die mit verknüpft sind Anfragen, die von NAS-Geräten (Netzwerk Attached Storage) gesendet oder empfangen werden. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Antwort Goodput Bytes Die Anzahl der Goodput-Bytes, die mit verknüpft sind Antworten auf gesendete oder empfangene NAS-Geräte (Netzwerk Attached Storage). Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Pakete anfordern Die Anzahl der Pakete, die Anfragen zugeordnet sind NAS-Geräte (Netzwerk Attached Storage). Antwortpakete Die Anzahl der Pakete, die den Antworten zugeordnet sind gesendet oder empfangen von NAS-Geräten (Netzwerk Attached Storage).
Telnet
Das ExtraHop-System sammelt Messwerte zur Teletype Network Protocol (Telnet) -Aktivität. Telnet ist ein Protokoll für interaktive textorientierte Kommunikation über eine virtuelle Terminalverbindung. Telnet bietet eine Befehlszeilenschnittstelle für die Kommunikation mit einem entferntes Gerät oder Server, die manchmal für die Remoteverwaltung verwendet wird, z. B. für die Ersteinrichtung der Netzwerkhardware.
Überlegungen zur Sicherheit
- unverschlüsselt Telnet Verbindungen können vertrauliche Daten für Angreifer preisgeben, die den Telnet-Verkehr abfangen.
- Telnet ist ein Fernwartung Protokoll, das ein Angreifer nutzen kann, um mit entfernten Geräten zu interagieren und sich seitlich im Netzwerk zu bewegen.
Telnet-Client-Seite
Auf dieser Seite werden Metrikdiagramme von angezeigt Telnet Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur Telnet-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
Telnet-Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Pakete
- Dieses Diagramm zeigt, wann Telnet-Anforderungspakete gesendet und Antwortpakete vom Client
empfangen wurden.
Metrisch Beschreibung Pakete anfordern Die Anzahl der Pakete, die mit verknüpft sind Telnet-Anfragen Antwortpakete Die Anzahl der Pakete, die mit verknüpft sind Telnet-Antworten - Pakete insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der gesendeten Telnet-Anforderungspakete und der vom Server
empfangenen Antwortpakete.
Metrisch Beschreibung Pakete anfordern Die Anzahl der Pakete, die mit verknüpft sind Telnet-Anfragen Antwortpakete Die Anzahl der Pakete, die mit verknüpft sind Telnet-Antworten - Zeit für Hin- und Rückfahrt
- Dieses Diagramm zeigt die Perzentile der Round Trip Time (RTT). Die RTT-Metrik misst, wie
lange es gedauert hat, bis Pakete vom Client oder Server sofort bestätigt wurden.
Daher ist RTT ein guter Indikator für die Leistung Ihres Netzwerk.
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Anzahl der Pakete, die mit verknüpft sind Telnet-Anfragen - Zeit für Hin- und Rückfahrt
- Diese Grafik zeigt das 95. Perzentil und den Median der RTT.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Telnet-Clients an Paket, für das eine sofortige Bestätigung erforderlich war und wann der Client die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Die Leistung (95. Perzentil) Das Diagramm zeigt das 95. Perzentil, um den höchsten Wert für einen Zeitraum anzuzeigen und gleichzeitig Ausreißer zu filtern. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Die folgende Tabelle zeigt, wie die Anzeige des 95. Werts anstelle des tatsächlichen Maximums zu einer genaueren Ansicht der Daten führen kann:
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Telnet-Serverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt Telnet Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur Telnet-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
Telnet-Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Pakete
- Dieses Diagramm zeigt, wann Telnet-Anforderungspakete empfangen und Antwortpakete vom Server
gesendet wurden.
Metrisch Beschreibung Pakete anfordern Die Anzahl der Pakete, die mit verknüpft sind Telnet-Anfragen Antwortpakete Die Anzahl der Pakete, die mit verknüpft sind Telnet-Antworten - Pakete insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der vom Server empfangenen Telnet-Anforderungspakete und der gesendeten
Antwortpakete.
Metrisch Beschreibung Pakete anfordern Die Anzahl der Pakete, die mit verknüpft sind Telnet-Anfragen Antwortpakete Die Anzahl der Pakete, die mit verknüpft sind Telnet-Antworten - Zeit für Hin- und Rückfahrt
- Dieses Diagramm zeigt die Perzentile der Round Trip Time (RTT). Die RTT-Metrik misst, wie
lange es gedauert hat, bis Pakete vom Client oder Server sofort bestätigt wurden.
Daher ist RTT ein guter Indikator für die Leistung Ihres Netzwerk.
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Anzahl der Pakete, die mit verknüpft sind Telnet-Anfragen - Zusammenfassung des Zeitplans
- Diese Grafik zeigt das 95. Perzentil und den Median der RTT.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden eines Telnet-Servers Paket, das eine sofortige Bestätigung erforderte und wann der Server die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Die Leistung (95. Perzentil) Das Diagramm zeigt das 95. Perzentil, um den höchsten Wert für einen Zeitraum anzuzeigen und gleichzeitig Ausreißer zu filtern. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Die folgende Tabelle zeigt, wie die Anzeige des 95. Werts anstelle des tatsächlichen Maximums zu einer genaueren Ansicht der Daten führen kann:
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Telnet-Client-Gruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt Telnet Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur Telnet-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
Telnet Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Pakete
- Dieses Diagramm zeigt, wann Telnet-Anforderungspakete gesendet und Antwortpakete von den Clients in der Gruppe
empfangen wurden.
Metrisch Beschreibung Pakete anfordern Die Anzahl der Pakete, die mit verknüpft sind Telnet-Anfragen Antwortpakete Die Anzahl der Pakete, die mit verknüpft sind Telnet-Antworten - Pakete insgesamt
- Dieses Diagramm zeigt, wie viele Telnet-Anforderungspakete gesendet und wie viele Antwortpakete von den Clients in der Gruppe
empfangen wurden.
Metrisch Beschreibung Pakete anfordern Die Anzahl der Pakete, die mit verknüpft sind Telnet-Anfragen Antwortpakete Die Anzahl der Pakete, die mit verknüpft sind Telnet-Antworten
Telnet-Servergruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt Telnet Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über Überlegungen zur Telnet-Sicherheit
- Erfahre mehr über mit Metriken arbeiten.
Telnet Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Pakete
- Dieses Diagramm zeigt, wann Telnet-Anforderungspakete empfangen und Antwortpakete von Servern in der Gruppe
gesendet wurden.
Metrisch Beschreibung Pakete anfordern Die Anzahl der Pakete, die mit verknüpft sind Telnet-Anfragen Antwortpakete Die Anzahl der Pakete, die mit verknüpft sind Telnet-Antworten - Pakete insgesamt
- Dieses Diagramm zeigt, wie viele Telnet-Anforderungspakete von Servern in der Gruppe empfangen und Antwortpakete gesendet
wurden.
Metrisch Beschreibung Pakete anfordern Die Anzahl der Pakete, die mit verknüpft sind Telnet-Anfragen Antwortpakete Die Anzahl der Pakete, die mit verknüpft sind Telnet-Antworten
Telnet-Details für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (Telnet-Server)
- Dieses Diagramm zeigt, welche Telnet-Server in der Gruppe am aktivsten waren, indem die Gesamtzahl der Telnet-Antworten, die die Gruppe vom Server gesendet hat, aufgeschlüsselt wird.
WebSocket
Das ExtraHop-System sammelt Messwerte zur WebSocket-Aktivität. WebSocket ist ein Protokoll, das Vollduplex-Kommunikationskanäle über eine einzige TCP-Verbindung bereitstellt.
| Hinweis: | Das ExtraHop-System enthält keine integrierten Metriken für WebSocket. Sie können jedoch Trigger erstellen, die WebSocket-Aktivitäten in benutzerdefinierten Metriken Datensatz und sie einer benutzerdefinierten Seite hinzufügen oder Dashboard. |
WebSocket-Clientseite
Auf dieser Seite werden Metrikdiagramme von angezeigt WebSocket Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
WebSocket Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Nachrichten
- Dieses Diagramm zeigt Ihnen, wann WebSocket-Nachrichten vom
Client gesendet und empfangen wurden.
Metrisch Beschreibung Gesendete Nachrichten Die Anzahl der WebSocket-Nachrichten (TEXT/BINARY) gesendet oder empfangen während eines Aggregationszeitraums Empfangene Nachrichten Die Anzahl der WebSocket-Nachrichten (TEXT/BINARY) gesendet oder empfangen während eines Aggregationszeitraums - Nachrichten insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele WebSocket-Nachrichten vom
Client gesendet und empfangen wurden.
Metrisch Beschreibung Gesendete Nachrichten Die Anzahl der WebSocket-Nachrichten (TEXT/BINARY) gesendet oder empfangen während eines Aggregationszeitraums Empfangene Nachrichten Die Anzahl der WebSocket-Nachrichten (TEXT/BINARY) gesendet oder empfangen während eines Aggregationszeitraums - Zeit für Hin- und Rückfahrt
- Dieses Diagramm zeigt die Perzentile der Round Trip Time (RTT). Die RTT-Metrik misst, wie
lange es gedauert hat, bis Pakete vom Client oder Server sofort bestätigt wurden.
Daher ist RTT ein guter Indikator für die Leistung Ihres Netzwerk.
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Zeitpunkt, an dem ein WebSocket-Client sendete ein Paket, für das eine sofortige Bestätigung erforderlich war, und als der Client es erhielt die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
- Diese Grafik zeigt das 95. Perzentil und den Median der RTT.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Zeitpunkt, an dem ein WebSocket-Client sendete ein Paket, für das eine sofortige Bestätigung erforderlich war, und als der Client es erhielt die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Die Leistung (95. Perzentil) Das Diagramm zeigt das 95. Perzentil, um den höchsten Wert für einen Zeitraum anzuzeigen und gleichzeitig Ausreißer zu filtern. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Die folgende Tabelle zeigt, wie die Anzeige des 95. Werts anstelle des wahren Maximums zu einer genaueren Ansicht der Daten führen kann:
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
WebSocket-Serverseite
Auf dieser Seite werden Metrikdiagramme von angezeigt WebSocket Datenverkehr, der mit einem Gerät in Ihrem Netzwerk verbunden ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
WebSocket Zusammenfassung
Die folgenden Diagramme sind in dieser Region verfügbar:
- Nachrichten
- Dieses Diagramm zeigt Ihnen, wann WebSocket-Nachrichten vom
Server gesendet und empfangen wurden.
Metrisch Beschreibung Gesendete Nachrichten Die Anzahl der WebSocket-Nachrichten (TEXT/BINARY) gesendet oder empfangen während eines Aggregationszeitraums Empfangene Nachrichten Die Anzahl der WebSocket-Nachrichten (TEXT/BINARY) gesendet oder empfangen während eines Aggregationszeitraums - Nachrichten insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele WebSocket-Nachrichten vom
Server gesendet und empfangen wurden.
Metrisch Beschreibung Gesendete Nachrichten Die Anzahl der WebSocket-Nachrichten (TEXT/BINARY) gesendet oder empfangen während eines Aggregationszeitraums Empfangene Nachrichten Die Anzahl der WebSocket-Nachrichten (TEXT/BINARY) gesendet oder empfangen während eines Aggregationszeitraums - Zeit für Hin- und Rückfahrt
- Dieses Diagramm zeigt die Perzentile der Round Trip Time (RTT). Die RTT-Metrik misst, wie
lange es gedauert hat, bis Pakete vom Client oder Server sofort bestätigt wurden.
Daher ist RTT ein guter Indikator für die Leistung Ihres Netzwerk.
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Zeitpunkt, an dem ein WebSocket-Client sendete ein Paket, für das eine sofortige Bestätigung erforderlich war, und als der Client es erhielt die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. - Zeit für Hin- und Rückfahrt
- Diese Grafik zeigt das 95. Perzentil und den Median der RTT.
Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Zeitpunkt, an dem ein WebSocket-Client sendete ein Paket, für das eine sofortige Bestätigung erforderlich war, und als der Client es erhielt die Bestätigung. Die Round Trip Time (RTT) ist ein Maß für das Netzwerk Latenz. Die Leistung (95. Perzentil) Das Diagramm zeigt das 95. Perzentil, um den höchsten Wert für einen Zeitraum anzuzeigen und gleichzeitig Ausreißer zu filtern. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Die folgende Tabelle zeigt, wie die Anzeige des 95. Werts anstelle des wahren Maximums zu einer genaueren Ansicht der Daten führen kann:
Netzwerk-Daten
In dieser Region werden Ihnen TCP-Informationen angezeigt, die sich auf das aktuelle Protokoll beziehen. Im Allgemeinen deuten Host-Stalls darauf hin, dass entweder ein Problem mit dem Server oder dem Client vorliegt, und Netzwerk-Stalls deuten darauf hin, dass ein Problem mit dem Netzwerk vorliegt.
- Stände veranstalten
- Dieses Diagramm zeigt die Anzahl der Nullfenster, die vom
Gerät beworben oder empfangen wurden. Geräte kontrollieren die Datenmenge, die sie empfangen, indem sie die Anzahl der
Pakete angeben, die über einen bestimmten Zeitraum an sie gesendet werden können. Wenn an ein Gerät mehr
Daten gesendet werden, als es verarbeiten kann, kündigt das Gerät ein Nullfenster an, um sein Peer-Gerät aufzufordern, das Senden von Paketen vollständig
einzustellen, bis das Gerät den Vorgang aufholt. Wenn Sie eine große Anzahl
von Nullfenstern sehen, ist ein Server oder Client möglicherweise nicht schnell genug, um die empfangene
Datenmenge zu unterstützen.
Metrisch Definition Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl von Nullfenstern deutet darauf hin, dass der Client die empfangene Datenmenge zu langsam verarbeiten konnte.
- Netzwerkstände
-
Dieses Diagramm zeigt die Anzahl der aufgetretenen Timeouts bei der erneuten Übertragung. Retransmission Timeouts (RTOs) treten auf, wenn ein Netzwerk zu viele Pakete verwirft, was in der Regel auf Paketkollisionen oder eine Erschöpfung des Puffers zurückzuführen ist. Wenn ein Gerät eine Anfrage oder Antwort sendet und innerhalb einer bestimmten Zeit keine Bestätigung erhält, überträgt das Gerät die Anfrage erneut. Wenn zu viele Wiederholungen nicht bestätigt werden, erfolgt ein RTO. Wenn Sie eine große Anzahl von RTOs sehen, ist das Netzwerk möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen.
Metrisch Definition RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
WebSocket-Client-Gruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt WebSocket Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
WebSocket Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Nachrichten
- Dieses Diagramm zeigt Ihnen, wann WebSocket-Nachrichten von Clients in der
Gruppe gesendet und empfangen wurden.
Metrisch Beschreibung Gesendete Nachrichten Die Anzahl der WebSocket-Nachrichten (TEXT/BINARY) gesendet oder empfangen während eines Aggregationszeitraums Empfangene Nachrichten Die Anzahl der WebSocket-Nachrichten (TEXT/BINARY) gesendet oder empfangen während eines Aggregationszeitraums - Nachrichten insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele WebSocket-Nachrichten von Clients in
der Gruppe gesendet und empfangen wurden.
Metrisch Beschreibung Gesendete Nachrichten Die Anzahl der WebSocket-Nachrichten (TEXT/BINARY) gesendet oder empfangen während eines Aggregationszeitraums Empfangene Nachrichten Die Anzahl der WebSocket-Nachrichten (TEXT/BINARY) gesendet oder empfangen während eines Aggregationszeitraums
WebSocket-Details für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (WebSocket-Server)
- Dieses Diagramm zeigt, welche WebSocket-Clients in der Gruppe am aktivsten waren, indem es die Gesamtzahl der WebSocket-Anfragen aufschlüsselt, die die Gruppe vom Client gesendet hat.
WebSocket-Servergruppenseite
Auf dieser Seite werden Metrikdiagramme von angezeigt WebSocket Datenverkehr, der mit einer Gerätegruppe in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
WebSocket Zusammenfassung für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Nachrichten
- Dieses Diagramm zeigt Ihnen, wann WebSocket-Nachrichten von Servern in der
Gruppe gesendet und empfangen wurden.
Metrisch Beschreibung Gesendete Nachrichten Die Anzahl der WebSocket-Nachrichten (TEXT/BINARY) gesendet oder empfangen während eines Aggregationszeitraums Empfangene Nachrichten Die Anzahl der WebSocket-Nachrichten (TEXT/BINARY) gesendet oder empfangen während eines Aggregationszeitraums - Nachrichten insgesamt
- Dieses Diagramm zeigt Ihnen, wie viele WebSocket-Nachrichten von Servern in
der Gruppe gesendet und empfangen wurden.
Metrisch Beschreibung Gesendete Nachrichten Die Anzahl der WebSocket-Nachrichten (TEXT/BINARY) gesendet oder empfangen während eines Aggregationszeitraums Empfangene Nachrichten Die Anzahl der WebSocket-Nachrichten (TEXT/BINARY) gesendet oder empfangen während eines Aggregationszeitraums
WebSocket-Details für Gruppe
Die folgenden Diagramme sind in dieser Region verfügbar:
- Top-Gruppenmitglieder (WebSocket-Server)
- Dieses Diagramm zeigt, welche WebSocket-Server in der Gruppe am aktivsten waren, indem die Gesamtzahl der WebSocket-Antworten, die die Gruppe vom Server gesendet hat, aufgeschlüsselt wird.
WMI
Das ExtraHop-System sammelt Metriken über Windows Management Instrumentation (WMI) Fernprotokollaktivität. WMI ist eine Reihe von Windows-Systemerweiterungen, die eine Betriebssystemschnittstelle für die Einrichtung von Fernzugriffssitzungen bereitstellen.
| Hinweis: | Das ExtraHop-System enthält keine integrierten Metrikseiten für WMI. Sie können jedoch WMI-Metriken anzeigen, indem Sie sie zu einer benutzerdefinierten Seite hinzufügen oder Dashboard. |
Überlegungen zur Sicherheit
- WMI ermöglicht Windows und Anwendungen von Drittanbietern, Befehle an Remotegeräte zu senden. Angreifer können WMI nutzen, um entfernte Geräte zu kompromittieren und sich lateral über ein Netzwerk zu bewegen.
- Angriffstools wie Impaket, verfügen über Python-Skripte, die bösartige Befehle auf Remote-Geräten über WMI ausführen können.
FRAU
Das ExtraHop-System sammelt Metriken über das WSMAN Management-Protokoll (WSMAN) Aktivität. Das WSMAN-Protokoll ist ein SOAP-basierter, öffentlicher Standard für den Datenaustausch mit beliebigen Computergeräten.
| Hinweis: | Das ExtraHop-System enthält keine integrierten Metrikseiten für WSMAN. Sie können WSMAN-Metriken jedoch anzeigen, indem Sie sie zu einer benutzerdefinierten Seite hinzufügen oder Dashboard. |
Überlegungen zur Sicherheit
- WSMAN ermöglicht Verwaltungsprogramme wie PowerShell, um Befehle an entfernte Geräte zu senden. Angreifer können PowerShell nutzen, um Remote-Geräte zu kompromittieren und sich lateral über ein Netzwerk zu bewegen.
Kennzahlen nach Asset
Jede integrierte Asset-Seite enthält Metriken über die zugehörige Metrikquelle. Diese Metrikdiagramme können in Ihre Dashboards kopiert werden.
Geräte-Metriken
Diese Metriken beziehen sich auf Geräte, die in Ihrem Netzwerk entdeckt wurden.
Seite „Geräteübersicht"
klicken Verkehr um die Metriken für eingehenden und ausgehenden Traffic einzusehen, die die folgenden Diagramme enthalten können.
- Eingehender Verkehr
- Dieses Diagramm zeigt die vom Gerät empfangene Datenrate, gemessen in Bit pro
Sekunde.
Metrisch Beschreibungen Eingegangene Byte Der eingehende Datendurchsatz des Gerät. - Ausgehender Verkehr
- Dieses Diagramm zeigt die vom Gerät gesendete Datenrate, gemessen in Bit pro
Sekunde.
Metrisch Beschreibungen Ausgehende Bytes Der ausgehende Datendurchsatz des Gerät. - Die besten Protokolle in
- Dieses Diagramm zeigt, wann Daten vom Gerät empfangen wurden, aufgeschlüsselt nach dem
L7-Protokoll.
Metrisch Beschreibungen Durch das L7-Protokoll eingegangene Bytes Der eingehende Datendurchsatz des Gerät. - Top Protocols out
- Dieses Diagramm zeigt, wann Daten vom Gerät gesendet wurden, aufgeschlüsselt nach dem L7-Protokoll.
Metrisch Beschreibungen Ausgehende Bytes über das L7-Protokoll Der ausgehende Datendurchsatz des Gerät. - Die besten Cloud-Dienste in
- Dieses Diagramm zeigt, wann Cloud-Dienstdaten vom Gerät empfangen wurden, aufgeschlüsselt nach
den fünf wichtigsten Cloud-Diensten.
Metrisch Beschreibungen Cloud-Dienste — Byte-Zugänge nach Dienst Die Anzahl der eingehenden Byte von Cloud-Dienste, aufgelistet vom Cloud-Dienstanbieter. Diese Metrik zählt die Größe von die gesamte Paketnutzlast - Die besten Cloud-Dienste auf dem Markt
- Dieses Diagramm zeigt, wann Cloud-Dienstdaten vom Gerät gesendet wurden, aufgeschlüsselt nach den fünf
wichtigsten Cloud-Diensten.
Metrisch Beschreibungen Cloud-Dienste — Byteausgänge nach Diensten Die Anzahl der ausgehenden Byte an Cloud-Dienste, aufgelistet vom Cloud-Dienstanbieter. Diese Metrik zählt die Größe von die gesamte Paketnutzlast - Top-Kollegen
- In dieser Tabelle werden die Peer-Geräte angezeigt, die den meisten Datenverkehr mit dem Gerät ausgetauscht haben
Wo soll ich als Nächstes suchen?
Analysieren Sie eine Metrik: Sie können weitere Informationen zu einer Metrik abrufen, indem Sie auf den Metrikwert oder -namen klicken und eine Option aus dem Menü Drilldown by auswählen. Wenn Sie sich beispielsweise die Gesamtzahl der Fehler ansehen, klicken Sie auf die Zahl und wählen Sie Server um zu sehen, welche Server die Fehler zurückgegeben haben.
Den Metric Explorer durchsuchen: Integrierte Protokollseiten enthalten die am häufigsten referenzierten Metriken für ein Protokoll, aber Sie können zusätzliche Metriken im Metric Explorer sehen. Klicken Sie auf einer Protokollseite auf einen beliebigen Diagrammtitel und wählen Sie Diagramm erstellen aus.... Wenn der Metric Explorer geöffnet wird, klicken Sie auf Metrik hinzufügen im linken Bereich, um eine Drop-down-Liste mit umfassenden Messwerten für das Gerät anzuzeigen. Wenn Sie eine interessante Metrik finden, klicken Sie Zum Dashboard hinzufügen um die Metrik zu einem neuen oder vorhandenen Dashboard hinzuzufügen.
Erstellen Sie eine benutzerdefinierte Metrik: Wenn Sie eine Metrik anzeigen möchten, die nicht im Metric Explorer enthalten ist, können Sie über einen Auslöser eine benutzerdefinierte Metrik erstellen. Weitere Informationen finden Sie in den folgenden Ressourcen:
Seite „Geräte für Kinder"
Auf dieser Seite wird eine Liste der untergeordneten Geräte (auch als L3-Geräte bezeichnet) für das aktuelle Gerät angezeigt. Weitere Informationen darüber, wie das ExtraHop-System Geräte identifiziert und klassifiziert, finden Sie unter Erkennung von Geräten.
- Name
- Der primäre Name, der dem Gerät im Netzwerk zugeordnet ist. Namen werden durch die
passive Überwachung einer Vielzahl von Benennungsprotokollen entdeckt, darunter DNS, DHCP, NETBIOS und Cisco Discovery Protocol.
Wenn ein Gerätename nicht erkannt wird, wird dem Gerät anhand der MAC-Adresse eine vom NIC-Hersteller erstellte Kennung zugewiesen.
Wenn der MAC-Adressbereich nicht registriert ist oder
zu einem privaten MAC-Adressraum gehört, umfasst der Name die letzten sechs Zeichen
der MAC-Adresse (z. B. Gerät 00000c0789b1).
Das Gerätetypsymbol links neben dem Gerätenamen kennzeichnet die Aktivität, die hauptsächlich mit diesem Gerät verknüpft ist. Der Gerätename und der Gerätetyp können bearbeitet werden, indem Sie auf den Namen klicken und die Bearbeitungstools auf der Geräteseite verwenden.
- MAC-Adresse
- Die MAC-Adresse ist eine eindeutige Kennung der Gerätenetzwerkschnittstelle. Für physische Geräte mit mehreren Schnittstellen wird ein Eintrag pro Schnittstelle beibehalten. Das Herstellersymbol wird links neben der MAC-Adresse angezeigt, wie durch die MAC-OID-Suche bestimmt.
- VLAN
- Das VLAN-Tag des Gerät.
- IP Adresse
- Die primäre IP-Adresse, die das Gerät für die Kommunikation im Netzwerk verwendet. Standardmäßig wird ARP-Verkehr ( Address Resolution Protocol) verwendet, um die Zuordnung von MAC-Adressen zu IP-Adressen zu ermitteln. In Ermangelung eines solchen Datenverkehrs werden IP-Paket-Header-Informationen verwendet. Wenn kein ARP-Verkehr vorhanden ist, wird die IP-Adresse 0.0.0.0 Routing-Geräten wie Gateways, Firewalls und Load Balancern zugewiesen, um anzuzeigen, dass sie Pakete aus vielen Quellen verarbeitet .
- Entdeckungszeit
- Die Zeit, zu der das Gerät zum ersten Mal entdeckt wurde. Der Wochentag, das Kalenderdatum und die Uhrzeit werden im folgenden Format angezeigt: Mittwoch, 23. Februar, 09:01.
- Beschreibung
- Eine benutzerdefinierte Beschreibung des Gerät. Um die Gerätebeschreibung zu bearbeiten, klicken Sie auf den Gerätenamen und verwenden Sie die Bearbeitungstools auf der Geräteseite.
Seite Gerätenetzwerk
Durchsatz
- Durchsatz im Überblick
- Diese Tabelle zeigt Ihnen, wie viele Daten vom Gerät empfangen wurden.
Metrisch Beschreibung Eingehende Byte Der eingehende Datendurchsatz des Gerät. - Zusammenfassung des ausgehenden Durchsatzes
- Diese Tabelle zeigt Ihnen, wie viele Daten vom Gerät gesendet wurden.
Metrisch Beschreibung Ausgehende Bytes Der ausgehende Datendurchsatz des Gerät. - Eingehender Durchsatz
- Diese Tabelle zeigt Ihnen, wann Daten vom Gerät empfangen wurden.
Metrisch Beschreibung Eingehende Byte Der eingehende Datendurchsatz des Gerät. - Ausgehender Durchsatz
- Diese Tabelle zeigt Ihnen, wann Daten vom Gerät gesendet wurden.
Metrisch Beschreibung Ausgehende Bytes Der ausgehende Datendurchsatz des Gerät. - Eingehender Durchsatz durch das L7-Protokoll
- Diese Tabelle zeigt Ihnen, wann Daten vom Gerät empfangen wurden, aufgeschlüsselt nach dem
L7-Protokoll.
Metrisch Beschreibung Durch das L7-Protokoll eingegangene Bytes Die Anzahl der beobachteten eingehenden Bytes, aufgelistet nach dem L7-Protokoll. L7-Protokolle unterstützen die Kommunikation auf Anwendungsebene. - Ausgehender Durchsatz über das L7-Protokoll
- Diese Tabelle zeigt Ihnen, wann Daten vom Gerät gesendet wurden, aufgeschlüsselt nach dem
L7-Protokoll.
Metrisch Beschreibung Ausgehende Bytes über das L7-Protokoll Die Anzahl der beobachteten ausgehenden Byte, aufgelistet nach dem L7-Protokoll.L7-Protokolle unterstützen die Kommunikation auf Anwendungsebene.
Netzwerklatenz
Dieser Region wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
- Zeit für Hin- und Rückfahrt
- Dieses Diagramm zeigt Perzentile für die TCP-Roundtrip-Zeit des Gerät. Die RTT-Metrik
misst, wie lange es gedauert hat, bis Pakete vom
Client oder Server sofort bestätigt wurden. Das ExtraHop-System berechnet diesen Wert, indem es die Zeit
zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie
in der folgenden Abbildung dargestellt:
RTT misst nur, wie lange es dauert, bis eine sofortige Bestätigung gesendet wird; es wartet nicht, bis alle Pakete zugestellt sind. Daher ist RTT ein guter Indikator für die Leistung Ihres Netzwerk. Wenn die TCP-RTT-Zeit hoch ist, liegt möglicherweise ein Problem mit dem Netzwerk vor.
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit, die zwischen dem Senden eines Paket durch ein Gerät verstrichen ist und Empfangen einer Bestätigung (ACK). Die Round Trip Time (RTT) ist ein Maß für Netzwerklatenz. - Zeit für Hin- und Rückfahrt
- Diese Tabelle zeigt Ihnen das 95. Perzentil und den Medianwert der RTT für das Gerät.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit, die zwischen dem Senden eines Paket durch ein Gerät verstrichen ist und Empfangen einer Bestätigung (ACK). Die Round Trip Time (RTT) ist ein Maß für Netzwerklatenz. In diesem Diagramm mit der Zusammenfassung der Roundtrip-Zeit wird das 95. Perzentil hervorgehoben, um den höchsten Wert für einen Zeitraum anzuzeigen und gleichzeitig Ausreißer zu filtern. Das 95. Perzentil ist der höchste Wert, der unter 95% der Werte für einen Stichprobenzeitraum fällt. Die folgende Tabelle zeigt, wie die Anzeige des 95. Werts anstelle des wahren Maximums zu einer genaueren Ansicht der Daten führen kann:
Pakete und Fragmentierung
- Eingehende Pakete
- Diese Tabelle zeigt Ihnen, wie viele Pakete vom Gerät empfangen wurden.
Metrisch Beschreibung Eingehende Pakete Die Anzahl der eingehenden Pakete, die von der Gerät. - Ausgehende Pakete
- Diese Tabelle zeigt Ihnen, wie viele Pakete vom Gerät gesendet wurden.
Metrisch Beschreibung Ausgehende Pakete Die Anzahl der ausgehenden Pakete, die von der Gerät. - Eingangspaketrate
- Diese Tabelle zeigt Ihnen, wann Pakete vom Gerät empfangen wurden.
Metrisch Beschreibung Eingehende Pakete Die Anzahl der eingehenden Pakete, die von der Gerät. - Ausgehende Paketrate
- Diese Tabelle zeigt Ihnen, wann Pakete vom Gerät gesendet wurden.
Metrisch Beschreibung Ausgehende Pakete Die Anzahl der ausgehenden Pakete, die von der Gerät. - Paketfragmentierung eingehender
- Dieses Diagramm zeigt Ihnen, wann das Gerät IP-Datagramme empfangen hat, die während der
Übertragung fragmentiert wurden und erneut zusammengebaut werden mussten. Dieses Diagramm wird nicht angezeigt, wenn sich das Gerät im Modus Flow
Analysis befindet.
Metrisch Beschreibung Eingehende IP-Fragmente Die Anzahl der IP-Fragmente, die empfangen wurden von das Gerät. IP-Fragmentierung tritt auf, wenn ein IP-Datagramm größer als die aktuelle maximale Übertragungseinheit (MTU) ist. Damit das Paket gesendet werden kann, zerlegt der Absender das Datagramm in kleinere Teile, sogenannte Fragmente, von denen jedes seine eigenen Header-Informationen hat.Wenn Sie einen anhaltenden Anstieg dieser Zahl feststellen, vergewissern Sie sich, dass das Gerät Empfangen des erwarteten Datenverkehrs und dass die MTU-Einstellungen nicht zu niedrig sind - Ausgehende Paketfragmentierung
- Dieses Diagramm zeigt Ihnen, wann das Gerät IP-Datagramme gesendet hat, die während der Übertragung fragmentiert waren
und erneut zusammengebaut werden mussten. Dieses Diagramm wird nicht angezeigt, wenn sich das Gerät im Modus Flow
Analysis befindet.
Metrisch Beschreibung Ausgehende IP-Fragmente Die Anzahl der IP-Fragmente, die von der gesendet wurden Gerät. IP-Fragmentierung tritt auf, wenn ein IP-Datagramm größer als die aktuelle maximale Übertragungseinheit (MTU) ist. Damit das Paket gesendet werden kann, zerlegt der Absender das Datagramm in kleinere Teile, sogenannte Fragmente, von denen jedes seine eigenen Header-Informationen hat.Wenn wenn Sie einen anhaltenden Anstieg dieser Zahl sehen, stellen Sie sicher, dass das Gerät erwartungsgemäß sendet Verkehr und dass die MTU-Einstellungen nicht zu niedrig sind
Arten von Paketen
Dieser Region wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
- Arten von Paketen
- In der Tabelle ist nach Pakettyp aufgeschlüsselt, wie viele Pakete das Gerät gesendet hat.
Metrisch Beschreibung Unicast-Pakete Die Anzahl der Ethernet-Frames (Pakete), die vom Gerät als Unicast-Verkehr an das Netzwerk gesendet Multicast-Pakete Die Anzahl der Ethernet-Frames (Pakete), die vom Gerät als Multicast-Verkehr an das Netzwerk gesendet Broadcast-Pakete Die Anzahl der Ethernet-Frames (Pakete), die vom Gerät als Broadcast-Verkehr an das Netzwerk gesendet werden. - Die häufigsten Multicast-Paketgruppen
- Das Diagramm zeigt, wie viele Multicast-Pakete das Gerät pro
Multicast-Gruppe gesendet hat.
Metrisch Beschreibung Multicast-Gruppen Die Anzahl der Ethernet-Frames (Pakete), die vom Gerät als Multicast-Verkehr an das Netzwerk gesendet
DSCP-Typen (Servicequalität)
Dieser Region wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
- Die besten DSCP-Typen — eingehende Pakete
- In dieser Tabelle wird anhand des Typs Differentiated Services
Code Point (DSCP) dargestellt, wie viele Pakete das Gerät empfangen hat.
Metrisch Beschreibung Eingehende Pakete Die Anzahl der eingehenden Pakete, die von der Gerät. - Die häufigsten DSCP-Typen — Ausgehende Pakete
- In dieser Tabelle wird dargestellt, wie viele Pakete das Gerät vom Typ Differentiated Services Code
Point (DSCP) gesendet hat.
Metrisch Beschreibung Ausgehende Pakete Die Anzahl der ausgehenden Pakete, die von der Gerät.
Rahmengrößen
Dieser Region wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
- Rahmengrößen in
- In der Tabelle ist nach Größe aufgeschlüsselt, wie viele Pakete das Gerät empfangen hat.
Metrisch Beschreibung 64-Byte-Frame-Eingang Die Anzahl der Ethernet-Frames (Pakete) empfangen von dem Gerät, das 64 oder weniger Byte an Nutzlast enthielt 128-Byte-Frame-Eingang Die Anzahl der Ethernet-Frames (Pakete) vom Gerät empfangen, das zwischen 65 und 128 Byte enthielt Nutzlast 256-Byte-Frame-In Die Anzahl der Ethernet-Frames (Pakete) vom Gerät empfangen, das zwischen 129 und 256 Byte von Nutzlast 512-Byte-Frame-Eingang Die Anzahl der Ethernet-Frames (Pakete) vom Gerät empfangen, das zwischen 257 und 512 Byte enthielt Nutzlast 1024-Byte-Frame-Eingang Die Anzahl der Ethernet-Frames (Pakete) vom Gerät empfangen, die zwischen 513 und 1024 Byte enthalten 1513-Byte-Frame-In Die Anzahl der Ethernet-Frames (Pakete) vom Gerät empfangen, das zwischen 1025 und 1513 Byte von Nutzlast 1518-Byte-Frame-Eingang Die Anzahl der Ethernet-Frames (Pakete) vom Gerät empfangen, das zwischen 1514 und 1518 Byte von Nutzlast Jumbo Frames in Die Anzahl der Ethernet-Frames (Pakete) vom Gerät empfangen, die als Jumbo-Frames gelten und zwischen 1501 und 9000 Byte Nutzlast - Rahmengrößen außerhalb
- In der Tabelle ist nach Größe aufgeschlüsselt, wie viele Pakete das Gerät gesendet hat.
Metrisch Beschreibung 64-Byte-Frame-Ausgabe Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das 64 oder weniger Byte an Nutzlast enthielt 128-Byte-Frame-Ausgabe Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das zwischen 65 und 128 Byte Nutzlast enthielt 256-Byte-Frame-Ausgabe Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das zwischen 129 und 256 Byte Nutzlast enthielt 512-Byte-Frame-Ausgabe Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das zwischen 257 und 512 Byte Nutzlast enthielt 1024-Byte-Frame-Ausgabe Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das zwischen 513 und 1024 Byte enthielt Nutzlast 1513-Byte-Frame-Ausgabe Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das zwischen 1025 und 1513 Byte enthielt Nutzlast 1518-Byte-Frame-Ausgabe Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das zwischen 1514 und 1518 Byte enthielt Nutzlast Jumbo Frames raus Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das als Jumbo-Frames gilt und zwischen 1501 und 9000 enthält Byte an Nutzlast
Rahmentypen
Dieser Region wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
- Rahmentypen In
- In der Tabelle ist nach Typ aufgeführt, wie viele Pakete das Gerät empfangen hat.
Metrisch Beschreibung ARP Frames In Die Anzahl der Ethernet-Frames (Pakete) empfangen von dem Gerät, das ein ARP-Datagramm (Address Resolution Protocol) enthielt. ARP ist ein Link-Level-Protokoll, das zum Auflösen von IP-Adressen in MAC verwendet wird Adressen. IEEE 802.1x-Frame-In Die Anzahl der Ethernet-Frames (Pakete), die vom Gerät empfangen wurden und durch den portbasierten Netzwerkzugriff definiert wurden Steuerung (PNAC). IEEE 802.1x bietet einen Authentifizierungsmechanismus für Geräte, die an ein LAN oder WLAN anschließen. IPv4-Frames Ein Die Anzahl der Ethernet-Frames (Pakete) empfangen von dem Gerät, das ein Internetprotokoll Version 4 (IPv4) enthielt Datagramm IPv6-Frames Ein Die Anzahl der Ethernet-Frames (Pakete) vom Gerät empfangen, das ein Internetprotokoll Version 6 (IPv6) enthielt Datagramm IPX-Frames Ein Die Anzahl der Ethernet-Frames (Pakete) empfangen von dem Gerät, das einen Internetwork Packet Exchange (IPX) enthielt Datagramm. IPX ist ein Netzwerkprotokoll, das Netzwerke miteinander verbindet, die Novell verwenden. NetWare-Clients und -Server LACP Frames In Die Anzahl der Ethernet-Frames (Pakete) empfangen von dem Gerät, das ein Link Aggregation Control Protocol (LACP) enthielt Datagramm. LACP steuert die Bündelung mehrerer physischer Ports zu einem einzigen logischer Kanal. MPLS-Frames Ein Die Anzahl der Ethernet-Frames (Pakete) empfangen von dem Gerät, das ein Multiprotocol Label Switching (MPLS) enthielt Datagramm. MPLS ist eine Paketweiterleitungstechnologie, die Labels verwendet, um Daten zu erstellen Weiterleitung von Entscheidungen. Es wird häufig verwendet, um das folgende Netzwerk zu aktivieren Dienste: Virtual Private Networking (VPN), Traffic Engineering (TE) und Quality of Dienst (QoS) Andere Rahmen in Die Anzahl der Ethernet-Frames (Pakete) vom Gerät empfangen, das ein nicht spezifiziertes Datagramm enthielt STP Frames In Die Anzahl der Ethernet-Frames, die empfangen wurden von das Gerät, das ein Spanning Tree Protocol (STP) -Datagramm enthielt. STP erstellt eine spannt einen Baum innerhalb eines Netzwerk verbundener L2-Brücken und deaktiviert Verbindungen, die nicht Teil des Spannbaums, sodass ein einziger aktiver Pfad zwischen zwei beliebigen Netzwerk übrig bleibt Knoten. - Rahmentypen raus
- In der Tabelle ist nach Typ aufgeführt, wie viele Pakete das Gerät gesendet hat.
Metrisch Beschreibung ARP-Frame-Out Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das ein ARP-Datagramm (Address Resolution Protocol) enthielt. HARFE ist ein Link-Level-Protokoll, das zum Auflösen von IP-Adressen in MAC verwendet wird Adressen. IEEE 802.1x-Frame-Out Die Anzahl der Ethernet-Frames (Pakete), die vom Gerät gesendet wurden und durch die portbasierte Netzwerkzugriffskontrolle definiert wurden (PNAC). IEEE 802.1x bietet einen Authentifizierungsmechanismus für Geräte, die eine Verbindung zu einem LAN oder WLAN. IPv4-Frame-Out Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das ein Internetprotokoll Version 4 (IPv4) enthielt Datagramm IPv6-Frame-Out Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das ein Internetprotokoll Version 6 (IPv6) enthielt Datagramm IPX-Frame-Ausgang Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das ein IPX-Datagramm (Internetwork Packet Exchange) enthielt. IPX ist ein Netzwerkprotokoll, das Netzwerke miteinander verbindet, die Novell NetWare verwenden. Clients und Server. LACP Frames Out Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das ein Link Aggregation Control Protocol (LACP) enthielt Datagramm. LACP steuert die Bündelung mehrerer physischer Ports zu einem einzigen logischer Kanal. MPLS-Frame-Ausgang Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das ein MPLS-Datagramm (Multiprotocol Label Switching) enthielt. MPLS ist eine Paketweiterleitungstechnologie, die Labels für die Datenweiterleitung verwendet Entscheidungen. Es wird häufig verwendet, um die folgenden Netzwerkdienste zu aktivieren: Virtuell Private Netzwerke (VPN), Verkehrstechnik (TE) und Servicequalität (QoS). Andere Frames Out Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das ein nicht spezifiziertes Datagramm enthielt STP-Frame-Out Die Anzahl der Ethernet-Frames, die vom Gerät, das ein Spanning Tree Protocol (STP) -Datagramm enthielt. STP erstellt eine spannt einen Baum innerhalb eines Netzwerk verbundener L2-Brücken und deaktiviert Verbindungen, die nicht Teil des Spannbaums, sodass ein einziger aktiver Pfad zwischen zwei beliebigen Netzwerk übrig bleibt Knoten. - Mit VLAN markierte Frames In
-
Metrisch Beschreibung Multicast-Gruppen Die Anzahl der Ethernet-Frames, die vom Gerät, die mit einem VLAN-Tag versehen wurden. VLAN-Tagging gruppiert Netzwerkressourcen logisch zu verbessern Sie die Netzwerkleistung, Sicherheit und einfache Verwaltung. - Mit VLAN markierte Frames Out
-
Metrisch Beschreibung Multicast-Gruppen Die Anzahl der Ethernet-Frames, die vom Gerät, die mit einem VLAN-Tag versehen wurden. VLAN-Tagging gruppiert Netzwerkressourcen logisch zu verbessern Sie die Netzwerkleistung, Sicherheit und einfache Verwaltung.
IP-Protokolle
- Wichtigste IP-Protokolle — eingehende Pakete
- In dieser Tabelle wird aufgeschlüsselt, wie viele Pakete das Gerät per Protokoll empfangen hat.
Metrisch Beschreibung Eingehende Pakete Die Anzahl der eingehenden Pakete, die von der Gerät. - Wichtigste IP-Protokolle — Ausgehende Pakete
- In dieser Tabelle ist aufgeführt, wie viele Pakete das Gerät per Protokoll gesendet hat.
Metrisch Beschreibung Ausgehende Pakete Die Anzahl der ausgehenden Pakete, die von der Gerät.
ICMP-Typen
Dieser Region wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
- Die ICMP ICMP-Typen — eingehende Pakete
- In dieser Tabelle ist nach ICMP-Typ aufgeführt, wie viele Pakete das Gerät empfangen hat.
Metrisch Beschreibung Eingehende Pakete Die Anzahl der eingehenden Pakete, die von der Gerät. - Die ICMP ICMP-Typen — Ausgehende Pakete
- In dieser Tabelle ist nach ICMP-Typ aufgeführt, wie viele Pakete das Gerät gesendet hat.
Metrisch Beschreibung Ausgehende Pakete Die Anzahl der ausgehenden Pakete, die von der Gerät.
Wo soll ich als Nächstes suchen?
Analysieren Sie eine Metrik: Sie können weitere Informationen zu einer Metrik abrufen, indem Sie auf den Metrikwert oder -namen klicken und eine Option aus dem Menü Drilldown by auswählen. Wenn Sie sich beispielsweise die Gesamtzahl der Fehler ansehen, klicken Sie auf die Zahl und wählen Sie Server um zu sehen, welche Server die Fehler zurückgegeben haben.
Den Metric Explorer durchsuchen: Integrierte Protokollseiten enthalten die am häufigsten referenzierten Metriken für ein Protokoll, aber Sie können zusätzliche Metriken im Metric Explorer sehen. Klicken Sie auf einer Protokollseite auf einen beliebigen Diagrammtitel und wählen Sie Diagramm erstellen aus.... Wenn der Metric Explorer geöffnet wird, klicken Sie auf Metrik hinzufügen im linken Bereich, um eine Drop-down-Liste mit umfassenden Messwerten für das Gerät anzuzeigen. Wenn Sie eine interessante Metrik finden, klicken Sie Zum Dashboard hinzufügen um die Metrik zu einem neuen oder vorhandenen Dashboard hinzuzufügen.
Erstellen Sie eine benutzerdefinierte Metrik: Wenn Sie eine Metrik anzeigen möchten, die nicht im Metric Explorer enthalten ist, können Sie über einen Auslöser eine benutzerdefinierte Metrik erstellen. Weitere Informationen finden Sie in den folgenden Ressourcen:
TCP-Geräteseite
TCP-Zusammenfassung
- Verbindungen
- Zeigt an, wann das Gerät Verbindungen akzeptiert und initiiert hat.
Akzeptiert Die Anzahl der eingehenden TCP-Verbindungen, die von einem akzeptiert werden Gerät während des ausgewählten Zeitintervalls. Verbunden Die Anzahl der ausgehenden TCP-Verbindungen, die initiiert wurden von ein Gerät während des ausgewählten Zeitintervalls. Extern akzeptiert Die Anzahl der eingehenden TCP-Verbindungen von einer externen IP-Adresse von einem Gerät während des ausgewählten Zeitintervalls akzeptiert. Standardmäßig wird eine IP-Adresse, die nicht nach RFC1918 stammt, als extern betrachtet. IP-Adressen kann auf der Seite Netzwerkorte im System als intern oder extern angegeben werden Einstellungen oder über die REST-API-Ressource Network Locality Entry Extern verbunden Die Anzahl der ausgehenden TCP-Verbindungen von einem Gerät während des ausgewählten Zeitintervalls an eine externe IP-Adresse initiiert. Standardmäßig wird eine IP-Adresse, die nicht nach RFC1918 stammt, als extern betrachtet. IP-Adressen kann auf der Seite Netzwerkorte im System als intern oder extern angegeben werden Einstellungen oder über die REST-API-Ressource Network Locality Entry geschlossen Die Anzahl der Verbindungen, die explizit vom Gerät oder sein Peer. Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Abgebrochene Verbindungen in Die Häufigkeit, mit der ein Gerät unerwartet erhielt einen Reset (RST) anstelle eines Finishs (FIN), um einen etablierten Verbindung. Diese Zahl beinhaltet nicht unsaubere Shutdowns, also wenn ein Gerät reagiert absichtlich auf eine FIN mit einem RST, um die Verbindung zu schließen Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Abgebrochene Verbindungen ausgehen Die Häufigkeit, mit der ein Gerät unerwartet hat einen Reset (RST) anstelle eines Finishs (FIN) gesendet, um einen etablierten Verbindung. Diese Zahl beinhaltet nicht unsaubere Shutdowns, also wenn ein Gerät reagiert absichtlich auf eine FIN mit einem RST, um die Verbindung zu schließen Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
- Verbindungen insgesamt
- Zeigt die Anzahl der akzeptierten Verbindungen und die Anzahl der vom
Gerät initiierten Verbindungen an. Akzeptierte Verbindungen und verbundene Verbindungen sind nicht identisch.
Beispielsweise wird ein Server im Allgemeinen weit mehr akzeptiert als verbunden haben, da
Webserver selten Verbindungen mit anderen Geräten initiieren.
Akzeptiert Die Anzahl der eingehenden TCP-Verbindungen, die von einem akzeptiert werden Gerät während des ausgewählten Zeitintervalls. Verbunden Die Anzahl der ausgehenden TCP-Verbindungen, die initiiert wurden von ein Gerät während des ausgewählten Zeitintervalls. Extern akzeptiert Die Anzahl der eingehenden TCP-Verbindungen von einer externen IP-Adresse von einem Gerät während des ausgewählten Zeitintervalls akzeptiert. Standardmäßig wird eine IP-Adresse, die nicht nach RFC1918 stammt, als extern betrachtet. IP-Adressen kann auf der Seite Netzwerkorte im System als intern oder extern angegeben werden Einstellungen oder über die REST-API-Ressource Network Locality Entry Extern verbunden Die Anzahl der ausgehenden TCP-Verbindungen von einem Gerät während des ausgewählten Zeitintervalls an eine externe IP-Adresse initiiert. Standardmäßig wird eine IP-Adresse, die nicht nach RFC1918 stammt, als extern betrachtet. IP-Adressen kann auf der Seite Netzwerkorte im System als intern oder extern angegeben werden Einstellungen oder über die REST-API-Ressource Network Locality Entry geschlossen Die Anzahl der Verbindungen, die explizit vom Gerät oder sein Peer. Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Abgebrochene Verbindungen in Die Häufigkeit, mit der ein Gerät unerwartet erhielt einen Reset (RST) anstelle eines Finishs (FIN), um einen etablierten Verbindung. Diese Zahl beinhaltet nicht unsaubere Shutdowns, also wenn ein Gerät reagiert absichtlich auf eine FIN mit einem RST, um die Verbindung zu schließen Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Abgebrochene Verbindungen ausgehen Die Häufigkeit, mit der ein Gerät unerwartet hat einen Reset (RST) anstelle eines Finishs (FIN) gesendet, um einen etablierten Verbindung. Diese Zahl beinhaltet nicht unsaubere Shutdowns, also wenn ein Gerät reagiert absichtlich auf eine FIN mit einem RST, um die Verbindung zu schließen Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
TCP-Leistung
Dieser Region wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.- Zeit für Hin- und Rückfahrt
-
Zeit für Hin- und Rückfahrt Die Zeit, die zwischen dem Senden eines Paket durch ein Gerät verstrichen ist und Empfangen einer Bestätigung (ACK). Die Round Trip Time (RTT) ist ein Maß für Netzwerklatenz. - Zeit für den Verbindungsaufbau
-
TCP-Einrichtungszeit Die Zeit zwischen der Erkennung des erstes und letztes Paket eines TCP-3-Wege-Handshakes
TCP-Datenübertragung
Dieser Region wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.- Übertragene Daten
-
Eingeschlossene Byte Die Anzahl der übergebenen Goodput-Bytes für Gerät. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Ausgehende Bytes Die Anzahl der ausübertragenen Goodput-Bytes für Gerät. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Ausgehende Byte für die erneute Übertragung Die Anzahl der Bytes, die von der erneut gesendet wurden Gerät. - Erneut übertragene Pakete
-
Ausgehende Neuübertragungen Die Häufigkeit, mit der Daten erneut von der gesendet wurden Gerät. - Netzwerküberlastung
-
RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. - Vorübergehende Reaktionslosigkeit
-
Der TCP-Fluss gerät ins Stocken Die Häufigkeit, mit der ein TCP-Fluss ins Stocken geraten ist so, dass dieses Gerät nicht mehr zu reagieren schien. Im ExtraHop-System ein TCP Flow Stall In gibt an, dass drei aufeinanderfolgende Retransmission-Timeouts (RTOs) trat auf, als Peer-Geräte Daten an dieses Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen.
TCP-Flusskontrolle und Überlastung
- Netzwerküberlastung
- Dieses Diagramm wird nicht angezeigt, wenn sich das Gerät im Modus Flow Analysis befindet.
RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. - Netzwerküberlastung
- Dieses Diagramm wird nicht angezeigt, wenn sich das Gerät im Modus Flow Analysis befindet.
RTOs Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. RTOs raus Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. - Stände veranstalten
- Dieses Diagramm wird nicht angezeigt, wenn sich das Gerät im Modus Flow Analysis befindet.
Kein Fenster rein Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Empfangsfenster drosselt ein Die Häufigkeit, mit der das Empfangsfenster angezeigt wird wurde von einem Peer-Gerät empfangen, beschränkte den TCP-Verbindungsdurchsatz, um den Datenfluss. Eine Drosselung tritt auf, wenn ein Peer-Gerätepuffer zum Empfangen von Daten voll werden. In einigen Fällen kann die Größe des Lesesocket-Puffers erhöht werden oder Die Skalierung des Empfangsfensters kann auf dem Peer-Gerät aktiviert werden, um dieses Problem zu beheben Problem. Drosselungen des Empfangsfensters Die Häufigkeit, mit der das Empfangsfenster angezeigt wird, was vom Gerät gesendet wurde, begrenzte den Durchsatz der TCP-Verbindung, um den Datenfluss zu verlangsamen von Daten. Eine Drosselung tritt auf, wenn ein Gerätepuffer für den Empfang von Daten voll ist. In In einigen Fällen kann die Größe des Lese-Socket-Puffers erhöht oder das Empfangsfenster skaliert werden kann auf dem Gerät aktiviert werden, um dieses Problem zu beheben. - Stände veranstalten
- Dieses Diagramm wird nicht angezeigt, wenn sich das Gerät im Modus Flow Analysis befindet.
Kein Fenster rein Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Empfangsfenster drosselt ein Die Häufigkeit, mit der das Empfangsfenster angezeigt wird wurde von einem Peer-Gerät empfangen, beschränkte den TCP-Verbindungsdurchsatz, um den Datenfluss. Eine Drosselung tritt auf, wenn ein Peer-Gerätepuffer zum Empfangen von Daten voll werden. In einigen Fällen kann die Größe des Lesesocket-Puffers erhöht werden oder Die Skalierung des Empfangsfensters kann auf dem Peer-Gerät aktiviert werden, um dieses Problem zu beheben Problem. Drosselungen des Empfangsfensters Die Häufigkeit, mit der das Empfangsfenster angezeigt wird, was vom Gerät gesendet wurde, begrenzte den Durchsatz der TCP-Verbindung, um den Datenfluss zu verlangsamen von Daten. Eine Drosselung tritt auf, wenn ein Gerätepuffer für den Empfang von Daten voll ist. In In einigen Fällen kann die Größe des Lese-Socket-Puffers erhöht oder das Empfangsfenster skaliert werden kann auf dem Gerät aktiviert werden, um dieses Problem zu beheben. - Verbindung Health In
-
Erhaltene Syns Die Anzahl der vom Gerät empfangenen SYNs. EIN Das Synchronisationspaket (SYN) ist das erste Paket, das über ein TCP gesendet wird Verbindung. Akzeptiert Die Anzahl der eingehenden TCP-Verbindungen, die von einem akzeptiert werden Gerät während des ausgewählten Zeitintervalls. - Verbindung Health In
-
Erhaltene Syns Die Anzahl der vom Gerät empfangenen SYNs. EIN Das Synchronisationspaket (SYN) ist das erste Paket, das über ein TCP gesendet wird Verbindung. Akzeptiert Die Anzahl der eingehenden TCP-Verbindungen, die von einem akzeptiert werden Gerät während des ausgewählten Zeitintervalls. - Verbindung unterbrochen
-
SYNs gesendet Die Anzahl der SYNs, die vom Gerät gesendet wurden, um eine Verbindung. Ein Synchronisationspaket (SYN) ist das erste Paket, das über ein TCP gesendet wird Verbindung. Verbunden Die Anzahl der ausgehenden TCP-Verbindungen, die initiiert wurden von ein Gerät während des ausgewählten Zeitintervalls. - Verbindung unterbrochen
-
SYNs gesendet Die Anzahl der SYNs, die vom Gerät gesendet wurden, um eine Verbindung. Ein Synchronisationspaket (SYN) ist das erste Paket, das über ein TCP gesendet wird Verbindung. Verbunden Die Anzahl der ausgehenden TCP-Verbindungen, die initiiert wurden von ein Gerät während des ausgewählten Zeitintervalls. - Staukontrolle
- Dieses Diagramm wird nicht angezeigt, wenn sich das Gerät im Modus Flow Analysis befindet.
Schlechte Staukontrolle in Die Anzahl der Episoden, in denen sich ein Peer-Gerät befand zu viele Daten an das Gerät senden, was zu einer Netzwerküberlastung und einem Datenverlust führt Pakete. Schlechte Überlastungskontrolle raus Die Anzahl der Episoden, in denen sich das Gerät befand zu viele Daten an ein Peer-Gerät senden, was zu einer Netzwerküberlastung und einem Datenverlust führt Pakete. - Staukontrolle
- Dieses Diagramm wird nicht angezeigt, wenn sich das Gerät im Modus Flow Analysis befindet.
Schlechte Staukontrolle in Die Anzahl der Episoden, in denen sich ein Peer-Gerät befand zu viele Daten an das Gerät senden, was zu einer Netzwerküberlastung und einem Datenverlust führt Pakete. Schlechte Überlastungskontrolle raus Die Anzahl der Episoden, in denen sich das Gerät befand zu viele Daten an ein Peer-Gerät senden, was zu einer Netzwerküberlastung und einem Datenverlust führt Pakete. - Fensterdrosselung senden
- Dieses Diagramm wird nicht angezeigt, wenn sich das Gerät im Modus Flow Analysis befindet.
Fensterdrosseln einsenden Die Häufigkeit, mit der das Gerät zu sein schien kann Daten vom Absender mit einer höheren Rate empfangen, aber das Peer-Gerät schien durch das Sendefenster eingeschränkt zu sein. Fensterdrosselungen versenden Die Häufigkeit, mit der ein Peer-Gerät schien in der Lage zu sein, Daten vom Absender mit einer höheren Rate zu empfangen, aber der Das Gerät schien durch sein Sendefenster eingeschränkt zu sein. - Fensterdrosselung senden
- Dieses Diagramm wird nicht angezeigt, wenn sich das Gerät im Modus Flow Analysis befindet.
Fensterdrosseln einsenden Die Häufigkeit, mit der das Gerät zu sein schien kann Daten vom Absender mit einer höheren Rate empfangen, aber das Peer-Gerät schien durch das Sendefenster eingeschränkt zu sein. Fensterdrosselungen versenden Die Häufigkeit, mit der ein Peer-Gerät schien in der Lage zu sein, Daten vom Absender mit einer höheren Rate zu empfangen, aber der Das Gerät schien durch sein Sendefenster eingeschränkt zu sein. - Langsame Starts
- Dieses Diagramm wird nicht angezeigt, wenn sich das Gerät im Modus Flow Analysis befindet.
Langsam fängt an Die Häufigkeit, mit der die Geräte den TCP-Slowstart eingegeben haben Vermeidung von Staus, Reduzierung des Verbindungsdurchsatzes - Langsame Starts
- Dieses Diagramm wird nicht angezeigt, wenn sich das Gerät im Modus Flow Analysis befindet.
Langsam fängt an Die Häufigkeit, mit der die Geräte den TCP-Slowstart eingegeben haben Vermeidung von Staus, Reduzierung des Verbindungsdurchsatzes
Effiziente TCP-Netzwerknutzung
Dieser Region wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.- Tinygramme
-
Tinygrams raus Die Anzahl der vom Gerät gesendeten Tinygrams. Tinygrams treten auf, wenn TCP-Nutzlasten ineffizient segmentiert werden, was zu einem höheren als die erforderliche Anzahl von Paketen im Netzwerk. - Tinygramme insgesamt
-
Tinygrams raus Die Anzahl der vom Gerät gesendeten Tinygrams. Tinygrams treten auf, wenn TCP-Nutzlasten ineffizient segmentiert werden, was zu einem höheren als die erforderliche Anzahl von Paketen im Netzwerk. - Nagle-Verzögerungen — Tinygramm-Vermeidung
-
Nagle verzögert durch das L7-Protokoll Die Anzahl der Verzögerungen bei Nagle, die durch den aktuellen Gerät, das auf eine schlechte Interaktion zwischen dem Nagle-Algorithmus und verzögert hinweist Bestätigungen (ACKs - Nagle-Verzögerungen insgesamt
-
Nagle verzögert durch das L7-Protokoll Die Anzahl der Verzögerungen bei Nagle, die durch den aktuellen Gerät, das auf eine schlechte Interaktion zwischen dem Nagle-Algorithmus und verzögert hinweist Bestätigungen (ACKs
Bemerkenswerte TCP-Bedingungen
Dieser Region wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.- Nicht in Ordnung befindliche Segmente
-
Ausgehende Pakete, die nicht in der richtigen Reihenfolge sind Anzahl der Pakete, die von dem Gerät gesendet wurden, auf dem Die TCP-Sequenznummer stimmte nicht mit der Sequenznummer des ExtraHop-Systems überein erwartend. Die Neuordnung wurde möglicherweise am Gerät selbst oder durch einen Zwischengerät. Dies kann zu einem verringerten Verbindungsdurchsatz führen, der erhöht wird Verarbeitungslast auf dem Peer-Gerät und zusätzliche ACK-Pakete im Netzwerk. - Gesamtzahl der nicht in Ordnung befindlichen Segmente
-
Ausgehende Pakete, die nicht in der richtigen Reihenfolge sind Anzahl der Pakete, die von dem Gerät gesendet wurden, auf dem Die TCP-Sequenznummer stimmte nicht mit der Sequenznummer des ExtraHop-Systems überein erwartend. Die Neuordnung wurde möglicherweise am Gerät selbst oder durch einen Zwischengerät. Dies kann zu einem verringerten Verbindungsdurchsatz führen, der erhöht wird Verarbeitungslast auf dem Peer-Gerät und zusätzliche ACK-Pakete im Netzwerk. - Verbindungen, die keine selektiven Bestätigungen (SACK) verwenden
-
SYNs ohne SACK-Ausgang Die Anzahl der SYNs, die von dem Gerät gesendet wurden, das dies getan hat Die TCP-SackOk-Option ist nicht gesetzt. Ein Synchronisationspaket (SYN) ist das erste gesendete Paket über eine TCP-Verbindung. Selective Acknowledgment (SACK) ermöglicht es dem Empfänger bestätigt diskontinuierliche Blöcke von Paketen, die korrekt empfangen wurden SYNs ohne SACK In Die Anzahl der SYNs, die das Gerät empfangen hat Die TCP-SackOk-Option ist nicht gesetzt. Ein Synchronisationspaket (SYN) ist das erste gesendete Paket über eine TCP-Verbindung. Selective Acknowledgment (SACK) ermöglicht es dem Empfänger diskontinuierliche Blöcke von Paketen bestätigen, die empfangen wurden richtig. - Insgesamt wird SACK nicht verwendet
-
SYNs ohne SACK-Ausgang Die Anzahl der SYNs, die von dem Gerät gesendet wurden, das dies getan hat Die TCP-SackOk-Option ist nicht gesetzt. Ein Synchronisationspaket (SYN) ist das erste gesendete Paket über eine TCP-Verbindung. Selective Acknowledgment (SACK) ermöglicht es dem Empfänger bestätigt diskontinuierliche Blöcke von Paketen, die korrekt empfangen wurden SYNs ohne SACK In Die Anzahl der SYNs, die das Gerät empfangen hat Die TCP-SackOk-Option ist nicht gesetzt. Ein Synchronisationspaket (SYN) ist das erste gesendete Paket über eine TCP-Verbindung. Selective Acknowledgment (SACK) ermöglicht es dem Empfänger diskontinuierliche Blöcke von Paketen bestätigen, die empfangen wurden richtig. - Segmente gelöscht oder erneut gesendet
-
Ausgefallene Segmente Die Anzahl der Folgen, in denen ein Segment oder ein Eine Reihe von Segmenten ging auf dem Weg vom aktuellen Gerät verloren und wurde benötigt Weiterübertragung Eingelassene Segmente Die Anzahl der Folgen, in denen ein Segment oder eine Serie der Segmente gingen auf dem Weg zum aktuellen Gerät verloren und wurden benötigt Weiterübertragung Ausgehende Neuübertragungen Die Häufigkeit, mit der Daten erneut von der gesendet wurden Gerät. - Segmente gelöscht oder erneut gesendet
-
Ausgefallene Segmente Die Anzahl der Folgen, in denen ein Segment oder ein Eine Reihe von Segmenten ging auf dem Weg vom aktuellen Gerät verloren und wurde benötigt Weiterübertragung Eingelassene Segmente Die Anzahl der Folgen, in denen ein Segment oder eine Serie der Segmente gingen auf dem Weg zum aktuellen Gerät verloren und wurden benötigt Weiterübertragung Ausgehende Neuübertragungen Die Häufigkeit, mit der Daten erneut von der gesendet wurden Gerät.
Gesamtwerte der TCP-Metriken
- TCP-Verbindungen
-
Akzeptiert Die Anzahl der eingehenden TCP-Verbindungen, die von einem akzeptiert werden Gerät während des ausgewählten Zeitintervalls. Verbunden Die Anzahl der ausgehenden TCP-Verbindungen, die initiiert wurden von ein Gerät während des ausgewählten Zeitintervalls. Extern akzeptiert Die Anzahl der eingehenden TCP-Verbindungen von einer externen IP-Adresse von einem Gerät während des ausgewählten Zeitintervalls akzeptiert. Standardmäßig wird eine IP-Adresse, die nicht nach RFC1918 stammt, als extern betrachtet. IP-Adressen kann auf der Seite Netzwerkorte im System als intern oder extern angegeben werden Einstellungen oder über die REST-API-Ressource Network Locality Entry Extern verbunden Die Anzahl der ausgehenden TCP-Verbindungen von einem Gerät während des ausgewählten Zeitintervalls an eine externe IP-Adresse initiiert. Standardmäßig wird eine IP-Adresse, die nicht nach RFC1918 stammt, als extern betrachtet. IP-Adressen kann auf der Seite Netzwerkorte im System als intern oder extern angegeben werden Einstellungen oder über die REST-API-Ressource Network Locality Entry geschlossen Die Anzahl der Verbindungen, die explizit vom Gerät oder sein Peer. Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Etabliert Die Gesamtzahl der offenen TCP-Verbindungen zwischen Geräte während des ausgewählten Zeitintervalls. Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Gegründet Max Die größte Anzahl offener TCP-Verbindungen zwischen Geräten während des ausgewählten Zeitintervalls. Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Abgelaufen Die Anzahl der mit diesem Gerät verknüpften Verbindungen für die das Tracking aufgrund von Inaktivität eingestellt wurde. Für die meisten Protokolle ist der Zeitbereich für Inaktivität liegt sie zwischen 16 und 60 Sekunden. Für Protokolle, die verknüpft sind mit Bei Sitzungen mit langer Laufzeit, wie ICA, kann der Bereich bis zu 10 Minuten betragen. Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
- TCP-Eingang
-
Abgebrochene Verbindungen in Die Häufigkeit, mit der ein Gerät unerwartet erhielt einen Reset (RST) anstelle eines Finishs (FIN), um einen etablierten Verbindung. Diese Zahl beinhaltet nicht unsaubere Shutdowns, also wenn ein Gerät reagiert absichtlich auf eine FIN mit einem RST, um die Verbindung zu schließen Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Setzt ein Die Anzahl der vom Gerät empfangenen Resets (RSTs) bevor die Verbindung geschlossen wird. Eine hohe Anzahl von RSTs kann normal sein. Ein Anstieg RSTs sollten untersucht werden Empfangene SYNs Die Anzahl der vom Gerät empfangenen SYNs. EIN Das Synchronisationspaket (SYN) ist das erste Paket, das über ein TCP gesendet wird Verbindung. Nicht etablierte SYN-ACKs wurden empfangen Die Anzahl der SYN-Bestätigungen (SYN-Acks) von einem Gerät empfangen, das nicht zu einem etablierten TCP geführt hat Verbindung. Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Unbeantwortete SYNs Ein Die Anzahl der empfangenen erneut übertragenen SYNs von einem Gerät, das nicht reagiert, beim Versuch, eine Verbindung herzustellen Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Verstreute Segmente rein Die Anzahl der unerwarteten TCP-Pakete, die vom Gerät. Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Eingelassene Segmente Die Anzahl der Folgen, in denen ein Segment oder eine Serie der Segmente gingen auf dem Weg zum aktuellen Gerät verloren und wurden benötigt Weiterübertragung Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Timeouts für die erneute Übertragung (RTOs) Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Empfangsfenster drosselt ein Die Häufigkeit, mit der das Empfangsfenster angezeigt wird wurde von einem Peer-Gerät empfangen, beschränkte den TCP-Verbindungsdurchsatz, um den Datenfluss. Eine Drosselung tritt auf, wenn ein Peer-Gerätepuffer zum Empfangen von Daten voll werden. In einigen Fällen kann die Größe des Lesesocket-Puffers erhöht werden oder Die Skalierung des Empfangsfensters kann auf dem Peer-Gerät aktiviert werden, um dieses Problem zu beheben Problem. Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Fensterdrosseln einsenden Die Häufigkeit, mit der das Gerät zu sein schien kann Daten vom Absender mit einer höheren Rate empfangen, aber das Peer-Gerät schien durch das Sendefenster eingeschränkt zu sein. Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
SYNs ohne eingegebene Zeitstempel Die Anzahl der SYNs, die von dem Gerät empfangen wurden, das hatte keine TCP-Zeitstempeloption gesetzt. Ein Synchronisationspaket (SYN) ist das erste Paket, das über eine TCP-Verbindung gesendet wurde. Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
SYNs ohne SACK In Die Anzahl der SYNs, die das Gerät empfangen hat Die TCP-SackOk-Option ist nicht gesetzt. Ein Synchronisationspaket (SYN) ist das erste gesendete Paket über eine TCP-Verbindung. Selective Acknowledgment (SACK) ermöglicht es dem Empfänger diskontinuierliche Blöcke von Paketen bestätigen, die empfangen wurden richtig. Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Schlechte Staukontrolle in Die Anzahl der Episoden, in denen sich ein Peer-Gerät befand zu viele Daten an das Gerät senden, was zu einer Netzwerküberlastung und einem Datenverlust führt Pakete. Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Per Paws fallengelassene SYNs Die Anzahl der unbeantworteten SYN-Pakete, die wird an ein Gerät gesendet, um eine Verbindung herzustellen. Der TCP-Schutz eines Geräts Der Mechanismus gegen Wrapped Sequence (PAWS) verwirft eingehende SYN-Pakete, wenn der SYN Die Segmentsequenznummer stimmt nicht mit dem zugehörigen Zeitstempel überein Wert. Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Der TCP-Fluss gerät ins Stocken Die Häufigkeit, mit der ein TCP-Fluss ins Stocken geraten ist so, dass dieses Gerät nicht mehr zu reagieren schien. Im ExtraHop-System ein TCP Flow Stall In gibt an, dass drei aufeinanderfolgende Retransmission-Timeouts (RTOs) trat auf, als Peer-Geräte Daten an dieses Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Kein Fenster rein Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
- TCP-Ausgang
-
Abgebrochene Verbindungen ausgehen Die Häufigkeit, mit der ein Gerät unerwartet hat einen Reset (RST) anstelle eines Finishs (FIN) gesendet, um einen etablierten Verbindung. Diese Zahl beinhaltet nicht unsaubere Shutdowns, also wenn ein Gerät reagiert absichtlich auf eine FIN mit einem RST, um die Verbindung zu schließen Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Wird zurückgesetzt Die Anzahl der Resets (RSTs), die das Gerät an gesendet hat eine Verbindung beenden. Eine hohe Anzahl von RSTs kann normal sein. Ein Anstieg der RSTs sollte untersucht. SYNs gesendet Die Anzahl der SYNs, die vom Gerät gesendet wurden, um eine Verbindung. Ein Synchronisationspaket (SYN) ist das erste Paket, das über ein TCP gesendet wird Verbindung. Unbeantwortete SYNs Out Die Anzahl der erneut übertragenen SYN-Pakete wird an ein nicht reagierendes Gerät gesendet, um eine Verbindung herzustellen Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Langsam fängt an Die Häufigkeit, mit der die Geräte den TCP-Slowstart eingegeben haben Vermeidung von Staus, Reduzierung des Verbindungsdurchsatzes Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Ausgefallene Segmente Die Anzahl der Folgen, in denen ein Segment oder ein Eine Reihe von Segmenten ging auf dem Weg vom aktuellen Gerät verloren und wurde benötigt Weiterübertragung Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Ausgang für Neuübertragungs-Timeouts (RTOs) Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl von RTOs sehen, hat das Gerät nicht schnell genug eine Bestätigung vom Server erhalten, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Drosselungen des Empfangsfensters Die Häufigkeit, mit der das Empfangsfenster angezeigt wird, was vom Gerät gesendet wurde, begrenzte den Durchsatz der TCP-Verbindung, um den Datenfluss zu verlangsamen von Daten. Eine Drosselung tritt auf, wenn ein Gerätepuffer für den Empfang von Daten voll ist. In In einigen Fällen kann die Größe des Lese-Socket-Puffers erhöht oder das Empfangsfenster skaliert werden kann auf dem Gerät aktiviert werden, um dieses Problem zu beheben. Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Fensterdrosselungen versenden Die Häufigkeit, mit der ein Peer-Gerät schien in der Lage zu sein, Daten vom Absender mit einer höheren Rate zu empfangen, aber der Das Gerät schien durch sein Sendefenster eingeschränkt zu sein. Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
SYNs ohne ausgegebene Zeitstempel Die Anzahl der SYNs, die von dem Gerät gesendet wurden, das dies getan hat Die TCP-Zeitstempeloption ist nicht gesetzt. Ein Synchronisationspaket (SYN) ist das erste Paket über eine TCP-Verbindung gesendet. Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
SYNs ohne SACK-Ausgang Die Anzahl der SYNs, die von dem Gerät gesendet wurden, das dies getan hat Die TCP-SackOk-Option ist nicht gesetzt. Ein Synchronisationspaket (SYN) ist das erste gesendete Paket über eine TCP-Verbindung. Selective Acknowledgment (SACK) ermöglicht es dem Empfänger bestätigt diskontinuierliche Blöcke von Paketen, die korrekt empfangen wurden Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Schlechte Überlastungskontrolle raus Die Anzahl der Episoden, in denen sich das Gerät befand zu viele Daten an ein Peer-Gerät senden, was zu einer Netzwerküberlastung und einem Datenverlust führt Pakete. Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Ausgehende Neuübertragungen Die Häufigkeit, mit der Daten erneut von der gesendet wurden Gerät. Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Der TCP-Fluss gerät ins Stocken Die Häufigkeit, mit der ein TCP-Fluss ins Stocken geraten ist so, dass ein Peer-Gerät anscheinend nicht mehr reagierte. Im ExtraHop-System ein TCP Flow Stall Out gibt an, dass drei aufeinanderfolgende Retransmission-Timeouts (RTOs) trat auf, als dieses Gerät Daten an Peer-Geräte sendete. Ein einzelnes RTO steht für 1-5 zweite Verzögerung in Ihrem Netzwerk. Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Ausgehende Pakete, die nicht in der richtigen Reihenfolge sind Anzahl der Pakete, die von dem Gerät gesendet wurden, auf dem Die TCP-Sequenznummer stimmte nicht mit der Sequenznummer des ExtraHop-Systems überein erwartend. Die Neuordnung wurde möglicherweise am Gerät selbst oder durch einen Zwischengerät. Dies kann zu einem verringerten Verbindungsdurchsatz führen, der erhöht wird Verarbeitungslast auf dem Peer-Gerät und zusätzliche ACK-Pakete im Netzwerk. Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Tinygrams raus Die Anzahl der vom Gerät gesendeten Tinygrams. Tinygrams treten auf, wenn TCP-Nutzlasten ineffizient segmentiert werden, was zu einem höheren als die erforderliche Anzahl von Paketen im Netzwerk. Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Nagle verzögert Die Anzahl der Verzögerungen bei Nagle, die durch den aktuellen Gerät, das auf eine schlechte Interaktion zwischen dem Nagle-Algorithmus und verzögert hinweist Bestätigungen (ACKs Diese Metrik wird nicht angezeigt, wenn sich das Gerät in Flow Analysis befindet.
Wo soll ich als Nächstes suchen?
Analysieren Sie eine Metrik: Sie können weitere Informationen zu einer Metrik abrufen, indem Sie auf den Metrikwert oder -namen klicken und eine Option aus dem Menü Drilldown by auswählen. Wenn Sie sich beispielsweise die Gesamtzahl der Fehler ansehen, klicken Sie auf die Zahl und wählen Sie Server um zu sehen, welche Server die Fehler zurückgegeben haben.
Den Metric Explorer durchsuchen: Integrierte Protokollseiten enthalten die am häufigsten referenzierten Metriken für ein Protokoll, aber Sie können zusätzliche Metriken im Metric Explorer sehen. Klicken Sie auf einer Protokollseite auf einen beliebigen Diagrammtitel und wählen Sie Diagramm erstellen aus.... Wenn der Metric Explorer geöffnet wird, klicken Sie auf Metrik hinzufügen im linken Bereich, um eine Drop-down-Liste mit umfassenden Messwerten für das Gerät anzuzeigen. Wenn Sie eine interessante Metrik finden, klicken Sie Zum Dashboard hinzufügen um die Metrik zu einem neuen oder vorhandenen Dashboard hinzuzufügen.
Erstellen Sie eine benutzerdefinierte Metrik: Wenn Sie eine Metrik anzeigen möchten, die nicht im Metric Explorer enthalten ist, können Sie über einen Auslöser eine benutzerdefinierte Metrik erstellen. Weitere Informationen finden Sie in den folgenden Ressourcen:
Seite „Device Cloud Services"
Verkehr durch Cloud-Dienste
Diese Seite zeigt Ihnen, welche Cloud-Dienstanbieter Daten mit diesem Gerät ausgetauscht haben. klicken Eingehende Byte oder Ausgehende Bytes um Informationen über empfangene oder gesendete Daten einzusehen.
Die Halo-Visualisierung zeigt Verbindungen von diesem Gerät zu externen Endpunkten nach Cloud-Dienstanbietern. Externe Endpunkte erscheinen auf dem äußeren Ring und sind mit diesem Gerät verbunden, das als Kreis in der Mitte der Visualisierung erscheint. Innere Kreise und äußere Ringe nehmen mit zunehmendem Verkehrsaufkommen an Größe zu.
- Bewegen Sie den Mauszeiger über Endpunkte oder Verbindungen, um die verfügbaren Hostnamen und IP-Adressen anzuzeigen.
- Klicken Sie auf Endpunkte oder Verbindungen, um den Fokus zu behalten und Informationen für Ihre Auswahl im Informationsfenster auf der rechten Seite anzuzeigen.
Die Tabelle im Informationsfeld zeigt Ihnen die Bitrate und wann dieses Gerät Daten gesendet oder empfangen hat, aufgeschlüsselt nach den fünf wichtigsten Cloud-Dienstanbietern.
Die Liste im Informationsfeld zeigt Ihnen die Menge der von diesem Gerät gesendeten oder empfangenen Daten, aufgeschlüsselt nach Cloud-Dienstanbietern.
Seite „Geräte-Geolokalisierung"
Verkehr nach Geolokalisierung
Diese Seite zeigt Ihnen, welche geografischen Standorte Daten mit diesem Gerät ausgetauscht haben. klicken Eingehende Byte oder Ausgehende Bytes um Informationen über empfangene oder gesendete Daten einzusehen.
Die Halo-Visualisierung zeigt Verbindungen von diesem Gerät zu externen Endpunkten anhand der Geolokalisierung. Externe Endpunkte erscheinen auf dem äußeren Ring und sind mit diesem Gerät verbunden, das als Kreis in der Mitte der Visualisierung erscheint. Innere Kreise und äußere Ringe nehmen mit zunehmendem Verkehrsaufkommen an Größe zu.
- Bewegen Sie den Mauszeiger über Endpunkte oder Verbindungen, um die verfügbaren Hostnamen und IP-Adressen anzuzeigen.
- Klicken Sie auf Endpunkte oder Verbindungen, um den Fokus zu behalten und Informationen für Ihre Auswahl im Informationsfenster auf der rechten Seite anzuzeigen.
Die Liste im Informationsfeld zeigt Ihnen die Menge der von diesem Gerät gesendeten oder empfangenen Daten, aufgeschlüsselt nach Geolokalisierung.
Seite „Große Uploads auf Geräten"
Große Uploads
Diese Seite zeigt Ihnen, welche externen Endpunkte in einer einzigen Übertragung von diesem Gerät mehr als 1 MB an Daten empfangen haben.
Die Halo-Visualisierung zeigt Verbindungen von diesem Gerät zu externen Endpunkten. Externe Endpunkte erscheinen auf dem äußeren Ring und sind mit diesem Gerät verbunden, das als Kreis in der Mitte der Visualisierung erscheint. Innere Kreise und äußere Ringe nehmen mit zunehmendem Verkehrsaufkommen an Größe zu.
- Bewegen Sie den Mauszeiger über Endpunkte oder Verbindungen, um die verfügbaren Hostnamen und IP-Adressen anzuzeigen.
- Klicken Sie auf Endpunkte oder Verbindungen, um den Fokus zu behalten und Informationen für Ihre Auswahl im Informationsfenster auf der rechten Seite anzuzeigen.
Die Tabelle im Informationsfeld zeigt Ihnen die Bitrate und wann dieses Gerät Daten gesendet hat, aufgeschlüsselt nach den fünf wichtigsten externen Endpunkten.
Die Liste im Informationsfeld zeigt Ihnen die Menge der von diesem Gerät gesendeten oder empfangenen Daten, aufgeteilt auf den Externer Endpunkt.
AWS-Seite für Geräte
AWS — Eingehender Datenverkehr zum Gerät
- Durchsatz
- Dieses Diagramm zeigt Ihnen die Bitrate des Datenverkehrs von allen AWS-Cloud-Services
zum Gerät.
Metrisch Beschreibung AWS-Kunde — Eingehende AWS-Bytes Die Anzahl der eingehenden Byte von AWS. Das Metrik zählt die Größe der gesamten Paketnutzlast - Verkehr
- Dieses Diagramm zeigt Ihnen, wie viele Daten das Gerät von allen
AWS-Cloud-Services empfangen hat.
Metrisch Beschreibung AWS-Kunde — Eingehende AWS-Bytes Die Anzahl der eingehenden Byte von AWS. Das Metrik zählt die Größe der gesamten Paketnutzlast - Die besten Dienstleistungen
- Dieses Diagramm zeigt die Bitrate und den Zeitpunkt, zu dem das Gerät Daten empfangen hat,
aufgeschlüsselt nach den fünf wichtigsten AWS-Cloud-Services.
Metrisch Beschreibung Cloud-Dienste — Byte-Zugänge nach Dienst Die Anzahl der eingehenden Byte von Cloud-Dienste, aufgelistet vom Cloud-Dienstanbieter. Diese Metrik zählt die Größe von die gesamte Paketnutzlast - Die besten Dienstleistungen
- Dieses Diagramm zeigt Ihnen, wie viele Daten das Gerät empfangen hat, aufgeschlüsselt nach den fünf
wichtigsten AWS-Cloud-Services.
Metrisch Beschreibung Cloud-Dienste — Byte-Zugänge nach Dienst Die Anzahl der eingehenden Byte von Cloud-Dienste, aufgelistet vom Cloud-Dienstanbieter. Diese Metrik zählt die Größe von die gesamte Paketnutzlast - Die besten S3-Eimer
- Diese Tabelle zeigt Ihnen, wie viele Daten das Gerät empfangen hat, aufgeschlüsselt nach den fünf
wichtigsten S3-Buckets.
Metrisch Beschreibung AWS-Client — Per S3-Bucket eingehende S3-Bytes Die Anzahl der empfangenen Byte von Amazon S3 (Simple Storage Service), aufgelistet nach S3-Bucket. Diese Metrik zählt Verkehr zwischen dem Gerät und S3-Buckets. Die Zählung beinhaltet nur die Größe der verschlüsselter SSL-Datensatz.
AWS — Ausgehender Datenverkehr vom Gerät
- Durchsatz
- Dieses Diagramm zeigt Ihnen die Bitrate des Datenverkehrs des gesamten
AWS-Cloud-Service-Datenverkehrs vom Gerät.
Metrisch Beschreibung AWS-Client — Ausgehende AWS-Bytes Die Anzahl der ausgehenden Byte an AWS. Das Metrik zählt die Größe der gesamten Paketnutzlast - Verkehr
- Dieses Diagramm zeigt Ihnen, wie viele Daten von allen AWS-Cloud-Services
vom Gerät gesendet wurden.
Metrisch Beschreibung AWS-Client — Ausgehende AWS-Bytes Die Anzahl der ausgehenden Byte an AWS. Das Metrik zählt die Größe der gesamten Paketnutzlast - Die besten Dienstleistungen
- Dieses Diagramm zeigt die Bitrate und den Zeitpunkt, zu dem Daten vom Gerät gesendet wurden,
aufgeschlüsselt nach den fünf wichtigsten AWS-Cloud-Services.
Metrisch Beschreibung Cloud-Dienste — Byteausgänge nach Diensten Die Anzahl der ausgehenden Byte an Cloud-Dienste, aufgelistet vom Cloud-Dienstanbieter. Diese Metrik zählt die Größe von die gesamte Paketnutzlast - Die besten Dienstleistungen
- Dieses Diagramm zeigt Ihnen, wie viele Daten vom Gerät gesendet wurden, aufgeschlüsselt nach
den fünf wichtigsten AWS-Cloud-Services.
Metrisch Beschreibung Cloud-Dienste — Byteausgänge nach Diensten Die Anzahl der ausgehenden Byte an Cloud-Dienste, aufgelistet vom Cloud-Dienstanbieter. Diese Metrik zählt die Größe von die gesamte Paketnutzlast - Die besten S3-Eimer
- Diese Tabelle zeigt Ihnen, wie viele Daten vom Gerät gesendet wurden, aufgeschlüsselt nach
den fünf wichtigsten S3-Buckets.
Metrisch Beschreibung AWS-Client — Vom S3-Bucket ausgehende S3-Bytes Die Anzahl der Byte, die an gesendet wurden Amazon S3 (Simple Storage Service), sortiert nach S3-Bucket. Diese Metrik zählt den Traffic zwischen dem Gerät und den S3-Buckets. Die Zählung beinhaltet nur die Größe des verschlüsselten SSL-Datensatz.
Metriken für Gerätegruppen
Bei diesen Metriken geht es um Gerätegruppen, bei denen es sich um benutzerdefinierte Gruppen von Geräten handelt, die gemeinsam als Metrikquelle einem Diagramm, einer Alarm oder einem Auslöser zugewiesen werden können.
Seite „Gruppenübersicht"
Überblick über die Gruppe
- Verkehr
- Dieses Diagramm zeigt Ihnen, wie viele Daten von der Gruppe gesendet und empfangen wurden.
Metrisch Beschreibung Netzwerk — Eingehende Byte Der eingehende Datendurchsatz des Gerät. Netzwerk — Ausgehende Bytes Der ausgehende Datendurchsatz des Gerät. Netzwerk — Eingehende externe Bytes (nur ExtraHop Reveal (x)) Der eingehende Datendurchsatz eines Gerät von externen IP-Adressen. Standardmäßig wird eine Nicht-RFC1918-IP-Adresse berücksichtigt extern. IP-Adressen können jedoch als intern oder extern auf dem Seite „Netzwerkorte" in den Systemeinstellungen oder über die REST-API Network Locality Einstiegsressource. Netzwerk — Externe Byte-Ausgabe (nur ExtraHop Reveal (x)) Der ausgehende Datendurchsatz eines Gerät an externe IP-Adressen. Standardmäßig wird eine Nicht-RFC1918-IP-Adresse berücksichtigt extern. IP-Adressen können jedoch als intern oder extern auf dem Seite „Netzwerkorte" in den Systemeinstellungen oder über die REST-API Network Locality Einstiegsressource. - Durchsatz
- Dieses Diagramm zeigt Ihnen, wie viele Daten von der Gruppe gesendet und empfangen wurden, gemessen in
Bits.
Metrisch Beschreibung Netzwerk — Eingehende Byte Der eingehende Datendurchsatz des Gerät. Netzwerk — Ausgehende Bytes Der ausgehende Datendurchsatz des Gerät. - Externe Verbindungen
- Dieses Diagramm zeigt die Anzahl der Verbindungen zu und von der Gruppe. (
nur ExtraHop Reveal (x))
Metrisch Beschreibung TCP - Extern akzeptiert Die Anzahl der eingehenden TCP-Verbindungen, die von einem akzeptiert werden Gerät während des ausgewählten Zeitintervalls. TCP — Extern verbunden Die Anzahl der ausgehenden TCP-Verbindungen von einem Gerät während des ausgewählten Zeitintervalls an eine externe IP-Adresse initiiert. Standardmäßig wird eine IP-Adresse, die nicht nach RFC1918 stammt, als extern betrachtet. IP-Adressen kann auf der Seite Netzwerkorte im System als intern oder extern angegeben werden Einstellungen oder über die REST-API-Ressource Network Locality Entry TCP — Verdächtige Verbindungen Die Anzahl der ausgehenden TCP-Verbindungen zu verdächtige IP-Adressen, die von einem Gerät initiiert wurden. Diese IP-Adressen werden berücksichtigt verdächtig, basierend auf Bedrohungsinformationen, die in Ihrem Reveal (x) -System gefunden wurden. - Die besten Gruppenmitglieder
- Diese Tabelle zeigt die Gruppengeräte mit dem meisten Datenverkehr, einschließlich gesendeter und
empfangener Daten.
Metrisch Beschreibung Netzwerk — Eingehende Byte Der eingehende Datendurchsatz des Gerät. Netzwerk — Ausgehende Bytes Der ausgehende Datendurchsatz des Gerät.
Protokolle
- Die besten Protokolle in
- Dieses Diagramm zeigt Ihnen, wann Daten von der Gruppe gesendet wurden, aufgeschlüsselt nach dem L7-Protokoll.
Metrisch Beschreibung L7 - Durch das L7-Protokoll eingegangene Byte Die Anzahl der beobachteten eingehenden Byte, aufgeführt in L7 Protokoll. L7-Protokolle unterstützen die Kommunikation auf Anwendungsebene. - Herausragende Protokolle
- Dieses Diagramm zeigt Ihnen, wann Daten von der Gruppe empfangen wurden, aufgeschlüsselt nach dem
L7-Protokoll.
Metrisch Beschreibung L7 - Durch das L7-Protokoll eingegangene Byte Die Anzahl der beobachteten ausgehenden Byte, aufgeführt in L7 Protokoll. L7-Protokolle unterstützen die Kommunikation auf Anwendungsebene. - Die besten Protokolle in
- Dieses Diagramm zeigt Ihnen, wie viele Daten von der Gruppe gesendet wurden, aufgeschlüsselt nach dem
L7-Protokoll.
Metrisch Beschreibung L7 - Durch das L7-Protokoll eingegangene Byte Die Anzahl der beobachteten eingehenden Byte, aufgeführt in L7 Protokoll. L7-Protokolle unterstützen die Kommunikation auf Anwendungsebene. - Herausragende Protokolle
- Dieses Diagramm zeigt Ihnen, wie viele Daten von der Gruppe empfangen wurden, aufgeschlüsselt nach dem
L7-Protokoll.
Metrisch Beschreibung L7 - Durch das L7-Protokoll eingegangene Byte Die Anzahl der beobachteten ausgehenden Byte, aufgeführt in L7 Protokoll. L7-Protokolle unterstützen die Kommunikation auf Anwendungsebene.
Warnmeldungen
- Warnmeldungen
- Dieses Diagramm zeigt Ihnen, welche Benachrichtigungen für Geräte in der Gruppe generiert wurden.
Wo soll ich als Nächstes suchen?
Analysieren Sie eine Metrik: Sie können weitere Informationen zu einer Metrik abrufen, indem Sie auf den Metrikwert oder -namen klicken und eine Option aus dem Menü Drilldown by auswählen. Wenn Sie sich beispielsweise die Gesamtzahl der Fehler ansehen, klicken Sie auf die Zahl und wählen Sie Server um zu sehen, welche Server die Fehler zurückgegeben haben.
Den Metric Explorer durchsuchen: Integrierte Protokollseiten enthalten die am häufigsten referenzierten Metriken für ein Protokoll, aber Sie können zusätzliche Metriken im Metric Explorer sehen. Klicken Sie auf einer Protokollseite auf einen beliebigen Diagrammtitel und wählen Sie Diagramm erstellen aus.... Wenn der Metric Explorer geöffnet wird, klicken Sie auf Metrik hinzufügen im linken Bereich, um eine Drop-down-Liste mit umfassenden Messwerten für das Gerät anzuzeigen. Wenn Sie eine interessante Metrik finden, klicken Sie Zum Dashboard hinzufügen um die Metrik zu einem neuen oder vorhandenen Dashboard hinzuzufügen.
Erstellen Sie eine benutzerdefinierte Metrik: Wenn Sie eine Metrik anzeigen möchten, die nicht im Metric Explorer enthalten ist, können Sie über einen Auslöser eine benutzerdefinierte Metrik erstellen. Weitere Informationen finden Sie in den folgenden Ressourcen:
Seite „Geräte gruppieren"
Die Geräte Eine Unterseite listet die Geräte in der Gruppe auf. Sie können die Geräteliste filtern und die Zuweisungen für ein Gerät oder eine Gerätegruppe verwalten. Sie können auf ein Gerät klicken, um eine Seite mit detaillierten Messwerten für dieses Gerät zu öffnen. Um zur Geräteliste zurückzukehren, klicken Sie in Ihrem Browser auf die Schaltfläche Zurück.
Seite Gruppennetzwerk
Durchsatz
- Eingehender Durchsatz
- Diese Tabelle zeigt Ihnen die Bitrate und wann die Gerätegruppe Daten empfangen hat.
Metrisch Beschreibung Eingehende Byte Der eingehende Datendurchsatz des Gerät. - Gesamter eingehender Verkehr
- Diese Tabelle zeigt Ihnen, wie viele Daten die Gerätegruppe empfangen hat.
Metrisch Beschreibung Eingehende Byte Der eingehende Datendurchsatz des Gerät. - Ausgehender Durchsatz
- Diese Tabelle zeigt Ihnen die Bitrate und wann die Gerätegruppe Daten gesendet hat.
Metrisch Beschreibung Ausgehende Bytes Der ausgehende Datendurchsatz des Gerät. - Ausgehender Verkehr insgesamt
- Diese Tabelle zeigt Ihnen, wie viele Daten die Gerätegruppe gesendet hat.
Metrisch Beschreibung Ausgehende Bytes Der ausgehende Datendurchsatz des Gerät.
Pakete und Fragmentierung
- Eingehende Pakete
- Dieses Diagramm zeigt Ihnen die durchschnittliche Rate und wann die Gerätegruppe
Pakete empfangen hat.
Metrisch Beschreibung Eingehende Pakete Die Anzahl der eingehenden Pakete, die von der Gerät. - Gesamtzahl der eingehenden Pakete
- Diese Tabelle zeigt Ihnen, wie viele Pakete die Gerätegruppe empfangen hat.
Metrisch Beschreibung Eingehende Pakete Die Anzahl der eingehenden Pakete, die von der Gerät. - Ausgehende Pakete
- Dieses Diagramm zeigt Ihnen die durchschnittliche Rate und wann die Gerätegruppe Pakete gesendet hat.
Metrisch Beschreibung Ausgehende Pakete Die Anzahl der ausgehenden Pakete, die von der Gerät. - Gesamtzahl der ausgehenden Pakete
- Diese Tabelle zeigt Ihnen, wie viele Pakete die Gerätegruppe gesendet hat.
Metrisch Beschreibung Ausgehende Pakete Die Anzahl der ausgehenden Pakete, die von der Gerät. - Paketfragmentierung eingehend
- Dieses Diagramm zeigt Ihnen, wann die Gruppe IP-Datagramme empfangen hat, die während der
Übertragung fragmentiert wurden und erneut zusammengesetzt werden mussten. Dieses Diagramm wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis
befinden.
Metrisch Beschreibung Eingehende IP-Fragmente Die Anzahl der IP-Fragmente, die empfangen wurden von das Gerät. IP-Fragmentierung tritt auf, wenn ein IP-Datagramm größer als die aktuelle maximale Übertragungseinheit (MTU) ist. Damit das Paket gesendet werden kann, zerlegt der Absender das Datagramm in kleinere Teile, sogenannte Fragmente, von denen jedes seine eigenen Header-Informationen hat.Wenn Sie einen anhaltenden Anstieg dieser Zahl feststellen, vergewissern Sie sich, dass das Gerät Empfangen des erwarteten Datenverkehrs und dass die MTU-Einstellungen nicht zu niedrig sind - Ausgehende Paketfragmentierung
- Dieses Diagramm zeigt Ihnen, wann die Gruppe IP-Datagramme gesendet hat, die während der Übertragung fragmentiert wurden
und erneut zusammengesetzt werden mussten. Dieses Diagramm wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in
Flow Analysis befinden.
Metrisch Beschreibung Ausgehende IP-Fragmente Die Anzahl der IP-Fragmente, die von der gesendet wurden Gerät. IP-Fragmentierung tritt auf, wenn ein IP-Datagramm größer als die aktuelle maximale Übertragungseinheit (MTU) ist. Damit das Paket gesendet werden kann, zerlegt der Absender das Datagramm in kleinere Teile, sogenannte Fragmente, von denen jedes seine eigenen Header-Informationen hat.Wenn wenn Sie einen anhaltenden Anstieg dieser Zahl sehen, stellen Sie sicher, dass das Gerät erwartungsgemäß sendet Verkehr und dass die MTU-Einstellungen nicht zu niedrig sind
Pakettypen
Dieser Region wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.- Pakettypen
- In der Tabelle ist nach Pakettyp aufgeschlüsselt, wie viele Pakete die Gruppe gesendet hat.
Metrisch Beschreibung Unicast-Pakete Die Anzahl der Ethernet-Frames (Pakete), die vom Gerät als Unicast-Verkehr an das Netzwerk gesendet Multicast-Pakete Die Anzahl der Ethernet-Frames (Pakete), die vom Gerät als Multicast-Verkehr an das Netzwerk gesendet Broadcast-Pakete Die Anzahl der Ethernet-Frames (Pakete), die vom Gerät als Broadcast-Verkehr an das Netzwerk gesendet werden. - Die häufigsten Multicast-Paketgruppen
- Das Diagramm zeigt, wie viele Multicast-Pakete die Gruppe pro
Multicast-Gruppe gesendet hat.
Metrisch Beschreibung Multicast-Gruppen Die Anzahl der Ethernet-Frames (Pakete), die vom Gerät als Multicast-Verkehr an das Netzwerk gesendet
DSCP-Typen (Servicequalität)
Dieser Region wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.- Priorisierung des Datenverkehrs in
- In diesem Diagramm wird anhand des Typs Differentiated Services Code
Point (DSCP) dargestellt, wie viele Daten die Gruppe erhalten hat.
Metrisch Beschreibung Eingehende Byte Der eingehende Datendurchsatz des Gerät. - Priorisierung des Datenverkehrs aus
- In diesem Diagramm wird anhand des Typs Differentiated Services Code
Point (DSCP) dargestellt, wie viele Daten die Gruppe gesendet hat.
Metrisch Beschreibung Ausgehende Bytes Der ausgehende Datendurchsatz des Gerät.
Rahmengrößen
Dieser Region wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.- Rahmengrößen in
- In der Tabelle ist nach Größe aufgeschlüsselt, wie viele Pakete die Gruppe empfangen hat.
Metrisch Beschreibung 64-Byte-Frame-Eingabe Die Anzahl der Ethernet-Frames (Pakete) empfangen von dem Gerät, das 64 oder weniger Byte an Nutzlast enthielt 128-Byte-Frame-Eingabe Die Anzahl der Ethernet-Frames (Pakete) vom Gerät empfangen, das zwischen 65 und 128 Byte enthielt Nutzlast 256-Byte-Frame-In Die Anzahl der Ethernet-Frames (Pakete) vom Gerät empfangen, das zwischen 129 und 256 Byte von Nutzlast 512-Byte-Frame-In Die Anzahl der Ethernet-Frames (Pakete) vom Gerät empfangen, das zwischen 257 und 512 Byte enthielt Nutzlast 1024-Byte-Frame-Eingang Die Anzahl der Ethernet-Frames (Pakete) vom Gerät empfangen, die zwischen 513 und 1024 Byte enthalten 1513-Byte-Frame-In Die Anzahl der Ethernet-Frames (Pakete) vom Gerät empfangen, das zwischen 1025 und 1513 Byte von Nutzlast 1518-Byte-Frame-In Die Anzahl der Ethernet-Frames (Pakete) vom Gerät empfangen, das zwischen 1514 und 1518 Byte von Nutzlast Jumbo Frames in Die Anzahl der Ethernet-Frames (Pakete) vom Gerät empfangen, die als Jumbo-Frames gelten und zwischen 1501 und 9000 Byte Nutzlast - Rahmengrößen außerhalb
- In der Tabelle ist nach Größe aufgeschlüsselt, wie viele Pakete die Gruppe gesendet hat.
Metrisch Beschreibung 64-Byte-Frame-Ausgabe Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das 64 oder weniger Byte an Nutzlast enthielt 128-Byte-Frame-Ausgabe Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das zwischen 65 und 128 Byte Nutzlast enthielt 256-Byte-Frame-Ausgabe Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das zwischen 129 und 256 Byte Nutzlast enthielt 512-Byte-Frame-Ausgabe Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das zwischen 257 und 512 Byte Nutzlast enthielt 1024-Byte-Frame-Ausgabe Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das zwischen 513 und 1024 Byte enthielt Nutzlast 1513-Byte-Frame-Ausgabe Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das zwischen 1025 und 1513 Byte enthielt Nutzlast 1518-Byte-Frame-Ausgabe Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das zwischen 1514 und 1518 Byte enthielt Nutzlast Jumbo Frames raus Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das als Jumbo-Frames gilt und zwischen 1501 und 9000 enthält Byte an Nutzlast
Rahmentypen
Dieser Region wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.- Rahmentypen In
- In der Tabelle ist nach Typ aufgeschlüsselt, wie viele Pakete die Gruppe empfangen hat.
Metrisch Beschreibung ARP Frames In Die Anzahl der Ethernet-Frames (Pakete) empfangen von dem Gerät, das ein ARP-Datagramm (Address Resolution Protocol) enthielt. ARP ist ein Link-Level-Protokoll, das zum Auflösen von IP-Adressen in MAC verwendet wird Adressen. IEEE 802.1x-Frame-In Die Anzahl der Ethernet-Frames (Pakete), die vom Gerät empfangen wurden und durch den portbasierten Netzwerkzugriff definiert wurden Steuerung (PNAC). IEEE 802.1x bietet einen Authentifizierungsmechanismus für Geräte, die an ein LAN oder WLAN anschließen. IPv4-Frames Ein Die Anzahl der Ethernet-Frames (Pakete) empfangen von dem Gerät, das ein Internetprotokoll Version 4 (IPv4) enthielt Datagramm IPv6-Frames Ein Die Anzahl der Ethernet-Frames (Pakete) vom Gerät empfangen, das ein Internetprotokoll Version 6 (IPv6) enthielt Datagramm IPX-Frames Ein Die Anzahl der Ethernet-Frames (Pakete) empfangen von dem Gerät, das einen Internetwork Packet Exchange (IPX) enthielt Datagramm. IPX ist ein Netzwerkprotokoll, das Netzwerke miteinander verbindet, die Novell verwenden. NetWare-Clients und -Server LACP Frames In Die Anzahl der Ethernet-Frames (Pakete) empfangen von dem Gerät, das ein Link Aggregation Control Protocol (LACP) enthielt Datagramm. LACP steuert die Bündelung mehrerer physischer Ports zu einem einzigen logischer Kanal. MPLS-Frames Ein Die Anzahl der Ethernet-Frames (Pakete) empfangen von dem Gerät, das ein Multiprotocol Label Switching (MPLS) enthielt Datagramm. MPLS ist eine Paketweiterleitungstechnologie, die Labels verwendet, um Daten zu erstellen Weiterleitung von Entscheidungen. Es wird häufig verwendet, um das folgende Netzwerk zu aktivieren Dienste: Virtual Private Networking (VPN), Traffic Engineering (TE) und Quality of Dienst (QoS) Andere Frames in Die Anzahl der Ethernet-Frames (Pakete) vom Gerät empfangen, das ein nicht spezifiziertes Datagramm enthielt STP Frames In Die Anzahl der Ethernet-Frames, die empfangen wurden von das Gerät, das ein Spanning Tree Protocol (STP) -Datagramm enthielt. STP erstellt eine spannt einen Baum innerhalb eines Netzwerk verbundener L2-Brücken und deaktiviert Verbindungen, die nicht Teil des Spannbaums, sodass ein einziger aktiver Pfad zwischen zwei beliebigen Netzwerk übrig bleibt Knoten. - Rahmentypen raus
- Das Diagramm zeigt nach Typ, wie viele Pakete die Gruppe gesendet hat.
Metrisch Beschreibung ARP Frames Out Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das ein ARP-Datagramm (Address Resolution Protocol) enthielt. HARFE ist ein Link-Level-Protokoll, das zum Auflösen von IP-Adressen in MAC verwendet wird Adressen. IEEE 802.1x-Frame-Out Die Anzahl der Ethernet-Frames (Pakete), die vom Gerät gesendet wurden und durch die portbasierte Netzwerkzugriffskontrolle definiert wurden (PNAC). IEEE 802.1x bietet einen Authentifizierungsmechanismus für Geräte, die eine Verbindung zu einem LAN oder WLAN. IPv4-Frame-Out Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das ein Internetprotokoll Version 4 (IPv4) enthielt Datagramm IPv6-Frame-Out Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das ein Internetprotokoll Version 6 (IPv6) enthielt Datagramm IPX-Frame-Ausgang Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das ein IPX-Datagramm (Internetwork Packet Exchange) enthielt. IPX ist ein Netzwerkprotokoll, das Netzwerke miteinander verbindet, die Novell NetWare verwenden. Clients und Server. LACP Frames Out Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das ein Link Aggregation Control Protocol (LACP) enthielt Datagramm. LACP steuert die Bündelung mehrerer physischer Ports zu einem einzigen logischer Kanal. MPLS-Frame-Ausgang Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das ein MPLS-Datagramm (Multiprotocol Label Switching) enthielt. MPLS ist eine Paketweiterleitungstechnologie, die Labels für die Datenweiterleitung verwendet Entscheidungen. Es wird häufig verwendet, um die folgenden Netzwerkdienste zu aktivieren: Virtuell Private Netzwerke (VPN), Verkehrstechnik (TE) und Servicequalität (QoS). Andere Frames Out Die Anzahl der Ethernet-Frames (Pakete) gesendet von dem Gerät, das ein nicht spezifiziertes Datagramm enthielt STP Frames Out Die Anzahl der Ethernet-Frames, die vom Gerät, das ein Spanning Tree Protocol (STP) -Datagramm enthielt. STP erstellt eine spannt einen Baum innerhalb eines Netzwerk verbundener L2-Brücken und deaktiviert Verbindungen, die nicht Teil des Spannbaums, sodass ein einziger aktiver Pfad zwischen zwei beliebigen Netzwerk übrig bleibt Knoten. - Mit VLAN markierte Frames In
- Dieses Diagramm zeigt Ihnen die Anzahl der Ethernet-Frames, die von Geräten in der Gruppe empfangen wurden
, die mit einem VLAN-Tag versehen wurden.
Metrisch Beschreibung Multicast-Gruppen Die Anzahl der Ethernet-Frames, die vom Gerät, die mit einem VLAN-Tag versehen wurden. VLAN-Tagging gruppiert Netzwerkressourcen logisch zu verbessern Sie die Netzwerkleistung, Sicherheit und einfache Verwaltung. - Mit VLAN markierte Frames Out
- Dieses Diagramm zeigt Ihnen die Anzahl der Ethernet-Frames, die von Geräten in der Gruppe gesendet wurden, die mit einem
VLAN-Tag versehen wurden.
Metrisch Beschreibung Multicast-Gruppen Die Anzahl der Ethernet-Frames, die vom Gerät, die mit einem VLAN-Tag versehen wurden. VLAN-Tagging gruppiert Netzwerkressourcen logisch zu verbessern Sie die Netzwerkleistung, Sicherheit und einfache Verwaltung.
IP-Protokolle
- Wichtigste IP-Protokolle — eingehende Pakete
- In dieser Tabelle wird aufgeschlüsselt, wie viele Pakete Geräte in der Gruppe per
Protokoll empfangen haben.
Metrisch Beschreibung Eingehende Pakete Die Anzahl der eingehenden Pakete, die von der Gerät. - Wichtigste IP-Protokolle — Ausgehende Pakete
- Dieses Diagramm zeigt, wie viele Pakete Geräte in der Gruppe per Protokoll gesendet haben.
Metrisch Beschreibung Ausgehende Pakete Die Anzahl der ausgehenden Pakete, die von der Gerät.
ICMP-Typen
Dieser Region wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.- Die ICMP ICMP-Typen — eingehende Pakete
- In dieser Tabelle ist nach
ICMP-Typ aufgeführt, wie viele Pakete Geräte in der Gruppe empfangen haben.
Metrisch Beschreibung Eingehende Pakete Die Anzahl der eingehenden Pakete, die von der Gerät. - Die ICMP ICMP-Typen — Ausgehende Pakete
- In dieser Tabelle ist nach ICMP-Typ aufgeführt, wie viele Pakete Geräte in der Gruppe gesendet haben.
Metrisch Beschreibung Ausgehende Pakete Die Anzahl der ausgehenden Pakete, die von der Gerät.
Wo soll ich als Nächstes suchen?
Analysieren Sie eine Metrik: Sie können weitere Informationen zu einer Metrik abrufen, indem Sie auf den Metrikwert oder -namen klicken und eine Option aus dem Menü Drilldown by auswählen. Wenn Sie sich beispielsweise die Gesamtzahl der Fehler ansehen, klicken Sie auf die Zahl und wählen Sie Server um zu sehen, welche Server die Fehler zurückgegeben haben.
Den Metric Explorer durchsuchen: Integrierte Protokollseiten enthalten die am häufigsten referenzierten Metriken für ein Protokoll, aber Sie können zusätzliche Metriken im Metric Explorer sehen. Klicken Sie auf einer Protokollseite auf einen beliebigen Diagrammtitel und wählen Sie Diagramm erstellen aus.... Wenn der Metric Explorer geöffnet wird, klicken Sie auf Metrik hinzufügen im linken Bereich, um eine Drop-down-Liste mit umfassenden Messwerten für das Gerät anzuzeigen. Wenn Sie eine interessante Metrik finden, klicken Sie Zum Dashboard hinzufügen um die Metrik zu einem neuen oder vorhandenen Dashboard hinzuzufügen.
Erstellen Sie eine benutzerdefinierte Metrik: Wenn Sie eine Metrik anzeigen möchten, die nicht im Metric Explorer enthalten ist, können Sie über einen Auslöser eine benutzerdefinierte Metrik erstellen. Weitere Informationen finden Sie in den folgenden Ressourcen:
TCP-Gerätegruppenseite
TCP-Metriken für Gruppe
| Hinweis: | Um die TCP-Metrikwerte nach Gerätegruppe aufgelistet zu sehen, können Sie bohren zu TCP-Metriken. Um
Metrikwerte nach Peer-Geräten zu sehen, die entweder TCP-Verbindungen von den Mitgliedern der
Gerätegruppe senden oder empfangen, können Sie einen Drilldown durchführen nach IP, wie in der
folgenden Abbildung dargestellt. |
- TCP-Verbindungen
- Zeigt die Anzahl der akzeptierten Verbindungen und die Anzahl der von der Gruppe initiierten Verbindungen an.
Akzeptierte Verbindungen und verbundene Verbindungen sind nicht identisch. Beispielsweise wird
ein Server im Allgemeinen weit mehr akzeptiert als verbunden haben, da Webserver
selten Verbindungen mit anderen Geräten initiieren.
Akzeptiert Die Anzahl der eingehenden TCP-Verbindungen, die von einem akzeptiert werden Gerät während des ausgewählten Zeitintervalls. Verbunden Die Anzahl der ausgehenden TCP-Verbindungen, die initiiert wurden von ein Gerät während des ausgewählten Zeitintervalls. Extern akzeptiert Die Anzahl der eingehenden TCP-Verbindungen von einer externen IP-Adresse von einem Gerät während des ausgewählten Zeitintervalls akzeptiert. Standardmäßig wird eine IP-Adresse, die nicht nach RFC1918 stammt, als extern betrachtet. IP-Adressen kann auf der Seite Netzwerkorte im System als intern oder extern angegeben werden Einstellungen oder über die REST-API-Ressource Network Locality Entry Extern verbunden Die Anzahl der ausgehenden TCP-Verbindungen von einem Gerät während des ausgewählten Zeitintervalls an eine externe IP-Adresse initiiert. Standardmäßig wird eine IP-Adresse, die nicht nach RFC1918 stammt, als extern betrachtet. IP-Adressen kann auf der Seite Netzwerkorte im System als intern oder extern angegeben werden Einstellungen oder über die REST-API-Ressource Network Locality Entry geschlossen Die Anzahl der Verbindungen, die explizit vom Gerät oder sein Peer. Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
Etabliert Die Gesamtzahl der offenen TCP-Verbindungen zwischen Geräte während des ausgewählten Zeitintervalls. Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
Gegründet Max Die größte Anzahl offener TCP-Verbindungen zwischen Geräten während des ausgewählten Zeitintervalls. Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
Abgelaufen Die Anzahl der mit diesem Gerät verknüpften Verbindungen für die das Tracking aufgrund von Inaktivität eingestellt wurde. Für die meisten Protokolle ist der Zeitbereich für Inaktivität liegt sie zwischen 16 und 60 Sekunden. Für Protokolle, die verknüpft sind mit Bei Sitzungen mit langer Laufzeit, wie ICA, kann der Bereich bis zu 10 Minuten betragen. Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
- TCP-Eingang
-
Abgebrochene Verbindungen in Die Häufigkeit, mit der ein Gerät unerwartet erhielt einen Reset (RST) anstelle eines Finishs (FIN), um einen etablierten Verbindung. Diese Zahl beinhaltet nicht unsaubere Shutdowns, also wenn ein Gerät reagiert absichtlich auf eine FIN mit einem RST, um die Verbindung zu schließen Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
Setzt ein Die Anzahl der vom Gerät empfangenen Resets (RSTs) bevor die Verbindung geschlossen wird. Eine hohe Anzahl von RSTs kann normal sein. Ein Anstieg RSTs sollten untersucht werden Empfangene SYNs Die Anzahl der vom Gerät empfangenen SYNs. EIN Das Synchronisationspaket (SYN) ist das erste Paket, das über ein TCP gesendet wird Verbindung. Nicht etablierte SYN-ACKs wurden empfangen Die Anzahl der SYN-Bestätigungen (SYN-Acks) von einem Gerät empfangen, das nicht zu einem etablierten TCP geführt hat Verbindung. Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
Unbeantwortete SYNs Ein Die Anzahl der empfangenen erneut übertragenen SYNs von einem Gerät, das nicht reagiert, beim Versuch, eine Verbindung herzustellen Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
Verstreute Segmente rein Die Anzahl der unerwarteten TCP-Pakete, die vom Gerät. Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
Eingeworfene Segmente Die Anzahl der Folgen, in denen ein Segment oder eine Serie der Segmente gingen auf dem Weg zum aktuellen Gerät verloren und wurden benötigt Weiterübertragung Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
Timeouts für die erneute Übertragung (RTOs) Ein Die Anzahl der Retransmission-Timeouts (RTOs), verursacht durch Netzwerküberlastung, da Peers Daten an das aktuelle Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
Empfangsfenster drosselt ein Die Häufigkeit, mit der das Empfangsfenster angezeigt wird wurde von einem Peer-Gerät empfangen, beschränkte den TCP-Verbindungsdurchsatz, um den Datenfluss. Eine Drosselung tritt auf, wenn ein Peer-Gerätepuffer zum Empfangen von Daten voll werden. In einigen Fällen kann die Größe des Lesesocket-Puffers erhöht werden oder Die Skalierung des Empfangsfensters kann auf dem Peer-Gerät aktiviert werden, um dieses Problem zu beheben Problem. Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
Fensterdrosseln einsenden Die Häufigkeit, mit der das Gerät zu sein schien kann Daten vom Absender mit einer höheren Rate empfangen, aber das Peer-Gerät schien durch das Sendefenster eingeschränkt zu sein. Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
SYNs ohne eingegebene Zeitstempel Die Anzahl der SYNs, die von dem Gerät empfangen wurden, das hatte keine TCP-Zeitstempeloption gesetzt. Ein Synchronisationspaket (SYN) ist das erste Paket, das über eine TCP-Verbindung gesendet wurde. Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
SYNs ohne SACK In Die Anzahl der SYNs, die das Gerät empfangen hat Die TCP-SackOk-Option ist nicht gesetzt. Ein Synchronisationspaket (SYN) ist das erste gesendete Paket über eine TCP-Verbindung. Selective Acknowledgment (SACK) ermöglicht es dem Empfänger diskontinuierliche Blöcke von Paketen bestätigen, die empfangen wurden richtig. Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
Schlechte Staukontrolle in Die Anzahl der Episoden, in denen sich ein Peer-Gerät befand zu viele Daten an das Gerät senden, was zu einer Netzwerküberlastung und einem Datenverlust führt Pakete. Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
PAWs hat SYNs reingeschmissen Die Anzahl der unbeantworteten SYN-Pakete, die wird an ein Gerät gesendet, um eine Verbindung herzustellen. Der TCP-Schutz eines Geräts Der Mechanismus gegen Wrapped Sequence (PAWS) verwirft eingehende SYN-Pakete, wenn der SYN Die Segmentsequenznummer stimmt nicht mit dem zugehörigen Zeitstempel überein Wert. Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
Der TCP-Fluss gerät ins Stocken Die Häufigkeit, mit der ein TCP-Fluss ins Stocken geraten ist so, dass dieses Gerät nicht mehr zu reagieren schien. Im ExtraHop-System ein TCP Flow Stall In gibt an, dass drei aufeinanderfolgende Retransmission-Timeouts (RTOs) trat auf, als Peer-Geräte Daten an dieses Gerät sendeten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
Kein Windows-Eingang Die Anzahl der null Fenster, die an die gesendet wurden Gerät, um den Datenfluss über die Verbindung zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
- TCP-Ausgang
-
Abgebrochene Verbindungen ausgehen Die Häufigkeit, mit der ein Gerät unerwartet hat einen Reset (RST) anstelle eines Finishs (FIN) gesendet, um einen etablierten Verbindung. Diese Zahl beinhaltet nicht unsaubere Shutdowns, also wenn ein Gerät reagiert absichtlich auf eine FIN mit einem RST, um die Verbindung zu schließen Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
Wird zurückgesetzt Die Anzahl der Resets (RSTs), die das Gerät an gesendet hat eine Verbindung beenden. Eine hohe Anzahl von RSTs kann normal sein. Ein Anstieg der RSTs sollte untersucht. SYNs gesendet Die Anzahl der SYNs, die vom Gerät gesendet wurden, um eine Verbindung. Ein Synchronisationspaket (SYN) ist das erste Paket, das über ein TCP gesendet wird Verbindung. Unbeantwortete SYNs Out Die Anzahl der erneut übertragenen SYN-Pakete wird an ein nicht reagierendes Gerät gesendet, um eine Verbindung herzustellen Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
Langsam fängt an Die Häufigkeit, mit der die Geräte den TCP-Slowstart eingegeben haben Vermeidung von Staus, Reduzierung des Verbindungsdurchsatzes Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
Ausgefallene Segmente Die Anzahl der Folgen, in denen ein Segment oder ein Eine Reihe von Segmenten ging auf dem Weg vom aktuellen Gerät verloren und wurde benötigt Weiterübertragung Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
Ausgang für Neuübertragungs-Timeouts (RTOs) Die Anzahl der verursachten Retransmission-Timeouts (RTOs) durch Netzwerküberlastung, als das Gerät Daten an seine Peers sendete. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
Drosselungen des Empfangsfensters Die Häufigkeit, mit der das Empfangsfenster angezeigt wird, was vom Gerät gesendet wurde, begrenzte den Durchsatz der TCP-Verbindung, um den Datenfluss zu verlangsamen von Daten. Eine Drosselung tritt auf, wenn ein Gerätepuffer für den Empfang von Daten voll ist. In In einigen Fällen kann die Größe des Lese-Socket-Puffers erhöht oder das Empfangsfenster skaliert werden kann auf dem Gerät aktiviert werden, um dieses Problem zu beheben. Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
Fensterdrosselungen versenden Die Häufigkeit, mit der ein Peer-Gerät schien in der Lage zu sein, Daten vom Absender mit einer höheren Rate zu empfangen, aber der Das Gerät schien durch sein Sendefenster eingeschränkt zu sein. Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
SYNs ohne ausgegebene Zeitstempel Die Anzahl der SYNs, die von dem Gerät gesendet wurden, das dies getan hat Die TCP-Zeitstempeloption ist nicht gesetzt. Ein Synchronisationspaket (SYN) ist das erste Paket über eine TCP-Verbindung gesendet. Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
SYNs ohne SACK-Ausgang Die Anzahl der SYNs, die von dem Gerät gesendet wurden, das dies getan hat Die TCP-SackOk-Option ist nicht gesetzt. Ein Synchronisationspaket (SYN) ist das erste gesendete Paket über eine TCP-Verbindung. Selective Acknowledgment (SACK) ermöglicht es dem Empfänger bestätigt diskontinuierliche Blöcke von Paketen, die korrekt empfangen wurden Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
Schlechte Überlastungskontrolle raus Die Anzahl der Episoden, in denen sich das Gerät befand zu viele Daten an ein Peer-Gerät senden, was zu einer Netzwerküberlastung und einem Datenverlust führt Pakete. Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
Ausgesandte Neuübertragungen Die Häufigkeit, mit der Daten erneut von der gesendet wurden Gerät. Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
Der TCP-Fluss gerät ins Stocken Die Häufigkeit, mit der ein TCP-Fluss ins Stocken geraten ist so, dass ein Peer-Gerät anscheinend nicht mehr reagierte. Im ExtraHop-System ein TCP Flow Stall Out gibt an, dass drei aufeinanderfolgende Retransmission-Timeouts (RTOs) trat auf, als dieses Gerät Daten an Peer-Geräte sendete. Ein einzelnes RTO steht für 1-5 zweite Verzögerung in Ihrem Netzwerk. Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
Kein Windows Out Die Anzahl der null Fenster, die gesendet wurden von Gerät, um den Datenfluss zu stoppen. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
Ausgehende Pakete, die nicht in der richtigen Reihenfolge sind Anzahl der Pakete, die von dem Gerät gesendet wurden, auf dem Die TCP-Sequenznummer stimmte nicht mit der Sequenznummer des ExtraHop-Systems überein erwartend. Die Neuordnung wurde möglicherweise am Gerät selbst oder durch einen Zwischengerät. Dies kann zu einem verringerten Verbindungsdurchsatz führen, der erhöht wird Verarbeitungslast auf dem Peer-Gerät und zusätzliche ACK-Pakete im Netzwerk. Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
Tinygrams raus Die Anzahl der vom Gerät gesendeten Tinygrams. Tinygrams treten auf, wenn TCP-Nutzlasten ineffizient segmentiert werden, was zu einem höheren als die erforderliche Anzahl von Paketen im Netzwerk. Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
Nagle verzögert Die Anzahl der Verzögerungen bei Nagle, die durch den aktuellen Gerät, das auf eine schlechte Interaktion zwischen dem Nagle-Algorithmus und verzögert hinweist Bestätigungen (ACKs Diese Metrik wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.
TCP-Geräte in der Gruppe
- Top-Gruppenmitglieder (TCP akzeptiert)
- Zeigt die Gruppenmitglieder an, die die meisten TCP-Verbindungen akzeptiert haben.
TCP akzeptiert Die Anzahl der eingehenden TCP-Verbindungen, die von einem akzeptiert werden Gerät während des ausgewählten Zeitintervalls.
TCP-Leistung
Dieser Region wird nicht angezeigt, wenn sich alle Geräte in der Gruppe in Flow Analysis befinden.- Zeit für Hin- und Rückfahrt
-
Zeit für Hin- und Rückfahrt Die Zeit, die zwischen dem Senden eines Paket durch ein Gerät verstrichen ist und Empfangen einer Bestätigung (ACK). Die Round Trip Time (RTT) ist ein Maß für Netzwerklatenz. - Zeit für den Verbindungsaufbau
-
TCP-Einrichtungszeit Die Zeit zwischen der Erkennung des erstes und letztes Paket eines TCP-3-Wege-Handshakes
Seite „Gruppen-Cloud-Dienste"
Verkehr durch Cloud-Dienste
Diese Seite zeigt Ihnen, welche Cloud-Dienstanbieter Daten mit dieser Gerätegruppe ausgetauscht haben. klicken Eingehende Byte oder Ausgehende Bytes um Informationen über empfangene oder gesendete Daten einzusehen.
Die Halo-Visualisierung zeigt Verbindungen von internen Endpunkten in dieser Gerätegruppe zu externen Endpunkten nach Cloud-Dienstanbietern. Externe Endpunkte werden auf dem äußeren Ring angezeigt und sind mit Geräten in dieser Gruppe verbunden, die als Kreise in der Mitte der Visualisierung angezeigt werden. Innere Kreise und äußere Ringe nehmen mit zunehmendem Verkehrsaufkommen an Größe zu.
- Bewegen Sie den Mauszeiger über Endpunkte oder Verbindungen, um die verfügbaren Hostnamen und IP-Adressen anzuzeigen.
- Klicken Sie auf Endpunkte oder Verbindungen, um den Fokus zu behalten und Informationen für Ihre Auswahl im Informationsfenster auf der rechten Seite anzuzeigen.
Die Tabelle im Informationsfeld zeigt Ihnen die Bitrate und wann diese Gerätegruppe Daten gesendet oder empfangen hat, aufgeschlüsselt nach den fünf wichtigsten Cloud-Dienstanbietern.
Die Liste im Informationsfeld zeigt Ihnen die Menge der von dieser Gerätegruppe gesendeten oder empfangenen Daten, aufgeschlüsselt nach Cloud-Dienstanbietern.
Seite „Gruppen-Geolokalisierung"
Verkehr nach Geolokalisierung
Diese Seite zeigt Ihnen, welche geografischen Standorte Daten mit dieser Gerätegruppe ausgetauscht haben. klicken Eingehende Byte oder Ausgehende Bytes um Informationen über empfangene oder gesendete Daten einzusehen.
Die Halo-Visualisierung zeigt Verbindungen von internen Endpunkten in dieser Gerätegruppe zu externen Endpunkten nach Geolokalisierung. Externe Endpunkte werden auf dem äußeren Ring angezeigt und sind mit Geräten in dieser Gruppe verbunden, die als Kreise in der Mitte der Visualisierung angezeigt werden. Innere Kreise und äußere Ringe nehmen mit zunehmendem Verkehrsaufkommen an Größe zu.
- Bewegen Sie den Mauszeiger über Endpunkte oder Verbindungen, um die verfügbaren Hostnamen und IP-Adressen anzuzeigen.
- Klicken Sie auf Endpunkte oder Verbindungen, um den Fokus zu behalten und Informationen für Ihre Auswahl im Informationsfenster auf der rechten Seite anzuzeigen.
Die Liste im Informationsfeld zeigt Ihnen die Menge der von dieser Gerätegruppe gesendeten oder empfangenen Daten, aufgeteilt nach Geolokalisierung.
Seite „Große Uploads gruppieren"
Große Uploads
Diese Seite zeigt Ihnen, welche externen Endpunkte in einer einzigen Übertragung über 1 MB an Daten von einem Gerät dieser Gruppe empfangen haben.
Die Halo-Visualisierung zeigt Ihnen die Verbindungen zwischen internen Endpunkten in dieser Gerätegruppe und externen Endpunkten. Externe Endpunkte werden im äußeren Ring mit Verbindungen zu Geräten in dieser Gruppe angezeigt, die als Kreise in der Mitte der Visualisierung angezeigt werden. Innere Kreise und äußere Ringe nehmen mit zunehmendem Verkehrsaufkommen an Größe zu.
Die Halo-Visualisierung zeigt Verbindungen von internen Endpunkten in dieser Gerätegruppe zu externen Endpunkten. Externe Endpunkte werden auf dem äußeren Ring angezeigt und sind mit Geräten in dieser Gruppe verbunden , die als Kreise in der Mitte der Visualisierung angezeigt werden. Innere Kreise und äußere Ringe nehmen mit zunehmendem Verkehrsaufkommen an Größe zu.
- Bewegen Sie den Mauszeiger über Endpunkte oder Verbindungen, um die verfügbaren Hostnamen und IP-Adressen anzuzeigen.
- Klicken Sie auf Endpunkte oder Verbindungen, um den Fokus zu behalten und Informationen für Ihre Auswahl im Informationsfenster auf der rechten Seite anzuzeigen.
Die Tabelle im Informationsfeld zeigt Ihnen die Bitrate und den Zeitpunkt, zu dem diese Gerätegruppe Daten gesendet hat, aufgeschlüsselt nach den fünf wichtigsten externen Endpunkten.
Die Liste im Informationsfeld zeigt Ihnen die Menge der von dieser Gerätegruppe gesendeten oder empfangenen Daten, aufgeschlüsselt nach Externer Endpunkt.
AWS-Seite für Gruppen
AWS — Eingehender Datenverkehr zur Gruppe
- Durchsatz
- Dieses Diagramm zeigt Ihnen die Bitrate des Datenverkehrs von allen AWS-Cloud-Services
zur Gerätegruppe.
Metrisch Beschreibung AWS-Kunde — Eingehende AWS-Bytes Die Anzahl der eingehenden Byte von AWS. Das Metrik zählt die Größe der gesamten Paketnutzlast - Verkehr
- Dieses Diagramm zeigt Ihnen, wie viele Daten die Gerätegruppe von allen
AWS-Cloud-Services erhalten hat.
Metrisch Beschreibung AWS-Kunde — Eingehende AWS-Bytes Die Anzahl der eingehenden Byte von AWS. Das Metrik zählt die Größe der gesamten Paketnutzlast - Die besten Dienstleistungen
- Dieses Diagramm zeigt Ihnen, wie viele Daten die Gerätegruppe empfangen hat, aufgeschlüsselt nach
den fünf wichtigsten AWS-Cloud-Services.
Metrisch Beschreibung Cloud-Dienst — Eingehende Byte nach Dienst Die Anzahl der eingehenden Byte von Cloud-Dienste, aufgelistet vom Cloud-Dienstanbieter. Diese Metrik zählt die Größe von die gesamte Paketnutzlast - Die besten S3-Eimer
- Dieses Diagramm zeigt Ihnen, wie viele Daten die Gerätegruppe empfangen hat, aufgeschlüsselt nach
den fünf wichtigsten S3-Buckets.
Metrisch Beschreibung AWS-Client — Per S3-Bucket eingehende S3-Bytes Die Anzahl der empfangenen Byte von Amazon S3 (Simple Storage Service), aufgelistet nach S3-Bucket. Diese Metrik zählt Verkehr zwischen dem Gerät und S3-Buckets. Die Zählung beinhaltet nur die Größe der verschlüsselter SSL-Datensatz.
AWS — Ausgehender Datenverkehr von der Gruppe
- Durchsatz
- Dieses Diagramm zeigt Ihnen die Bitrate des Datenverkehrs des gesamten
AWS-Cloud-Service-Datenverkehrs aus der Gerätegruppe.
Metrisch Beschreibung AWS-Client — Ausgehende AWS-Bytes Die Anzahl der ausgehenden Byte an AWS. Das Metrik zählt die Größe der gesamten Paketnutzlast - Verkehr
- Dieses Diagramm zeigt Ihnen, wie viele Daten von allen AWS-Cloud-Services von
der Gerätegruppe gesendet wurden.
Metrisch Beschreibung AWS-Client — Ausgehende AWS-Bytes Die Anzahl der ausgehenden Byte an AWS. Das Metrik zählt die Größe der gesamten Paketnutzlast - Die besten Dienstleistungen
- Dieses Diagramm zeigt Ihnen, wie viele Daten von der Gerätegruppe gesendet wurden,
aufgeschlüsselt nach den fünf wichtigsten AWS-Cloud-Services.
Metrisch Beschreibung Cloud-Dienst — Byteausgänge nach Dienst Die Anzahl der ausgehenden Byte an Cloud-Dienste, aufgelistet vom Cloud-Dienstanbieter. Diese Metrik zählt die Größe von die gesamte Paketnutzlast - Die besten S3-Eimer
- Dieses Diagramm zeigt Ihnen, wie viele Daten von der Gerätegruppe gesendet wurden,
aufgeschlüsselt nach den fünf wichtigsten S3-Buckets.
Metrisch Beschreibung AWS-Client — Vom S3-Bucket ausgehende S3-Bytes Die Anzahl der Byte, die an gesendet wurden Amazon S3 (Simple Storage Service), sortiert nach S3-Bucket. Diese Metrik zählt den Traffic zwischen dem Gerät und den S3-Buckets. Die Zählung beinhaltet nur die Größe des verschlüsselten SSL-Datensatz.
Benutzerdefinierte Gerätemetriken
Mit benutzerdefinierten Geräten können Sie Messwerte für Geräte sammeln, die sich außerhalb Ihres lokalen Netzwerk befinden, oder wenn Sie über eine Gruppe von Geräten verfügen, für die Sie Messwerte zu einem einzigen Gerät zusammenfassen möchten.
Metriken für Remote-Standorte
Sie können beliebige Gerätekennzahlen zu einem benutzerdefinierten Gerät erfassen, aber Sie können auch Metriken für entfernte Standort sammeln, um auf einfache Weise zu erfahren, wie an entfernten Standorten Dienste genutzt werden, und um einen Überblick über den Verkehr zwischen entfernten Standorten und einem Rechenzentrum zu erhalten.
In der folgenden Tabelle werden alle verfügbaren Remote-Standort-Metriken für benutzerdefinierte Geräte beschrieben:
| Metrisch | Beschreibung |
|---|---|
| Benutzerdefiniertes Gerät — Byte pro Konversation | Die Anzahl der eingehenden vom benutzerdefinierten Gerät empfangene Byte, aufgelistet nach den IP-Adressen des Empfängers und Absender. |
| Benutzerdefiniertes Gerät — Byteausgang nach Konversation | Die Anzahl der ausgehenden vom benutzerdefinierten Gerät gesendete Bytes, aufgelistet nach den IP-Adressen des Absenders und Empfänger. |
| Benutzerdefiniertes Gerät — Byteeingabe per L7-Protokoll nach Konversation | Die Nummer der vom benutzerdefinierten Gerät empfangenen eingehenden Bytes, aufgelistet nach L7-Protokoll und IP Adressen des Empfängers und Absenders. L7-Protokolle unterstützen die Kommunikation auf Anwendungsebene. |
| Benutzerdefiniertes Gerät — Byte-Ausgabe per L7-Protokoll nach Konversation | Die Nummer der vom benutzerdefinierten Gerät gesendeten ausgehenden Bytes, aufgelistet nach L7-Protokoll und IP Adressen des Absenders und Empfängers. L7-Protokolle unterstützen die Kommunikation auf Anwendungsebene. |
| Benutzerdefiniertes Gerät — Byte nach Peer-Gerät | Die Gesamtmenge der Daten Durchsatz (gemessen in Byte oder Bits), der zwischen dem benutzerdefinierten Gerät gesendet und empfangen wird und ein benutzerdefiniertes Peer-Gerät, das vom benutzerdefinierten Peer-Gerät aufgeführt wird. |
| Benutzerdefiniertes Gerät — Byteeingabe nach Peer-Gerät | Der Durchsatz eingehender Daten des benutzerdefinierten Gerät von einem benutzerdefinierten Peer-Gerät, aufgelistet vom benutzerdefinierten Peer-Gerät Gerät. |
| Benutzerdefiniertes Gerät — Byte-Ausgabe nach Peer-Gerät | Die ausgehenden Daten Durchsatz des benutzerdefinierten Gerät zu einem benutzerdefinierten Peer-Gerät, aufgeführt vom benutzerdefinierten Peer-Gerät Gerät. |
| Benutzerdefiniertes Gerät — Byteeingang nach Empfänger-IP-Adresse | Die Anzahl der eingehende Byte, die vom benutzerdefinierten Gerät empfangen wurden, aufgelistet nach der empfangenden IP Adresse. |
| Benutzerdefiniertes Gerät — Byte-Ausgabe nach Absender-IP-Adresse | Die Anzahl der vom benutzerdefinierten Gerät gesendete ausgehende Byte, aufgeführt nach der sendenden IP Adresse. |
| Benutzerdefiniertes Gerät — Per Konversation einsteigen | Die Anzahl der Neuübertragungen Timeouts (RTOs), die durch Netzwerküberlastung verursacht wurden, wenn Peers Daten an den aktuellen benutzerdefiniertes Gerät, aufgelistet nach den IP-Adressen des Empfängers und Absenders. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. |
| Benutzerdefiniertes Gerät — Per Konversation abmelden | Die Anzahl der Retransmission-Timeouts (RTOs), die durch Netzwerküberlastung verursacht werden, wenn das benutzerdefinierte Gerät sendete Daten an seine Peers, aufgelistet nach den IP-Adressen des Absenders und Empfängers. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. |
| Benutzerdefiniertes Gerät — RTT nach Konversation | Die verstrichene Zeit zwischen einem benutzerdefiniertes Gerät, das ein Paket sendet und eine Bestätigung (ACK) empfängt, aufgeführt in der IP-Adressen der Flow-Endpunkte. Die Round Trip Time (RTT) ist ein Maß für Netzwerklatenz. |
| Benutzerdefiniertes Gerät — Per Konversation einsenden | Die Anzahl der Nullfenster die an das benutzerdefinierte Gerät gesendet wurden, um den Datenfluss zu stoppen, aufgelistet nach der IP Adressen des Empfängers und Absenders. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. |
| Benutzerdefiniertes Gerät — Per Konversation versenden | Die Zahl von Null Fenster, die vom benutzerdefinierten Gerät gesendet wurden, um den Datenfluss zu stoppen, aufgelistet nach die IP-Adressen des Absenders und Empfängers. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. |
Anwendungsmetriken
Diese Metriken beziehen sich auf Anwendungen, bei denen es sich um benutzerdefinierte Container handelt.
Seite „Anwendungsübersicht"
Die Seite Anwendungsübersicht enthält interaktive Diagramme, die einen Überblick über eine ausgewählte Anwendung bieten.
Auf dieser Seite erfahren Sie mehr über Diagramme:
| Hinweis: | Diese Seite enthält nur integrierte Metriken. Wenn es zusätzlichen Traffic für benutzerdefinierte Metriken gibt, wird dieser Traffic nicht auf dieser Seite angezeigt. Sie können benutzerdefinierte Metriken auf einem Dashboard anzeigen. |
Überblick über die Anwendung
- Transaktionen
- Dieses Diagramm zeigt, über welche Protokolle die Anwendung am häufigsten kommuniziert.
- Fehler
- Diese Tabelle zeigt, bei welchen Protokollen die Anwendung die meisten Fehler hat.
- Serververarbeitungszeit (95.)
- Dieses Diagramm zeigt, welche Protokolle die höchsten Serververarbeitungszeiten haben.
- Antwort-Bytes
- Dieses Diagramm zeigt die Protokolle, über die die meisten Daten an die Anwendung übertragen werden.
Transaktionen nach Protokoll
- Transaktionen
- Dieses Diagramm zeigt, wann die Anwendung am aktivsten war, aufgeschlüsselt nach Protokoll.
- Fehler
- Dieses Diagramm zeigt, wann in der Anwendung Fehler aufgetreten sind, aufgeschlüsselt nach Protokoll.
- Serververarbeitungszeit (95.)
- Dieses Diagramm zeigt, wann die Anwendung die höchsten Serververarbeitungszeiten verzeichnete, aufgeschlüsselt nach Protokoll.
Verkehr nach Protokoll
- Antwort-Bytes
- Dieses Diagramm zeigt, wie viele Antwortbytes der Anwendung zugeordnet sind, aufgeschlüsselt nach Protokoll.
- Antwortpakete
- Dieses Diagramm zeigt, wie viele Antwortpakete der Anwendung zugeordnet sind, aufgeschlüsselt nach Protokoll.
Wo soll ich als Nächstes suchen?
Analysieren Sie eine Metrik: Sie können weitere Informationen zu einer Metrik abrufen, indem Sie auf den Metrikwert oder -namen klicken und eine Option aus dem Menü Drilldown by auswählen. Wenn Sie sich beispielsweise die Gesamtzahl der Fehler ansehen, klicken Sie auf die Zahl und wählen Sie Server um zu sehen, welche Server die Fehler zurückgegeben haben.
Den Metric Explorer durchsuchen: Integrierte Protokollseiten enthalten die am häufigsten referenzierten Metriken für ein Protokoll, aber Sie können zusätzliche Metriken im Metric Explorer sehen. Klicken Sie auf einer Protokollseite auf einen beliebigen Diagrammtitel und wählen Sie Diagramm erstellen aus.... Wenn der Metric Explorer geöffnet wird, klicken Sie auf Metrik hinzufügen im linken Bereich, um eine Drop-down-Liste mit umfassenden Messwerten für das Gerät anzuzeigen. Wenn Sie eine interessante Metrik finden, klicken Sie Zum Dashboard hinzufügen um die Metrik zu einem neuen oder vorhandenen Dashboard hinzuzufügen.
Erstellen Sie eine benutzerdefinierte Metrik: Wenn Sie eine Metrik anzeigen möchten, die nicht im Metric Explorer enthalten ist, können Sie über einen Auslöser eine benutzerdefinierte Metrik erstellen. Weitere Informationen finden Sie in den folgenden Ressourcen:
Netzwerk- und TCP-Anwendungsseite
Auf dieser Seite werden Metrikdiagramme des Netzwerk- und TCP-Datenverkehrs angezeigt, der mit Anwendungscontainern in Ihrem Netzwerk verknüpft ist.
- Auf dieser Seite erfahren Sie mehr über Diagramme:
- Erfahre mehr über mit Metriken arbeiten.
Durchsatz
- Durchsatz
- Dieses Diagramm zeigt den L2-Durchsatz im Zeitverlauf.
Metrisch Beschreibung L2-Byte anfordern Die Anzahl der L2-Bytes, die von Clients an gesendet wurden Server. Antwort L2 Byte Die Anzahl der L2-Bytes, die von Servern an gesendet wurden Kunden. - Durchsatz
- Dieses Diagramm zeigt die L2-Durchsatzrate.
Metrisch Beschreibung L2-Byte anfordern Die Anzahl der L2-Bytes, die von Clients an gesendet wurden Server. Antwort L2 Byte Die Anzahl der L2-Bytes, die von Servern an gesendet wurden Kunden. - Durchsatz
- Dieses Diagramm zeigt den gesamten L2-Durchsatz.
Metrisch Beschreibung L2-Byte anfordern Die Anzahl der L2-Bytes, die von Clients an gesendet wurden Server. Antwort L2 Byte Die Anzahl der L2-Bytes, die von Servern an gesendet wurden Kunden.
TCP-Zusammenfassung
- Verbindungen
- Dieses Diagramm zeigt L2-Verbindungen im Zeitverlauf.
Metrisch Beschreibung Verbunden Die Anzahl der Verbindungen initiiert. geschlossen Die Anzahl der geschlossenen Verbindungen. geschlossen Verbindungen werden entweder vom Client oder vom Server explizit heruntergefahren. Abgelaufen Die Anzahl der damit verbundenen Verbindungen Gerät, für das das Tracking aufgrund von Inaktivität eingestellt wurde. Für die meisten Protokolle ist der Der Zeitbereich für Inaktivität liegt zwischen 16 und 60 Sekunden. Für zugehörige Protokolle Bei Sitzungen mit langer Laufzeit wie ICA kann der Bereich bis zu 10 betragen Minuten. Aborte Die Anzahl der etablierten Verbindungen, die wurde unerwartet geschlossen, als ein Gerät einen TCP-Reset (RST) gesendet
Netzwerklatenz
- Zeit für Hin- und Rückfahrt
- In diesem Diagramm werden Perzentile für die TCP-Roundtrip-Zeit angezeigt. Hohe Roundtrip-Zeiten
deuten darauf hin, dass die Anwendung über langsame Netzwerke kommuniziert.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden einer Nachricht durch einen Client oder Server Paket, das sofort bestätigt werden muss und wann die Bestätigung erfolgte erhalten. - Zeit für Hin- und Rückfahrt
- In diesem Diagramm werden das 95. und 5. Perzentil für die TCP-Roundtrip-Zeit angezeigt.
Metrisch Beschreibung Zeit für Hin- und Rückfahrt Die Zeit zwischen dem Senden einer Nachricht durch einen Client oder Server Paket, das sofort bestätigt werden muss und wann die Bestätigung erfolgte erhalten.
Stände veranstalten
- Stände für Kunden
- Dieses Diagramm zeigt, wann Clients entweder mehr Daten sendeten, als Server verarbeiten konnten,
oder mehr Daten erhielten, als die Clients verarbeiten konnten.
Metrisch Beschreibung Zero Windows anfordern Die Anzahl der gesendeten Null-Window-Anzeigen von Kunden. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl eingehender Zero-Windows weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Drosselung anfordern und empfangen Die Gesamtanzahl der Male, dass Empfangsfenster, das die Datenmenge bestimmt, die ein Client zuvor senden kann Das Erfordernis eines ACK, das von einem Server angekündigt wurde, begrenzte den Durchsatz von Anfragen, die Kunden haben gesendet. - Gesamtzahl der Kundenstände
- Dieses Diagramm zeigt die Gesamtzahl der Anforderungs-Null-Fenster und der Anforderungs-Empfangsdrosselung
im ausgewählten Zeitraum.
Metrisch Beschreibung Zero Windows anfordern Die Anzahl der gesendeten Null-Window-Anzeigen von Kunden. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl eingehender Zero-Windows weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Drosselung anfordern und empfangen Die Gesamtanzahl der Male, dass Empfangsfenster, das die Datenmenge bestimmt, die ein Client zuvor senden kann Das Erfordernis eines ACK, das von einem Server angekündigt wurde, begrenzte den Durchsatz von Anfragen, die Kunden haben gesendet. - Serverstände
- Dieses Diagramm zeigt, wann Server entweder mehr Daten sendeten, als Clients verarbeiten konnten,
oder mehr Daten erhielten, als die Server verarbeiten konnten.
Metrisch Beschreibung Antwort Null Windows Die Anzahl der gesendeten Null-Window-Anzeigen von Servern. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl eingehender Zero-Windows weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Antwort, Empfang, Drosselung Die Gesamtanzahl der Male, dass Empfangsfenster, das die Datenmenge bestimmt, die ein Client zuvor senden kann Das Erfordernis eines ACK, das von einem Server angekündigt wurde, begrenzte den Durchsatz von Antworten, die Kunden erhielten. - Serverausfälle insgesamt
- Dieses Diagramm zeigt die Gesamtzahl der Anforderungs-Null-Fenster und der Anforderungs-Empfangsdrosselung
im ausgewählten Zeitraum.
Metrisch Beschreibung Antwort Null Windows Die Anzahl der gesendeten Null-Window-Anzeigen von Servern. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl eingehender Zero-Windows weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Antwort, Empfang, Drosselung Die Gesamtanzahl der Male, dass Empfangsfenster, das die Datenmenge bestimmt, die ein Client zuvor senden kann Das Erfordernis eines ACK, das von einem Server angekündigt wurde, begrenzte den Durchsatz von Antworten, die Kunden erhielten.
Netzwerkstände
- Überlastung anfordern
- In dieser Tabelle werden Goodput-Bitraten von Anfragen mit Antwort-RTOs verglichen, sodass Sie sehen können, wie
viele Daten übertragen wurden, als es im Netzwerk zu Blockaden kam.
Metrisch Beschreibung Goodput Bitrate anfragen Der Goodput, der mit Anfragen verknüpft ist, die gesendet wurden von von Clients zu Servern. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. RTOs anfragen Die Anzahl der aufgetretenen Retransmission-Timeouts (RTOs) beim Senden von Anforderungsdaten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
- Reaktion: Überlastung
- In dieser Tabelle werden die Goodput-Bitraten für Antworten mit den Antwort-RTOs verglichen, sodass Sie sehen können, wie
viele Daten übertragen wurden, als es im Netzwerk zu Blockaden kam.
Metrisch Beschreibung Antwort: Goodput-Bitrate Der Goodput, der den gesendeten Antworten zugeordnet ist von Servern zu Clients. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Antwort-RTOs Die Anzahl der aufgetretenen Retransmission-Timeouts (RTOs) beim Senden von Antwortdaten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
Effiziente TCP-Netzwerknutzung
- Nagle-Verzögerungen
- Dieses Diagramm zeigt, wann Verbindungen aufgrund schlechter Interaktionen zwischen dem
Nagle-Algorithmus und verzögerten ACKs verzögert wurden. In einigen Fällen kann die Deaktivierung des Nagle-Algorithmus das Problem mildern.
Auf dem BIG-IP Application Delivery Controller sollte die Nagle-Einstellung im
TCP-Profil deaktiviert und ack_on_push aktiviert sein.
Metrisch Beschreibung Nagle Delays anfragen Die Anzahl der Verbindungsverzögerungen aufgrund eines Fehlers Interaktion zwischen dem Algorithmus von Nagle und verzögerten ACKs, wenn Anfragen gesendet werden von von Clients zu Servern. Verzögerungen bei der Reaktionszeit Die Anzahl der Verbindungsverzögerungen aufgrund eines Fehlers Interaktion zwischen dem Algorithmus von Nagle und verzögerten ACKs, wenn Antworten gesendet werden von Server zu Clients. - Nagle-Verzögerungen insgesamt
- Dieses Diagramm zeigt, wie viele Verbindungen aufgrund schlechter Interaktionen zwischen dem
Nagle-Algorithmus und verzögerten ACKs verzögert wurden.
Metrisch Beschreibung Nagle Delays anfragen Die Anzahl der Verbindungsverzögerungen aufgrund eines Fehlers Interaktion zwischen dem Algorithmus von Nagle und verzögerten ACKs, wenn Anfragen gesendet werden von von Clients zu Servern. Verzögerungen bei der Reaktionszeit Die Anzahl der Verbindungsverzögerungen aufgrund eines Fehlers Interaktion zwischen dem Algorithmus von Nagle und verzögerten ACKs, wenn Antworten gesendet werden von Server zu Clients.
Gesamtwerte der Netzwerkmetriken
- Verbindungen
-
Metrisch Beschreibung Akzeptiert oder Verbunden Die Anzahl der Verbindungen initiiert. geschlossen Die Anzahl der geschlossenen Verbindungen. geschlossen Verbindungen werden entweder vom Client oder vom Server explizit heruntergefahren. Abgelaufen Die Anzahl der damit verbundenen Verbindungen Gerät, für das das Tracking aufgrund von Inaktivität eingestellt wurde. Für die meisten Protokolle ist der Der Zeitbereich für Inaktivität liegt zwischen 16 und 60 Sekunden. Für zugehörige Protokolle Bei Sitzungen mit langer Laufzeit wie ICA kann der Bereich bis zu 10 betragen Minuten. Etabliert Ein Snapshot-Zähler der Anzahl der geöffneten Verbindungen. Gegründet Max Die größte Anzahl offener Verbindungen für die Anwendung während des ausgewählten Zeitintervalls beobachtet. Aborte Die Anzahl der etablierten Verbindungen, die wurde unerwartet geschlossen, als ein Gerät einen TCP-Reset (RST) gesendet - Metriken anfordern
-
Metrisch Beschreibung Zero Windows anfordern Die Anzahl der gesendeten Null-Window-Anzeigen von Kunden. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl eingehender Zero-Windows weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Drosselung anfordern und empfangen Die Gesamtanzahl der Male, dass Empfangsfenster, das die Datenmenge bestimmt, die ein Client zuvor senden kann Das Erfordernis eines ACK, das von einem Server angekündigt wurde, begrenzte den Durchsatz von Anfragen, die Kunden haben gesendet. Nagle Delays anfragen Die Anzahl der Verbindungsverzögerungen aufgrund eines Fehlers Interaktion zwischen dem Algorithmus von Nagle und verzögerten ACKs, wenn Anfragen gesendet werden von von Clients zu Servern. RTOs Die Anzahl der aufgetretenen Retransmission-Timeouts (RTOs) beim Senden von Anforderungsdaten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
L2-Byte Die Anzahl der L2-Bytes, die von Clients an gesendet wurden Server. Gute Ausgangs-Bytes Der Goodput, der mit Anfragen verknüpft ist, die gesendet wurden von von Clients zu Servern. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Pakete Die Anzahl der Pakete, die von Clients an gesendet wurden Server. - Antwortmetriken
-
Metrisch Beschreibung Zero Windows anfordern Die Anzahl der gesendeten Null-Window-Anzeigen von Servern. Ein Gerät kündigt ein Zero Window an, wenn eingehende Daten zu schnell ankommen, um verarbeitet zu werden. Eine große Anzahl eingehender Zero-Windows weist darauf hin, dass ein Peer-Gerät zu langsam war, um die empfangene Datenmenge zu verarbeiten.
Drosselung anfordern und empfangen Die Gesamtanzahl der Male, dass Empfangsfenster, das die Datenmenge bestimmt, die ein Client zuvor senden kann Das Erfordernis eines ACK, das von einem Server angekündigt wurde, begrenzte den Durchsatz von Antworten, die Kunden erhielten. Nagle Delays anfragen Die Anzahl der Verbindungsverzögerungen aufgrund eines Fehlers Interaktion zwischen dem Algorithmus von Nagle und verzögerten ACKs, wenn Antworten gesendet werden von Server zu Clients. RTOs Die Anzahl der aufgetretenen Retransmission-Timeouts (RTOs) beim Senden von Antwortdaten. Ein RTO ist ein 1—5 Sekunden langer Stillstand im TCP-Verbindungsfluss aufgrund übermäßiger Neuübertragungen. Wenn Sie eine große Anzahl eingehender RTOs sehen, hat ein Gerät nicht schnell genug eine Bestätigung an den Server gesendet, oder das Netzwerk ist möglicherweise zu langsam, um das aktuelle Aktivitätsniveau zu unterstützen. Je nach dem im Betriebssystem konfigurierten Timeout-Wert kann diese Verzögerung zwischen 1 und 8 Sekunden liegen.
L2-Byte Die Anzahl der L2-Bytes, die von Servern an gesendet wurden Kunden. Gute Ausgangs-Bytes Der Goodput, der den gesendeten Antworten zugeordnet ist von Servern zu Clients. Goodput bezieht sich auf den Durchsatz der ursprünglich übertragenen Daten und schließt anderen Durchsatz wie Protokoll-Header oder erneut übertragene Pakete aus. Pakete Die Anzahl der Pakete, die von Servern an gesendet wurden Kunden.
Netzwerk-Metriken
Diese Metriken beziehen sich auf die Datenfeeds des Kabelnetzes oder des Flussnetz an das ExtraHop-System und umfassen VLANs und Flow-Netzwerkschnittstellen.
Seite „Netzwerkübersicht"
Eigenschaften des Netzwerks
- Name
- Der primäre Name für das Netzwerk.
- Geräte
- Die Anzahl der im Netzwerk erkannten Geräte.
- VLANs
- Die Anzahl der VLANs im Netzwerk.
- Beschreibung
- Eine benutzerdefinierte Beschreibung des Netzwerk.
- Typ
- Die Art des Netzwerk.
- API-ID
- Die ID, die das Netzwerk in der REST-API identifiziert.
- IP erfassen
- Die IP-Adresse des ExtraHop-Systems, das für die Netzwerkerfassung verantwortlich ist.
- MAC aufnehmen
-
Die MAC-Adresse des ExtraHop-Systems, das für die Netzwerkerfassung verantwortlich ist.
Überblick über das Netzwerk
- Durchsatz
- Dieses Diagramm zeigt Ihnen, wann Daten über das Netzwerk gesendet wurden, gemessen in Bits.
Metrisch Beschreibung Durchsatz Der Gesamtdurchsatz der Netzwerkerfassung in Byte. - Maximaler Durchsatz
- Dieses Diagramm zeigt Ihnen die höchste Rate, mit der Daten während des
ausgewählten Zeitintervalls über das Netzwerk gesendet wurden.
Metrisch Beschreibung Durchsatz Der Gesamtdurchsatz der Netzwerkerfassung in Byte. - Durchschnittlicher Durchsatz
- Dieses Diagramm zeigt Ihnen die durchschnittliche Rate, mit der Daten während des
ausgewählten Zeitintervalls über das Netzwerk gesendet wurden.
Metrisch Beschreibung Durchsatz Der Gesamtdurchsatz der Netzwerkerfassung in Byte.
Cloud-Dienste
- Top-Cloud-Dienste — Eingehender Verkehr
- Dieses Diagramm zeigt Ihnen, wann Daten von einem Cloud-Dienst in das Netzwerk gesendet wurden,
aufgeschlüsselt nach Cloud-Dienstanbietern.
Metrisch Beschreibung Per Cloud-Dienst eingegangene Bytes Die Anzahl der eingehenden Byte von Cloud-Dienste, aufgelistet vom Cloud-Dienstanbieter. Diese Metrik zählt die Größe von die gesamte Paketnutzlast - Top-Cloud-Dienste — Eingehender Verkehr
- Dieses Diagramm zeigt Ihnen die Gesamtmenge der Daten, die von einem
Cloud-Dienst in das Netzwerk gesendet wurden, aufgeschlüsselt nach Cloud-Dienstanbietern.
Metrisch Beschreibung Per Cloud-Dienst eingegangene Bytes Die Anzahl der eingehenden Byte von Cloud-Dienste, aufgelistet vom Cloud-Dienstanbieter. Diese Metrik zählt die Größe von die gesamte Paketnutzlast - Top-Cloud-Dienste — Ausgehender Traffic
- Dieses Diagramm zeigt Ihnen, wann Daten aus dem Netzwerk an einen Cloud-Dienst gesendet wurden,
aufgeschlüsselt nach Cloud-Dienstanbietern.
Metrisch Beschreibung Vom Cloud-Dienst ausgegebene Bytes Die Anzahl der ausgehenden Byte an Cloud-Dienste, aufgelistet vom Cloud-Dienstanbieter. Diese Metrik zählt die Größe von die gesamte Paketnutzlast - Top-Cloud-Dienste — Ausgehender Traffic
- Dieses Diagramm zeigt Ihnen die Gesamtmenge der Daten, die aus dem Netzwerk an einen
Cloud-Dienst gesendet wurden, aufgeschlüsselt nach Cloud-Dienstanbietern.
Metrisch Beschreibung Vom Cloud-Dienst ausgegebene Bytes Die Anzahl der ausgehenden Byte an Cloud-Dienste, aufgelistet vom Cloud-Dienstanbieter. Diese Metrik zählt die Größe von die gesamte Paketnutzlast
L7-Protokolle
- Die wichtigsten L7-Protokolle
- Dieses Diagramm zeigt Ihnen, wann Daten über das Netzwerk gesendet wurden, aufgeschlüsselt nach
L7-Protokoll.
Metrisch Beschreibung Bytes nach dem L7-Protokoll Die Byteanzahl für ein bestimmtes L7-Protokoll innerhalb des aktuell ausgewählten Netzwerk. L7-Protokolle unterstützen die Kommunikation auf Anwendungsebene. - Die wichtigsten L7-Protokolle
- Dieses Diagramm zeigt Ihnen die Gesamtmenge der über das Netzwerk gesendeten Daten, aufgeteilt nach
L7-Protokollen.
Metrisch Beschreibung Bytes nach dem L7-Protokoll Die Byteanzahl für ein bestimmtes L7-Protokoll innerhalb des aktuell ausgewählten Netzwerk. L7-Protokolle unterstützen die Kommunikation auf Anwendungsebene.
IP-Protokolle
- Die besten IP-Protokolle
- Dieses Diagramm zeigt Ihnen, wann Daten über das Netzwerk gesendet wurden, aufgeschlüsselt nach
IP-Protokollen.
Metrisch Beschreibung Durchsatz Der Gesamtdurchsatz der Netzwerkerfassung in Byte. - Die besten IP-Protokolle
- Dieses Diagramm zeigt die Gesamtmenge der über das Netzwerk gesendeten Daten, aufgeschlüsselt nach
IP-Protokollen.
Metrisch Beschreibung Durchsatz Der Gesamtdurchsatz der Netzwerkerfassung in Byte. - Fragmentierung von Paketen
- Dieses Diagramm zeigt, wann IP-Datagramme, die über das Netzwerk gesendet wurden, während der Übertragung fragmentiert wurden und erneut
zusammengesetzt werden mussten. Dieses Diagramm wird nicht im Fluss angezeigt Sensoren.
Metrisch Beschreibung IP-Fragmente Die Gesamtzahl der gesendeten und empfangenen IP-Fragmente. IP-Fragmentierung tritt auf, wenn ein IP-Datagramm größer als die aktuelle maximale Übertragungseinheit (MTU) ist. Damit das Paket gesendet werden kann, zerlegt der Absender das Datagramm in kleinere Teile, sogenannte Fragmente, von denen jedes seine eigenen Header-Informationen hat.Wenn du einen siehst anhaltender Anstieg dieser Zahl. Stellen Sie sicher, dass die Geräte den erwarteten Datenverkehr senden und dass die MTU-Einstellungen nicht zu niedrig sind - Fragmentierung von Paketen
- Dieses Diagramm zeigt, wie viele IP-Datagramme, die über das Netzwerk gesendet wurden, bei der Übertragung
fragmentiert waren und erneut zusammengebaut werden mussten. Dieses Diagramm wird nicht im Fluss angezeigt
Sensoren.
Metrisch Beschreibung IP-Fragmente Die Gesamtzahl der gesendeten und empfangenen IP-Fragmente. IP-Fragmentierung tritt auf, wenn ein IP-Datagramm größer als die aktuelle maximale Übertragungseinheit (MTU) ist. Damit das Paket gesendet werden kann, zerlegt der Absender das Datagramm in kleinere Teile, sogenannte Fragmente, von denen jedes seine eigenen Header-Informationen hat.Wenn du einen siehst anhaltender Anstieg dieser Zahl. Stellen Sie sicher, dass die Geräte den erwarteten Datenverkehr senden und dass die MTU-Einstellungen nicht zu niedrig sind
DSCP-Typen (Servicequalität)
Dieser Region erscheint nicht auf Durchflusssensoren.- Die besten DSCP-Typen
- Dieses Diagramm zeigt Ihnen, wann Daten über das Netzwerk gesendet wurden, aufgeschlüsselt nach dem Typ Differentiated
Services Code Point (DSCP).
Metrisch Beschreibung Durchsatz Der Gesamtdurchsatz der Netzwerkerfassung in Byte. - Die besten DSCP-Typen
- Dieses Diagramm zeigt die Gesamtmenge der über das Netzwerk gesendeten Daten, aufgeschlüsselt nach
DSCP-Typ.
Metrisch Beschreibung Durchsatz Der Gesamtdurchsatz der Netzwerkerfassung in Byte.
Arten von Paketen
Dieser Region erscheint nicht auf Durchflusssensoren.- Arten von Paketen
- Dieses Diagramm zeigt Ihnen, wann Daten über das Netzwerk gesendet wurden, aufgeschlüsselt nach
Bytetyp.
Metrisch Beschreibung Unicast-Bytes Die Anzahl der an eine einzelne gesendeten Byte Ziel im Netzwerk. Multicast-Bytes Die Anzahl der Byte, die an eine Gruppe von gesendet wurden Geräte im Netzwerk. Broadcast-Bytes Die Anzahl der Byte, die an jedes Gerät gesendet wurden das Netzwerk. - Arten von Paketen
- Dieses Diagramm zeigt die Gesamtmenge der über das Netzwerk gesendeten Daten, aufgeschlüsselt nach
Bytetyp.
Metrisch Beschreibung Unicast-Bytes Die Anzahl der an eine einzelne gesendeten Byte Ziel im Netzwerk. Multicast-Bytes Die Anzahl der Byte, die an eine Gruppe von gesendet wurden Geräte im Netzwerk. Broadcast-Bytes Die Anzahl der Byte, die an jedes Gerät gesendet wurden das Netzwerk. - Häufigste Multicast-Gruppen — Byte
- Dieses Diagramm zeigt Ihnen, wann Daten über das Netzwerk an eine Gruppe von Geräten gesendet wurden, aufgeteilt
nach Multicastgruppen.
Metrisch Beschreibung Unicast-Bits Die Anzahl der an eine einzelne gesendeten Byte Ziel im Netzwerk. Multicast-Bits Die Anzahl der Byte, die an eine Gruppe von gesendet wurden Geräte im Netzwerk. Broadcast-Bits Die Anzahl der Byte, die an jedes Gerät gesendet wurden das Netzwerk. - Häufigste Multicast-Gruppen — Byte
- Dieses Diagramm zeigt die Gesamtmenge der Daten, die über das
Netzwerk an eine Gruppe von Geräten gesendet wurden, aufgeschlüsselt nach Multicast-Gruppen.
Metrisch Beschreibung Unicast-Bits Die Anzahl der an eine einzelne gesendeten Byte Ziel im Netzwerk. Multicast-Bits Die Anzahl der Byte, die an eine Gruppe von gesendet wurden Geräte im Netzwerk. Broadcast-Bits Die Anzahl der Byte, die an jedes Gerät gesendet wurden das Netzwerk.
Wo soll ich als Nächstes suchen?
Analysieren Sie eine Metrik: Sie können weitere Informationen zu einer Metrik abrufen, indem Sie auf den Metrikwert oder -namen klicken und eine Option aus dem Menü Drilldown by auswählen. Wenn Sie sich beispielsweise die Gesamtzahl der Fehler ansehen, klicken Sie auf die Zahl und wählen Sie Server um zu sehen, welche Server die Fehler zurückgegeben haben.
Den Metric Explorer durchsuchen: Integrierte Protokollseiten enthalten die am häufigsten referenzierten Metriken für ein Protokoll, aber Sie können zusätzliche Metriken im Metric Explorer sehen. Klicken Sie auf einer Protokollseite auf einen beliebigen Diagrammtitel und wählen Sie Diagramm erstellen aus.... Wenn der Metric Explorer geöffnet wird, klicken Sie auf Metrik hinzufügen im linken Bereich, um eine Drop-down-Liste mit umfassenden Messwerten für das Gerät anzuzeigen. Wenn Sie eine interessante Metrik finden, klicken Sie Zum Dashboard hinzufügen um die Metrik zu einem neuen oder vorhandenen Dashboard hinzuzufügen.
Erstellen Sie eine benutzerdefinierte Metrik: Wenn Sie eine Metrik anzeigen möchten, die nicht im Metric Explorer enthalten ist, können Sie über einen Auslöser eine benutzerdefinierte Metrik erstellen. Weitere Informationen finden Sie in den folgenden Ressourcen:
Seite „Netzwerkpakete"
Zusammenfassung des Pakets
- Paket-Rate
- Dieses Diagramm zeigt Ihnen, wann Pakete über das Netzwerk gesendet wurden.
Metrisch Beschreibung Pakete Die Gesamtzahl der Pakete der Netzwerkerfassung. - Maximale Paketrate
- Dieses Diagramm zeigt Ihnen die höchste Rate, mit der Pakete während des ausgewählten Zeitintervalls über
das Netzwerk gesendet wurden.
Metrisch Beschreibung Pakete Die Gesamtzahl der Pakete der Netzwerkerfassung. - Durchschnittliche Paketrate
- Dieses Diagramm zeigt Ihnen die durchschnittliche Rate, mit der Pakete während des ausgewählten Zeitintervalls über
das Netzwerk gesendet wurden.
Metrisch Beschreibung Pakete Die Gesamtzahl der Pakete der Netzwerkerfassung.
L7-Protokolle
- Die besten L7-Protokolle — Pakete
- Dieses Diagramm zeigt Ihnen, wann Pakete über das Netzwerk gesendet wurden, aufgeteilt nach dem
L7-Protokoll.
Metrisch Beschreibung Pakete nach dem L7-Protokoll Die Paketanzahl für ein bestimmtes L7 Protokoll innerhalb des aktuell ausgewählten Netzwerk. L7-Protokolle unterstützen die Kommunikation auf Anwendungsebene. - Die besten L7-Protokolle — Pakete
- Dieses Diagramm zeigt die Gesamtzahl der über das Netzwerk gesendeten Pakete, aufgeteilt nach
L7-Protokollen.
Metrisch Beschreibung Pakete nach dem L7-Protokoll Die Paketanzahl für ein bestimmtes L7 Protokoll innerhalb des aktuell ausgewählten Netzwerk. L7-Protokolle unterstützen die Kommunikation auf Anwendungsebene.
IP-Protokolle
- Die besten IP-Protokolle — Pakete
- Dieses Diagramm zeigt Ihnen, wann Pakete über das Netzwerk gesendet wurden, aufgeschlüsselt nach
IP-Protokollen.
Metrisch Beschreibung Pakete Die Gesamtzahl der Pakete der Netzwerkerfassung. - Die besten IP-Protokolle — Pakete
- Dieses Diagramm zeigt die Gesamtzahl der über das Netzwerk gesendeten Pakete, aufgeteilt nach
IP-Protokollen.
Metrisch Beschreibung Pakete Die Gesamtzahl der Pakete der Netzwerkerfassung. - Fragmentierung von Paketen
- Dieses Diagramm zeigt, wann IP-Datagramme, die über das Netzwerk gesendet wurden, während der Übertragung fragmentiert wurden und erneut
zusammengesetzt werden mussten. Dieses Diagramm wird nicht im Fluss angezeigt Sensoren.
Metrisch Beschreibung IP-Fragmente Die Gesamtzahl der Pakete der Netzwerkerfassung. - Fragmentierung von Paketen
- Dieses Diagramm zeigt, wie viele IP-Datagramme, die über das Netzwerk gesendet wurden, bei der Übertragung
fragmentiert waren und erneut zusammengebaut werden mussten. Dieses Diagramm wird nicht im Fluss angezeigt
Sensoren.
Metrisch Beschreibung IP-Fragmente Die Gesamtzahl der gesendeten und empfangenen IP-Fragmente. IP-Fragmentierung tritt auf, wenn ein IP-Datagramm größer als die aktuelle maximale Übertragungseinheit (MTU) ist. Damit das Paket gesendet werden kann, zerlegt der Absender das Datagramm in kleinere Teile, sogenannte Fragmente, von denen jedes seine eigenen Header-Informationen hat.Wenn du einen siehst anhaltender Anstieg dieser Zahl. Stellen Sie sicher, dass die Geräte den erwarteten Datenverkehr senden und dass die MTU-Einstellungen nicht zu niedrig sind
DSCP-Typen (Servicequalität)
Dieser Region erscheint nicht auf Durchflusssensoren.- Die besten DSCP-Typen — Pakete
- Dieses Diagramm zeigt Ihnen, wann Pakete über das Netzwerk gesendet wurden, aufgeschlüsselt nach dem Typ
Differentiated Services Code Point (DSCP).
Metrisch Beschreibung Pakete Die Gesamtzahl der Pakete der Netzwerkerfassung. - Die besten DSCP-Typen -Pakete
- Dieses Diagramm zeigt die Gesamtzahl der über das Netzwerk gesendeten Pakete, aufgeschlüsselt nach
DSCP-Typ.
Metrisch Beschreibung Pakete Die Gesamtzahl der Pakete der Netzwerkerfassung.
Arten von Paketen
Dieser Region erscheint nicht auf Durchflusssensoren.- Arten von Paketen
- Dieses Diagramm zeigt Ihnen, wann Pakete über das Netzwerk gesendet wurden, aufgeschlüsselt nach
Pakettyp.
Metrisch Beschreibung Unicast-Pakete Die Anzahl der Informationspakete, die an einen gesendet wurden ein einziges Ziel im Netzwerk. Multicast-Pakete Die Anzahl der Informationspakete, die an einen gesendet wurden Gruppe von Geräten im Netzwerk. Broadcast-Pakete Die Anzahl der Informationspakete, die an gesendet wurden jedes Gerät im Netzwerk. - Arten von Paketen
- Dieses Diagramm zeigt die Gesamtzahl der über das Netzwerk gesendeten Pakete, aufgeschlüsselt nach
Pakettyp.
Metrisch Beschreibung Unicast-Pakete Die Anzahl der Informationspakete, die an einen gesendet wurden ein einziges Ziel im Netzwerk. Multicast-Pakete Die Anzahl der Informationspakete, die an einen gesendet wurden Gruppe von Geräten im Netzwerk. Broadcast-Pakete Die Anzahl der Informationspakete, die an gesendet wurden jedes Gerät im Netzwerk. - Die häufigsten Multicast-Gruppen — Pakete
- Dieses Diagramm zeigt Ihnen, wann Pakete an eine Gruppe von Geräten im Netzwerk gesendet wurden,
aufgeteilt nach Multicastgruppen.
Metrisch Beschreibung Multicast-Pakete Die Anzahl der Informationspakete, die an einen gesendet wurden Gruppe von Geräten im Netzwerk. - Die häufigsten Multicast-Gruppen — Pakete
- Dieses Diagramm zeigt die Gesamtzahl der Pakete, die an eine Gruppe von Geräten
im Netzwerk gesendet wurden, aufgeteilt nach Multicast-Gruppen.
Metrisch Beschreibung Multicast-Pakete Die Anzahl der Informationspakete, die an einen gesendet wurden Gruppe von Geräten im Netzwerk.
Wo soll ich als Nächstes suchen?
Analysieren Sie eine Metrik: Sie können weitere Informationen zu einer Metrik abrufen, indem Sie auf den Metrikwert oder -namen klicken und eine Option aus dem Menü Drilldown by auswählen. Wenn Sie sich beispielsweise die Gesamtzahl der Fehler ansehen, klicken Sie auf die Zahl und wählen Sie Server um zu sehen, welche Server die Fehler zurückgegeben haben.
Den Metric Explorer durchsuchen: Integrierte Protokollseiten enthalten die am häufigsten referenzierten Metriken für ein Protokoll, aber Sie können zusätzliche Metriken im Metric Explorer sehen. Klicken Sie auf einer Protokollseite auf einen beliebigen Diagrammtitel und wählen Sie Diagramm erstellen aus.... Wenn der Metric Explorer geöffnet wird, klicken Sie auf Metrik hinzufügen im linken Bereich, um eine Drop-down-Liste mit umfassenden Messwerten für das Gerät anzuzeigen. Wenn Sie eine interessante Metrik finden, klicken Sie Zum Dashboard hinzufügen um die Metrik zu einem neuen oder vorhandenen Dashboard hinzuzufügen.
Erstellen Sie eine benutzerdefinierte Metrik: Wenn Sie eine Metrik anzeigen möchten, die nicht im Metric Explorer enthalten ist, können Sie über einen Auslöser eine benutzerdefinierte Metrik erstellen. Weitere Informationen finden Sie in den folgenden Ressourcen:
Seite „Netzwerk-Frames"
Rahmengrößen
- Rahmengrößen
- Dieses Diagramm zeigt Ihnen, wann Frames über das Netzwerk gesendet wurden, aufgeschlüsselt nach
Framegrößen.
Metrisch Beschreibung 64-Byte-Frames Die Anzahl der L2-Ethernet-Frames mit einem Maximum von 64 Byte Nutzlast 128-Byte-Frames Die Anzahl der L2-Ethernet-Frames mit einem Maximum von 128 Byte Nutzlast 256-Byte-Frames Die Anzahl der L2-Ethernet-Frames mit einem Maximum von 256 Byte Nutzlast 512-Byte-Frames Die Anzahl der L2-Ethernet-Frames mit einem Maximum von 512 Byte Nutzlast 1024-Byte-Frames Die Anzahl der L2-Ethernet-Frames mit einem Maximum von 1024 Byte Nutzlast 1513-Byte-Frames Die Anzahl der L2-Ethernet-Frames mit einem Maximum von 1513 Byte Nutzlast 1518-Byte-Frames Die Anzahl der L2-Ethernet-Frames mit einem Maximum von 1518 Byte Nutzlast Jumbo-Rahmen Die Anzahl der L2-Ethernet-Frames, die mehr als enthalten 1500 und bis zu 9000 Byte Nutzlast - Rahmengrößen
- Dieses Diagramm zeigt die Gesamtzahl der Frames, die über das Netzwerk gesendet wurden,
aufgeteilt nach Framegröße.
Metrisch Beschreibung 64-Byte-Frames Die Anzahl der L2-Ethernet-Frames mit einem Maximum von 64 Byte Nutzlast 128-Byte-Frames Die Anzahl der L2-Ethernet-Frames mit einem Maximum von 128 Byte Nutzlast 256-Byte-Frames Die Anzahl der L2-Ethernet-Frames mit einem Maximum von 256 Byte Nutzlast 512-Byte-Frames Die Anzahl der L2-Ethernet-Frames mit einem Maximum von 512 Byte Nutzlast 1024-Byte-Frames Die Anzahl der L2-Ethernet-Frames mit einem Maximum von 1024 Byte Nutzlast 1513-Byte-Frames Die Anzahl der L2-Ethernet-Frames mit einem Maximum von 1513 Byte Nutzlast 1518-Byte-Frames Die Anzahl der L2-Ethernet-Frames mit einem Maximum von 1518 Byte Nutzlast Jumbo-Rahmen Die Anzahl der L2-Ethernet-Frames, die mehr als enthalten 1500 und bis zu 9000 Byte Nutzlast
Rahmentypen
- Rahmentypen
- Dieses Diagramm zeigt Ihnen, wann Frames über das Netzwerk gesendet wurden, aufgeschlüsselt nach
Framegrößen.
Metrisch Beschreibung ARP-Rahmen Ein Ethernet-Frame, der eine Adressauflösung enthält Protokolldatagramm (ARP). ARP ist ein Link-Level-Protokoll, das zur Auflösung von IP verwendet wird Adressen in MAC-Adressen umwandeln. IEEE 802.1x-Rahmen Ein Ethernet-Frame, der durch ein portbasiertes Netzwerk definiert wird Zugriffskontrolle (PNAC). IEEE 802.1x bietet einen Authentifizierungsmechanismus für Geräte die an ein LAN oder WLAN angeschlossen sind. IPv4-Frames Ein Ethernet-Frame, der ein Internetprotokoll enthält Datagramm der Version 4 (IPv4) IPv6-Frames Ein Ethernet-Frame, der ein Internetprotokoll enthält Datagramm der Version 6 (IPv6) IPX-Rahmen Ein Ethernet-Frame, der ein Internetwork-Paket enthält Exchange (IPX) -Datagramm. IPX ist ein Netzwerkprotokoll, das Netzwerke miteinander verbindet. die die NetWare-Clients und -Server von Novell verwenden LACP-Rahmen Ein Ethernet-Frame, der eine Link Aggregation Control enthält Protokolldatagramm (LACP). LACP steuert die Bündelung mehrerer physischer Ports zu bilden einen einzigen logischen Kanal. MPLS-Rahmen Ein Ethernet-Frame, der ein Multiprotokoll-Label enthält Switching (MPLS) -Datagramm. MPLS ist eine Paketweiterleitungstechnologie, die Labels verwendet um Entscheidungen zur Datenweiterleitung zu treffen. Es wird häufig verwendet, um Folgendes zu aktivieren Netzwerkdienste: Virtual Private Networking (VPN), Traffic Engineering (TE) und Servicequalität (QoS) Andere Rahmen Ein Ethernet-Frame, der einen nicht spezifizierten enthält Datagramm STP-Rahmen Ein Ethernet-Frame, der ein Spanning Tree-Protokoll enthält (STP) -Datagramm. STP erstellt einen Spannbaum innerhalb eines Netzwerk verbundener L2-Brücken und deaktiviert Links, die nicht Teil des Spanning Trees sind, sodass ein einziger aktiv bleibt Pfad zwischen zwei beliebigen Netzwerkknoten. - Rahmentypen
- Dieses Diagramm zeigt die Gesamtzahl der Frames, die über das Netzwerk gesendet wurden,
aufgeschlüsselt nach Frame-Typen.
Metrisch Beschreibung ARP-Rahmen Ein Ethernet-Frame, der eine Adressauflösung enthält Protokolldatagramm (ARP). ARP ist ein Link-Level-Protokoll, das zur Auflösung von IP verwendet wird Adressen in MAC-Adressen umwandeln. IEEE 802.1x-Rahmen Ein Ethernet-Frame, der durch ein portbasiertes Netzwerk definiert wird Zugriffskontrolle (PNAC). IEEE 802.1x bietet einen Authentifizierungsmechanismus für Geräte die an ein LAN oder WLAN angeschlossen sind. IPv4-Frames Ein Ethernet-Frame, der ein Internetprotokoll enthält Datagramm der Version 4 (IPv4) IPv6-Frames Ein Ethernet-Frame, der ein Internetprotokoll enthält Datagramm der Version 6 (IPv6) IPX-Rahmen Ein Ethernet-Frame, der ein Internetwork-Paket enthält Exchange (IPX) -Datagramm. IPX ist ein Netzwerkprotokoll, das Netzwerke miteinander verbindet. die die NetWare-Clients und -Server von Novell verwenden LACP-Rahmen Ein Ethernet-Frame, der eine Link Aggregation Control enthält Protokolldatagramm (LACP). LACP steuert die Bündelung mehrerer physischer Ports zu bilden einen einzigen logischen Kanal. MPLS-Rahmen Ein Ethernet-Frame, der ein Multiprotokoll-Label enthält Switching (MPLS) -Datagramm. MPLS ist eine Paketweiterleitungstechnologie, die Labels verwendet um Entscheidungen zur Datenweiterleitung zu treffen. Es wird häufig verwendet, um Folgendes zu aktivieren Netzwerkdienste: Virtual Private Networking (VPN), Traffic Engineering (TE) und Servicequalität (QoS) Andere Rahmen Ein Ethernet-Frame, der einen nicht spezifizierten enthält Datagramm STP-Rahmen Ein Ethernet-Frame, der ein Spanning Tree-Protokoll enthält (STP) -Datagramm. STP erstellt einen Spannbaum innerhalb eines Netzwerk verbundener L2-Brücken und deaktiviert Links, die nicht Teil des Spanning Trees sind, sodass ein einziger aktiv bleibt Pfad zwischen zwei beliebigen Netzwerkknoten. - Mit VLAN markierte Frames
- Dieses Diagramm zeigt Ihnen, wann Frames mit VLAN-Tags über das
Netzwerk gesendet wurden.
Metrisch Beschreibung VLAN markiert Die Anzahl der Frames, die VLAN-Tags enthalten beobachtet. - Mit VLAN markierte Frames
- Dieses Diagramm zeigt Ihnen, wie viele Frames mit VLAN-Tags
während des ausgewählten Zeitintervalls über das Netzwerk gesendet wurden.
Metrisch Beschreibung VLAN markiert Die Anzahl der Frames, die VLAN-Tags enthalten beobachtet.
Wo soll ich als Nächstes suchen?
Analysieren Sie eine Metrik: Sie können weitere Informationen zu einer Metrik abrufen, indem Sie auf den Metrikwert oder -namen klicken und eine Option aus dem Menü Drilldown by auswählen. Wenn Sie sich beispielsweise die Gesamtzahl der Fehler ansehen, klicken Sie auf die Zahl und wählen Sie Server um zu sehen, welche Server die Fehler zurückgegeben haben.
Den Metric Explorer durchsuchen: Integrierte Protokollseiten enthalten die am häufigsten referenzierten Metriken für ein Protokoll, aber Sie können zusätzliche Metriken im Metric Explorer sehen. Klicken Sie auf einer Protokollseite auf einen beliebigen Diagrammtitel und wählen Sie Diagramm erstellen aus.... Wenn der Metric Explorer geöffnet wird, klicken Sie auf Metrik hinzufügen im linken Bereich, um eine Drop-down-Liste mit umfassenden Messwerten für das Gerät anzuzeigen. Wenn Sie eine interessante Metrik finden, klicken Sie Zum Dashboard hinzufügen um die Metrik zu einem neuen oder vorhandenen Dashboard hinzuzufügen.
Erstellen Sie eine benutzerdefinierte Metrik: Wenn Sie eine Metrik anzeigen möchten, die nicht im Metric Explorer enthalten ist, können Sie über einen Auslöser eine benutzerdefinierte Metrik erstellen. Weitere Informationen finden Sie in den folgenden Ressourcen:
Seite „VLAN-Übersicht"
VLAN-Eigenschaften
- Name
- Der primäre Name für das VLAN.
- Übergeordnetes Netzwerk
- Der primäre Name für das übergeordnete Netzwerk des VLAN.
- Beschreibung
- Eine benutzerdefinierte Beschreibung des VLAN.
- Typ
- Die Art des Netzwerk.
- API-ID
- Die ID, die das VLAN in der REST-API identifiziert.
VLAN im Überblick
Dieser Region erscheint nicht auf Durchflusssensoren.- Durchschnittlicher Durchsatz
- Dieses Diagramm zeigt die durchschnittliche Rate, mit der Daten im Laufe der Zeit über das VLAN gesendet wurden,
gemessen in Bits.
Metrisch Beschreibung Durchsatz Der Gesamtdurchsatz der Netzwerkerfassung in Byte. - Verkehr insgesamt
- Dieses Diagramm zeigt Ihnen die Gesamtmenge der Daten, die während des
ausgewählten Zeitintervalls über das VLAN gesendet wurden.
Metrisch Beschreibung Durchsatz Der Gesamtdurchsatz der Netzwerkerfassung in Byte. - Durchschnittlicher Durchsatz
- Dieses Diagramm zeigt Ihnen die durchschnittliche Rate, mit der Daten während des
ausgewählten Zeitintervalls über das VLAN gesendet wurden.
Metrisch Beschreibung Durchsatz Der Gesamtdurchsatz der Netzwerkerfassung in Byte.
L7-Protokolle
- Die wichtigsten L7-Protokolle
- Dieses Diagramm zeigt Ihnen, wann Daten über das VLAN gesendet wurden, aufgeschlüsselt nach dem L7-Protokoll
.
Metrisch Beschreibung Bytes nach L7-Protokoll Die Byteanzahl für ein bestimmtes L7-Protokoll innerhalb des aktuell ausgewählten VLAN. L7-Protokolle unterstützen die Kommunikation auf Anwendungsebene. - Die wichtigsten L7-Protokolle
- Dieses Diagramm zeigt die Gesamtmenge der über das VLAN gesendeten Daten, aufgeteilt nach
L7-Protokollen.
Metrisch Beschreibung Bytes nach L7-Protokoll Die Byteanzahl für ein bestimmtes L7-Protokoll innerhalb des aktuell ausgewählten VLAN. L7-Protokolle unterstützen die Kommunikation auf Anwendungsebene.
IP-Protokolle
Dieser Region erscheint nicht auf Durchflusssensoren.- Die besten IP-Protokolle
- Dieses Diagramm zeigt Ihnen, wann Daten über das VLAN gesendet wurden, aufgeschlüsselt nach
IP-Protokollen.
Metrisch Beschreibung Bytes nach IP-Protokoll Die Anzahl der eingehenden und ausgehenden Byte für jedes L3 Protokolltyp. - Die besten IP-Protokolle
- Dieses Diagramm zeigt Ihnen die Gesamtmenge der über das VLAN gesendeten Daten, aufgeteilt nach
IP-Protokollen.
Metrisch Beschreibung Bytes nach IP-Protokoll Die Anzahl der eingehenden und ausgehenden Byte für jedes L3 Protokolltyp. - Fragmentierung von Paketen
- Dieses Diagramm zeigt Ihnen, wann IP-Datagramme, die über das VLAN gesendet wurden, während der
Übertragung fragmentiert wurden und erneut zusammengebaut werden mussten.
Metrisch Beschreibung IP-Fragmente Die Gesamtzahl der gesendeten und empfangenen IP-Fragmente. IP-Fragmentierung tritt auf, wenn ein IP-Datagramm größer als die aktuelle maximale Übertragungseinheit (MTU) ist. Damit das Paket gesendet werden kann, zerlegt der Absender das Datagramm in kleinere Teile, sogenannte Fragmente, von denen jedes seine eigenen Header-Informationen hat.Wenn du einen siehst anhaltender Anstieg dieser Zahl. Stellen Sie sicher, dass die Geräte den erwarteten Datenverkehr senden und dass die MTU-Einstellungen nicht zu niedrig sind - Fragmentierung von Paketen
- Dieses Diagramm zeigt Ihnen, wie viele IP-Datagramme, die über das VLAN gesendet wurden, bei der Übertragung
fragmentiert wurden und erneut zusammengebaut werden mussten.
Metrisch Beschreibung IP-Fragmente Die Gesamtzahl der gesendeten und empfangenen IP-Fragmente. IP-Fragmentierung tritt auf, wenn ein IP-Datagramm größer als die aktuelle maximale Übertragungseinheit (MTU) ist. Damit das Paket gesendet werden kann, zerlegt der Absender das Datagramm in kleinere Teile, sogenannte Fragmente, von denen jedes seine eigenen Header-Informationen hat.Wenn du einen siehst anhaltender Anstieg dieser Zahl. Stellen Sie sicher, dass die Geräte den erwarteten Datenverkehr senden und dass die MTU-Einstellungen nicht zu niedrig sind
DSCP-Typen (Servicequalität)
Dieser Region erscheint nicht auf Durchflusssensoren.- Die besten DSCP-Typen
- Dieses Diagramm zeigt Ihnen, wann Daten über das VLAN gesendet wurden, aufgeschlüsselt nach dem Typ Differentiated
Services Code Point (DSCP).
Metrisch Beschreibung Durchsatz Der Gesamtdurchsatz der Netzwerkerfassung in Byte. - Die besten DSCP-Typen
- Dieses Diagramm zeigt die Gesamtmenge der über das VLAN gesendeten Daten, aufgeschlüsselt nach
DSCP-Typ.
Metrisch Beschreibung Durchsatz Der Gesamtdurchsatz der Netzwerkerfassung in Byte.
Arten von Paketen
Dieser Region erscheint nicht auf Durchflusssensoren.- Arten von Paketen
- Dieses Diagramm zeigt Ihnen, wann Daten über das VLAN gesendet wurden, aufgeschlüsselt nach Bytetyp.
Metrisch Beschreibung Unicast-Bytes Die Anzahl der an eine einzelne gesendeten Byte Ziel im Netzwerk. Multicast-Bytes Die Anzahl der Byte, die an eine Gruppe von gesendet wurden Geräte im Netzwerk. Broadcast-Bytes Die Anzahl der Byte, die an jedes Gerät gesendet wurden das Netzwerk. - Arten von Paketen
- Dieses Diagramm zeigt die Gesamtmenge der über das VLAN gesendeten Daten, aufgeschlüsselt nach
Bytetyp.
Metrisch Beschreibung Unicast-Bytes Die Anzahl der an eine einzelne gesendeten Byte Ziel im Netzwerk. Multicast-Bytes Die Anzahl der Byte, die an eine Gruppe von gesendet wurden Geräte im Netzwerk. Broadcast-Bytes Die Anzahl der Byte, die an jedes Gerät gesendet wurden das Netzwerk. - Top-Multicast-Gruppen — Bitrate
- Dieses Diagramm zeigt Ihnen, wann Daten über das VLAN an eine Gruppe von Geräten gesendet wurden, aufgeteilt
nach Multicast-Gruppen.
Metrisch Beschreibung Unicast-Bits Die Anzahl der an eine einzelne gesendeten Byte Ziel im Netzwerk. Multicast-Bits Die Anzahl der Byte, die an eine Gruppe von gesendet wurden Geräte im Netzwerk. Broadcast-Bits Die Anzahl der Byte, die an jedes Gerät gesendet wurden das Netzwerk. - Häufigste Multicast-Gruppen — Byte
- Dieses Diagramm zeigt Ihnen die Gesamtmenge der Daten, die über das
VLAN an eine Gruppe von Geräten gesendet wurden, aufgeteilt nach Multicast-Gruppen.
Metrisch Beschreibung Unicast-Bits Die Anzahl der an eine einzelne gesendeten Byte Ziel im Netzwerk. Multicast-Bits Die Anzahl der Byte, die an eine Gruppe von gesendet wurden Geräte im Netzwerk. Broadcast-Bits Die Anzahl der Byte, die an jedes Gerät gesendet wurden das Netzwerk.
Warnmeldungen
- Warnmeldungen
- Dieses Diagramm zeigt Ihnen, welche Alerts für das VLAN generiert wurden.
Wo soll ich als Nächstes suchen?
Analysieren Sie eine Metrik: Sie können weitere Informationen zu einer Metrik abrufen, indem Sie auf den Metrikwert oder -namen klicken und eine Option aus dem Menü Drilldown by auswählen. Wenn Sie sich beispielsweise die Gesamtzahl der Fehler ansehen, klicken Sie auf die Zahl und wählen Sie Server um zu sehen, welche Server die Fehler zurückgegeben haben.
Den Metric Explorer durchsuchen: Integrierte Protokollseiten enthalten die am häufigsten referenzierten Metriken für ein Protokoll, aber Sie können zusätzliche Metriken im Metric Explorer sehen. Klicken Sie auf einer Protokollseite auf einen beliebigen Diagrammtitel und wählen Sie Diagramm erstellen aus.... Wenn der Metric Explorer geöffnet wird, klicken Sie auf Metrik hinzufügen im linken Bereich, um eine Drop-down-Liste mit umfassenden Messwerten für das Gerät anzuzeigen. Wenn Sie eine interessante Metrik finden, klicken Sie Zum Dashboard hinzufügen um die Metrik zu einem neuen oder vorhandenen Dashboard hinzuzufügen.
Erstellen Sie eine benutzerdefinierte Metrik: Wenn Sie eine Metrik anzeigen möchten, die nicht im Metric Explorer enthalten ist, können Sie über einen Auslöser eine benutzerdefinierte Metrik erstellen. Weitere Informationen finden Sie in den folgenden Ressourcen:
Seite „VLAN-Pakete"
Zusammenfassung des Pakets
Dieser Region erscheint nicht auf Durchflusssensoren.- Paket-Rate
- Dieses Diagramm zeigt Ihnen, wann Pakete über das VLAN gesendet wurden.
Metrisch Beschreibung Pakete Die Gesamtzahl der Pakete der Netzwerkerfassung. - Pakete insgesamt
- Dieses Diagramm zeigt Ihnen die Gesamtzahl der Pakete, die während des ausgewählten Zeitintervalls über
das VLAN gesendet wurden.
Metrisch Beschreibung Pakete Die Gesamtzahl der Pakete der Netzwerkerfassung. - Durchschnittliche Paketrate
- Dieses Diagramm zeigt Ihnen die durchschnittliche Rate, mit der Pakete während des
ausgewählten Zeitintervalls über das VLAN gesendet wurden.
Metrisch Beschreibung Pakete Die Gesamtzahl der Pakete der Netzwerkerfassung.
L7-Protokolle
- Die besten L7-Protokolle — Pakete
- Dieses Diagramm zeigt Ihnen, wann Pakete über das VLAN gesendet wurden, aufgeteilt nach dem L7-Protokoll
.
Metrisch Beschreibung Pakete nach dem L7-Protokoll Die Paketanzahl für ein bestimmtes L7 Protokoll innerhalb des aktuell ausgewählten Netzwerk. L7-Protokolle unterstützen die Kommunikation auf Anwendungsebene. - Die besten L7-Protokolle — Pakete
- Dieses Diagramm zeigt die Gesamtzahl der über das VLAN gesendeten Pakete, aufgeteilt nach
L7-Protokollen.
Metrisch Beschreibung Pakete nach dem L7-Protokoll Die Paketanzahl für ein bestimmtes L7 Protokoll innerhalb des aktuell ausgewählten Netzwerk. L7-Protokolle unterstützen die Kommunikation auf Anwendungsebene.
IP-Protokolle
Dieser Region erscheint nicht auf Durchflusssensoren.- Die besten IP-Protokolle — Pakete
- Dieses Diagramm zeigt Ihnen, wann Pakete über das VLAN gesendet wurden, aufgeschlüsselt nach
IP-Protokollen.
Metrisch Beschreibung Pakete Die Gesamtzahl der Pakete der Netzwerkerfassung. - Die besten IP-Protokolle — Pakete
- Dieses Diagramm zeigt die Gesamtzahl der über das VLAN gesendeten Pakete, aufgeteilt nach
IP-Protokollen.
Metrisch Beschreibung Pakete Die Gesamtzahl der Pakete der Netzwerkerfassung. - Fragmentierung von Paketen
- Dieses Diagramm zeigt, wann IP-Datagramme, die über das VLAN gesendet wurden, während der
Übertragung fragmentiert wurden und erneut zusammengebaut werden mussten.
Metrisch Beschreibung IP-Fragmente Die Gesamtzahl der Pakete der Netzwerkerfassung. - Fragmentierung von Paketen
- Dieses Diagramm zeigt Ihnen, wie viele IP-Datagramme, die über das VLAN gesendet wurden, bei der Übertragung
fragmentiert wurden und erneut zusammengebaut werden mussten.
Metrisch Beschreibung IP-Fragmente Die Gesamtzahl der gesendeten und empfangenen IP-Fragmente. IP-Fragmentierung tritt auf, wenn ein IP-Datagramm größer als die aktuelle maximale Übertragungseinheit (MTU) ist. Damit das Paket gesendet werden kann, zerlegt der Absender das Datagramm in kleinere Teile, sogenannte Fragmente, von denen jedes seine eigenen Header-Informationen hat.Wenn du einen siehst anhaltender Anstieg dieser Zahl. Stellen Sie sicher, dass die Geräte den erwarteten Datenverkehr senden und dass die MTU-Einstellungen nicht zu niedrig sind
DSCP-Typen (Servicequalität)
Dieser Region erscheint nicht auf Durchflusssensoren.- Die besten DSCP-Typen — Pakete
- Dieses Diagramm zeigt Ihnen, wann Pakete über das VLAN gesendet wurden, aufgeschlüsselt nach dem Typ
Differentiated Services Code Point (DSCP).
Metrisch Beschreibung Pakete Die Gesamtzahl der Pakete der Netzwerkerfassung. - Die besten DSCP-Typen -Pakete
- Dieses Diagramm zeigt die Gesamtzahl der über das VLAN gesendeten Pakete, aufgeteilt nach
DSCP-Typ.
Metrisch Beschreibung Pakete Die Gesamtzahl der Pakete der Netzwerkerfassung.
Pakettypen
Dieser Region erscheint nicht auf Durchflusssensoren.- Pakettypen
- Dieses Diagramm zeigt Ihnen, wann Pakete über das VLAN gesendet wurden, aufgeschlüsselt nach
Pakettyp.
Metrisch Beschreibung Unicast-Pakete Die Anzahl der Informationspakete, die an einen gesendet wurden ein einziges Ziel im Netzwerk. Multicast-Pakete Die Anzahl der Informationspakete, die an einen gesendet wurden Gruppe von Geräten im Netzwerk. Broadcast-Pakete Die Anzahl der Informationspakete, die an gesendet wurden jedes Gerät im Netzwerk. - Pakettypen
- Dieses Diagramm zeigt Ihnen die Gesamtzahl der über das VLAN gesendeten Pakete, aufgeschlüsselt nach
Pakettyp.
Metrisch Beschreibung Unicast-Pakete Die Anzahl der Informationspakete, die an einen gesendet wurden ein einziges Ziel im Netzwerk. Multicast-Pakete Die Anzahl der Informationspakete, die an einen gesendet wurden Gruppe von Geräten im Netzwerk. Broadcast-Pakete Die Anzahl der Informationspakete, die an gesendet wurden jedes Gerät im Netzwerk. - Die häufigsten Multicast-Gruppen — Pakete
- Dieses Diagramm zeigt Ihnen, wann Pakete an eine Gruppe von Geräten im VLAN gesendet wurden, aufgeteilt
nach Multicast-Gruppen.
Metrisch Beschreibung Multicast-Pakete Die Anzahl der Informationspakete, die an einen gesendet wurden Gruppe von Geräten im Netzwerk. - Die häufigsten Multicast-Gruppen — Pakete
- Dieses Diagramm zeigt die Gesamtzahl der Pakete, die an eine Gruppe von Geräten
im VLAN gesendet wurden, aufgeteilt nach Multicast-Gruppen.
Metrisch Beschreibung Multicast-Pakete Die Anzahl der Informationspakete, die an einen gesendet wurden Gruppe von Geräten im Netzwerk.
Wo soll ich als Nächstes suchen?
Analysieren Sie eine Metrik: Sie können weitere Informationen zu einer Metrik abrufen, indem Sie auf den Metrikwert oder -namen klicken und eine Option aus dem Menü Drilldown by auswählen. Wenn Sie sich beispielsweise die Gesamtzahl der Fehler ansehen, klicken Sie auf die Zahl und wählen Sie Server um zu sehen, welche Server die Fehler zurückgegeben haben.
Den Metric Explorer durchsuchen: Integrierte Protokollseiten enthalten die am häufigsten referenzierten Metriken für ein Protokoll, aber Sie können zusätzliche Metriken im Metric Explorer sehen. Klicken Sie auf einer Protokollseite auf einen beliebigen Diagrammtitel und wählen Sie Diagramm erstellen aus.... Wenn der Metric Explorer geöffnet wird, klicken Sie auf Metrik hinzufügen im linken Bereich, um eine Drop-down-Liste mit umfassenden Messwerten für das Gerät anzuzeigen. Wenn Sie eine interessante Metrik finden, klicken Sie Zum Dashboard hinzufügen um die Metrik zu einem neuen oder vorhandenen Dashboard hinzuzufügen.
Erstellen Sie eine benutzerdefinierte Metrik: Wenn Sie eine Metrik anzeigen möchten, die nicht im Metric Explorer enthalten ist, können Sie über einen Auslöser eine benutzerdefinierte Metrik erstellen. Weitere Informationen finden Sie in den folgenden Ressourcen:
Seite „VLAN-Frames"
Rahmengrößen
- Rahmengrößen
- Dieses Diagramm zeigt Ihnen, wann Frames über das VLAN gesendet wurden, aufgeschlüsselt nach
Framegröße.
Metrisch Beschreibung 64-Byte-Frames Die Anzahl der L2-Ethernet-Frames mit einem Maximum von 64 Byte Nutzlast 128-Byte-Frames Die Anzahl der L2-Ethernet-Frames mit einem Maximum von 128 Byte Nutzlast 256-Byte-Frames Die Anzahl der L2-Ethernet-Frames mit einem Maximum von 256 Byte Nutzlast 512-Byte-Frames Die Anzahl der L2-Ethernet-Frames mit einem Maximum von 512 Byte Nutzlast 1024-Byte-Frames Die Anzahl der L2-Ethernet-Frames mit einem Maximum von 1024 Byte Nutzlast 1513-Byte-Frames Die Anzahl der L2-Ethernet-Frames mit einem Maximum von 1513 Byte Nutzlast 1518-Byte-Frames Die Anzahl der L2-Ethernet-Frames mit einem Maximum von 1518 Byte Nutzlast Jumbo-Rahmen Die Anzahl der L2-Ethernet-Frames, die mehr als enthalten 1500 und bis zu 9000 Byte Nutzlast - Rahmengrößen
- Dieses Diagramm zeigt die Gesamtzahl der Frames, die über das VLAN gesendet wurden, aufgeteilt nach
Framegröße.
Metrisch Beschreibung 64-Byte-Frames Die Anzahl der L2-Ethernet-Frames mit einem Maximum von 64 Byte Nutzlast 128-Byte-Frames Die Anzahl der L2-Ethernet-Frames mit einem Maximum von 128 Byte Nutzlast 256-Byte-Frames Die Anzahl der L2-Ethernet-Frames mit einem Maximum von 256 Byte Nutzlast 512-Byte-Frames Die Anzahl der L2-Ethernet-Frames mit einem Maximum von 512 Byte Nutzlast 1024-Byte-Frames Die Anzahl der L2-Ethernet-Frames mit einem Maximum von 1024 Byte Nutzlast 1513-Byte-Frames Die Anzahl der L2-Ethernet-Frames mit einem Maximum von 1513 Byte Nutzlast 1518-Byte-Frames Die Anzahl der L2-Ethernet-Frames mit einem Maximum von 1518 Byte Nutzlast Jumbo-Rahmen Die Anzahl der L2-Ethernet-Frames, die mehr als enthalten 1500 und bis zu 9000 Byte Nutzlast
Rahmentypen
- Rahmentypen
- Dieses Diagramm zeigt Ihnen, wann Frames über das VLAN gesendet wurden, aufgeschlüsselt nach
Framegröße.
Metrisch Beschreibung ARP-Rahmen Ein Ethernet-Frame, der eine Adressauflösung enthält Protokolldatagramm (ARP). ARP ist ein Link-Level-Protokoll, das zur Auflösung von IP verwendet wird Adressen in MAC-Adressen umwandeln. IEEE 802.1x-Rahmen Ein Ethernet-Frame, der durch ein portbasiertes Netzwerk definiert wird Zugriffskontrolle (PNAC). IEEE 802.1x bietet einen Authentifizierungsmechanismus für Geräte die an ein LAN oder WLAN angeschlossen sind. IPv4-Frames Ein Ethernet-Frame, der ein Internetprotokoll enthält Datagramm der Version 4 (IPv4) IPv6-Frames Ein Ethernet-Frame, der ein Internetprotokoll enthält Datagramm der Version 6 (IPv6) IPX-Rahmen Ein Ethernet-Frame, der ein Internetwork-Paket enthält Exchange (IPX) -Datagramm. IPX ist ein Netzwerkprotokoll, das Netzwerke miteinander verbindet. die die NetWare-Clients und -Server von Novell verwenden LACP-Rahmen Ein Ethernet-Frame, der eine Link Aggregation Control enthält Protokolldatagramm (LACP). LACP steuert die Bündelung mehrerer physischer Ports zu bilden einen einzigen logischen Kanal. MPLS-Rahmen Ein Ethernet-Frame, der ein Multiprotokoll-Label enthält Switching (MPLS) -Datagramm. MPLS ist eine Paketweiterleitungstechnologie, die Labels verwendet um Entscheidungen zur Datenweiterleitung zu treffen. Es wird häufig verwendet, um Folgendes zu aktivieren Netzwerkdienste: Virtual Private Networking (VPN), Traffic Engineering (TE) und Servicequalität (QoS) Andere Rahmen Ein Ethernet-Frame, der einen nicht spezifizierten enthält Datagramm STP-Rahmen Ein Ethernet-Frame, der ein Spanning Tree-Protokoll enthält (STP) -Datagramm. STP erstellt einen Spannbaum innerhalb eines Netzwerk verbundener L2-Brücken und deaktiviert Links, die nicht Teil des Spanning Trees sind, sodass ein einziger aktiv bleibt Pfad zwischen zwei beliebigen Netzwerkknoten. - Rahmentypen
- Dieses Diagramm zeigt Ihnen die Gesamtzahl der Frames, die über das VLAN gesendet wurden,
aufgeschlüsselt nach Frame-Typ.
Metrisch Beschreibung ARP-Rahmen Ein Ethernet-Frame, der eine Adressauflösung enthält Protokolldatagramm (ARP). ARP ist ein Link-Level-Protokoll, das zur Auflösung von IP verwendet wird Adressen in MAC-Adressen umwandeln. IEEE 802.1x-Rahmen Ein Ethernet-Frame, der durch ein portbasiertes Netzwerk definiert wird Zugriffskontrolle (PNAC). IEEE 802.1x bietet einen Authentifizierungsmechanismus für Geräte die an ein LAN oder WLAN angeschlossen sind. IPv4-Frames Ein Ethernet-Frame, der ein Internetprotokoll enthält Datagramm der Version 4 (IPv4) IPv6-Frames Ein Ethernet-Frame, der ein Internetprotokoll enthält Datagramm der Version 6 (IPv6) IPX-Rahmen Ein Ethernet-Frame, der ein Internetwork-Paket enthält Exchange (IPX) -Datagramm. IPX ist ein Netzwerkprotokoll, das Netzwerke miteinander verbindet. die die NetWare-Clients und -Server von Novell verwenden LACP-Rahmen Ein Ethernet-Frame, der eine Link Aggregation Control enthält Protokolldatagramm (LACP). LACP steuert die Bündelung mehrerer physischer Ports zu bilden einen einzigen logischen Kanal. MPLS-Rahmen Ein Ethernet-Frame, der ein Multiprotokoll-Label enthält Switching (MPLS) -Datagramm. MPLS ist eine Paketweiterleitungstechnologie, die Labels verwendet um Entscheidungen zur Datenweiterleitung zu treffen. Es wird häufig verwendet, um Folgendes zu aktivieren Netzwerkdienste: Virtual Private Networking (VPN), Traffic Engineering (TE) und Servicequalität (QoS) Andere Rahmen Ein Ethernet-Frame, der einen nicht spezifizierten enthält Datagramm STP-Rahmen Ein Ethernet-Frame, der ein Spanning Tree-Protokoll enthält (STP) -Datagramm. STP erstellt einen Spannbaum innerhalb eines Netzwerk verbundener L2-Brücken und deaktiviert Links, die nicht Teil des Spanning Trees sind, sodass ein einziger aktiv bleibt Pfad zwischen zwei beliebigen Netzwerkknoten.
Wo soll ich als Nächstes suchen?
Analysieren Sie eine Metrik: Sie können weitere Informationen zu einer Metrik abrufen, indem Sie auf den Metrikwert oder -namen klicken und eine Option aus dem Menü Drilldown by auswählen. Wenn Sie sich beispielsweise die Gesamtzahl der Fehler ansehen, klicken Sie auf die Zahl und wählen Sie Server um zu sehen, welche Server die Fehler zurückgegeben haben.
Den Metric Explorer durchsuchen: Integrierte Protokollseiten enthalten die am häufigsten referenzierten Metriken für ein Protokoll, aber Sie können zusätzliche Metriken im Metric Explorer sehen. Klicken Sie auf einer Protokollseite auf einen beliebigen Diagrammtitel und wählen Sie Diagramm erstellen aus.... Wenn der Metric Explorer geöffnet wird, klicken Sie auf Metrik hinzufügen im linken Bereich, um eine Drop-down-Liste mit umfassenden Messwerten für das Gerät anzuzeigen. Wenn Sie eine interessante Metrik finden, klicken Sie Zum Dashboard hinzufügen um die Metrik zu einem neuen oder vorhandenen Dashboard hinzuzufügen.
Erstellen Sie eine benutzerdefinierte Metrik: Wenn Sie eine Metrik anzeigen möchten, die nicht im Metric Explorer enthalten ist, können Sie über einen Auslöser eine benutzerdefinierte Metrik erstellen. Weitere Informationen finden Sie in den folgenden Ressourcen:
Seite „Flow Network Summary"
Auf dieser Seite erfahren Sie mehr über Diagramme:
In Diagrammen für ein Flussnetz werden Metrik Werte angezeigt, die von allen Flussschnittstellen erfasst wurden, die das Flussnetz enthält.
Überblick
- Durchschnittlicher Durchsatz
- Dieses Diagramm zeigt den NetFlow-Durchsatz im Zeitverlauf, indem es zeigt, wann Bytes
übertragen wurden.
Metrisch Beschreibung NetFlow-Bytes Die Anzahl der L3-Bytes, die dem Fluss zugeordnet sind Technologien. - Durchsatz
- Dieses Diagramm zeigt die Geschwindigkeit, mit der NetFlow-Bytes übertragen werden.
Metrisch Beschreibung NetFlow-Bytes Die Anzahl der L3-Bytes, die dem Fluss zugeordnet sind Technologien.
Protokolle
- Top-Protokolle (durchschnittlicher Durchsatz)
- Dieses Diagramm zeigt, welche NetFlow-Protokolle im Laufe der Zeit am aktivsten waren.
Es zeigt die Übertragungsrate von Bytes, aufgeschlüsselt nach Protokoll und
Portnummer.
Metrisch Beschreibung NetFlow-Bytes nach Protokoll und Port Die Anzahl der Pakete im Zusammenhang mit Flow-Technologien, aufgelistet nach Protokoll und Portnummer. - Die besten Protokolle
- Dieses Diagramm zeigt, welche NetFlow-Protokolle am aktivsten waren, aufgeschlüsselt nach
Protokoll und Portnummer.
Metrisch Beschreibung NetFlow-Bytes nach Protokoll und Port Die Anzahl der Pakete im Zusammenhang mit Flow-Technologien, aufgelistet nach Protokoll und Portnummer.
Endpunkte
- Top-Talker (durchschnittlicher Durchsatz)
- Dieses Diagramm zeigt, welche IP-Adressen im
Laufe der Zeit die meisten NetFlow-Daten gesendet und empfangen haben.
Metrisch Beschreibung NetFlow-Bytes nach IP Die Anzahl der L3-Bytes, die mit verknüpft sind Flow-Technologien, aufgelistet nach IP-Adresse. - Die besten Redner
- Dieses Diagramm zeigt, welche IP-Adressen die meisten
NetFlow-Daten gesendet und empfangen haben.
Metrisch Beschreibung NetFlow-Bytes nach IP Die Anzahl der L3-Bytes, die mit verknüpft sind Flow-Technologien, aufgelistet nach IP-Adresse. - Top-Sender (durchschnittlicher Durchsatz)
- Dieses Diagramm zeigt, welche IP-Adressen im Laufe der
Zeit die meisten NetFlow-Daten gesendet haben.
Metrisch Beschreibung NetFlow-Bytes nach Absender-IP Die Anzahl der zugehörigen L3-Bytes mit Flow-Technologien, aufgelistet nach der IP-Adresse des Absenders. - Die besten Absender
- Dieses Diagramm zeigt, welche IP-Adressen die meisten NetFlow-Daten gesendet haben.
Metrisch Beschreibung NetFlow-Bytes nach Absender-IP Die Anzahl der zugehörigen L3-Bytes mit Flow-Technologien, aufgelistet nach der IP-Adresse des Absenders. - Die besten Empfänger (durchschnittlicher Durchsatz)
- Dieses Diagramm zeigt, welche IP-Adressen im Laufe der
Zeit die meisten NetFlow-Daten erhalten haben.
Metrisch Beschreibung NetFlow-Bytes nach Empfänger-IP Die Anzahl der L3-Bytes im Zusammenhang mit Flow-Technologien, aufgeführt nach der IP-Adresse des Empfänger. - Die besten Empfänger
- Dieses Diagramm zeigt, welche IP-Adressen die meisten NetFlow-Daten erhalten haben.
Metrisch Beschreibung NetFlow-Bytes nach Empfänger-IP Die Anzahl der L3-Bytes im Zusammenhang mit Flow-Technologien, aufgeführt nach der IP-Adresse des Empfänger. - Top-Konversationen (durchschnittlicher Durchsatz)
- Dieses Diagramm zeigt, welche IP-Adresspaare im Laufe der
Zeit die meisten NetFlow-Daten ausgetauscht haben.
Metrisch Beschreibung NetFlow-Bytes nach Konversation Die Anzahl der L3-Bytes mit Flow-Technologien verknüpft, aufgelistet nach den IP-Adressen des Fluss Endpunkte - Die besten Konversationen
- Dieses Diagramm zeigt, welche IP-Adresspaare die meisten
NetFlow-Daten ausgetauscht haben.
Metrisch Beschreibung NetFlow-Bytes nach Konversation Die Anzahl der L3-Bytes mit Flow-Technologien verknüpft, aufgelistet nach den IP-Adressen des Fluss Endpunkte
Wo soll ich als Nächstes suchen?
Analysieren Sie eine Metrik: Sie können weitere Informationen zu einer Metrik abrufen, indem Sie auf den Metrikwert oder -namen klicken und eine Option aus dem Menü Drilldown by auswählen. Wenn Sie sich beispielsweise die Gesamtzahl der Fehler ansehen, klicken Sie auf die Zahl und wählen Sie Server um zu sehen, welche Server die Fehler zurückgegeben haben.
Den Metric Explorer durchsuchen: Integrierte Protokollseiten enthalten die am häufigsten referenzierten Metriken für ein Protokoll, aber Sie können zusätzliche Metriken im Metric Explorer sehen. Klicken Sie auf einer Protokollseite auf einen beliebigen Diagrammtitel und wählen Sie Diagramm erstellen aus.... Wenn der Metric Explorer geöffnet wird, klicken Sie auf Metrik hinzufügen im linken Bereich, um eine Drop-down-Liste mit umfassenden Messwerten für das Gerät anzuzeigen. Wenn Sie eine interessante Metrik finden, klicken Sie Zum Dashboard hinzufügen um die Metrik zu einem neuen oder vorhandenen Dashboard hinzuzufügen.
Erstellen Sie eine benutzerdefinierte Metrik: Wenn Sie eine Metrik anzeigen möchten, die nicht im Metric Explorer enthalten ist, können Sie über einen Auslöser eine benutzerdefinierte Metrik erstellen. Weitere Informationen finden Sie in den folgenden Ressourcen:
Anhang zu den Kennzahlen
In den folgenden Themen werden Konzepte beschrieben, die einer Reihe von Metriken gemeinsam sind.
Zeit für Hin- und Rückfahrt
RTT-Metriken sind ein guter Indikator für die Leistung Ihres Netzwerk. Wenn Sie hohe Übertragungs- oder Verarbeitungszeiten feststellen, die RTT jedoch niedrig ist, liegt das Problem wahrscheinlich auf Geräteebene. Wenn die RTT-, Verarbeitungs- und Übertragungszeiten jedoch alle hoch sind, kann sich die Netzwerklatenz auf die Übertragungs- und Verarbeitungszeiten auswirken, und das Problem liegt möglicherweise im Netzwerk.
Das ExtraHop-System berechnet den RTT-Wert, indem es die Zeit zwischen dem ersten Paket einer Anfrage und der Bestätigung durch den Server misst, wie in der folgenden Abbildung dargestellt:
Die RTT-Metrik kann dabei helfen, die Quelle des Problems zu identifizieren, da sie nur misst, wie lange es dauert, bis eine sofortige Bestätigung vom Client oder Server gesendet wird. Sie wartet nicht, bis alle Pakete zugestellt wurden.
Erfahren Sie mehr darüber, wie das ExtraHop-System die Hin- und Rückflugzeit auf der ExtraHop-Forum .
Danke für deine Rückmeldung. Dürfen wir Sie kontaktieren, um weitere Fragen zu stellen?